
Der Aufmerksamkeitsmechanismus wird oft mit der Transformatorarchitektur verbunden, wurde aber bereits in RNNs verwendet. Bei maschinellen Übersetzungen oder MT-Aufgaben (z. B. englisch-italienisch) müssen Sie Ihr Modell auf die wichtigsten englischen Wörter konzentrieren, die nützlich sind, um eine gute Übersetzung zu erstellen, wenn Sie das nächste italienische Wort vorhersagen möchten.

Ich werde nicht auf Particulars von RNNs eingehen, aber die Aufmerksamkeit hat diesen Modellen geholfen, das Drawback der verschwindenden Gradienten zu mildern und mehr Abhängigkeiten von Langstrecken unter den Worten zu erfassen.
An einem bestimmten Punkt haben wir verstanden, dass das einzig Wichtigste der Aufmerksamkeitsmechanismus conflict und die gesamte RNN -Architektur übertrieben conflict. Somit, Aufmerksamkeit ist alles, was Sie brauchen!
Selbstbekämpfung in Transformatoren
Die klassische Aufmerksamkeit gibt an, wo Wörter in der Ausgangssequenz die Aufmerksamkeit in Bezug auf die Wörter in der Eingabesequenz konzentrieren sollten. Dies ist wichtig bei Sequenz-zu-Sequenz-Aufgaben wie MT.
Der Selbstbeziehung ist eine bestimmte Artwork von Aufmerksamkeit. Es arbeitet zwischen zwei beliebigen Elementen in derselben Reihenfolge. Es enthält Informationen darüber, wie „korreliert“ die Wörter im selben Satz sind.
Für ein bestimmtes Token (oder ein Wort) in einer Sequenz erzeugt die Selbstbekämpfung eine Liste von Aufmerksamkeitsgewichten, die allen anderen Token in der Sequenz entsprechen. Dieser Vorgang wird auf jedes Token im Satz angewendet und erhält eine Matrix der Aufmerksamkeitsgewichte (wie im Bild).
Dies ist die allgemeine Idee, in der Praxis sind die Dinge etwas komplizierter, da wir unserem neuronalen Netzwerk viele lernbare Parameter hinzufügen möchten.
Ok, V, Q -Darstellungen
Unsere Modelleingabe ist ein Satz wie “Mein Title ist Marcello Politi “. Mit dem Prozess von Tokenisierungein Satz wird in eine Liste von Zahlen wie (2, 6, 8, 3, 1) umgewandelt.
Bevor wir den Satz in den Transformator einfügen, müssen wir für jedes Token eine dichte Darstellung erstellen.
Wie erstelle ich diese Darstellung? Wir multiplizieren jedes Token mit einer Matrix. Die Matrix wird während des Trainings gelernt.
Fügen wir jetzt etwas Komplexität hinzu.
Für jedes Token erstellen wir 3 Vektoren anstelle eines, nennen wir diese Vektoren: Schlüssel, Wert Und Abfrage. (Wir sehen später, wie wir diese 3 Vektoren erstellen).

Konzeptionell haben diese 3 Token eine bestimmte Bedeutung:
- Der Vektorschlüssel repräsentiert die Kerninformationen, die vom Token erfasst wurden
- Der Vektorwert erfasst die vollständigen Informationen eines Tokens
- Die Vektorabfrage ist eine Frage zur Token -Relevanz für die aktuelle Aufgabe.
Die Idee ist additionally, dass wir uns auf ein bestimmtes Token i konzentrieren und fragen, was die Wichtigkeit der anderen Token im Satz bezüglich des Tokens, den ich berücksichtigt, in Betracht gezogen werden.
Dies bedeutet, dass wir den Vektor q_i (wir stellen eine Frage zu i) für Token I ein und machen einige mathematische Operationen mit allen anderen Token K_J (j! = I). Dies ist so, als würde man sich auf den ersten Blick wundern, was die anderen Token in der Sequenz sind, die wirklich wichtig aussehen, um die Bedeutung von Token i zu verstehen.
Was ist diese magische mathematische Operation?
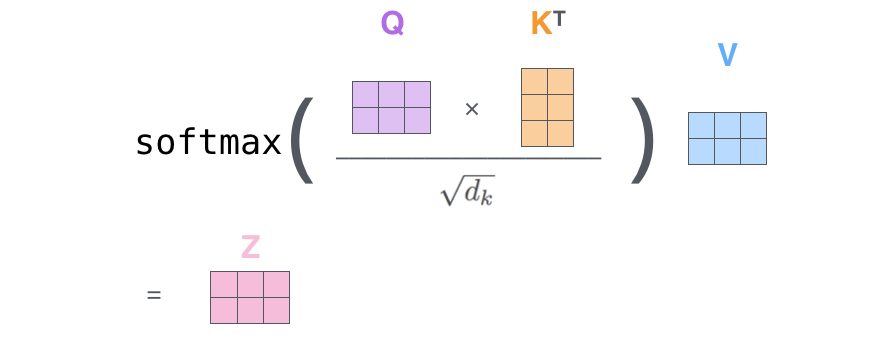
Wir müssen den Abfragevektor mit den Schlüsselvektoren multiplizieren und durch einen Skalierungsfaktor dividieren. Wir tun dies für jeden K_J -Token.
Auf diese Weise erhalten wir für jedes Paar eine Punktzahl (q_i, k_j). Wir machen diese Liste zu einer Wahrscheinlichkeitsverteilung, indem wir einen Softmax -Vorgang darauf anwenden. Großartig, jetzt haben wir das erhalten Aufmerksamkeitsgewichte!
Mit den Aufmerksamkeitsgewichten wissen wir, was die Bedeutung jedes Tokens K_J für den Token i. Jetzt multiplizieren wir den Wertvektor v_j, der jedem Token professional Gewicht zugeordnet ist, und wir summieren die Vektoren. Auf diese Weise erhalten wir das Finale Kontextbewusster Vektor von token_i.
Wenn wir den kontextbezogenen dichten Vektor von Token_1 berechnen, berechnen wir:
z1 = a11*v1 + a12*v2 +… + a15*v5
Wobei A1J die Aufmerksamkeit des Computer systems und V_J die Wertvektoren sind.
Erledigt! Quick…
Ich habe nicht bedeckt, wie wir die Vektoren Ok, V und Q eines jeden Tokens erhalten haben. Wir müssen einige Matrizen W_K, W_V und W_Q definieren, damit wir uns multiplizieren, wenn wir uns multiplizieren:
- Token * W_K -> Ok.
- Token * W_Q -> Q.
- Token * w_v -> v
Diese 3 Matrizen sind zufällig eingestellt und während des Trainings gelernt. Aus diesem Grund haben wir viele Parameter in modernen Modellen wie LLMs.
Multi-Head-Selbstbeziehung in Transformatoren (MHSA)
Sind wir sicher, dass der vorherige Selbstbekämpfungsmechanismus in der Lage ist, alle wichtigen Beziehungen zwischen Token (Wörter) aufzunehmen und dichte Vektoren dieser Token zu erzeugen, die wirklich Sinn machen?
Es könnte eigentlich nicht immer perfekt funktionieren. Was ist, wenn wir den Fehler abschwächen können, das das Ganze 2 Mal mit neuen Matrizen W_Q, W_K und W_V erneut ausführen und die 2 dichten Vektoren irgendwie verschmelzen? Auf diese Weise gelang es einer Selbstbekämpfung vielleicht, eine Beziehung aufzunehmen, und der andere gelang es, eine andere Beziehung aufzunehmen.
Nun, genau das passiert genau in MHSA. Der gerade besprochene Fall enthält zwei Köpfe, da es zwei Sätze von W_Q-, W_K- und W_V -Matrizen enthält. Wir können noch mehr Köpfe haben: 4, 8, 16 usw.
Das einzig komplizierte Ding ist, dass alle diese Köpfe parallel verwaltet werden. Wir verarbeiten das alle in derselben Berechnung mithilfe von Tensoren.

Die Artwork und Weise, wie wir die dichten Vektoren jedes Kopfes verschmelzen, ist einfach, sie verkettet sie (daher muss die Dimension jedes Vektors kleiner sein, damit wir die ursprüngliche Dimension erhalten, die wir gewünscht haben), und wir den erhaltenen Vektor durch eine andere W_O -lernbare Matrix bestehen.
Praktisch
Angenommen, Sie haben einen Satz. Nach der Tokenisierung entspricht jedes Token (Wort für die Einfachheit) einem Index (Nummer):
Bevor wir den Satz in den Transofrmer füttern, müssen wir für jedes Token eine dichte Darstellung erstellen.
Wie erstelle ich diese Darstellung? Wir multiplizieren jeden Token professional Matrix. Diese Matrix wird während des Trainings gelernt.
Lassen Sie uns diese Einbettungsmatrix erstellen.
Wenn wir unseren tokenisierten Satz mit den Einbettungen multiplizieren, erhalten wir für jeden Token eine dichte Darstellung der Dimension 16
Um den Aufmerksamkeitsmechanismus zu verwenden, müssen wir 3 Neue erstellen. Wir definieren 3 Matrixes W_Q, W_K und W_V. Wenn wir eine Eingangs -Token -Zeit multiplizieren, erhalten wir den Vektor q. Gleiches gilt für w_k und w_v.
Aufmerksamkeitsgewichte berechnen
Berechnen wir nun die Aufmerksamkeitsgewichte nur für das erste Eingangs -Token des Satzes.
Wir müssen den Abfragevektor multiplizieren, der Token1 (query_1) mit allen Schlüssel der anderen Vektoren zugeordnet ist.
Jetzt müssen wir alle Tasten berechnen (KEY_2, KEY_2, KEY_4, KEY_5). Aber warten Sie, wir können all dies in einer Zeit berechnen, indem wir die Zeit der W_K -Matrix multiplizieren.
Lassen Sie uns das Gleiche mit den Werten machen
Berechnen wir den ersten Teil der Attionsformel.
import torch.nn.practical as FMit den Aufmerksamkeitsgewichten wissen wir, was die Bedeutung jedes Tokens ist. Jetzt multiplizieren wir den Wertvektor, der jedem Token professional Gewicht zugeordnet ist.
Um den endgültigen Kontext zu erhalten, bewusster Vektor von Token_1.
Auf die gleiche Weise konnten wir den Kontext bewusst werden, die dichte Vektoren aller anderen Tokens bewusst sind. Jetzt verwenden wir immer die gleichen Matrizen W_K, W_Q, W_V. Wir sagen, dass wir einen Kopf benutzen.
Aber wir können mehrere Tripletts von Matrizen haben, additionally mehrköpfig. Deshalb wird es Multi-Head-Aufmerksamkeit genannt.
Die dichten Vektoren eines Enter -Tokens, die in Oputut von jedem Kopf angegeben sind, sind an der damaligen endgültigen und linear transformiert, um den endgültigen dichten Vektor zu erhalten.
Implementierung von Multiheadsselfbeziehung
Gleiche Schritte wie zuvor…
Wir werden einen Multi-Head-Aufmerksamkeitsmechanismus mit H-Köpfen definieren (sagen wir 4 Köpfe für dieses Beispiel). Jeder Kopf hat seine eigenen Matrizen mit W_Q, W_K und W_V, und die Ausgabe jedes Kopfes wird verkettet und durch eine endgültige lineare Schicht geleitet.
Da die Ausgabe des Kopfes verkettet wird und wir eine endgültige Dimension von D haben, muss die Dimension jedes Kopfes d/h sein. Zusätzlich wird jeder verkettete Vektor durch eine lineare Transformation verlaufen, sodass wir eine andere Matrix W_OUPTUT benötigen, wie Sie in der Formel sehen können.
Da wir 4 Köpfe haben, wollen wir 4 Kopien für jede Matrix. Anstelle von Kopien fügen wir eine Dimension hinzu, die dasselbe ist, aber wir machen nur eine Operation. (Stellen Sie sich vor, Sie stapeln Matrizen übereinander, es ist dasselbe).
Ich benutze zum Einfachheit halber Taschenlampen. Wenn Sie damit nicht vertraut sind, schauen Sie sich meine an Weblog -Beitrag.
Die Einsum -Operation torch.einsum('sd,hde->hse', sentence_embed, w_query) In Pytorch definieren Sie Buchstaben, um zu multiplizieren und Zahlen neu zu ordnen. Hier ist, was jeder Teil bedeutet:
- Tensoren eingeben:
sentence_embedmit der Notation'sd':srepräsentiert die Anzahl der Wörter (Sequenzlänge), die 5 ist.drepräsentiert die Anzahl der Zahlen professional Wort (Einbettungsgröße), die 16 ist.- Die Type dieses Tensors ist
(5, 16).
w_querymit der Notation'hde':hrepräsentiert die Anzahl der Köpfe, die 4 sind.drepräsentiert die Einbettungsgröße, die wiederum 16 ist.erepräsentiert die neue Zahlengröße professional Kopf (D_K), die 4 ist.- Die Type dieses Tensors ist
(4, 16, 4).
- Tensor Ausgang:
- Die Ausgabe hat die Notation
'hse':hrepräsentiert 4 Köpfe.srepräsentiert 5 Wörter.erepräsentiert 4 Zahlen professional Kopf.- Die Type des Ausgangs -Tensors ist
(4, 5, 4).
- Die Ausgabe hat die Notation
Diese Einsum -Gleichung führt ein Punktprodukt zwischen den Abfragen (HSE) und den transponierten Schlüssel (HEK) durch, um die Type von Type (h, seq_len, seq_len) zu erhalten, wobei:
- H -> Anzahl der Köpfe.
- S und Ok -> Sequenzlänge (Anzahl der Token).
- E -> Dimension jedes Kopfes (d_k).
Die Teilung durch (d_k ** 0,5) skaliert die Punktzahlen, um Gradienten zu stabilisieren. Softmax wird dann angewendet, um Aufmerksamkeitsgewichte zu erhalten:
Jetzt verkettet wir alle Köpfe von Token 1
Multiplizieren wir endlich die letzte W_Output -Matrix wie in der obigen Formel
Letzte Gedanken
In diesem Weblog -Beitrag habe ich eine einfache Model des Aufmerksamkeitsmechanismus implementiert. So wird es nicht wirklich in modernen Frameworks implementiert, aber mein Umfang ist es, einige Erkenntnisse zu geben, damit jemandem ein Verständnis dafür ist, wie dies funktioniert. In zukünftigen Artikeln werde ich die gesamte Implementierung einer Transformatorarchitektur durchgehen.
Folgen Sie mir weiter Tds Wenn Sie diesen Artikel mögen! 😁
💼 LinkedIn ️ | 🐦 X (Twitter) | 💻 Webseite
Sofern nicht anders angegeben, stammen die Bilder vom Autor