Einführung
In der sich schnell entwickelnden Welt der KI ist es entscheidend, die API-Kosten im Auge zu behalten, insbesondere beim Erstellen von LLM-basierten Anwendungen wie Retrieval-Augmented Era (RAG)-Pipelines in Produktion. Das Experimentieren mit verschiedenen LLMs, um die besten Ergebnisse zu erzielen, erfordert häufig zahlreiche API-Anfragen an den Server, wobei jede Anfrage Kosten verursacht. Um diese Ausgaben effektiv zu verwalten, ist es wichtig, zu verstehen und zu verfolgen, wofür jeder Greenback ausgegeben wird.
In diesem Artikel implementieren wir LL.M. Beobachtbarkeit mit RAG mit nur 10-12 Codezeilen. Die Beobachtbarkeit hilft uns, wichtige Kennzahlen wie Latenz, Anzahl der Token, Eingabeaufforderungen und Kosten professional Anfrage zu überwachen.
Lernziele
- Verstehen Sie das Konzept der LLM-Beobachtbarkeit und wie es bei der Überwachung und Optimierung der Leistung und Kosten von LLMs in Anwendungen hilft.
- Erkunden Sie verschiedene wichtige Kennzahlen zum Verfolgen und Überwachen, wie etwa Token-Nutzung, Latenz, Kosten professional Anfrage und prompte Experimente.
- So erstellen Sie eine Retrieval Augmented Era-Pipeline zusammen mit Observability.
- So verwenden Sie BeyondLLM, um die RAG-Pipeline mithilfe von RAG-Triadenmetriken, d. h. Kontextrelevanz, Antwortrelevanz und Bodenständigkeit, weiter zu bewerten.
- Durch sinnvolles Anpassen der Blockgröße und der High-Ok-Werte können die Kosten gesenkt, eine effiziente Anzahl an Tokens verwendet und die Latenz verbessert werden.
Dieser Artikel erschien im Rahmen der Information Science-Blogathon.
Was ist LLM-Beobachtbarkeit?
Stellen Sie sich LLM Observability so vor, als würden Sie die Leistung Ihres Autos überwachen oder Ihre täglichen Ausgaben verfolgen. LLM Observability beinhaltet das Beobachten und Verstehen jedes Particulars der Funktionsweise dieser KI-Modelle. Es hilft Ihnen, die Nutzung zu verfolgen, indem es die Anzahl der „Token“ zählt – Verarbeitungseinheiten, die jede Anfrage an das Modell verwendet. Dies hilft Ihnen, Ihr Price range einzuhalten und unerwartete Ausgaben zu vermeiden.
Darüber hinaus überwacht es die Leistung, indem es protokolliert, wie lange jede Anfrage dauert, und stellt so sicher, dass kein Teil des Prozesses unnötig langsam ist. Es liefert wertvolle Einblicke, indem es Muster und Traits anzeigt und Ihnen hilft, Ineffizienzen und Bereiche zu identifizieren, in denen Sie möglicherweise zu viel ausgeben. LLM Observability ist eine bewährte Methode, die Sie beim Erstellen von Anwendungen in der Produktion befolgen sollten, da dies die Aktionspipeline automatisieren kann, um Warnungen zu senden, wenn etwas schief geht.
Was ist Retrieval Augmented Era?
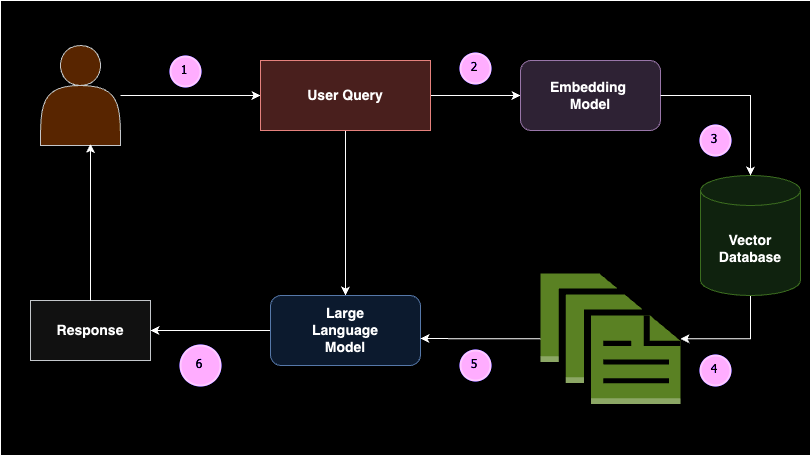
Retrieval Augmented Era (RAG) ist ein Konzept, bei dem relevante Dokumentblöcke als kontextbezogenes Lernen (d. h. Few-Shot-Prompting) basierend auf der Abfrage eines Benutzers an ein Massive Language Mannequin (LLM) zurückgegeben werden. Einfach ausgedrückt besteht RAG aus zwei Teilen: dem Retriever und dem Generator.
Wenn ein Benutzer eine Abfrage eingibt, wird diese zunächst in Einbettungen umgewandelt. Diese Abfrageeinbettungen werden dann vom Retriever in einer Vektordatenbank durchsucht, um die relevantesten oder semantisch ähnlichsten Dokumente zurückzugeben. Diese Dokumente werden als kontextbezogenes Lernen an das Generatormodell übergeben, sodass das LLM eine sinnvolle Antwort generieren kann. RAG verringert die Wahrscheinlichkeit von Halluzinationen und bietet domänenspezifische Antworten basierend auf der gegebenen Wissensbasis.
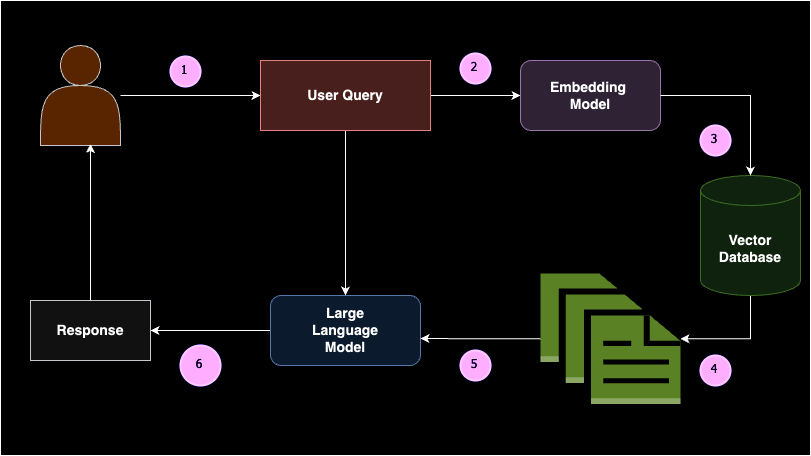
Der Aufbau einer RAG-Pipeline umfasst mehrere Schlüsselkomponenten: Datenquelle, Textsplitter, Vektordatenbank, Einbettungsmodelle und große Sprachmodelle. RAG wird häufig implementiert, wenn Sie ein großes Sprachmodell mit einer benutzerdefinierten Datenquelle verbinden müssen. Wenn Sie beispielsweise Ihr eigenes ChatGPT für Ihre Unterrichtsnotizen erstellen möchten, wäre RAG die ideale Lösung. Dieser Ansatz stellt sicher, dass das Modell genaue und relevante Antworten basierend auf Ihren spezifischen Daten liefern kann, was es für personalisierte Anwendungen äußerst nützlich macht.
Warum Observability mit RAG verwenden?
Das Erstellen einer RAG-Anwendung hängt von verschiedenen Anwendungsfällen ab. Jeder Anwendungsfall hängt von seinen eigenen benutzerdefinierten Eingabeaufforderungen für kontextbezogenes Lernen ab. Benutzerdefinierte Eingabeaufforderungen umfassen eine Kombination aus System- und Benutzereingabeaufforderungen. Die Systemeingabeaufforderung stellt die Regeln oder Anweisungen dar, auf deren Grundlage sich LLM verhalten muss, und die Benutzereingabeaufforderung ist die erweiterte Eingabeaufforderung für die Benutzerabfrage. Das Schreiben einer guten Eingabeaufforderung beim ersten Versuch ist ein sehr seltener Fall.
Die Verwendung von Observability mit Retrieval Augmented Era (RAG) ist entscheidend für die Gewährleistung effizienter und kosteneffektiver Abläufe. Observability hilft Ihnen, jedes Element Ihrer RAG-Pipeline zu überwachen und zu verstehen, von der Verfolgung der Token-Nutzung bis hin zur Messung von Latenz, Eingabeaufforderungen und Reaktionszeiten. Indem Sie diese Kennzahlen genau im Auge behalten, können Sie Ineffizienzen erkennen und beheben, unerwartete Ausgaben vermeiden und die Leistung Ihres Techniques optimieren. Im Wesentlichen liefert Observability die erforderlichen Einblicke, um Ihr RAG-Setup zu optimieren und sicherzustellen, dass es reibungslos läuft, im Rahmen des Budgets bleibt und durchgängig genaue, domänenspezifische Antworten liefert.
Nehmen wir ein praktisches Beispiel und verstehen, warum wir bei der Verwendung von RAG die Beobachtbarkeit nutzen müssen. Angenommen, Sie haben die App erstellt und sie ist jetzt in der Produktion
Chat mit YouTube: Beobachtbarkeit mit RAG-Implementierung
Sehen wir uns nun die Schritte der Beobachtbarkeit mit der RAG-Implementierung an.
Schritt 1: Set up
Bevor wir mit der Code-Implementierung fortfahren, müssen Sie einige Bibliotheken installieren. Diese Bibliotheken umfassen Über LLM hinaus, OpenAI, Phönixund YouTube Transcript API. Past LLM ist eine Bibliothek, die Ihnen hilft, erweiterte RAG-Anwendungen effizient zu erstellen, indem sie Beobachtbarkeit, Feinabstimmung, Einbettungen und Modellbewertung integriert.
pip set up beyondllm
pip set up openai
pip set up arize-phoenix(evals)
pip set up youtube_transcript_api llama-index-readers-youtube-transcriptSchritt 2: OpenAI API-Schlüssel einrichten
Richten Sie die Umgebungsvariable für den OpenAI-API-Schlüssel ein, der zur Authentifizierung und zum Zugriff auf OpenAI-Dienste wie LLM und Einbettung erforderlich ist.
Holen Sie sich Ihren Schlüssel hier
import os, getpass
os.environ('OPENAI_API_KEY') = getpass.getpass("API:")
# import required libraries
from beyondllm import supply,retrieve,generator, llms, embeddings
from beyondllm.observe import ObserverSchritt 3: Einrichten der Beobachtbarkeit
Das Aktivieren der Beobachtbarkeit sollte der erste Schritt in Ihrem Code sein, um sicherzustellen, dass alle nachfolgenden Vorgänge verfolgt werden.
Observe = Observer()
Observe.run()Schritt 4: LLM und Einbettung definieren
Da der OpenAI-API-Schlüssel bereits in der Umgebungsvariable gespeichert ist, können Sie jetzt das LLM und das Einbettungsmodell definieren, um das Dokument abzurufen und die Antwort entsprechend zu generieren.
llm=llms.ChatOpenAIModel()
embed_model = embeddings.OpenAIEmbeddings()Schritt 5: RAG Teil 1 – Retriever
BeyondLLM ist ein natives Framework für Datenwissenschaftler. Um Daten aufzunehmen, können Sie die Datenquelle innerhalb der Funktion „match“ definieren. Basierend auf der Datenquelle können Sie den „dtype“ angeben, in unserem Fall ist es YouTube. Darüber hinaus können wir unsere Daten in Blöcke aufteilen, um die Kontextlängenprobleme des Modells zu vermeiden und nur den spezifischen Block zurückzugeben. Die Blocküberlappung definiert die Anzahl der Token, die im nachfolgenden Block wiederholt werden müssen.
Der Auto Retriever in BeyondLLM hilft dabei, die relevante Anzahl von okay Dokumenten basierend auf dem Typ abzurufen. Es gibt verschiedene Retrievertypen wie Hybrid, Re-Rating, Flag Embedding Re-Ranker und mehr. In diesem Anwendungsfall verwenden wir einen normalen Retriever, d. h. einen In-Reminiscence-Retriever.
information = supply.match("https://www.youtube.com/watch?v=IhawEdplzkI",
dtype="youtube",
chunk_size=512,
chunk_overlap=50)
retriever = retrieve.auto_retriever(information,
embed_model,
sort="regular",
top_k=4)
Schritt 6: RAG Teil-2-Generator
Das Generatormodell kombiniert die Benutzerabfrage und die relevanten Dokumente aus der Retriever-Klasse und übergibt sie an das Massive Language Mannequin. Um dies zu ermöglichen, unterstützt BeyondLLM ein Generatormodul, das diese Pipeline verkettet und eine weitere Auswertung der Pipeline auf der RAG-Triade ermöglicht.
user_query = "summarize easy activity execution worflow?"
pipeline = generator.Generate(query=user_query,retriever=retriever,llm=llm)
print(pipeline.name())Ausgabe
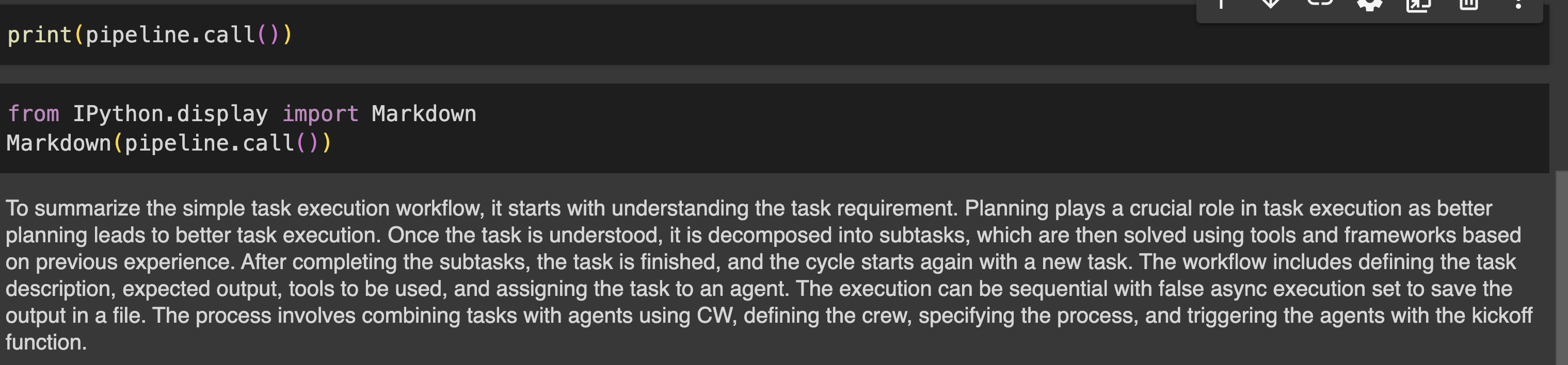
Schritt 7: Bewerten Sie die Pipeline
Die Bewertung der RAG-Pipeline kann mithilfe von RAG-Triadenmetriken durchgeführt werden, die Kontextrelevanz, Antwortrelevanz und Bodenständigkeit umfassen.
- Kontextrelevanz : Misst die Relevanz der vom Auto-Retriever abgerufenen Chunks im Verhältnis zur Abfrage des Benutzers. Bestimmt die Effizienz des Auto-Retrievers beim Abrufen kontextrelevanter Informationen und stellt sicher, dass die Grundlage für die Generierung von Antworten solide ist.
- Antwortrelevanz : Bewertet die Relevanz der LLM-Antwort auf die Benutzerabfrage.
- Bodenständigkeit : Es bestimmt, wie intestine die Antworten des Sprachmodells auf den vom Auto-Retriever abgerufenen Informationen basieren, mit dem Ziel, halluzinierte Inhalte zu identifizieren und zu eliminieren. Dadurch wird sichergestellt, dass die Ergebnisse auf genauen und sachlichen Informationen basieren.
print(pipeline.get_rag_triad_evals())
#or
# run it individually
print(pipeline.get_context_relevancy()) # context relevancy
print(pipeline.get_answer_relevancy()) # reply relevancy
print(pipeline.get_groundedness()) # groundednessAusgabe:

Phoenix Dashboard: LLM-Beobachtbarkeitsanalyse
Abbildung 1 zeigt das Haupt-Dashboard von Phoenix. Wenn Sie Observer.run() ausführen, werden zwei Hyperlinks zurückgegeben:
- Lokaler Host: http://127.0.0.1:6006/
- Wenn localhost nicht ausgeführt wird, können Sie einen alternativen Hyperlink auswählen, um die Phoenix-App in Ihrem Browser anzuzeigen.
Da wir zwei Dienste von OpenAI verwenden, werden sowohl LLM als auch Einbettungen unter dem Anbieter angezeigt. Es wird die Anzahl der von jedem Anbieter verwendeten Token angezeigt, zusammen mit der Latenz, der Startzeit, der Eingabe für die API-Anforderung und der vom LLM generierten Ausgabe.
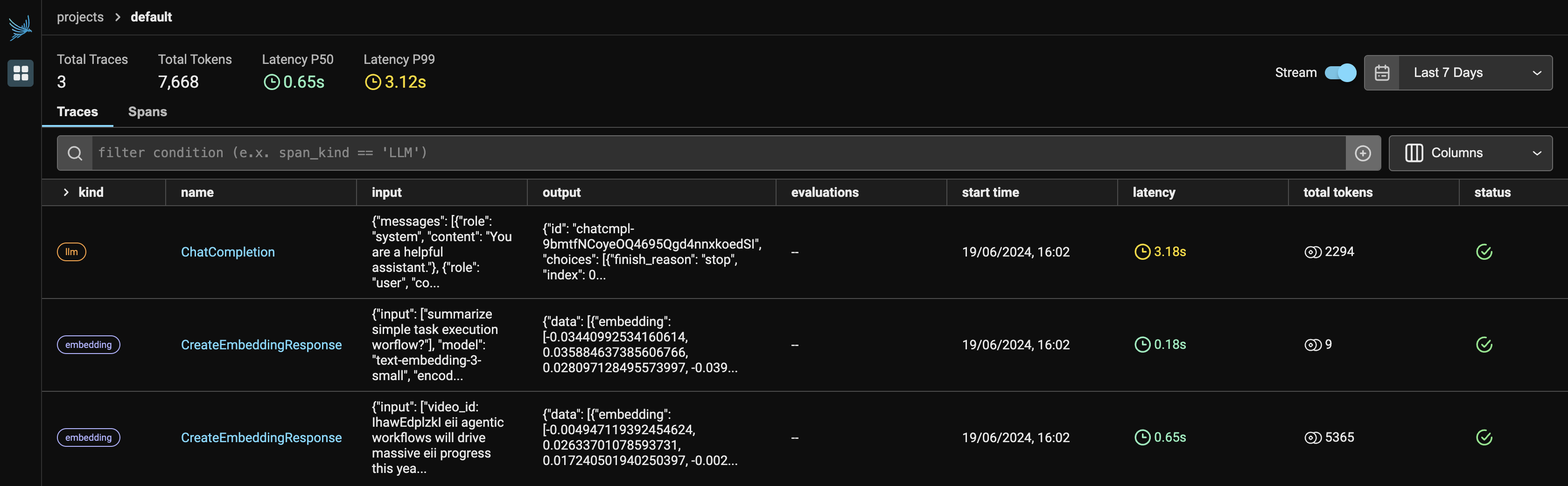
Abbildung 2 zeigt die Ablaufverfolgungsdetails des LLM. Dazu gehören die Latenzzeit von 1,53 Sekunden, die Anzahl der Tokens von 2212 und Informationen wie die Systemaufforderung, die Benutzeraufforderung und die Antwort.
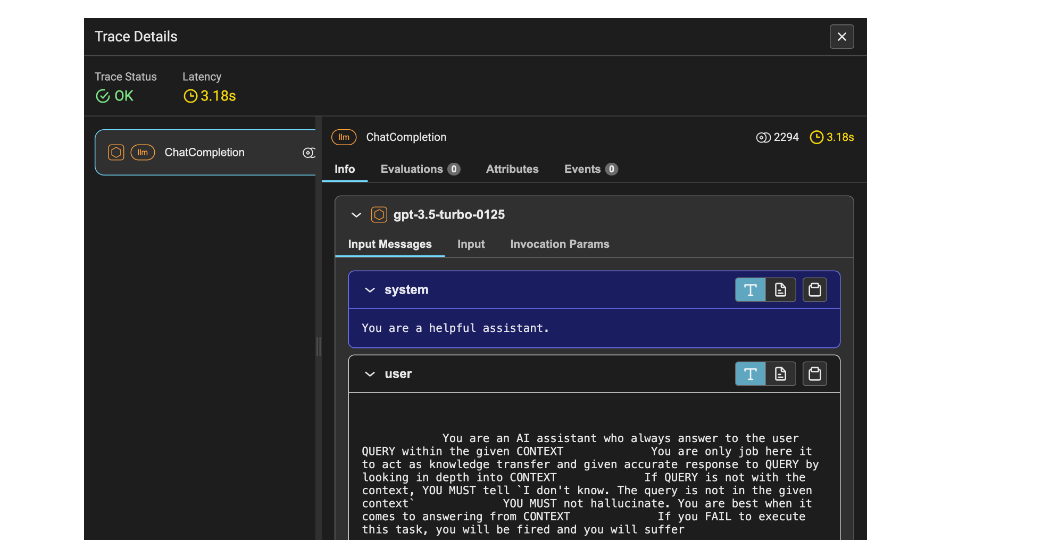
Abbildung 3 zeigt die Ablaufverfolgungsdetails der Einbettungen für die gestellte Benutzerabfrage sowie weitere Kennzahlen ähnlich wie in Abbildung 2. Anstelle einer Eingabeaufforderung sehen Sie die in Einbettungen umgewandelte Eingabeabfrage.
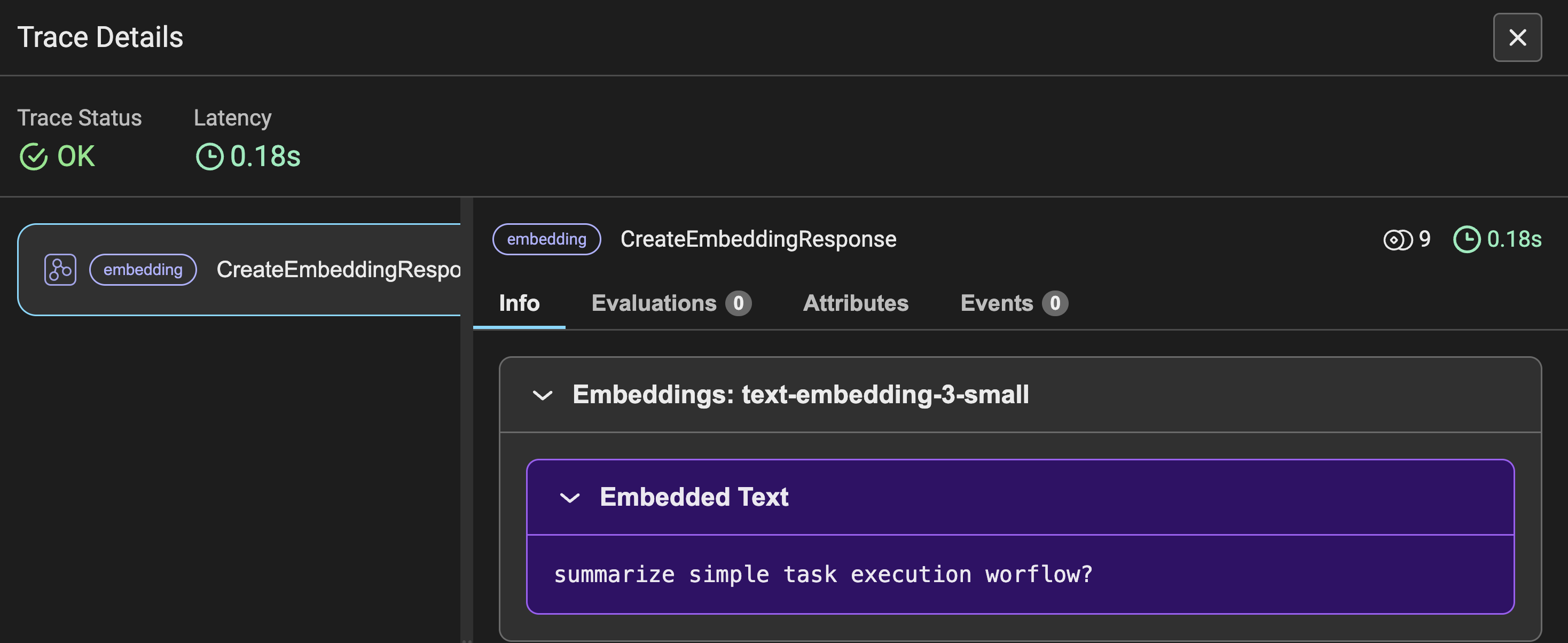
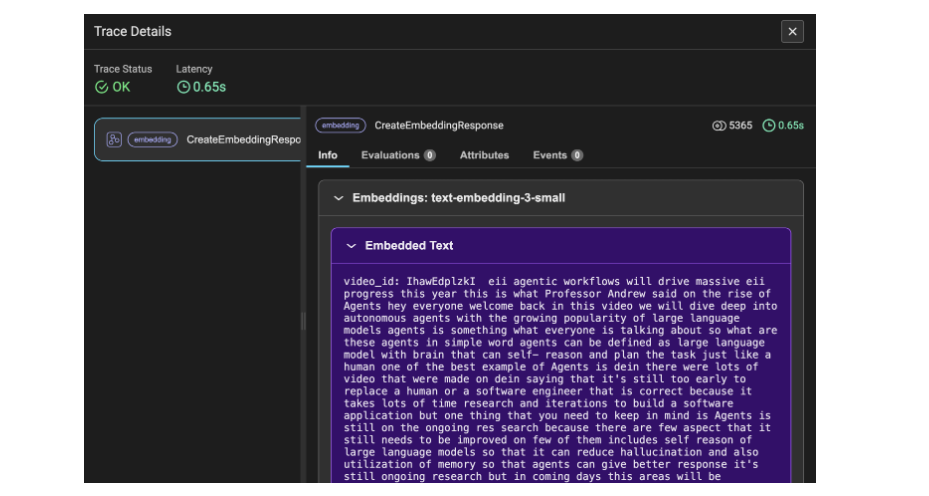
Abbildung 4 zeigt die Hint-Particulars der Embeddings für die YouTube-Transkriptdaten. Hier werden die Daten in Chunks und dann in Embeddings umgewandelt, weshalb sich die Anzahl der verwendeten Token auf 5365 beläuft. Dieses Hint-Element bezeichnet die Transkript-Videodaten als Data.
Abschluss
Zusammenfassend lässt sich sagen, dass Sie erfolgreich eine Retrieval Augmented Era (RAG)-Pipeline mit erweiterten Konzepten wie Auswertung und Beobachtbarkeit erstellt haben. Mit diesem Ansatz können Sie dieses Wissen weiter nutzen, um zu automatisieren und Skripte für Warnungen zu schreiben, wenn etwas schief geht, oder die Anfragen verwenden, um die Protokolldetails zu verfolgen, um bessere Einblicke in die Leistung der Anwendung zu erhalten und natürlich die Kosten im Rahmen des Budgets zu halten. Darüber hinaus hilft Ihnen die Einbeziehung der Beobachtbarkeit dabei, die Modellnutzung zu optimieren und eine effiziente, kostengünstige Leistung für Ihre spezifischen Anforderungen sicherzustellen.
Die zentralen Thesen
- Verstehen der Notwendigkeit der Beobachtbarkeit beim Erstellen von LLM-basierten Anwendungen wie Retrieval Augmented Era.
- Zu verfolgende Schlüsselmetriken wie beispielsweise die Anzahl der Token, Latenz, Eingabeaufforderungen und Kosten für jede gestellte API-Anforderung.
- Implementierung von RAG- und Triadenauswertungen mit BeyondLLM mit minimalen Codezeilen.
- Überwachung und Verfolgung der LLM-Beobachtbarkeit mit BeyondLLM und Phoenix.
- Einige Snapshots geben Einblicke in Hint-Particulars von LLM und Einbettungen, die zur Verbesserung der Anwendungsleistung automatisiert werden müssen.
Häufig gestellte Fragen
A. Wenn es um Beobachtbarkeit geht, ist es sinnvoll, Closed-Supply-Modelle wie GPT, Gemini, Claude und andere zu verfolgen. Phoenix unterstützt direkte Integrationen mit Langchain, LLamaIndex und dem DSPY-Framework sowie unabhängigen LLM-Anbietern wie OpenAI, Bedrock und anderen.
A. BeyondLLM unterstützt die Auswertung der Retrieval Augmented Era (RAG)-Pipeline mithilfe der von ihr unterstützten LLMs. Sie können RAG auf BeyondLLM ganz einfach mit Ollama- und HuggingFace-Modellen auswerten. Die Auswertungsmetriken umfassen Kontextrelevanz, Antwortrelevanz, Bodenständigkeit und Grundwahrheit.
A. Die Kosten für die OpenAI-API werden für die Anzahl der von Ihnen genutzten Token aufgewendet. Hier kann Ihnen die Beobachtung dabei helfen, die Überwachung und Nachverfolgung von Token professional Anfrage, Token insgesamt, Kosten professional Anfrage und Latenz beizubehalten. Diese Metriken helfen wirklich dabei, eine Funktion auszulösen, die den Benutzer auf die Kosten hinweist.
Die in diesem Artikel gezeigten Medien sind nicht Eigentum von Analytics Vidhya und werden nach Ermessen des Autors verwendet.