

# Einführung
Die meisten von Ihnen verwenden SQL-Fensterfunktionen, aber Sie kratzen nur an der Oberfläche – a ROW_NUMBER() hier, a SUM() OVER() Dort. Das wahre Potenzial der Fensterfunktionen zeigt sich, wenn man sie auf schwierigere Probleme anwendet. Ich werde Sie durch vier Muster führen, die Fensterfunktionen von ihrer nützlichsten Seite zeigen.

Bei den Beispielen handelt es sich allesamt um echte Interviewfragen, die Sie üben können StrataScratch.
# Laufende Gesamtsummen
Die Berechnung laufender Summen ist eine der häufigsten Geschäftsanwendungen von Fensterfunktionen. Die Finanzleute lieben es absolut! Es wird verwendet, um den kumulierten monatlichen Umsatz zu verfolgen, der dann problemlos in die Berechnung Ihres aktuellen Stands im Vergleich zum jährlichen Umsatzziel einfließt.
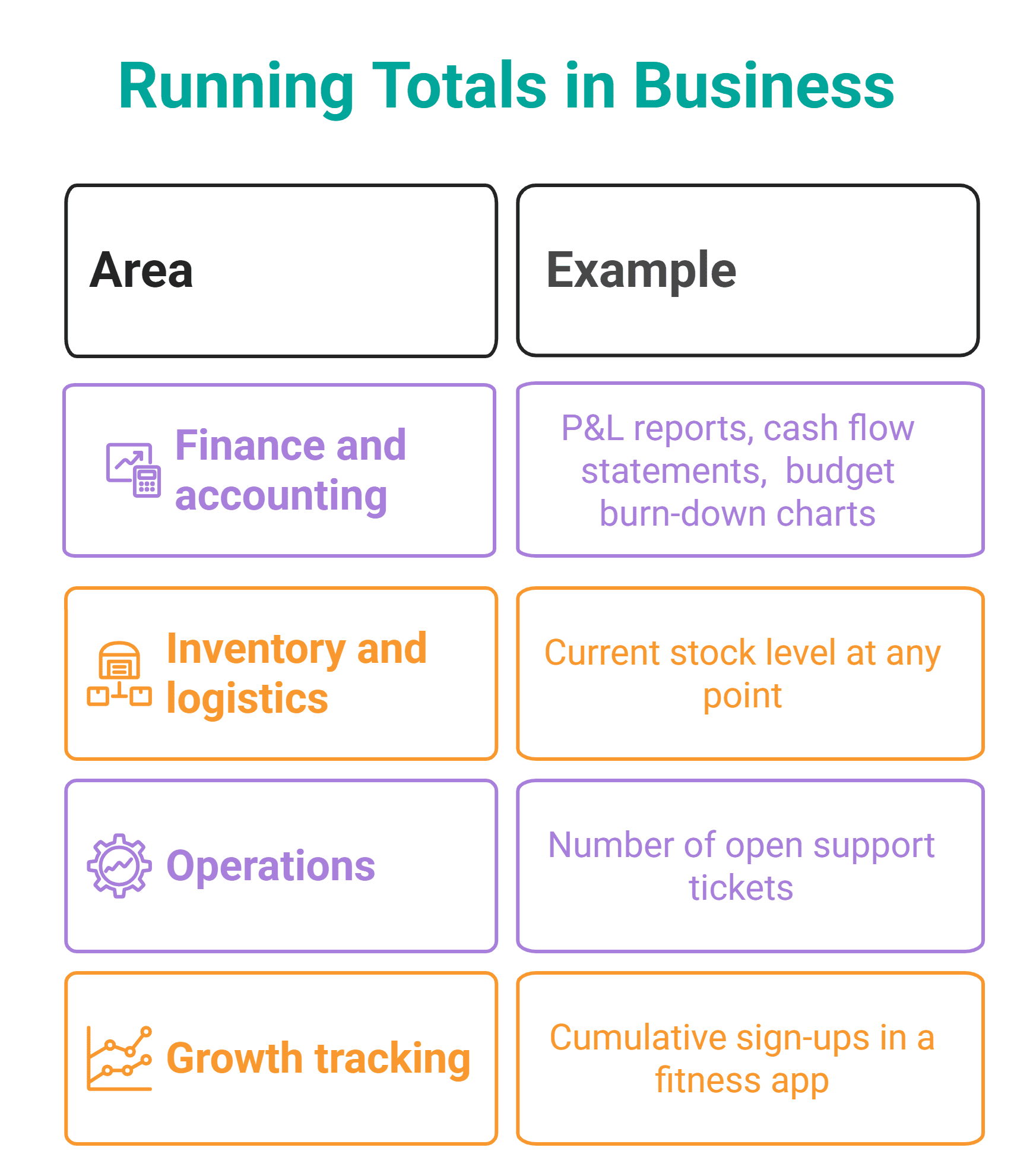
Was dieses Downside zu einem Fensterfunktionsproblem macht, ist, dass Sie normalerweise sowohl den Wert professional Periode als auch die kumulierte Summe in dieselbe Ausgabe einbeziehen sollten. Du kannst es nicht verwenden GROUP BY mit SUM()weil dadurch einzelne Zeilen ausgeblendet werden. Die offensichtliche Lösung ist additionally die Verwendung einer Fensterfunktion, d. h. SUM() OVER().
// Beispiel: Berechnung des Umsatzes im Zeitverlauf
Diese Amazon-Frage fordert Sie ursprünglich auf, den gleitenden 3-Monats-Durchschnitt zu berechnen. Wir ignorieren dies jedoch und berechnen den kumulierten Umsatz für jeden Monat.
Daten: Hier ist die amazon_purchases Tabellenvorschau.
| Benutzer-ID | erstellt_at | Purchase_amt |
|---|---|---|
| 10 | 01.01.2020 | 3742 |
| 11 | 04.01.2020 | 1290 |
| 12 | 07.01.2020 | 4249 |
| … | … | … |
| 109 | 24.10.2020 | 1749 |
Code: Die innere Abfrage wandelt Datumsangaben in um YYYY-MM formatieren mit TO_CHAR() und aggregiert die monatlichen Einnahmen und filtert die Renditen heraus WHERE purchase_amt > 0.
Die äußere Abfrage wendet die Fensterfunktion auf die von uns berechneten Monatssummen an. Ich gebe (absichtlich) keine explizite Rahmenklausel an OVER()daher ist die Fensterfunktion standardmäßig auf RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW. Das bedeutet, dass das Fenster alle Zeilen enthält, die der aktuellen Zeile, additionally dem Monat, vorangehen. Mit anderen Worten, die kumulierte Summe beträgt: alle vorherigen Monate + der aktuelle Monat. Das überrascht nicht Ist eine Lehrbuchdefinition einer kumulativen Summe.
SELECT t.month,
t.monthly_revenue,
SUM(t.monthly_revenue) OVER(ORDER BY t.month) AS cumulative_revenue
FROM (
SELECT TO_CHAR(created_at::DATE, 'YYYY-MM') AS month,
SUM(purchase_amt) AS monthly_revenue
FROM amazon_purchases
WHERE purchase_amt > 0
GROUP BY TO_CHAR(created_at::date, 'YYYY-MM')
ORDER BY TO_CHAR(created_at::date, 'YYYY-MM')
) t
ORDER BY t.month ASC;Ausgabe:
| Monat | monatlicher_Umsatz | kumulierter_Umsatz |
|---|---|---|
| 2020-01 | 26292 | 26292 |
| 2020-02 | 20695 | 46987 |
| 2020-03 | 29620 | 76607 |
| … | … | … |
| 2020-10 | 15310 | 239869 |
# Lücken und Inseln (Sessionisierung)
Auch dieses Muster umfasst sequenzielle Daten, genau wie laufende Summen, verwendet jedoch andere Fensterfunktionen.
Ein Insel ist eine Reihe von Zeilen mit derselben Bedingungz. B. aufeinanderfolgende tägliche Anmeldungen. A Lücke ist der Raum zwischen Inseln.
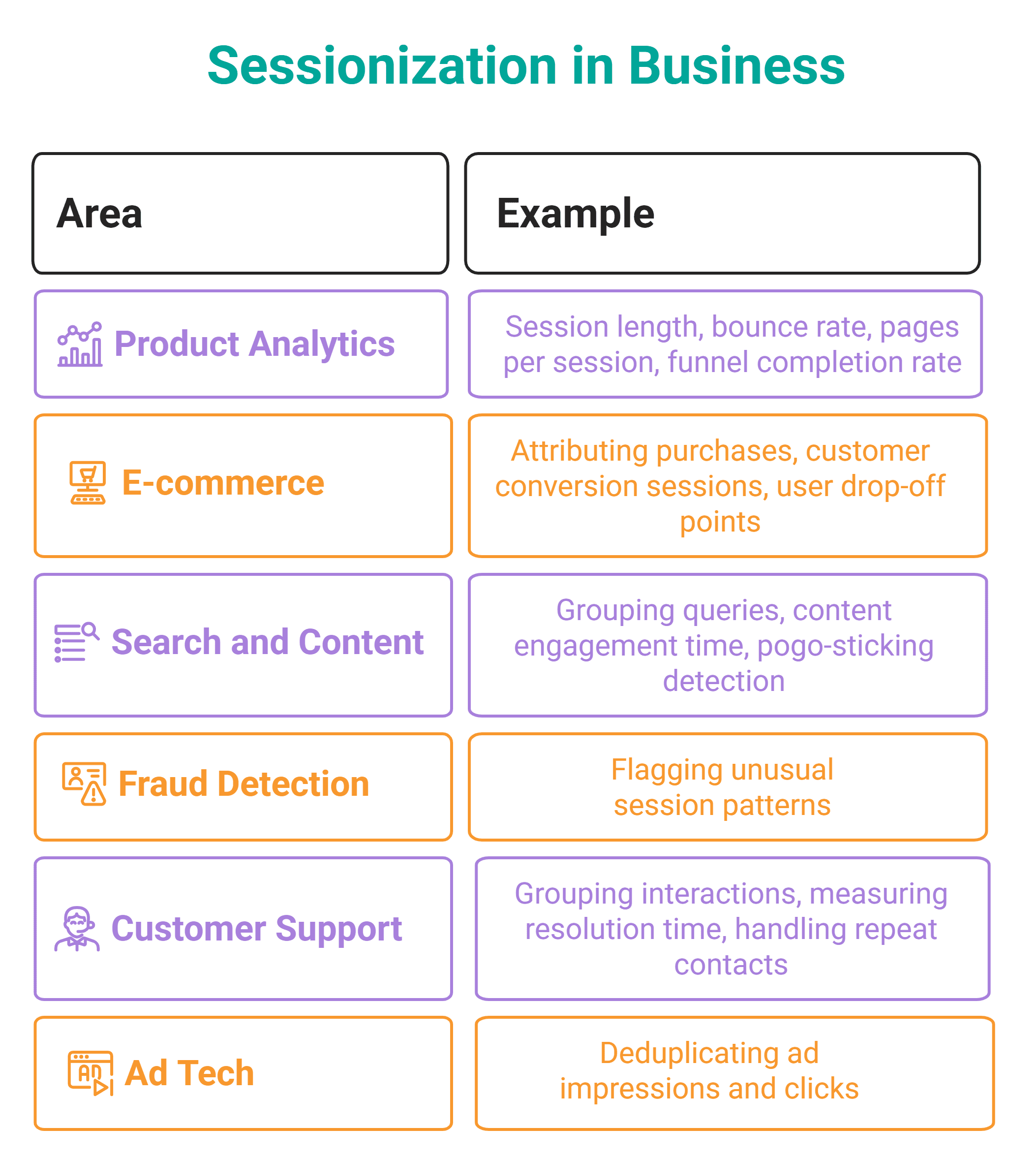
Eine der häufigsten realen Anwendungen dieses Musters ist Sessionisierung – Gruppieren eines rohen Ereignisstroms in Sitzungen. Eine Sitzung wird normalerweise als definiert Abfolge von Ereignissen desselben Benutzers, bei der keine Lücke zwischen aufeinanderfolgenden Ereignissen eine gewisse Zeitüberschreitung überschreitet (30 Minuten ist der Webanalysestandard).
Sessionisierung wird häufig angewendet in Produkt- und Datenentwicklung. Es wird überall dort eingesetzt, wo Sie rohe Ereignisströme in sinnvolle Aktivitätseinheiten gruppieren müssen.
Die klassische Erkennung in SQL besteht aus zwei Schritten:
LAG()oderLEAD()– um jede Zeile mit der davor oder danach zu vergleichen und zu markieren, wo ein neuer Streak beginnt.SUM(flag) OVER (PARTITION BY consumer ORDER BY date)– um Flags in einer Streak-ID zu sammeln, da diese innerhalb eines Streaks flach bleibt und an jeder Grenze erhöht wird.
// Beispiel: Consumer Streaks finden
Der Frage aus LinkedIn- und Meta-Interviews fordert Sie auf, bis zum 10. August 2022 die drei besten Benutzer mit der längsten Plattformbesuchssträhne zu finden. Sie sollten alle Benutzer mit den drei längsten Streaks ausgeben, wenn es mehr als einen Benutzer professional Streaklänge gibt.
Daten: Der Tisch ist user_streaks.
| Benutzer-ID | date_visited |
|---|---|
| u001 | 01.08.2022 |
| u001 | 01.08.2022 |
| u004 | 01.08.2022 |
| … | … |
| u005 | 11.08.2022 |
Code: Die Abfrage ist lang, aber sauber in CTEs gegliedert, sodass sie leicht zu verstehen ist.
unique_visits: Entfernt doppelte Besuchsdatensätze und begrenzt die Daten auf den 10. August 2022.streak_flags: VerwendungenLAG()um das vorherige Besuchsdatum professional Benutzer abzurufen und die Zeile als zu kennzeichnen0(eine Streak-Fortsetzung, wenn die Lücke 1 Tag beträgt) oder1(ein neuer Streak-Begin für jede andere Lücke).streak_ids: Wandelt Flags mithilfe einer kumulativen Summe in Streak-Gruppen-IDs umSUM().streak_lengths: Zählt Tage professional Streak.longest_per_user: Behält nur den längsten Streak jedes Benutzers.ranked_lengths: Ordnet unterschiedliche Streifenlängen ein.top_lengths: Findet die drei besten Streifenlängenwerte.
Das Finale SELECT verbindet alles: Es zeigt alle Benutzer mit den drei besten Streaks und ihrer jeweiligen Streak-Länge in Tagen.
WITH unique_visits AS (
SELECT DISTINCT user_id, date_visited
FROM user_streaks
WHERE date_visited <= DATE '2022-08-10'),
streak_flags AS (
SELECT *,
CASE
WHEN date_visited
- LAG(date_visited) OVER (PARTITION BY user_id ORDER BY date_visited) = 1
THEN 0
ELSE 1
END AS new_streak
FROM unique_visits),
streak_ids AS (
SELECT *,
SUM(new_streak) OVER (PARTITION BY user_id ORDER BY date_visited) AS streak_id
FROM streak_flags),
streak_lengths AS (
SELECT user_id,
streak_id,
COUNT(*) AS streak_length
FROM streak_ids
GROUP BY user_id, streak_id),
longest_per_user AS (
SELECT user_id,
MAX(streak_length) AS streak_length
FROM streak_lengths
GROUP BY user_id),
ranked_lengths AS (
SELECT DISTINCT
streak_length,
DENSE_RANK() OVER (ORDER BY streak_length DESC) AS len_rank
FROM longest_per_user),
top_lengths AS (
SELECT streak_length
FROM ranked_lengths
WHERE len_rank <= 3)
SELECT u.user_id,
u.streak_length
FROM longest_per_user u
JOIN top_lengths t USING (streak_length)
ORDER BY u.streak_length DESC, u.user_id;Ausgabe:
| Benutzer-ID | streak_length |
|---|---|
| u004 | 10 |
| u005 | 10 |
| u003 | 5 |
| u001 | 4 |
| u006 | 4 |
# Kohortenanalyse
A Kohorte ist eine Gruppe von Benutzern, die ein Startereignis teilenzum Beispiel ein erster Kauf, eine erste Anmeldung oder ein erstes Abonnementdatum. Das Analysieren von Kohorten ist das Grundlage des Retention-Reportingsda es die Frage beantwortet wie viele Benutzer nach der Startveranstaltung zurückgekommen sind.
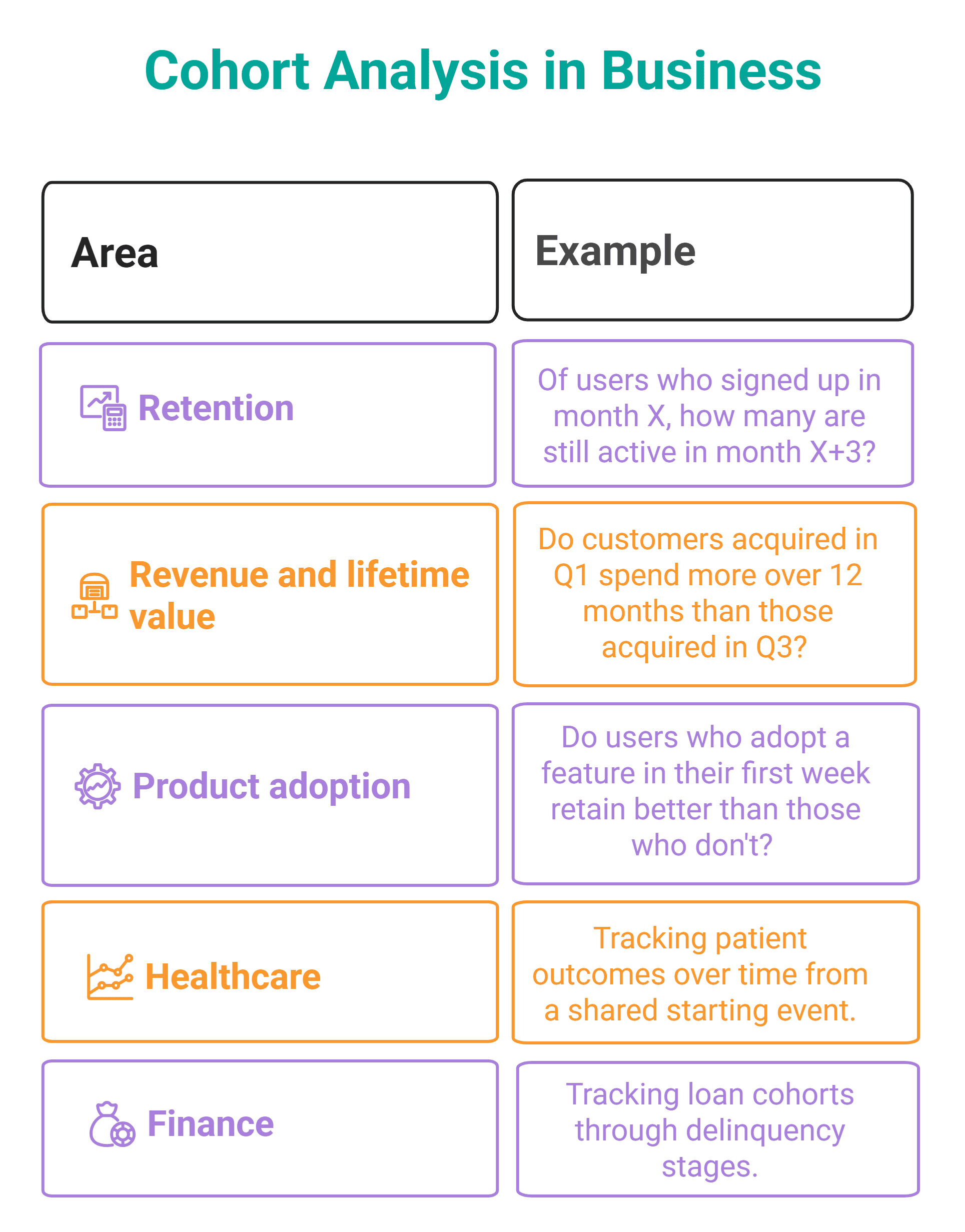
Das Wichtigste bei der Kohortenanalyse ist das Finden Kohortenanker im Aktivitätsverlauf des Benutzers, sodass Sie alle nachfolgenden Aktivitäten daran messen können.
Dies lässt sich in SQL auf drei Hauptansätze für Fensterfunktionen reduzieren:
MIN(event_time) OVER (PARTITION BY user_id)– das häufigste Muster, wenn der Anker ein Datum ist.FIRST_VALUE(attribute) OVER (PARTITION BY user_id ORDER BY event_time)– wird verwendet, wenn Sie den Ankerwert selbst benötigen, z. B. den ersten Händler oder die erste Produktkategorie.ROW_NUMBER() OVER (PARTITION BY user_id ORDER BY event_time) = 1– Wird verwendet, wenn Sie das erste Ereignis als separate Zeile isolieren und wieder mit dem gesamten Verlauf verbinden möchten, anstatt es über alle Zeilen zu übertragen.
// Beispiel: Erstbestellungen zählen
Hier ist ein DoorDash-Frage. Dazu müssen Sie die Anzahl der Bestellungen und Erstbestellungen (aus Kundensicht) für jeden Händler berechnen. Sie sollten auch Händler ausschließen, die keine Bestellungen erhalten haben.
Daten: Die erste Tabelle wird benannt order_details.
| Ausweis | customer_id | Merchant_ID | order_timestamp | n_items | total_amount_earned |
|---|---|---|---|---|---|
| 8 | 1049 | 6 | 2022-01-14 01:00:28 | 5 | 16.3 |
| 7 | 1049 | 5 | 2022-01-14 11:50:29 | 4 | 2.16 |
| 22 | 1049 | 1 | 2022-01-14 22:46:54 | 8 | 2,63 |
| … | … | … | … | … | … |
| 39 | 1060 | 1 | 2022-01-16 22:27:30 | 11 | 15.41 |
Die zweite Tabelle ist merchant_details.
| Ausweis | Identify | Kategorie | PLZ |
|---|---|---|---|
| 1 | Baumhauspizza | amerikanisch | 92507 |
| 2 | Thailändischer Löwe | asiatisch | 90017 |
| 3 | Mahlzeit Rabe | Fastfood | 95204 |
| … | … | … | … |
| 7 | Geschmack von Gyros | Mittelmeer | 94789 |
Code: Im ersten CTE findet die Kohortenlogik statt. Ich benutze das FIRST_VALUE() Fensterfunktion, um den Händler von der frühesten Bestellung jedes Kunden an jede Zeile in seiner Bestellhistorie anzuhängen. Das Ergebnis ist eine Tabelle, in der jede Bestellung mit der Angabe versehen ist, bei welchem Händler der Kunde angefangen hat.
Im zweiten CTE verbinde ich die Etiketten mit a wieder mit der vollständigen Bestellhistorie LEFT JOIN um sicherzustellen, dass Händler, die Bestellungen erhalten haben, aber nie der erste Händler von irgendjemandem waren, trotzdem im Ergebnis erscheinen. Wir verwenden COUNT() Und DISTINCT Nur die Kunden zu zählen, für die dieser Händler der erste struggle – das ist Ihre Kohortengröße. Mit einem anderen COUNT()erhalten Sie die Gesamtzahl der Bestellungen. DISTINCT ist auch hier erforderlich, da die LEFT JOIN mit first_order kann doppelte Bestellzeilen erzeugen – seitdem first_order Behält eine Zeile professional Bestellung (nicht professional Kunde), eine einzelne Bestellung in order_details kann mit mehreren Zeilen in übereinstimmen first_order für denselben Kunden, wobei die Anzahl ohne diesen erhöht wird.
Im Finale SELECTwir schließen uns dem an number_of_customers CTE mit merchant_details die Händlernamen einzubringen.
WITH first_order AS (
SELECT customer_id,
FIRST_VALUE(merchant_id) OVER(PARTITION BY customer_id ORDER BY order_timestamp) AS first_merchant
FROM order_details),
number_of_customers AS (
SELECT merchant_id,
COUNT(DISTINCT f.customer_id) AS first_time_orders,
COUNT(DISTINCT id) AS total_number_of_orders
FROM order_details d
LEFT JOIN first_order f ON d.merchant_id = f.first_merchant
GROUP BY 1)
SELECT identify,
total_number_of_orders,
first_time_orders
FROM number_of_customers
JOIN merchant_details ON number_of_customers.merchant_id = merchant_details.id;Ausgabe:
| Identify | total_number_of_orders | erste_malige_Bestellungen |
|---|---|---|
| Baumhauspizza | 8 | 1 |
| Thailändischer Löwe | 14 | 7 |
| Mahlzeit Rabe | 12 | 0 |
| Burger A1 | 4 | 0 |
| Sushi-Bucht | 7 | 3 |
| Tacos Sie | 7 | 1 |
# Perzentil- und Rankinganalyse
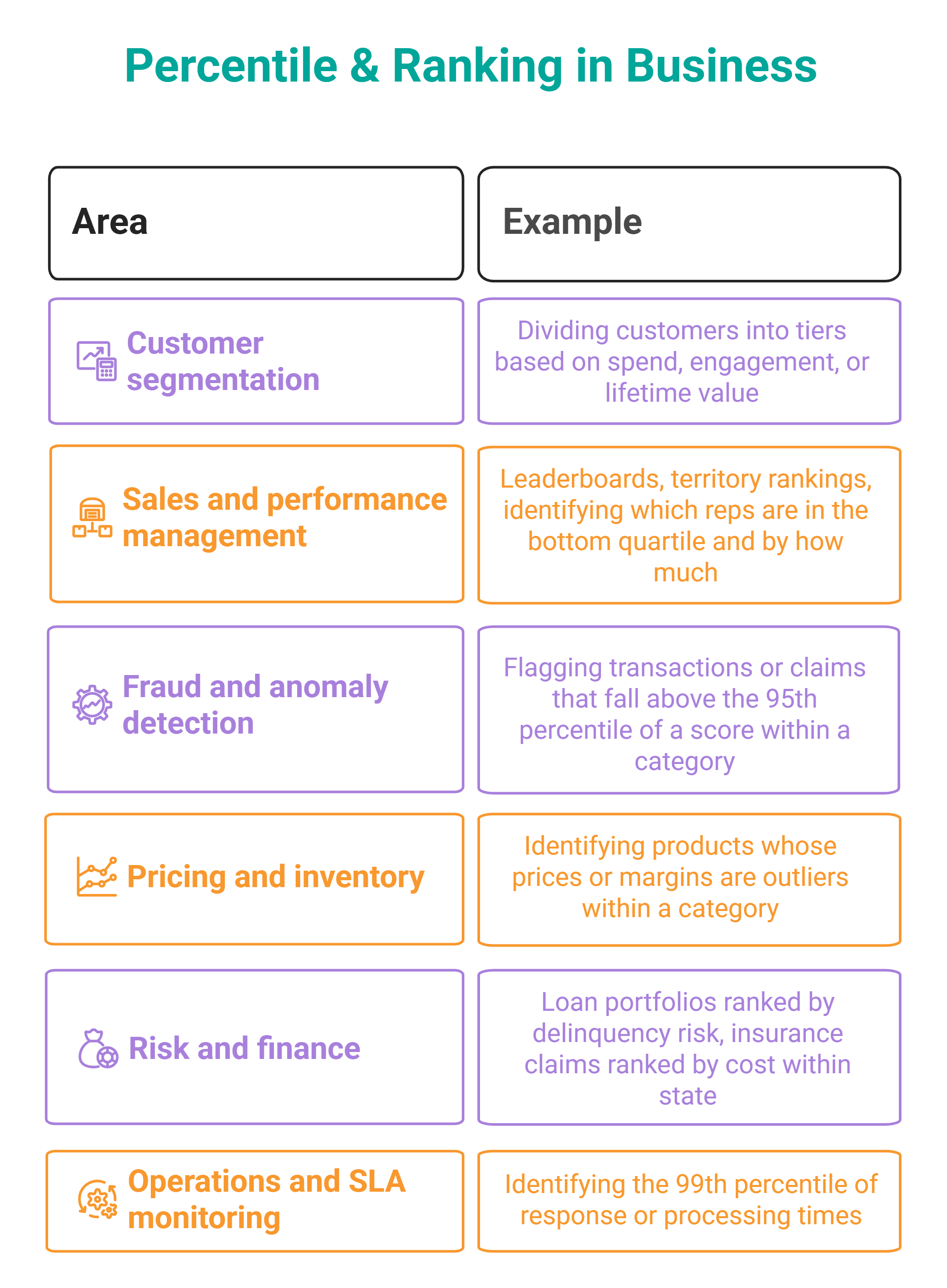
Aggregatfunktionen geben Ihnen den Durchschnitt an. Fensterbasierte Rating-Funktionen informieren Sie über die Verteilung, und in Verteilungen finden sich die interessanten Geschäftsfragen. Ist Ihr Bestellwert im 90. Perzentil ungewöhnlich hoch, was darauf hindeutet, dass einige große Käufer den Umsatz verzerren? Befinden sich die unteren 25 % der Vertriebsmitarbeiter in der Nähe des Medianwerts oder weit darunter?
NTILE(n) unterteilt Zeilen in n ungefähr gleiche Eimer. PERCENT_RANK() drückt den Rang jeder Zeile als Wert zwischen 0 und 1 aus. CUME_DIST() Gibt an, welcher Bruchteil der Zeilen einen Wert hat, der kleiner oder gleich der aktuellen Zeile ist. Und PERCENTILE_CONT() Berechnet den tatsächlichen Wert bei einem bestimmten Perzentilschwellenwert – nützlich, wenn Sie auf der Grundlage eines dynamischen Cutoffs und nicht auf der Grundlage einer Rangfolge innerhalb einer Ergebnismenge filtern möchten.
// Beispiel: Identifizieren von Betrug im höchsten Perzentilbereich
Hier ist eines von Google und Netflix. Sie möchten, dass Sie die verdächtigsten Ansprüche in jedem Bundesstaat identifizieren. Es wird davon ausgegangen, dass die obersten 5 % der Ansprüche in jedem Bundesstaat potenziell betrügerisch sind.
Daten: Die Tabelle ist benannt fraud_score.
| Richtliniennummer | Zustand | Claim_cost | betrug_score |
|---|---|---|---|
| ABCD1001 | CA | 4113 | 0,61 |
| ABCD1002 | CA | 3946 | 0,16 |
| ABCD1003 | CA | 4335 | 0,01 |
| … | … | … | … |
| ABCD1400 | TX | 3922 | 0,59 |
Code: Im Code, PERCENTILE_CONT(0.95) berechnet den interpolierten Wert am 95. Perzentil der Betrugswerte in jedem Bundesstaat.
Im Folgenden SELECT In der Anweisung wird der CTE mit der Originaltabelle verknüpft, sodass jeder Anspruch mit dem Schwellenwert für seinen eigenen Bundesstaat verglichen werden kann. Ansprüche in Höhe oder über diesem Wert werden gekürzt.
WITH state_percentiles AS (
SELECT state,
PERCENTILE_CONT(0.95) WITHIN GROUP (ORDER BY fraud_score) AS p95
FROM fraud_score
GROUP BY state)
SELECT f.policy_num,
f.state,
f.claim_cost,
f.fraud_score
FROM fraud_score f
JOIN state_percentiles sp
ON f.state = sp.state
WHERE f.fraud_score >= sp.p95;Ausgabe:
| Richtliniennummer | Zustand | Claim_cost | betrug_score |
|---|---|---|---|
| ABCD1016 | CA | 1639 | 0,96 |
| ABCD1021 | CA | 4898 | 0,95 |
| ABCD1027 | CA | 2663 | 0,99 |
| … | … | … | … |
| ABCD1398 | TX | 3191 | 0,98 |
# Abschluss
Diese vier Muster haben eine gemeinsame Philosophie: Erledigen Sie die Arbeit in der Datenbank möglichst in einem einzigen Durchgang und nutzen Sie dabei die volle Ausdruckskraft der SQL-Fensterspezifikation.
Was Fensterfunktionen wirklich leistungsstark macht, ist nicht eine einzelne Funktion für sich. Es ist die Zusammensetzbarkeit: Sie können CTEs verketten und mehrere Fensterfunktionen gleichzeitig anwenden SELECTund erstellen Sie eine komplexe analytische Logik, die sich quick wie eine Beschreibung des Geschäftsproblems selbst liest.
Nate Rosidi ist Datenwissenschaftler und in der Produktstrategie tätig. Er ist außerdem außerordentlicher Professor für Analytik und Gründer von StrataScratch, einer Plattform, die Datenwissenschaftlern hilft, sich mit echten Interviewfragen von Prime-Unternehmen auf ihre Interviews vorzubereiten. Nate schreibt über die neuesten Tendencies auf dem Karrieremarkt, gibt Ratschläge zu Vorstellungsgesprächen, stellt Knowledge-Science-Projekte vor und behandelt alles rund um SQL.