

Bild vom Autor
SQLite ist ein leichtes, serverloses relationales Datenbankmanagementsystem (RDBMS), das aufgrund seiner Einfachheit und der einfachen Einbettung in Anwendungen weit verbreitet ist.
Egal, ob Sie eine kleine Anwendung erstellen, Daten lokal verwalten oder einen Projektprototyp erstellen, SQLite bietet eine praktische Lösung zum Speichern und Abfragen strukturierter Daten. In diesem Tutorial erfahren Sie, wie Sie mit SQLite-Datenbanken von Python aus arbeiten, indem Sie die integrierte SQLite3-Modul.
Insbesondere erfahren Sie, wie Sie von Python aus eine Verbindung zu einer SQLite-Datenbank herstellen und grundlegende CRUD-Operationen durchführen. Lassen Sie uns beginnen.
Einrichten der Umgebung
Erstellen Sie als ersten Schritt eine dedizierte virtuelle Umgebung für Ihr Projekt (im Projektverzeichnis) und aktivieren Sie diese. Sie können dies mit dem integrierten venv-Modul wie folgt tun:
$ python3 -m venv v1
$ supply v1/bin/activate
In diesem Tutorial verwenden wir Schwindler um synthetische Datensätze zu generieren. Installieren Sie es additionally mit pip:
Das sqlite3-Modul ist in die Python-Standardbibliothek integriert, Sie müssen es additionally nicht installieren. Wenn Sie Faker installiert haben und eine aktuelle Model von Python verwenden, können Sie loslegen!
Herstellen einer Verbindung zu einer SQLite-Datenbank
Erstellen Sie im Projektverzeichnis ein Python-Skript und legen Sie los. Als ersten Schritt zur Interaktion mit der Datenbank sollten wir eine Verbindung mit der Datenbank herstellen.
Um eine Verbindung zu einer Beispieldatenbank instance.db herzustellen, können Sie den join() Funktion aus dem SQLite3-Modul wie folgt:
conn = sqlite3.join(‘instance.db’)Wenn die Datenbank bereits existiert, wird eine Verbindung zu ihr hergestellt. Andernfalls wird die Datenbank im Arbeitsverzeichnis erstellt.
Nachdem wir eine Verbindung zur Datenbank hergestellt haben, erstellen wir einen Datenbankcursor, der uns beim Ausführen von Abfragen hilft. Das Cursorobjekt verfügt über Methoden zum Ausführen von Abfragen und Abrufen der Abfrageergebnisse. Es funktioniert sehr ähnlich wie ein Dateihandler.
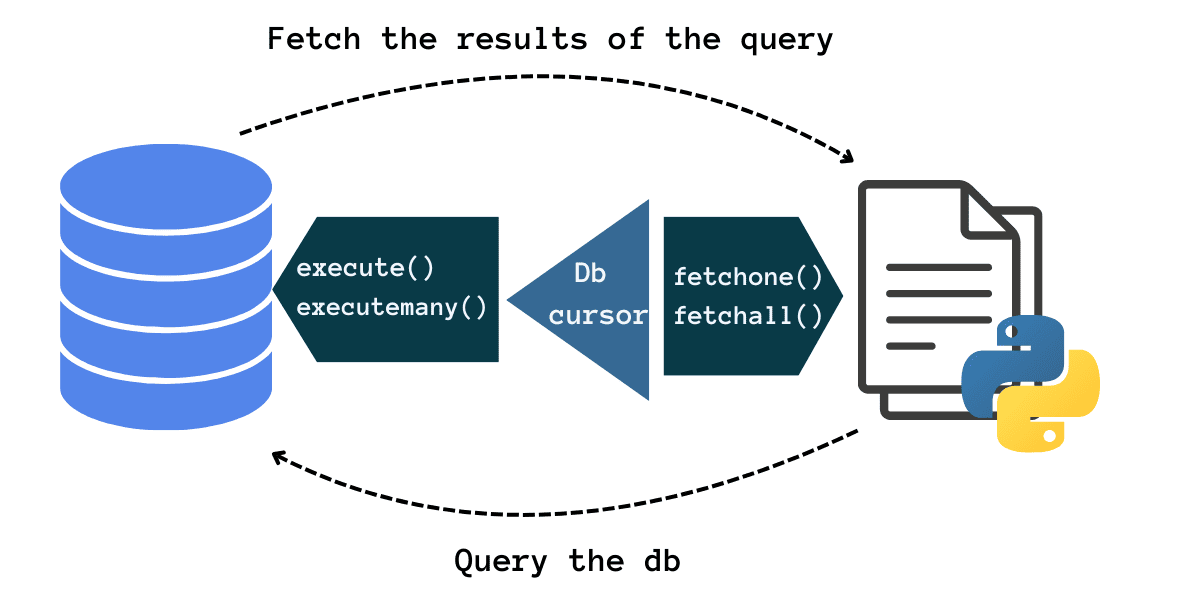
Datenbank-Cursor | Bild vom Autor
Es ist oft hilfreich, die Verbindung als Kontextmanager in einer with-Anweisung wie folgt zu verwenden:
import sqlite3
# Connect with the db
with sqlite3.join('instance.db') as conn:
# create db cursor
# run queries
# commit adjustments
Auf diese Weise müssen Sie sich nicht um das Schließen des Verbindungsobjekts kümmern. Die Verbindung wird automatisch geschlossen, wenn die Ausführung den with-Block verlässt. Wir werden die Cursorobjekte in diesem Tutorial jedoch explizit schließen.
Erstellen von Datenbanktabellen
Erstellen wir nun ein prospects Tabelle mit den erforderlichen Feldern in der Datenbank. Dazu erstellen wir zunächst ein Cursorobjekt. Anschließend führen wir eine CREATE TABLE-Anweisung aus und übergeben die Abfragezeichenfolge an den execute() Für das Cursorobjekt aufgerufene Methode:
import sqlite3
# Connect with the db
with sqlite3.join('instance.db') as conn:
cursor = conn.cursor()
# Create prospects desk
cursor.execute('''
CREATE TABLE IF NOT EXISTS prospects (
id INTEGER PRIMARY KEY,
first_name TEXT NOT NULL,
last_name TEXT NOT NULL,
e mail TEXT UNIQUE NOT NULL,
telephone TEXT,
num_orders INTEGER
);
''')
conn.commit()
print("Clients desk created efficiently.")
cursor.shut()
Wenn Sie das Skript ausführen, sollten Sie die folgende Ausgabe sehen:
Output >>>
Clients desk created efficiently.
Durchführen von CRUD-Operationen
Lassen Sie uns einige grundlegende CRUD-Operationen an der Datenbanktabelle durchführen. Wenn Sie möchten, können Sie für jede Operation separate Skripts erstellen.
Einfügen von Datensätzen
Nun fügen wir einige Datensätze in die prospects Tabelle. Wir verwenden Faker, um synthetische Datensätze zu generieren. Damit die Ausgaben lesbar bleiben, habe ich nur 10 Datensätze eingefügt. Sie können jedoch so viele Datensätze einfügen, wie Sie möchten.
import sqlite3
import random
from faker import Faker
# Initialize Faker object
faux = Faker()
Faker.seed(24)
# Connect with the db
with sqlite3.join('instance.db') as conn:
cursor = conn.cursor()
# Insert buyer data
num_records = 10
for _ in vary(num_records):
first_name = faux.first_name()
last_name = faux.last_name()
e mail = faux.e mail()
telephone = faux.phone_number()
num_orders = random.randint(0,100)
cursor.execute('''
INSERT INTO prospects (first_name, last_name, e mail, telephone, num_orders)
VALUES (?, ?, ?, ?, ?)
''', (first_name, last_name, e mail, telephone, num_orders))
print(f"{num_records} buyer data inserted efficiently.")
conn.commit()
cursor.shut()
Beachten Sie, wie wir parametrisierte Abfragen verwenden: Anstatt die Werte in der INSERT-Anweisung fest zu codieren, verwenden wir ?-Platzhalter und übergeben ein Tupel von Werten.
Das Ausführen des Skripts sollte Folgendes ergeben:
Output >>>
10 buyer data inserted efficiently.
Lesen und Aktualisieren von Datensätzen
Nachdem wir nun Datensätze in die Tabelle eingefügt haben, führen wir eine Abfrage aus, um alle Datensätze einzulesen. Beachten Sie, wie wir das execute() Methode zum Ausführen von Abfragen und die fetchall() Methode auf dem Cursor, um die Ergebnisse der Abfrage abzurufen.
Da wir die Ergebnisse der vorherigen Abfrage in `all_customers` gespeichert haben, führen wir auch eine UPDATE-Abfrage aus, um die num_orders entsprechend der ID 1. Hier ist der Codeausschnitt:
import sqlite3
# Connect with the db
with sqlite3.join('instance.db') as conn:
cursor = conn.cursor()
# Fetch and show all prospects
cursor.execute('SELECT id, first_name, last_name, e mail, num_orders FROM prospects')
all_customers = cursor.fetchall()
print("All Clients:")
for buyer in all_customers:
print(buyer)
# Replace num_orders for a particular buyer
if all_customers:
customer_id = all_customers(0)(0) # Take the ID of the primary buyer
new_num_orders = all_customers(0)(4) + 1 # Increment num_orders by 1
cursor.execute('''
UPDATE prospects
SET num_orders = ?
WHERE id = ?
''', (new_num_orders, customer_id))
print(f"Orders up to date for buyer ID {customer_id}: now has {new_num_orders} orders.")
conn.commit()
cursor.shut()
Dadurch werden sowohl die Datensätze als auch die Meldung nach der Replace-Abfrage ausgegeben:
Output >>>
All Clients:
(1, 'Jennifer', 'Franco', 'jefferyjackson@instance.org', 54)
(2, 'Grace', 'King', 'erinhorne@instance.org', 43)
(3, 'Lori', 'Braun', 'joseph43@instance.org', 99)
(4, 'Wendy', 'Hubbard', 'christophertaylor@instance.com', 11)
(5, 'Morgan', 'Wright', 'arthur75@instance.com', 4)
(6, 'Juan', 'Watson', 'matthewmeadows@instance.web', 51)
(7, 'Randy', 'Smith', 'kmcguire@instance.org', 32)
(8, 'Jimmy', 'Johnson', 'vwilliams@instance.com', 64)
(9, 'Gina', 'Ellison', 'awong@instance.web', 85)
(10, 'Cory', 'Joyce', 'samanthamurray@instance.org', 41)
Orders up to date for buyer ID 1: now has 55 orders.
Löschen von Datensätzen
Um einen Kunden mit einer bestimmten Kunden-ID zu löschen, führen wir eine DELETE-Anweisung wie gezeigt aus:
import sqlite3
# Specify the client ID of the client to delete
cid_to_delete = 3
with sqlite3.join('instance.db') as conn:
cursor = conn.cursor()
# Execute DELETE assertion to take away the client with the desired ID
cursor.execute('''
DELETE FROM prospects
WHERE id = ?
''', (cid_to_delete,))
conn.commit()
f"Buyer with ID {cid_to_delete} deleted efficiently.")
cursor.shut()
Dies gibt aus:
Buyer with ID 3 deleted efficiently.
Filtern von Datensätzen mithilfe der WHERE-Klausel
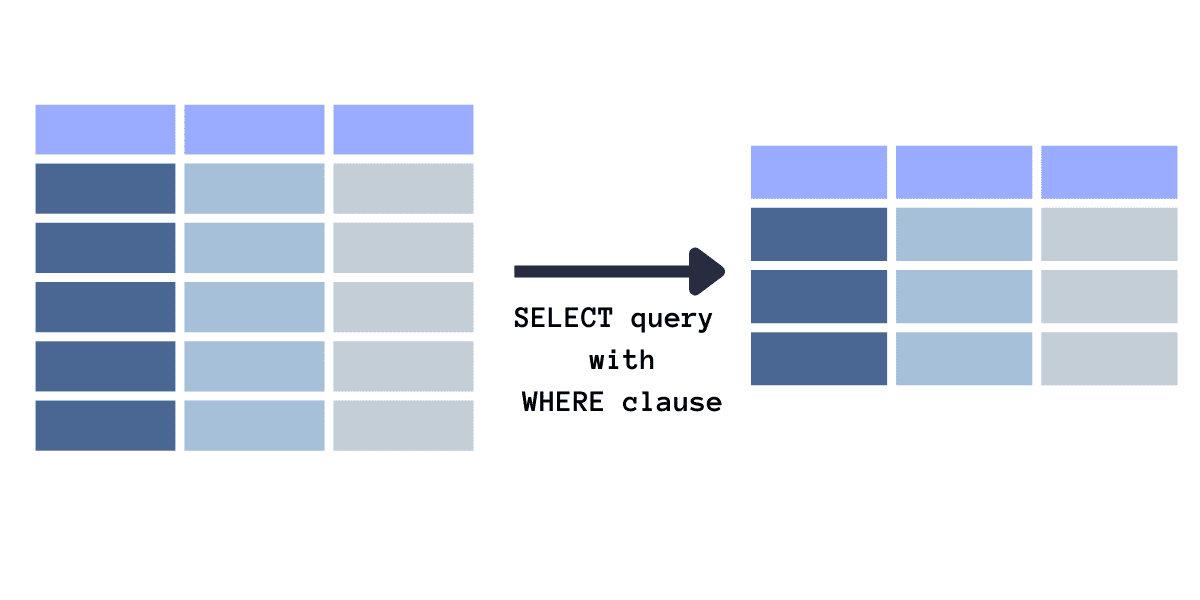
Bild vom Autor
Angenommen, wir möchten Datensätze von Kunden abrufen, die weniger als 10 Bestellungen aufgegeben haben, beispielsweise um gezielte Kampagnen durchzuführen oder Ähnliches. Dazu führen wir eine SELECT-Abfrage mit der WHERE-Klausel aus, die die Bedingung für die Filterung angibt (in diesem Fall die Anzahl der Bestellungen). So können Sie dies erreichen:
import sqlite3
# Outline the brink for the variety of orders
order_threshold = 10
with sqlite3.join('instance.db') as conn:
cursor = conn.cursor()
# Fetch prospects with lower than 10 orders
cursor.execute('''
SELECT id, first_name, last_name, e mail, num_orders
FROM prospects
WHERE num_orders < ?
''', (order_threshold,))
# Fetch all matching prospects
filtered_customers = cursor.fetchall()
# Show filtered prospects
if filtered_customers:
print("Clients with lower than 10 orders:")
for buyer in filtered_customers:
print(buyer)
else:
print("No prospects discovered with lower than 10 orders.")
Und hier ist die Ausgabe:
Output >>>
Clients with lower than 10 orders:
(5, 'Morgan', 'Wright', 'arthur75@instance.com', 4)
Einpacken
Und das struggle’s! Dies struggle eine Anleitung für den Einstieg in SQLite mit Python. Ich hoffe, Sie fanden sie hilfreich. Den gesamten Code finden Sie auf GitHub. Im nächsten Teil werden wir uns mit dem Ausführen von Joins und Unterabfragen, dem Verwalten von Transaktionen in SQLite und vielem mehr befassen. Bis dahin viel Spaß beim Programmieren!
Wenn Sie wissen möchten, wie Datenbankindizes funktionieren, lesen Sie So beschleunigen Sie SQL-Abfragen mithilfe von Indizes (Python Version).
Bala Priya C ist Entwicklerin und technische Redakteurin aus Indien. Sie arbeitet gerne an der Schnittstelle zwischen Mathematik, Programmierung, Datenwissenschaft und Inhaltserstellung. Ihre Interessens- und Fachgebiete umfassen DevOps, Datenwissenschaft und natürliche Sprachverarbeitung. Sie liest, schreibt, programmiert und trinkt gerne Kaffee! Derzeit arbeitet sie daran, ihr Wissen zu lernen und mit der Entwickler-Neighborhood zu teilen, indem sie Tutorials, Anleitungen, Meinungsbeiträge und mehr verfasst. Bala erstellt auch ansprechende Ressourcenübersichten und Programmier-Tutorials.