Dieser Blogbeitrag stammt von Aki und enthält am Ende einige Auszüge aus dem bald erscheinenden Buch „Bayesian Workflow“, Abschnitt 5.4 Ein Datenmodell ist nicht nur eine „Wahrscheinlichkeit“.
Es scheint immer häufiger vorzukommen, dass Menschen von Wahrscheinlichkeit sprechen, wenn sie über das Datenmodell sprechen.
Ein Bayesianisches Modell wird durch die gemeinsame Verteilung der Daten und Parameter p(y, Theta) definiert. Dies wird normalerweise als Datenmodell p(y | Theta) und Prior p(Theta) faktorisiert. Das Produkt aus Datenmodell und Prior definiert die gemeinsame Verteilung.
Wenn wir auf Daten konditionieren, ist p(y, Theta) nur eine Funktion von Theta und die Bayes-Regel gibt den Posterioren als p(Theta | y) propto p(y | Theta) p(Theta) an. Hier wird p(y | Theta) als Funktion von Theta Wahrscheinlichkeit (Funktion) genannt.
Ich habe absichtlich die übliche Notation verwendet, bei der p(y | Theta) als Funktion von y das Datenmodell und p(y | Theta) als Funktion von Theta die Wahrscheinlichkeit (Funktion) ist. Aufgrund dieser gebräuchlichen Schreibweise ist es umso wichtiger, dass wir für diese die korrekten Namen verwenden.
Beispielsweise ist bei einem Bernoulli-Datenmodell das Datenmodell diskret, die Wahrscheinlichkeit jedoch kontinuierlich. Es handelt sich offensichtlich um völlig unterschiedliche Funktionen. Vor sehr langer Zeit fragte ein Pupil: „Wie ist es möglich, dass die Kombination eines diskreten Binomialmodells und eines kontinuierlichen Beta-Prior-Modells ein kontinuierliches Posterior-Modell ergibt?“ Daher ist es wichtig zu verstehen, dass die Probability-Funktion nicht binomial ist, sondern die Kind einer Beta-Funktion hat!
Wir brauchen generative Modelle, Datenmodelle zur Vorabkontrolle. Wenn Sie Wahrscheinlichkeit und Prior kombinieren, erhalten Sie das Posterior. Wenn Sie das Prior- und das Datenmodell kombinieren, erhalten Sie die Prior-Vorhersageverteilung!
Sie können das Datenmodell nicht immer anhand der Wahrscheinlichkeit ermitteln. Das klassische Beispiel ist ein (diskretes) Poisson-Modell für die Anzahl der Ereignisse in einer bestimmten Zeit und ein Gamma-Modell für die Wartezeit bis zu einer bestimmten Anzahl von Ereignissen. Beide haben gammaförmige Wahrscheinlichkeiten, und die Kenntnis dieser Funktion verrät uns nicht, um welches Datenmodell es sich handelt!
Wenn man zum Beispiel in Stan schreibt
y ~ regular(mu, sigma);
dies lautet „y ist regular verteilt mit den Parametern mu und sigma“.
Wir können auch schreiben
goal += normal_lpdf(y | mu, sigma);
und wenn y Daten sind, erhöhen wir das Ziel mit der Log-Probability.
In einfachen Modellen ist das Datenmodell leicht vom Prior zu unterscheiden. Bei hierarchischen und fehlenden Datenmodellen gibt es jedoch keine scharfe Trennung zwischen Parametern und Daten, da ein Modell latente Daten enthalten kann, die nicht beobachtet werden, aber dennoch ein generatives Modell erhalten. Im Fall teilweise zensierter Daten können wir beispielsweise Beobachtungen y_obs und zensierte Beobachtungen y_cens haben, von denen wir wissen, dass sie größer als ein bekannter Zensurschwellenwert 𝑈 sind. Wir können ein gemeinsames Modell schreiben (da dieser Weblog keine Gleichungen zulässt, hier ein Screenshot aus dem Buch „Bayesian Workflow“)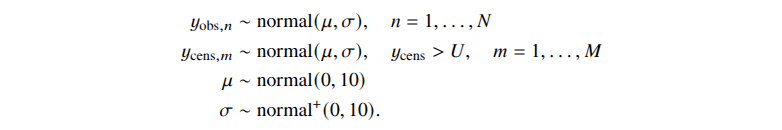
Hier erhalten y_cens das gleiche generative Datenmodell wie y_obs, und U hat überhaupt kein Modell. Wenn wir das Modell definieren, bevor die Daten beobachtet werden, ist es in einem solchen Modell nicht möglich zu sagen, wo das Datenmodell endet und das Prior beginnt. Es hängt davon ab, welche Beobachtungen zensiert werden, sobald die Daten eintreffen.
Ein weiterer Screenshot aus dem Bayesian Workflow-Buch:

Und noch ein weiteres Beispiel:

Ich hoffe, diese Beispiele veranschaulichen, warum es wichtig ist, die Begriffe Datenmodell und Wahrscheinlichkeit richtig zu verwenden und nicht alles als Wahrscheinlichkeit zu bezeichnen. In einfachen Fällen ist es möglich, aus dem Kontext zu verstehen, wann der Begriff Wahrscheinlichkeit falsch verwendet wird. Wenn Sie ihn jedoch weiterhin in einfachen Fällen verwenden, erschweren Sie die Sache in komplexeren Fällen.
Wir diskutieren Datenmodelle und Wahrscheinlichkeiten ausführlicher im kommenden Buch „Bayesian Workflow“ (voraussichtliches Veröffentlichungsdatum im Juni).
PS. Ein Datenmodell wird manchmal auch als Stichprobenverteilung, Beobachtungsverteilung oder Restverteilung bezeichnet. Diese entsprechen unterschiedlichen Datenstrukturen (Stichprobenentnahme aus einer Grundgesamtheit, verrauschte Messung eines latenten Prozesses und Residuen aus einem additiven Modell). Um alle diese Szenarien zu berücksichtigen, verwenden wir den allgemeineren Begriff „Datenmodell“.