
Sprachmodelle haben sich in der Welt schnell entwickelt. Jetzt mit multimodal Llms Wenn Sie das Rennen dieser Sprachmodelle in Anspruch nehmen, ist es wichtig zu verstehen, wie wir die Funktionen dieser multimodalen Modelle nutzen können. Von traditionellen textbasierten KI-betriebenen Chatbots wechseln wir zu sprachbasierten Chatbots. Diese fungieren als unsere persönlichen Assistenten, die in einem Second zur Verfügung stehen, um sich um unsere Bedürfnisse zu kümmern. Heutzutage finden Sie einen AI-In in diesem Weblog. Wir werden einen sprachbasierten Chatbot für Notfallbetreiber erstellen. Die Idee ist ziemlich einfach:
- Wir sprechen mit dem Chatbot
- Es hört zu, was wir gesagt haben
- Es reagiert mit einem Sprachbrief
Unser Anwendungsfall
Stellen wir uns ein reales Szenario vor. Wir leben in einem Land mit über 1,4 Milliarden Menschen und mit einer so großen Bevölkerung müssen Notfälle auftreten, unabhängig davon, ob es sich um ein medizinisches Drawback, ein Brandausbruch, eine polizeiliche Intervention oder sogar eine Unterstützung für psychische Gesundheit wie Anti-Suizid-Unterstützung usw. handelt.
In solchen Momenten zählt jede Sekunde. In Anbetracht des Mangels an Notfallbetreibern und der überwältigenden Menge an aufgeworfenen Problemen. Hier kann ein sprachbasierter Chatbot einen großen Unterschied machen, der eine schnelle und gesprochene Unterstützung bieten kann, wenn die Leute es am meisten brauchen.
- Nothilfe: Sofortige Hilfe für Gesundheit, Feuer, Kriminalität oder Katastrophenanfragen, ohne auf einen menschlichen Betreiber zu warten (wenn nicht verfügbar).
- Helpline für psychische Gesundheit: Ein sprachbasierter emotionaler Assist-Assistent, der Benutzer mit Mitgefühl führt.
- Ländliche Zugänglichkeit: Bereiche mit begrenztem Zugriff auf cellular Apps können von einer einfachen Sprachschnittstelle profitieren, da Menschen häufig durch Sprechen in solchen Bereichen kommunizieren.
Genau das werden wir bauen. Wir werden als jemand handeln, der Hilfe sucht, und der Chatbot spielt die Rolle eines Nothängers, der von einem großen Sprachmodell angetrieben wird.
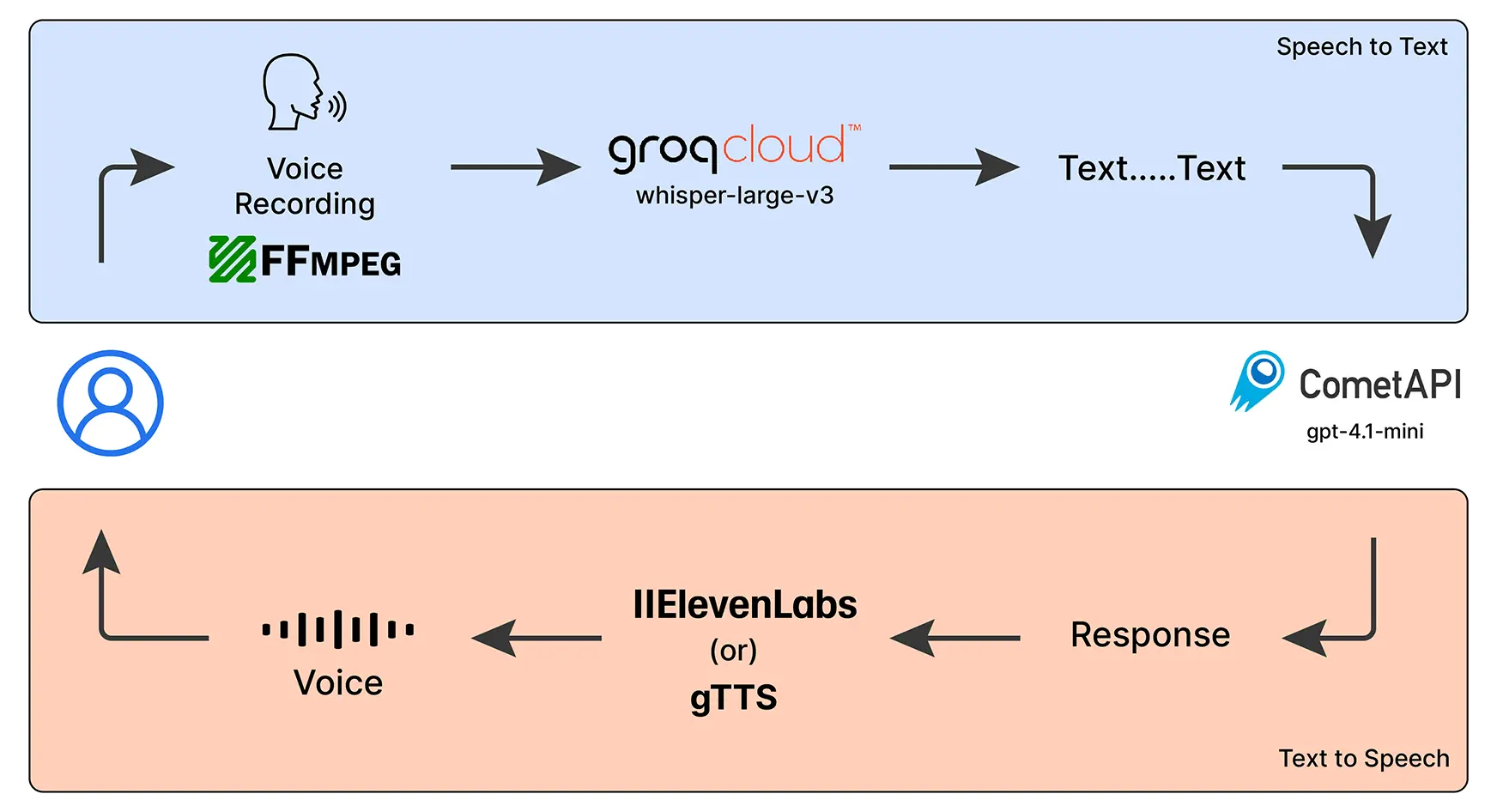
Um unseren Voice Chatbot zu implementieren, werden wir die folgenden erwähnten KI -Modelle verwenden:
- Flüstert (groß) -OpenAIs Rede-to-Textual content-Modell, das über Groqcloud ausgeführt wird, um Sprache in Textual content umzuwandeln.
- GPT-4.1-Mini – Angetrieben von Cometapi (kostenloser LLM -Anbieter) ist dies das Gehirn unseres Chatbots, das unsere Fragen versteht und sinnvolle Antworten erzeugt.
- Google Textual content-to-Speech (GTTS) – Umwandelt die Antworten des Chatbot wieder in die Stimme, damit sie mit uns sprechen kann.
- Ffmpeg – Eine praktische Bibliothek, die uns Audio einfach aufzeichnet und verwaltet.
Anforderungen
Bevor wir mit dem Codieren beginnen, müssen wir einige Dinge einrichten:
- Accloud apischlüssel: Holen Sie es von hier aus: https://console.groq.com/keys
- Cometapi -Schlüssel
Registrieren und speichern Sie Ihre API -Schlüssel von: https://api.cometapi.com/ - Elflabs api Schlüssel
Registrieren und speichern Sie Ihre API -Schlüssel von: https://elevenlabs.io/app/dwelling - FFMPEG -Set up
Wenn Sie es noch nicht haben, befolgen Sie diese Anleitung, um FFMPEG in Ihrem System zu installieren: https://itsfoss.com/ffmpeg/
Bestätigen Sie durch Eingabe “ffmeg -Verssion”In Ihrem Terminal
Sobald Sie diese eingerichtet haben, sind Sie bereit, Ihren eigenen sprachfähigen Chatbot aufzubauen!
Projektstruktur
Die Projektstruktur wird ziemlich einfach und rudimentär sein und die meisten unserer Arbeiten werden in der stattfinden app.py Und utils.py Python Skripte.
VOICE-CHATBOT/├── venv/ # Digital setting for dependencies
├── .env # Atmosphere variables (API keys, and many others.)
├── app.py # Predominant software script
├── emergency.png # Emergency-related picture asset
├── README.md # Venture documentation (elective)
├── necessities.txt # Python dependencies
├── utils.py # Utility/helper features
Es sind einige notwendige Dateien zu ändern, um sicherzustellen, dass alle unsere Abhängigkeiten erfüllt sind:
In der .env -Datei
GROQ_API_KEY = "<your-groq-api-key"
COMET_API_KEY = "<your-comet-api-key>"
ELEVENLABS_API_KEY = "<your-elevenlabs-api–key"In den Anforderungen.txt
ffmpeg-python
pydub
pyttsx3
langchain
langchain-community
langchain-core
langchain-groq
langchain_openai
python-dotenv
streamlit==1.37.0
audio-recorder-streamlit
dotenv
elevenlabs
gttsEinrichten der virtuellen Umgebung
Wir müssen auch a einrichten Virtuelle Umgebung (eine gute Praxis). Wir werden dies im Terminal tun.
- Schaffung unserer virtuellen Umgebung
~/Desktop/Emergency-Voice-Chatbot$ conda create -p venv python==3.12 -y
- Unsere virtuelle Umgebung aktivieren
~/Desktop/Emergency-Voice-Chatbot$ conda activate venv/
- Nachdem Sie die Ausführung der Anwendung beendet haben, können Sie auch die virtuelle Umgebung deaktivieren
~/Desktop/Emergency-Voice-Chatbot$ conda deactivate
Haupt -Python -Skripte
Lassen Sie uns zuerst die erkunden utils.py Skript.
1. Hauptimporte
Zeit, Tempfile, OS, Re, Bytesio -Timing, temporäre Dateien, Umgebungsvariablen, Regex und In-Reminiscence-Daten behandeln.
Anfragen – stellt HTTP -Anfragen (z. B. APIs an).
gttsAnwesend ElflabsAnwesend Pydub – Textual content in Sprache, Sprache in Textual content und Spielen-/Manipulation von Audio konvertieren.
GroqAnwesend Langchain_* – Verwenden Sie COR/OpenAI LLMs mit Langchain, um Textual content zu verarbeiten und zu generieren.
Straffung – Erstellen Sie interaktive Internet -Apps.dotenv – Umgebungsvariablen (wie API -Schlüssel) aus einer .Env -Datei laden.
import time
import requests
import tempfile
import re
from io import BytesIO
from gtts import gTTS
from elevenlabs.consumer import ElevenLabs
from elevenlabs import play
from pydub import AudioSegment
from groq import Groq
from langchain_groq import ChatGroq
from langchain_openai import ChatOpenAI
from langchain_core.messages import AIMessage, HumanMessage
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
import streamlit as st
import os
from dotenv import load_dotenv
load_dotenv() 2. Laden Sie Ihre API -Schlüssel und initialisieren Sie Ihre Modelle
# Initialize the Groq consumer
consumer = Groq(api_key=os.getenv('GROQ_API_KEY'))
# Initialize the Groq mannequin for LLM responses
llm = ChatOpenAI(
model_name="gpt-4.1-mini",
openai_api_key=os.getenv("COMET_API_KEY"),
openai_api_base="https://api.cometapi.com/v1"
)
# Set the trail to ffmpeg executable
AudioSegment.converter = "/bin/ffmpeg"
3. Konvertieren der Audiodatei (unsere Sprachaufzeichnung) in das WAV -Format
Hier werden wir unser Audio in Bytes konvertieren, was von Audiosisment und Bytesio durchgeführt wird und es in a umgewandelt wird Wave Format:
def audio_bytes_to_wav(audio_bytes):
attempt:
with tempfile.NamedTemporaryFile(delete=False, suffix=".wav") as temp_wav:
audio = AudioSegment.from_file(BytesIO(audio_bytes))
# Downsample to cut back file measurement if wanted
audio = audio.set_frame_rate(16000).set_channels(1)
audio.export(temp_wav.title, format="wav")
return temp_wav.title
besides Exception as e:
st.error(f"Error throughout WAV file conversion: {e}")
return None4. Audio spalten
Wir werden eine Funktion erstellen, um unser Audio gemäß unserem Eingabeparameter (check_length_ms) zu teilen. Wir werden auch eine Funktion machen, um jede Zeichensetzung mit Hilfe von zu beseitigen Regex.
def split_audio(file_path, chunk_length_ms):
audio = AudioSegment.from_wav(file_path)
return (audio(i:i + chunk_length_ms) for i in vary(0, len(audio), chunk_length_ms))
def remove_punctuation(textual content):
return re.sub(r'(^ws)', '', textual content)5. LLM -Antwortgenerierung
Um jetzt Haupthilfspflonder -Funktionalität zu machen, bei der der LLM eine passende Antwort auf unsere Fragen erzeugt. In der schnellen Vorlage geben wir die Anweisungen an unsere LLM, wie sie auf die Anfragen reagieren sollten. Wir werden implementieren Langchain Ausdruckssprache, um diese Aufgabe zu erledigen.
def get_llm_response(question, chat_history):
attempt:
template = template = """
You might be an skilled Emergency Response Telephone Operator educated to deal with crucial conditions in India.
Your function is to information customers calmly and clearly throughout emergencies involving:
- Medical crises (accidents, coronary heart assaults, and many others.)
- Hearth incidents
- Police/regulation enforcement help
- Suicide prevention or psychological well being crises
You could:
1. **Stay calm and assertive**, as if talking on a telephone name.
2. **Ask for and make sure key particulars** like location, situation of the individual, variety of folks concerned, and many others.
3. **Present fast and sensible steps** the consumer can take earlier than assist arrives.
4. **Share correct, India-based emergency helpline numbers** (e.g., 112, 102, 108, 1091, 1098, 9152987821, and many others.).
5. **Prioritize consumer security**, and clearly instruct them what *not* to do as effectively.
6. If the state of affairs entails **suicidal ideas or psychological misery**, reply with compassion and direct them to applicable psychological well being helplines and security actions.
If the consumer's question isn't associated to an emergency, reply with:
"I can solely help with pressing emergency-related points. Please contact a basic help line for non-emergency questions."
Use an authoritative, supportive tone, brief and direct sentences, and tailor your steering to **city and rural Indian contexts**.
**Chat Historical past:** {chat_history}
**Person:** {user_query}
"""
immediate = ChatPromptTemplate.from_template(template)
chain = immediate | llm | StrOutputParser()
response_gen = chain.stream({
"chat_history": chat_history,
"user_query": question
})
response_text="".be a part of(record(response_gen))
response_text = remove_punctuation(response_text)
# Take away repeated textual content
response_lines = response_text.break up('n')
unique_lines = record(dict.fromkeys(response_lines)) # Eradicating duplicates
cleaned_response="n".be a part of(unique_lines)
return cleaned_responseChatbot
besides Exception as e:
st.error(f"Error throughout LLM response technology: {e}")
return "Error"
6. Textual content zur Sprache
Wir werden eine Funktion erstellen, um unseren Textual content mit Hilfe des elfLabs -TTS -Purchasers in die Sprache umzuwandeln, die uns das Audio im Audiosisment -Format zurückgeben. Wir können auch andere TTS -Modelle wie Nari Lab’s Dia oder verwenden Googles GTTs zu. Elf Labs liefert uns zu Beginn kostenlose Credit, und dann müssen wir für weitere Credit bezahlen, GTTS auf der anderen Seite ist absolut kostenlos zu verwenden.
def text_to_speech(textual content: str, retries: int = 3, delay: int = 5):
try = 0
whereas try < retries:
attempt:
# Request speech synthesis (streaming generator)
response_stream = tts_client.text_to_speech.convert(
textual content=textual content,
voice_id="JBFqnCBsd6RMkjVDRZzb",
model_id="eleven_multilingual_v2",
output_format="mp3_44100_128",
)
# Write streamed bytes to a brief file
with tempfile.NamedTemporaryFile(delete=False, suffix='.mp3') as f:
for chunk in response_stream:
f.write(chunk)
temp_path = f.title
# Load and return the audio
audio = AudioSegment.from_mp3(temp_path)
return audio
else:
st.error(f"Failed to attach after {retries} makes an attempt. Please examine your web connection.")
return AudioSegment.silent(length=1000)
besides Exception as e:
st.error(f"Error throughout text-to-speech conversion: {e}")
return AudioSegment.silent(length=1000)
return AudioSegment.silent(length=1000)
7. Einführungsnachricht erstellen
Wir werden auch einen Einführungstext erstellen und an unser TTS -Modell weitergeben, da sich ein Befragter normalerweise vorstellen und nach Unterstützung des Benutzers suchen würde. Hier werden wir den Pfad der MP3 -Datei zurückgeben.
lang = „en“ -> Englisch
tld = „Co.in“ -> kann verschiedene lokalisierte ‚Akzente‘ für eine bestimmte Sprache erzeugen. Der Commonplace ist „com“
def create_welcome_message():
welcome_text = (
"Good day, you’ve reached the Emergency Assist Desk. "
"Please let me know if it is a medical, fireplace, police, or psychological well being emergency—"
"I am right here to information you immediately."
)
attempt:
# Request speech synthesis (streaming generator)
response_stream = tts_client.text_to_speech.convert(
textual content=welcome_text,
voice_id="JBFqnCBsd6RMkjVDRZzb",
model_id="eleven_multilingual_v2",
output_format="mp3_44100_128",
)
# Save streamed bytes to temp file
with tempfile.NamedTemporaryFile(delete=False, suffix='.mp3') as f:
for chunk in response_stream:
f.write(chunk)
return f.title
besides requests.ConnectionError:
st.error("Did not generate welcome message as a consequence of connection error.")
besides Exception as e:
st.error(f"Error creating welcome message: {e}")
return NoneStromlit -App
Nun springen wir in die principal.py Skript, wo wir verwenden werden Straffung Um unseren Chatbot zu visualisieren.
Bibliotheken und Funktionen importieren
Importieren Sie unsere Bibliotheken und die Funktionen, die wir in unserer Utils.Py aufgebaut hatten
import tempfile
import re # This may be eliminated if not used
from io import BytesIO
from pydub import AudioSegment
from langchain_core.messages import AIMessage, HumanMessage
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
import streamlit as st
from audio_recorder_streamlit import audio_recorder
from utils import *Streamlit Setup
Jetzt setzen wir unseren Titelnamen und ein schönes visuelles „Notfall“ -Foto fest
st.title(":blue(Emergency Assist Bot) 🚨🚑🆘")
st.sidebar.picture('./emergency.jpg', use_column_width=True)Wir werden unsere Sitzungsstaaten festlegen, um unsere Chats und Audio zu verfolgen
if "chat_history" not in st.session_state:
st.session_state.chat_history = ()
if "chat_histories" not in st.session_state:
st.session_state.chat_histories = ()
if "played_audios" not in st.session_state:
st.session_state.played_audios = {}
Aufrufen unserer Utils -Funktionen
Wir werden unsere Begrüßungsnachrichteneinführung von der befragten Seite erstellen. Dies wird der Beginn unseres Gesprächs sein.
if len(st.session_state.chat_history) == 0:
welcome_audio_path = create_welcome_message()
st.session_state.chat_history = (
AIMessage(content material="Good day, you’ve reached the Emergency Assist Desk. Please let me know if it is a medical, fireplace, police, or psychological well being emergency—I am right here to information you immediately.", audio_file=welcome_audio_path)
)
st.session_state.played_audios(welcome_audio_path) = False Jetzt werden wir in der Seitenleiste unseren Sprachrekorder und die einrichten Sprache zu Textual contentAnwesend LLM_Response und die Textual content-to-Speech Logik, die der Hauptkrux dieses Projekts ist
with st.sidebar:
audio_bytes = audio_recorder(
energy_threshold=0.01,
pause_threshold=0.8,
textual content="Converse on clicking the ICON (Max 5 min) n",
recording_color="#e9b61d", # yellow
neutral_color="#2abf37", # inexperienced
icon_name="microphone",
icon_size="2x"
)
if audio_bytes:
temp_audio_path = audio_bytes_to_wav(audio_bytes)
if temp_audio_path:
attempt:
user_input = speech_to_text(audio_bytes)
if user_input:
st.session_state.chat_history.append(HumanMessage(content material=user_input, audio_file=temp_audio_path))
response = get_llm_response(user_input, st.session_state.chat_history)
audio_response = text_to_speech(response) Wir werden auch eine Schaltfläche in der Seitenleiste einrichten, mit der wir bei Bedarf unsere Sitzung neu starten können, und natürlich unserem Einführungssprachnotiz von der befragten Seite.
if st.button("Begin New Chat"):
st.session_state.chat_histories.append(st.session_state.chat_history)
welcome_audio_path = create_welcome_message()
st.session_state.chat_history = (
AIMessage(content material="Good day, you’ve reached the Emergency Assist Desk. Please let me know if it is a medical, fireplace, police, or psychological well being emergency—I am right here to information you immediately.", audio_file=welcome_audio_path)
)Auf der Hauptseite unserer App visualisieren wir unseren Chat -Verlauf in Kind von Click on to Play Audio -Datei
for msg in st.session_state.chat_history:
if isinstance(msg, AIMessage):
with st.chat_message("AI"):
st.audio(msg.audio_file, format="audio/mp3")
else: # HumanMessage
with st.chat_message("consumer"):
st.audio(msg.audio_file, format="audio/wav")Jetzt sind wir mit allen Python -Skripten fertig, die für die Ausführung unserer App benötigt werden. Wir werden die Streamlit -App mit dem folgenden Befehl ausführen:
streamlit run app.py So sieht unser Projektworkflow aus:
(Person speaks) → audio_recorder → audio_bytes_to_wav → speech_to_text → get_llm_response → text_to_speech → st.audio
Für den vollständigen Code besuchen Sie Das Github -Repository.
Endgültige Ausgabe
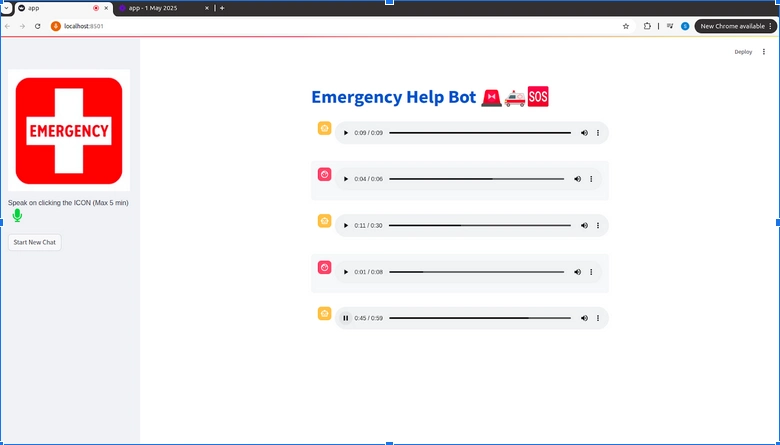
Die Streamlit -App sieht ziemlich sauber aus und funktioniert angemessen!
Lassen Sie uns einige seiner Antworten sehen:-
- Benutzer: Hallo, jemand hat gerade einen Herzinfarkt, was soll ich tun?
Wir hatten dann ein Gespräch über den Ort und den Zustand der Individual, und dann lieferte der Chatbot dies
- Benutzer: Hallo, in Delhi gab es einen riesigen Brandausbruch. Bitte senden Sie Hilfe schnell
Der Befragte erkundigt sich nach der Scenario und wo ist mein aktueller Standort und erfolgt dann entsprechend vorbeugende Maßnahmen
- Benutzer: Hey, da steht eine Individual alleine über den Rand der Brücke, wie soll ich vorgehen?
Der Befragte erkundigt sich nach dem Ort, an dem ich bin, und den mentalen Zustand der Individual, die ich erwähnt habe
Insgesamt kann unser Chatbot in Übereinstimmung mit der Scenario auf unsere Fragen antworten und die entsprechenden Fragen stellt, um vorbeugende Maßnahmen zu erteilen.
Mehr lesen: Wie baue ich einen Chatbot in Python?
Welche Verbesserungen können vorgenommen werden?
- Mehrsprachige Unterstützung: Kann LLMs in starke mehrsprachige Funktionen integrieren, mit denen der Chatbot nahtlos mit Benutzern aus verschiedenen Regionen und Dialekten interagieren kann.
- Echtzeit-Transkription und Übersetzung: Das Hinzufügen von Sprach-Textual content- und Echtzeitübersetzungen kann dazu beitragen, Kommunikationslücken zu überbrücken.
- Standortbasierte Dienste: Durch die Integration von GPS oder anderen standortbasierten Echtzeit-APIs kann das System den Standort eines Benutzers erkennen und die nächsten Notfalleinrichtungen leiten.
- Sprach-zu-Sprach-Interaktion: Wir können auch Sprach- zu Sprachmodelle verwenden, die Gespräche natürlicher fühlen können, da sie für solche Funktionen gebaut werden.
- Feinabstimmung des LLM: Die benutzerdefinierte Feinabstimmung des LLM basierend auf Notfallspezifischen Daten kann ihr Verständnis verbessern und genauere Antworten liefern.
Um mehr über KI-betriebene Sprachagenten zu erfahren, folgen Sie folgenden Ressourcen:
Abschluss
In diesem Artikel haben wir einen sprachbasierten Notfall-Reaktion-Chatbot mit einer Kombination von erfolgreich erstellt Ai Modelle und einige relevante Instruments. Dieser Chatbot reproduziert die Rolle eines ausgebildeten Notfallbetreibers, der in der Lage ist, Situationen mit hoher Stress aus medizinischen Krisen zu bewältigen, und Brandvorfälle zur Unterstützung der psychischen Gesundheit unter Verwendung einer ruhigen, durchsetzungsfähigen, die das Verhalten unseres LLM für die vielfältigen realen Notfälle verändern kann, was die Erfahrung sowohl für das städtische als auch für das ländliche Szenarien realistischer macht.
Genai Praktikant @ Analytics Vidhya | Letzte Jahr @ Vit Chennai
Leidenschaftlich für KI und maschinelles Lernen, ich bin bestrebt, als KI/ML -Ingenieur oder Datenwissenschaftler in Rollen einzutauchen, wo ich einen echten Einfluss haben kann. Ich freue mich sehr, modern Lösungen und hochmoderne Fortschritte auf den Tisch zu bringen. Meine Neugier treibt mich an, KI über verschiedene Bereiche hinweg zu erkunden und die Initiative zu ergreifen, um sich mit Information Engineering zu befassen, um sicherzustellen, dass ich vorne bleibe und wirksame Projekte liefere.
Melden Sie sich an, um weiter zu lesen und Experten-Kuratinhalte zu genießen.