Zusammenfassung
- Cross -Entropy -Maßnahmen in Bits, wie überraschend das wahre Token unter der vorhergesagten Verteilung Ihres Modells steht.
- Das Ziel ist nicht nur das Ziel, das Sie sowohl während der Vorab- als auch bei der Feinabstimmung aktiv optimieren, sondern es wird auch passiv als Bewertungsmetrik verwendet.
- Es ist zwar glatt, differenzierbar und rechnerisch effizient, was es ideally suited für die Gradientenoptimierung ist, kann es numerisch instabil sein.
Der Verlust von Cross -Entropie gilt als eines der Eckpfeilermetriken bei der Bewertung von Sprachmodellen und dient sowohl als Trainingsziel als auch als Evaluierungsmetrik. In diesem umfassenden Leitfaden untersuchen wir, was der Kreuzentropieverlust ist, wie er speziell im Kontext von funktioniert Großspracher Modelle (LLMs)und warum es so wichtig ist, die Modellleistung zu verstehen.
Egal, ob Sie ein maschinelles Lernpraktiker, ein Forscher oder ein jemand verstehen, der verstehen, wie moderne KI -Systeme geschult und bewertet werden, dieser Artikel bietet Ihnen ein gründliches Verständnis des Cross -Entropy -Verlusts und ihrer Bedeutung in der Welt der Sprachmodellierung.
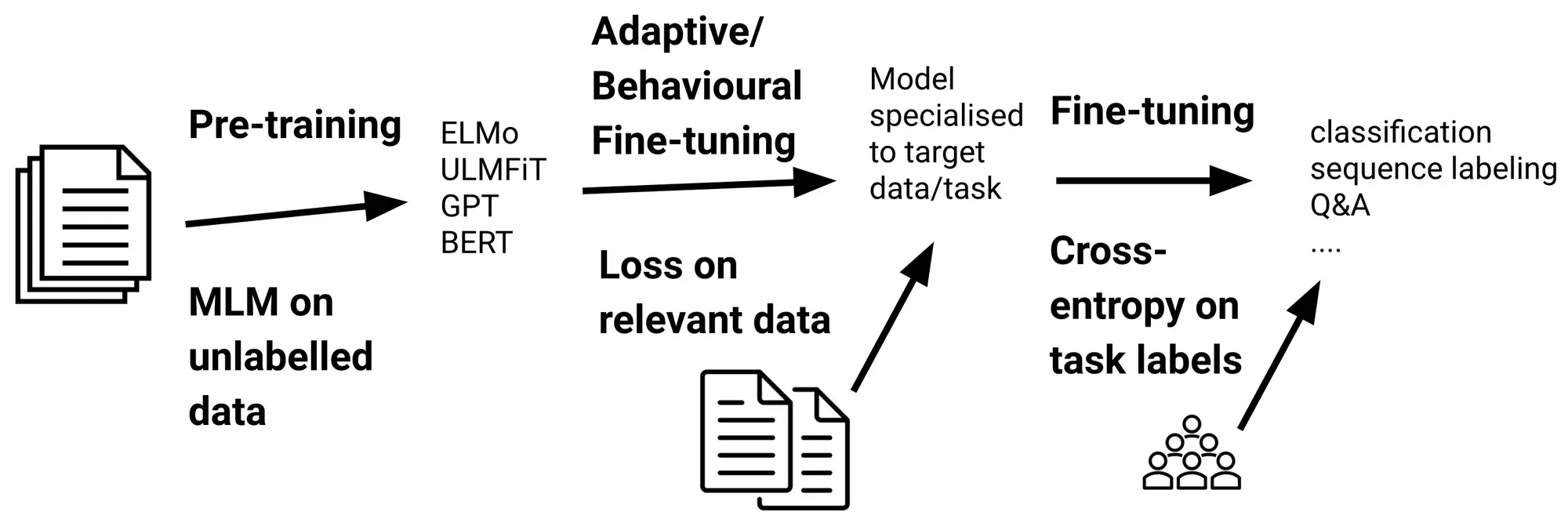
Was ist Cross -Entropy -Verlust?
Cross -Entropy -Verlust misst die Leistung von a Einstufung Modell, dessen Ausgabe eine Wahrscheinlichkeitsverteilung ist. Im Kontext von Sprachmodellen quantifiziert es den Unterschied zwischen der vorhergesagten Wahrscheinlichkeitsverteilung des nächsten Tokens und der tatsächlichen Verteilung (normalerweise einem hot-codierten Vektor, der das wahre Subsequent-Token darstellt).
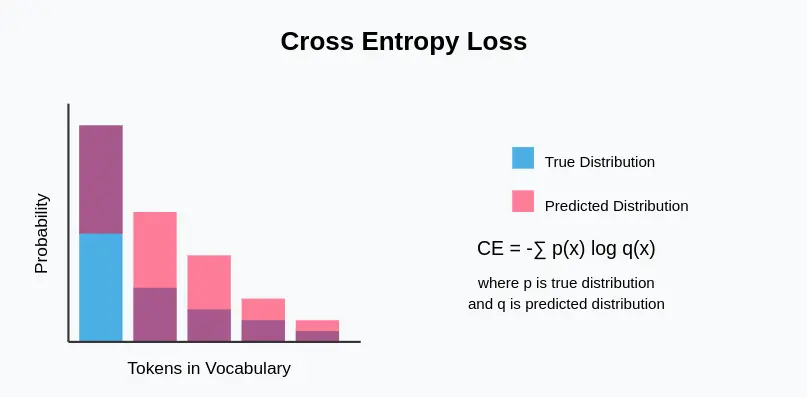
Schlüsselmerkmale des Cross-Entropy-Verlusts
- Informationstheoriestiftung: Die in der Informationstheorie verwurzelte Cross -Entropie misst, wie viele Informationen erforderlich sind, um Ereignisse aus einer Wahrscheinlichkeitsverteilung (die wahre Verteilung) zu identifizieren, wenn ein Codierungsschema für eine andere Verteilung (die vorhergesagte) optimiert wird.
- Probabilistische Ausgabe: Arbeitet mit Modellen, die Wahrscheinlichkeitsverteilungen und nicht deterministische Ausgaben erzeugen.
- Asymmetrisch: Im Gegensatz zu einigen anderen Distanzmetriken ist die Kreuzentropie nicht symmetrisch – die Reihenfolge der wahren und vorhergesagten Verteilungen.
- Differenzierbar: Kritisch für gradientenbasierte Optimierungsmethoden, die im neuronalen Netzwerktraining verwendet werden.
- Vertrauensempfindlich.
Lesen Sie auch: Wie bewerten Sie ein großes Sprachmodell (LLM)?
Binärkreuzentropie & Formel
Für binäre Klassifizierungsaufgaben (wie einfach Ja/Nein Fragen oder Stimmungsanalyse), binäre Kreuzentropie wird verwendet:
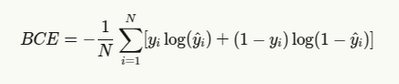
Wo:
- yi ist das wahre Etikett (0 oder 1)
- yi ist die vorhergesagte Wahrscheinlichkeit
- N ist die Anzahl der Proben
Binärer Kreuzentropie ist auch als bekannt als Protokollverlustinsbesondere bei maschinellen Lernwettbewerben.
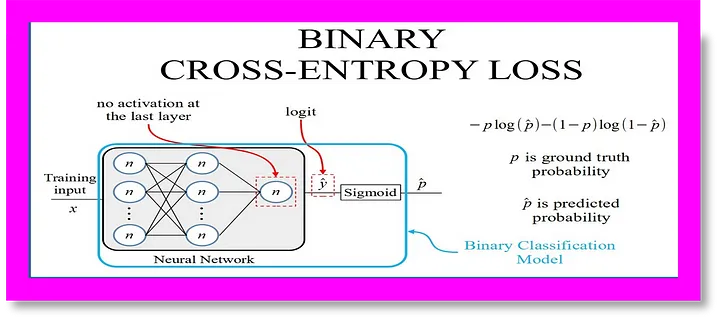
Kreuzentropie als Verlustfunktion
Während des Trainings dient Cross Entropy als objektive Funktion, die das Modell minimieren versucht. Durch Vergleich der vorhergesagten Wahrscheinlichkeitsverteilung des Modells mit der Grundwahrheit passt der Trainingsalgorithmus die Modellparameter an, um die Diskrepanz zwischen Vorhersagen und Realität zu verringern.
Die Rolle von Entropy in LLMs überschreiten
In Großsprachenmodellen spielt der Verlust von Cross Entropy mehrere entscheidende Rollen:
- Trainingsziel: Das Hauptziel während der Voraussetzung und der Feinabstimmung ist die Minimierung des Verlusts.
- Bewertungsmetrik: Wird verwendet, um die Modellleistung an gehaltenen Daten zu bewerten.
- Verwirrungsberechnung: Verwirrung, eine weitere häufige LLM -Bewertungsmetrik, wird von der Kreuzentropie abgeleitet: Verwirrung = 2^{Crossentropy}.
- Modellvergleich: Verschiedene Modelle können basierend auf ihrem Verlust auf demselben Datensatz verglichen werden.
- Bewertung der Lernung von Übertragung: Dies kann angeben, wie intestine ein Modell das Wissen von der Vorausbildung auf nachgeschaltete Aufgaben überträgt.
Wie funktioniert es?
Für Sprachmodelle funktioniert der Verlust von Cross Entropy wie folgt:
- Das Modell prognostiziert eine Wahrscheinlichkeitsverteilung über den gesamten Wortschatz für das nächste Token.
- Diese Verteilung wird mit der tatsächlichen Verteilung verglichen (normalerweise ein HOT-Vektor, bei dem das tatsächliche Subsequent-Token Wahrscheinlichkeit 1 hat).
- Die damaging Log-Chance des wahren Tokens unter der Verteilung des Modells wird berechnet.
- Dieser Wert wird in der Sequenz oder dem Datensatz über alle Token gemittelt.
Formeln und Erklärung
Die allgemeine Formel für den Verlust des Kreuzentropie -Verlusts bei der Sprachmodellierung lautet:
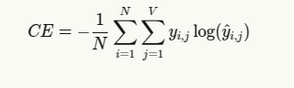
Wo:
- N ist die Anzahl der Token in der Sequenz
- V ist die Wortschatzgröße
- yichJ ist 1, wenn Token J das richtige neben Token an Place I ist, sonst 0
- yichJ ist die vorhergesagte Wahrscheinlichkeit von Token J an Place I.
Da wir uns normalerweise mit einer mit einem heißen kodierten Bodenwahrheit zu beschäftigen, vereinfacht dies zu:
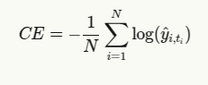
Wo tichIst der Index des wahren Tokens an Place i.
Implementierung der Entropieverlust im Pytorch- und Tensorflow -Code
# PyTorch Implementation
import torch
import torch.nn as nn
import torch.nn.purposeful as F
import numpy as np
import matplotlib.pyplot as plt
# Easy Language Mannequin in PyTorch
class SimpleLanguageModel(nn.Module):
def __init__(self, vocab_size, embedding_dim, hidden_dim):
tremendous(SimpleLanguageModel, self).__init__()
self.embedding = nn.Embedding(vocab_size, embedding_dim)
self.lstm = nn.LSTM(embedding_dim, hidden_dim, batch_first=True)
self.fc = nn.Linear(hidden_dim, vocab_size)
def ahead(self, x):
# x form: (batch_size, sequence_length)
embedded = self.embedding(x) # (batch_size, sequence_length, embedding_dim)
lstm_out, _ = self.lstm(embedded) # (batch_size, sequence_length, hidden_dim)
logits = self.fc(lstm_out) # (batch_size, sequence_length, vocab_size)
return logits
# Guide Cross Entropy Loss calculation
def manual_cross_entropy_loss(logits, targets):
"""
Computes cross entropy loss manually
Args:
logits: Uncooked mannequin outputs (batch_size, sequence_length, vocab_size)
targets: True token indices (batch_size, sequence_length)
"""
batch_size, seq_len, vocab_size = logits.form
# Reshape for simpler processing
logits = logits.reshape(-1, vocab_size) # (batch_size*sequence_length, vocab_size)
targets = targets.reshape(-1) # (batch_size*sequence_length)
# Convert logits to chances utilizing softmax
probs = F.softmax(logits, dim=1)
# Get chance of the right token for every place
correct_token_probs = probs(vary(len(targets)), targets)
# Compute damaging log chance
nll = -torch.log(correct_token_probs + 1e-10) # Add small epsilon to stop log(0)
# Common over all tokens
loss = torch.imply(nll)
return loss
# Instance utilization
def pytorch_example():
# Parameters
vocab_size = 10000
embedding_dim = 128
hidden_dim = 256
batch_size = 32
seq_length = 50
# Pattern knowledge
inputs = torch.randint(0, vocab_size, (batch_size, seq_length))
targets = torch.randint(0, vocab_size, (batch_size, seq_length))
# Create mannequin
mannequin = SimpleLanguageModel(vocab_size, embedding_dim, hidden_dim)
# Get mannequin outputs
logits = mannequin(inputs)
# PyTorch's built-in loss perform
criterion = nn.CrossEntropyLoss()
# For CrossEntropyLoss, we have to reshape
pytorch_loss = criterion(logits.view(-1, vocab_size), targets.view(-1))
# Our guide implementation
manual_loss = manual_cross_entropy_loss(logits, targets)
print(f"PyTorch CrossEntropyLoss: {pytorch_loss.merchandise():.4f}")
print(f"Guide CrossEntropyLoss: {manual_loss.merchandise():.4f}")
return mannequin, logits, targets
# TensorFlow Implementation
def tensorflow_implementation():
import tensorflow as tf
# Parameters
vocab_size = 10000
embedding_dim = 128
hidden_dim = 256
batch_size = 32
seq_length = 50
# Easy Language Mannequin in TensorFlow
class TFSimpleLanguageModel(tf.keras.Mannequin):
def __init__(self, vocab_size, embedding_dim, hidden_dim):
tremendous(TFSimpleLanguageModel, self).__init__()
self.embedding = tf.keras.layers.Embedding(vocab_size, embedding_dim)
self.lstm = tf.keras.layers.LSTM(hidden_dim, return_sequences=True)
self.fc = tf.keras.layers.Dense(vocab_size)
def name(self, x):
embedded = self.embedding(x)
lstm_out = self.lstm(embedded)
return self.fc(lstm_out)
# Create mannequin
tf_model = TFSimpleLanguageModel(vocab_size, embedding_dim, hidden_dim)
# Pattern knowledge
tf_inputs = tf.random.uniform((batch_size, seq_length), minval=0, maxval=vocab_size, dtype=tf.int32)
tf_targets = tf.random.uniform((batch_size, seq_length), minval=0, maxval=vocab_size, dtype=tf.int32)
# Get mannequin outputs
tf_logits = tf_model(tf_inputs)
# TensorFlow's built-in loss perform
tf_loss_fn = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True)
tf_loss = tf_loss_fn(tf_targets, tf_logits)
# Guide cross entropy calculation in TensorFlow
def tf_manual_cross_entropy(logits, targets):
batch_size, seq_len, vocab_size = logits.form
# Reshape
logits_flat = tf.reshape(logits, (-1, vocab_size))
targets_flat = tf.reshape(targets, (-1))
# Convert to chances
probs = tf.nn.softmax(logits_flat, axis=1)
# Get right token chances
indices = tf.stack((tf.vary(tf.form(targets_flat)(0), dtype=tf.int32), tf.solid(targets_flat, tf.int32)), axis=1)
correct_probs = tf.gather_nd(probs, indices)
# Compute loss
loss = -tf.reduce_mean(tf.math.log(correct_probs + 1e-10))
return loss
manual_tf_loss = tf_manual_cross_entropy(tf_logits, tf_targets)
print(f"TensorFlow CrossEntropyLoss: {tf_loss.numpy():.4f}")
print(f"Guide TF CrossEntropyLoss: {manual_tf_loss.numpy():.4f}")
return tf_model, tf_logits, tf_targets
# Visualizing Cross Entropy
def visualize_cross_entropy():
# True label is 1 (one-hot encoding could be (0, 1))
true_label = 1
# Vary of predicted chances for sophistication 1
predicted_probs = np.linspace(0.01, 0.99, 100)
# Calculate cross entropy loss for every predicted chance
cross_entropy = (-np.log(p) if true_label == 1 else -np.log(1-p) for p in predicted_probs)
# Plot
plt.determine(figsize=(10, 6))
plt.plot(predicted_probs, cross_entropy)
plt.title('Cross Entropy Loss vs. Predicted Chance (True Class = 1)')
plt.xlabel('Predicted Chance for Class 1')
plt.ylabel('Cross Entropy Loss')
plt.grid(True)
plt.axvline(x=1.0, colour="r", linestyle="--", alpha=0.5, label="True Chance = 1.0")
plt.legend()
plt.present()
# Visualize loss panorama for binary classification
probs_0 = np.linspace(0.01, 0.99, 100)
probs_1 = 1 - probs_0
# Calculate loss for true label = 0
loss_true_0 = (-np.log(1-p) for p in probs_0)
# Calculate loss for true label = 1
loss_true_1 = (-np.log(p) for p in probs_0)
plt.determine(figsize=(10, 6))
plt.plot(probs_0, loss_true_0, label="True Label = 0")
plt.plot(probs_0, loss_true_1, label="True Label = 1")
plt.title('Cross Entropy Loss for Completely different True Labels')
plt.xlabel('Predicted Chance for Class 1')
plt.ylabel('Cross Entropy Loss')
plt.legend()
plt.grid(True)
plt.present()
# Run examples
if __name__ == "__main__":
print("PyTorch Instance:")
pt_model, pt_logits, pt_targets = pytorch_example()
print("nTensorFlow Instance:")
strive:
tf_model, tf_logits, tf_targets = tensorflow_implementation()
besides ImportError:
print("TensorFlow not put in. Skipping TensorFlow instance.")
print("nVisualizing Cross Entropy:")
visualize_cross_entropy()Codeanalyse:
Ich habe den Verlust von Cross-Entropy-Verlust sowohl in Pytorch als auch in TensorFlow implementiert und sowohl integrierte Funktionen als auch manuelle Implementierungen angezeigt. Gehen wir durch die Schlüsselkomponenten:
- SimpleAluagemodel: Ein grundlegendes LSTM-basierter Sprachmodell, das die Wahrscheinlichkeiten für das nächste Token vorhersagt.
- Manuelle Cross -Entropie -Implementierung: Zeigt, wie die Kreuzentropie aus den ersten Prinzipien berechnet wird:
- Konvertieren Sie die Protokolls mit Softmax in Wahrscheinlichkeiten
- Extrahieren Sie die Wahrscheinlichkeit des richtigen Tokens
- Nehmen Sie das damaging Protokoll dieser Wahrscheinlichkeiten
- Durchschnitt über alle Token
- Visualisierungen: Der Code enthält Visualisierungen, die zeigen, wie sich der Verlust mit unterschiedlichen vorhergesagten Wahrscheinlichkeiten ändert.
Ausgabe:
PyTorch Instance:PyTorch CrossEntropyLoss: 9.2140
Guide CrossEntropyLoss: 9.2140
TensorFlow Instance:
TensorFlow CrossEntropyLoss: 9.2103
Guide TF CrossEntropyLoss: 9.2103
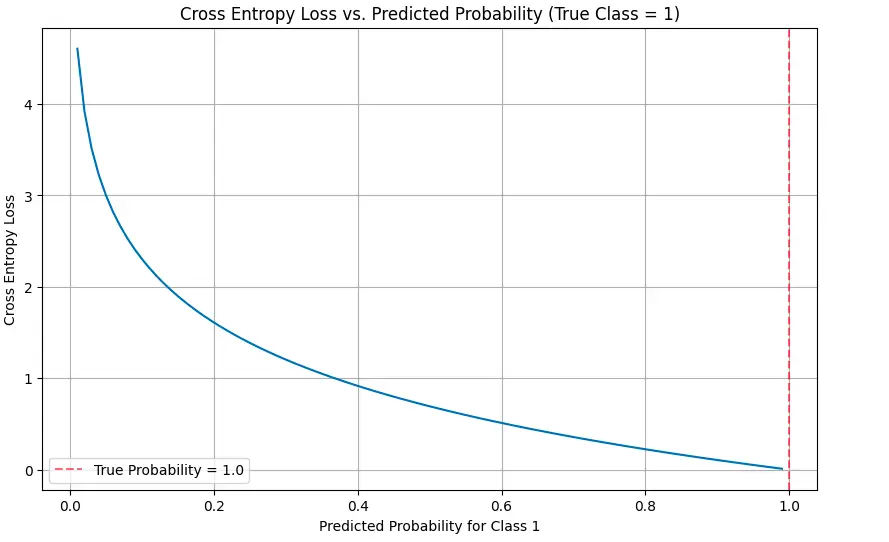
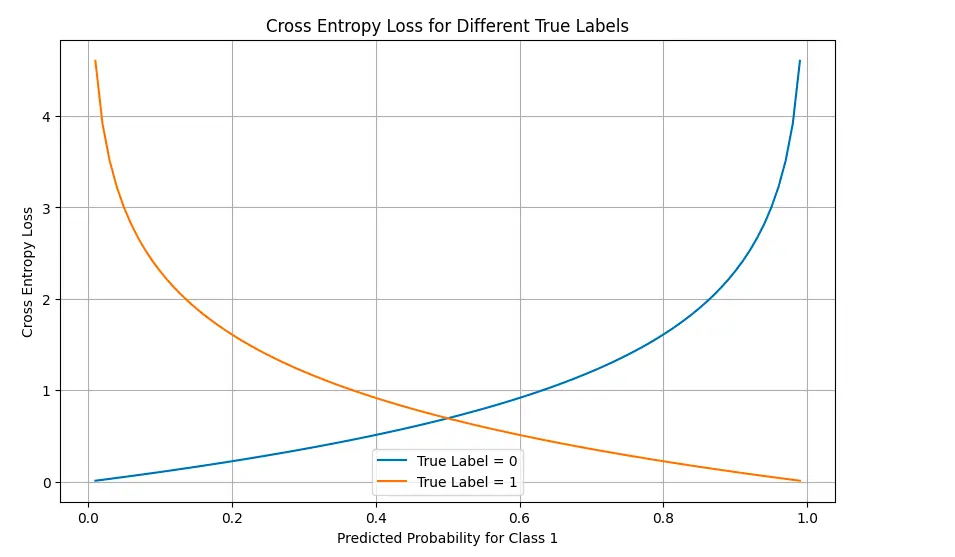
Die Visualisierungen veranschaulichen, wie der Verlust dramatisch zunimmt, wenn Vorhersagen von den wahren Beschriftungen abweichen, insbesondere wenn das Modell zuversichtlich falsch ist.
Vorteile und Einschränkungen
| Vorteile | Einschränkungen |
| Differenzierbar und reibungslos und ermöglichen die optimierung von Gradientenbasis | Kann mit sehr kleinen Wahrscheinlichkeiten numerisch instabil sein (erfordert das Umgang mit Epsilon) |
| Natürlich behandelt die probabilistischen Ausgänge | Möglicherweise benötigt Etikettenglättung, um ein Überbewusstsein zu verhindern |
| Intestine geeignet für Probleme mit mehreren Klassen | Kann von gemeinsamen Klassen in unausgeglichenen Datensätzen dominiert werden |
| Theoretisch begründet in der Informationstheorie | Optimiert nicht direkt für bestimmte Bewertungsmetriken (wie Bleu oder Rouge) |
| Rechnerisch effizient | Angenommen, Token sind unabhängig und ignorieren sequentielle Abhängigkeiten |
| Bestraft selbstbewusste, aber falsche Vorhersagen | Weniger interpretierbar als Metriken wie Genauigkeit oder Verwirrung |
| Kann professional Token zur Analyse zersetzt werden | Die semantische Ähnlichkeit zwischen Tokens nicht berücksichtigt |
Praktische Anwendungen
Der Verlust des Kreuzentropieverlusts wird ausführbar in Sprachmodellanwendungen verwendet:
- Schulungsfundamentmodelle: Cross-Entropy-Verlust ist die Customary-Objektivfunktion für Großsprachenmodelle vor dem Coaching zu massiven Textkorpora.
- Feinabstimmung: Bei der Anpassung vor ausgebildeter Modelle an bestimmte Aufgaben bleibt die Cross-Entropie die Fachfunktion.
- Sequenzgenerierung: Auch wenn Textual content generiert wird, beeinflusst der Verlust während des Trainings die Qualität der Ausgaben des Modells.
- Modellauswahl: Beim Vergleich verschiedener Modellarchitekturen oder Hyperparametereinstellungen ist der Verlust der Validierungsdaten eine Schlüsselmetrik.
- Domänenanpassung: Messen Sie, wie sich die Veränderungen der Kreuzentropie zwischen Domänen ändert, zeigen an, wie intestine ein Modell verallgemeinert wird.
- Wissensdestillation: Wird verwendet, um das Wissen von größeren „Lehrer“ -Modellen auf kleinere „Schüler“ -Modelle zu übertragen.
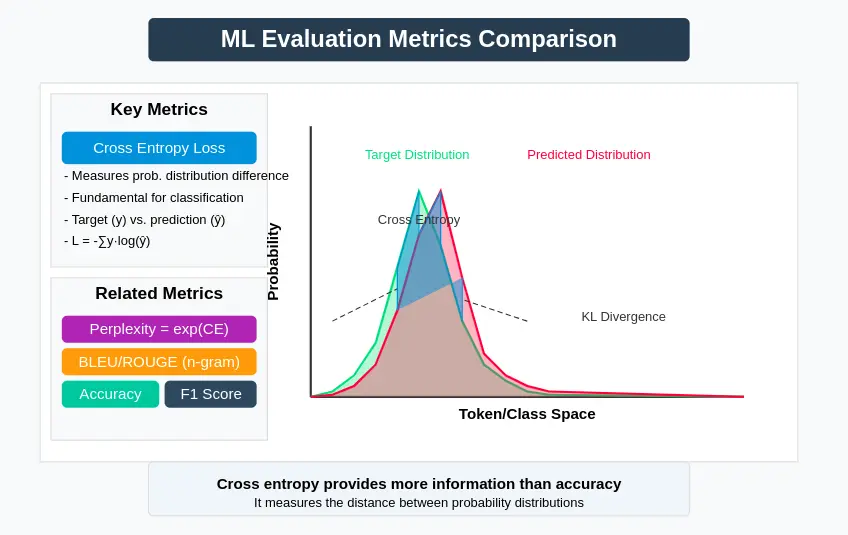
Vergleich mit anderen Metriken
Während der Verlust von Kreuzentropie grundlegend ist, wird er häufig neben anderen Bewertungsmetriken verwendet:
- Verwirrung: Exponential der Kreuzentropie; Interpretierbarer, wie es darstellt, wie „verwirrt“ das Modell ist
- Bleu/ROUGE: Für Erzeugungsaufgaben erfassen diese Metriken die N-Gramm-Überlappung mit Referenztexten
- Genauigkeit: Einfacher Prozentsatz der korrekten Vorhersagen, weniger informativ als Kreuzentropie
- F1 -Punktzahl: Gleiche Präzision und Rückruf für Klassifizierungsaufgaben
- KL -Divergenz: Misst, wie eine Wahrscheinlichkeitsverteilung von einer anderen abweicht
- Entfernung von Earth Mover: Im Gegensatz zur Kreuzentropie berücksichtigt die semantische Ähnlichkeit zwischen Tokens
Lesen Sie auch: High 15 LLM -Bewertungsmetriken, die 2025 untersucht werden sollen
Abschluss
Der Verlust von Cross Entropy ist ein unverzichtbares Werkzeug bei der Bewertung und Ausbildung von Sprachmodellen. Seine theoretischen Grundlagen in der Informationstheorie, kombiniert mit ihren praktischen Vorteilen für die Optimierung, machen es für die meisten NLP -Aufgaben zur Standardwahl.
Das Verständnis des Cross-Entropy-Verlusts bietet Einblicke nicht nur in die Ausbildung von Modellen, sondern auch in ihre grundlegenden Einschränkungen und die Kompromisse bei der Sprachmodellierung. Während sich die Sprachmodelle weiterentwickeln, bleibt der Verlust von Cross Entropy eine Eckpfeilermetrik, die Forschern und Praktikern hilft, den Fortschritt zu messen und Innovationen zu leiten.
Unabhängig davon, ob Sie Ihre Sprachmodelle aufbauen oder vorhandene bewerten, ist ein gründliches Verständnis des Verlusts von Kreuzentropie für fundierte Entscheidungen und die korrekte Interpretation der Ergebnisse von wesentlicher Bedeutung.
Gen AI -Praktikant bei Analytics Vidhya
Abteilung für Informatik, Vellore Institute of Know-how, Vellore, Indien
Ich arbeite derzeit als Normal-AI-Praktikant bei Analytics Vidhya, wo ich zu innovativen KI-gesteuerten Lösungen beiträgt, die Unternehmen dazu befähigen, Daten effektiv zu nutzen. Als Pupil des letzten Jahres am Vellore Institute of Know-how bringe ich eine solide Grundlage für Softwareentwicklung, Datenanalyse und maschinelles Lernen in meine Rolle.
Fühlen Sie sich frei, sich mit mir zu verbinden (E -Mail geschützt)
Melden Sie sich an, um weiter zu lesen und Experten-Kuratinhalte zu genießen.