
IBM hat die Veröffentlichung von angekündigt Granit 4.0 3B Imaginative and prescientein Imaginative and prescient-Language-Modell (VLM), das speziell für die Extraktion von Dokumentendaten auf Unternehmensebene entwickelt wurde. Abweichend vom monolithischen Ansatz größerer multimodaler Modelle ist die Model 4.0 Imaginative and prescient als spezialisierter Adapter konzipiert, der hochauflösende visuelle Argumentation in die Welt bringen soll Granit 4.0 Mikro Sprachrückgrat.
Diese Model stellt einen Übergang zu modularer, auf Extraktion fokussierter KI dar, die der Genauigkeit strukturierter Daten – wie der Konvertierung komplexer Diagramme in Code oder Tabellen in HTML – Vorrang vor allgemeiner Bildbeschriftung einräumt.
Architektur: Modulare LoRA- und DeepStack-Integration
Das Modell Granite 4.0 3B Imaginative and prescient wird als geliefert LoRA (Low-Rank-Anpassung) Adapter mit ca. 0,5B Parametern. Dieser Adapter ist so konzipiert, dass er oben auf den geladen werden kann Granit 4.0 Mikro Basismodell, ein dichtes Sprachmodell mit 3,5B Parametern. Dieses Design ermöglicht eine „Twin-Mode“-Bereitstellung: Das Basismodell kann reine Textanfragen unabhängig verarbeiten, während der Imaginative and prescient-Adapter nur aktiviert wird, wenn eine multimodale Verarbeitung erforderlich ist.
Imaginative and prescient Encoder und Patch Tiling
Die visuelle Komponente nutzt die google/siglip2-so400m-patch16-384 Encoder. Um eine hohe Auflösung über verschiedene Dokumentlayouts hinweg aufrechtzuerhalten, verwendet das Modell einen Kachelmechanismus. Eingabebilder werden in zerlegt 384×384 Patchesdie zusammen mit einer verkleinerten globalen Ansicht des gesamten Bildes verarbeitet werden. Dieser Ansatz stellt sicher, dass feine Particulars – wie etwa Indizes in Formeln oder kleine Datenpunkte in Diagrammen – erhalten bleiben, bevor sie das Sprachgerüst erreichen.
Das DeepStack-Spine
Um die Visions- und Sprachmodalitäten zu überbrücken, nutzt IBM eine Variante des DeepStack-Architektur. Dabei werden visuelle Token tief in das Sprachmodell integriert 8 spezifische Einspritzpunkte. Durch die Weiterleitung visueller Merkmale in mehrere Ebenen des Transformators erreicht das Modell eine engere Ausrichtung zwischen dem „Was“ (semantischer Inhalt) und dem „Wo“ (räumliches Structure), was für die Aufrechterhaltung der Struktur während der Dokumentenanalyse von entscheidender Bedeutung ist.
Schulungsplan: Schwerpunkt auf Diagramm- und Tabellenextraktion
Die Schulung von Granite 4.0 3B Imaginative and prescient spiegelt eine strategische Verlagerung hin zu spezialisierten Extraktionsaufgaben wider. Anstatt sich ausschließlich auf allgemeine Bild-Textual content-Datensätze zu verlassen, nutzte IBM eine kuratierte Mischung von Daten zur Befehlsfolge, die sich auf komplexe Dokumentstrukturen konzentrierten.
- ChartNet-Datensatz: Das Modell wurde mit verfeinert ChartNetein multimodaler Datensatz im Millionenmaßstab, der für ein solides Diagrammverständnis entwickelt wurde.
- Codegesteuerte Pipeline: Ein wichtiger technischer Höhepunkt der Schulung ist ein „codegesteuerter“ Ansatz für die Diagrammbegründung. Diese Pipeline verwendet ausgerichtete Daten, die aus dem ursprünglichen Plotcode, dem resultierenden gerenderten Bild und der zugrunde liegenden Datentabelle bestehen, sodass das Modell die strukturelle Beziehung zwischen visuellen Darstellungen und ihren Quelldaten lernen kann.
- Extraktionsoptimierung: Das Modell wurde anhand einer Mischung verschiedener Datensätze verfeinert Extraktion von Schlüssel-Wert-Paaren (KVP).Tabellenstrukturerkennung und Konvertierung visueller Diagramme in maschinenlesbare Formate wie CSV, JSON und OTSL.
Leistungs- und Bewertungsbenchmarks
In technischen Bewertungen wurde Granite 4.0 3B Imaginative and prescient mit mehreren branchenüblichen Suiten zum Dokumentenverständnis verglichen. Es ist wichtig zu beachten, dass Datensätze wie PubTables-v2 Und OmniDocBench werden als Evaluierungsbenchmarks verwendet, um die Zero-Shot-Leistung des Modells in realen Szenarien zu überprüfen.
| Aufgabe | Bewertungsbenchmark | Metrisch |
| KVP-Extraktion | VAREX | 85,5 % exakte Übereinstimmung (Zero-Shot) |
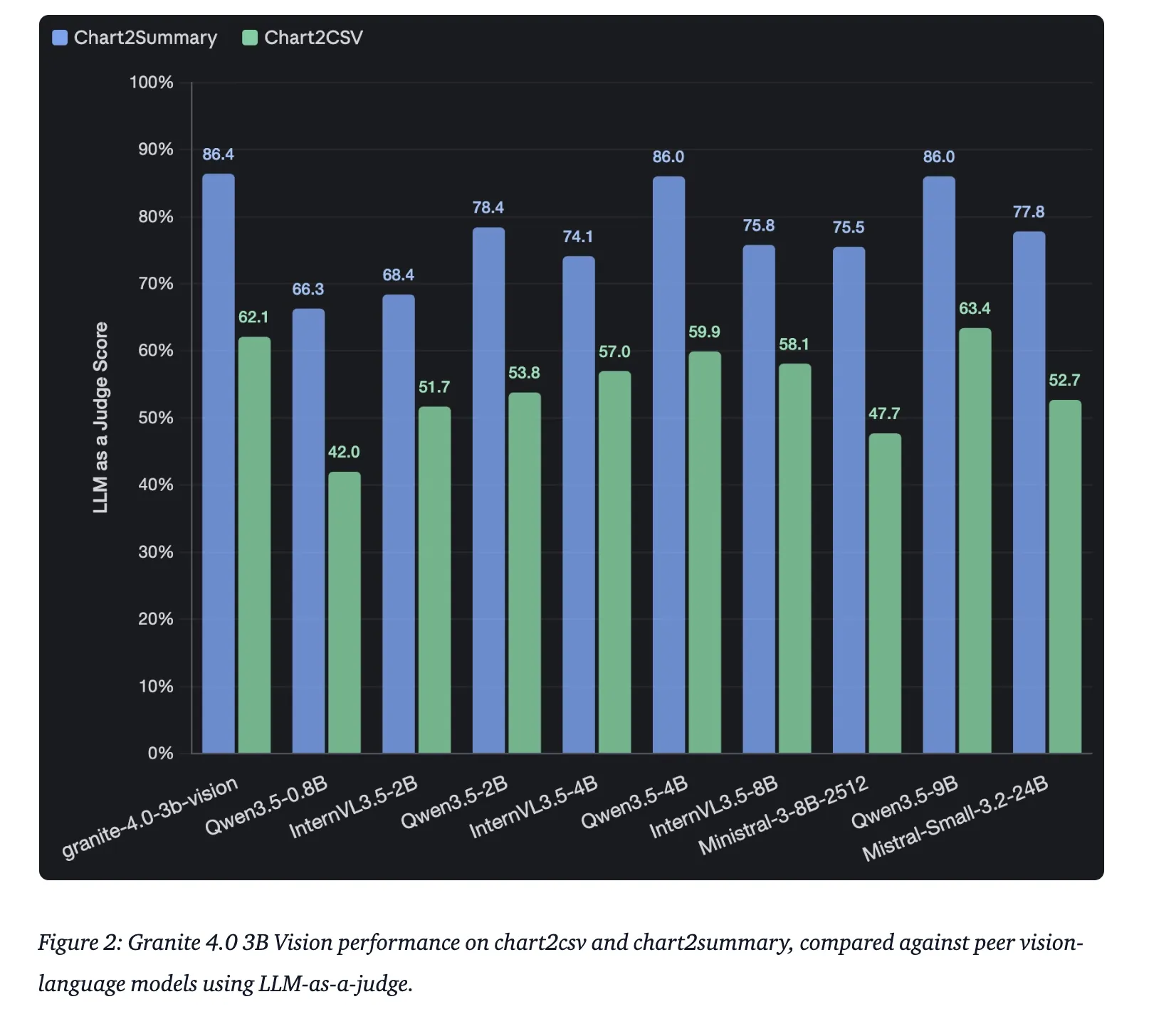
| Diagrammbegründung | ChartNet (vom Menschen verifizierter Testsatz) | Hohe Genauigkeit in Chart2Summary |
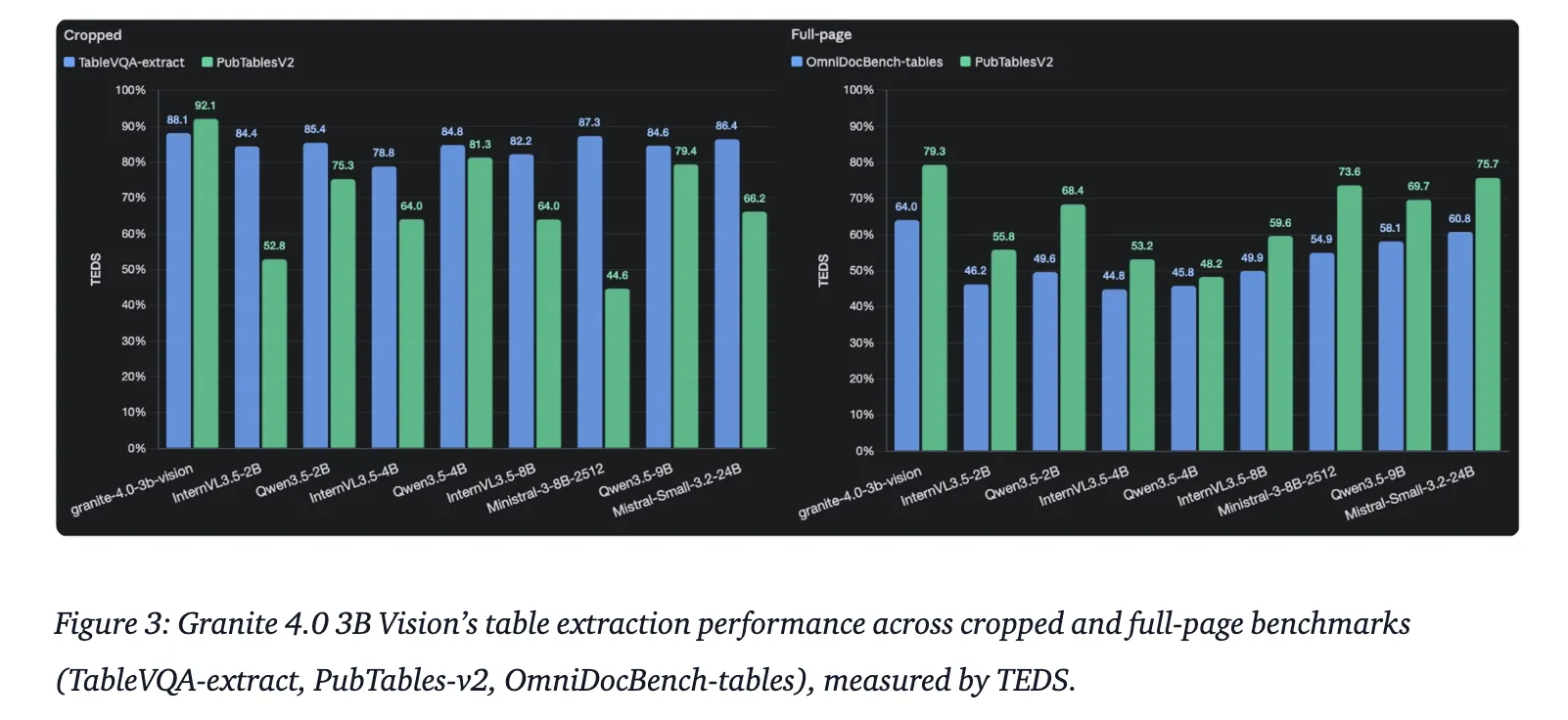
| Tabellenextraktion | TableVQA-Bench & OmniDocBench | Ausgewertet über TEDS und HTML-Extraktion |
Das Modell belegt derzeit den 3. Platz unter den Modellen in der Parameterklasse 2–4B auf der VAREX-Bestenliste (Stand März 2026) und demonstriert trotz seiner kompakten Größe seine Effizienz bei der strukturierten Extraktion.
Wichtige Erkenntnisse
- Modulare LoRA-Architektur: Das Modell ist ein 0,5-B-Parameter-LoRA-Adapter das funktioniert auf der Granit 4.0 Mikro (3,5B) Rückgrat. Dieses Design ermöglicht eine einzige Bereitstellung, um Nur-Textual content-Workloads effizient zu bewältigen und gleichzeitig Imaginative and prescient-Funktionen nur bei Bedarf zu aktivieren.
- Hochauflösende Kacheln: Nutzung der google/siglip2-so400m-patch16-384 Encoder verarbeitet das Modell Bilder, indem es sie kachelt 384×384 Patches Neben einer globalen verkleinerten Ansicht wird sichergestellt, dass feine Particulars in komplexen Dokumenten erhalten bleiben.
- DeepStack-Injektion: Um das Layoutbewusstsein zu verbessern, verwendet das Modell a DeepStack Ansatz mit 8 Einspritzpunkte. Dadurch werden semantische Merkmale an frühere Ebenen und räumliche Particulars an spätere Ebenen weitergeleitet, was für eine genaue Tabellen- und Diagrammextraktion von entscheidender Bedeutung ist.
- Spezialisierte Extraktionsschulung: Über das Befolgen allgemeiner Anweisungen hinaus wurde das Modell mithilfe von verfeinert ChartNet und eine „codegesteuerte“ Pipeline, die Plotcode, Bilder und Datentabellen ausrichtet, um dem Modell zu helfen, die Logik visueller Datenstrukturen zu verinnerlichen.
- Entwicklerbereite Integration: Die Veröffentlichung ist Apache 2.0 lizenziert und bietet native Unterstützung für vLLM (über eine benutzerdefinierte Modellimplementierung) und DoclingIBMs Device zum Konvertieren unstrukturierter PDFs in maschinenlesbares JSON oder HTML.
Schauen Sie sich das an Technische Particulars Und Modellgewicht. Sie können uns auch gerne weiter folgen Twitter und vergessen Sie nicht, bei uns mitzumachen 120.000+ ML SubReddit und Abonnieren Unser Publication. Warten! Bist du im Telegram? Jetzt können Sie uns auch per Telegram kontaktieren.