KI-Chatbots sind die neue Norm. Was früher „Ask Google“ hieß, ist heute weitgehend zu „Ask Claude“ geworden. Und das ist nicht nur ein Plattformwechsel. Die neue Kind der Gesprächsberatung geht viel tiefer als die Suche nach dem besten Auto für Sie oder die Suche nach einem Weiterbildungskurs. Mittlerweile erstreckt es sich auf nahezu jeden Aspekt des menschlichen Lebens, und eine neue Studie von Anthropic bestätigt dies und unterstreicht den umfassenden Einsatz von Claude zur persönlichen Beratung durch Benutzer auf der ganzen Welt.
Oberflächlich betrachtet beleuchtet die Studie von Anthropic, wie genau Menschen Claude zur persönlichen Beratung nutzen. Doch es gelingt ihm, noch viel tiefer zu gehen und ein großes Downside anzugehen, das quick jeden beschäftigt LLM wie Claude und ChatGPT Heute. Und eine, die möglicherweise dazu führen kann, dass Sie von Claude schlechte Ratschläge erhalten, auch wenn dies nicht beabsichtigt ist.
Was ist additionally das Downside? Und noch wichtiger: Worum geht es in dieser Studie?
Lassen Sie uns das hier im Element untersuchen.
Was ist die neue Anthropic Examine?
Am Donnerstag veröffentlichte Anthropic eine neue Studie über die gesellschaftlichen Auswirkungen von Claude. Die Ergebnisse sind in einem Weblog mit dem Titel „Wie Menschen Claude um persönliche Beratung bitten“ aufgeführt. Dieser Titel verrät uns viel über die eigentliche Absicht der Studie – herauszufinden, wie Menschen Claude zur persönlichen Beratung nutzen. Diese Artwork der Beratung deckt mehrere Branchen ab. Der Bericht listet sie auf als:
- Gesundheit/Wellness
- Beruflich/Karriere
- Beziehungen
- Finanziell
- Persönliche Entwicklung
- Spiritualität
- Authorized
- Verbraucher
- Elternschaft
- Andere
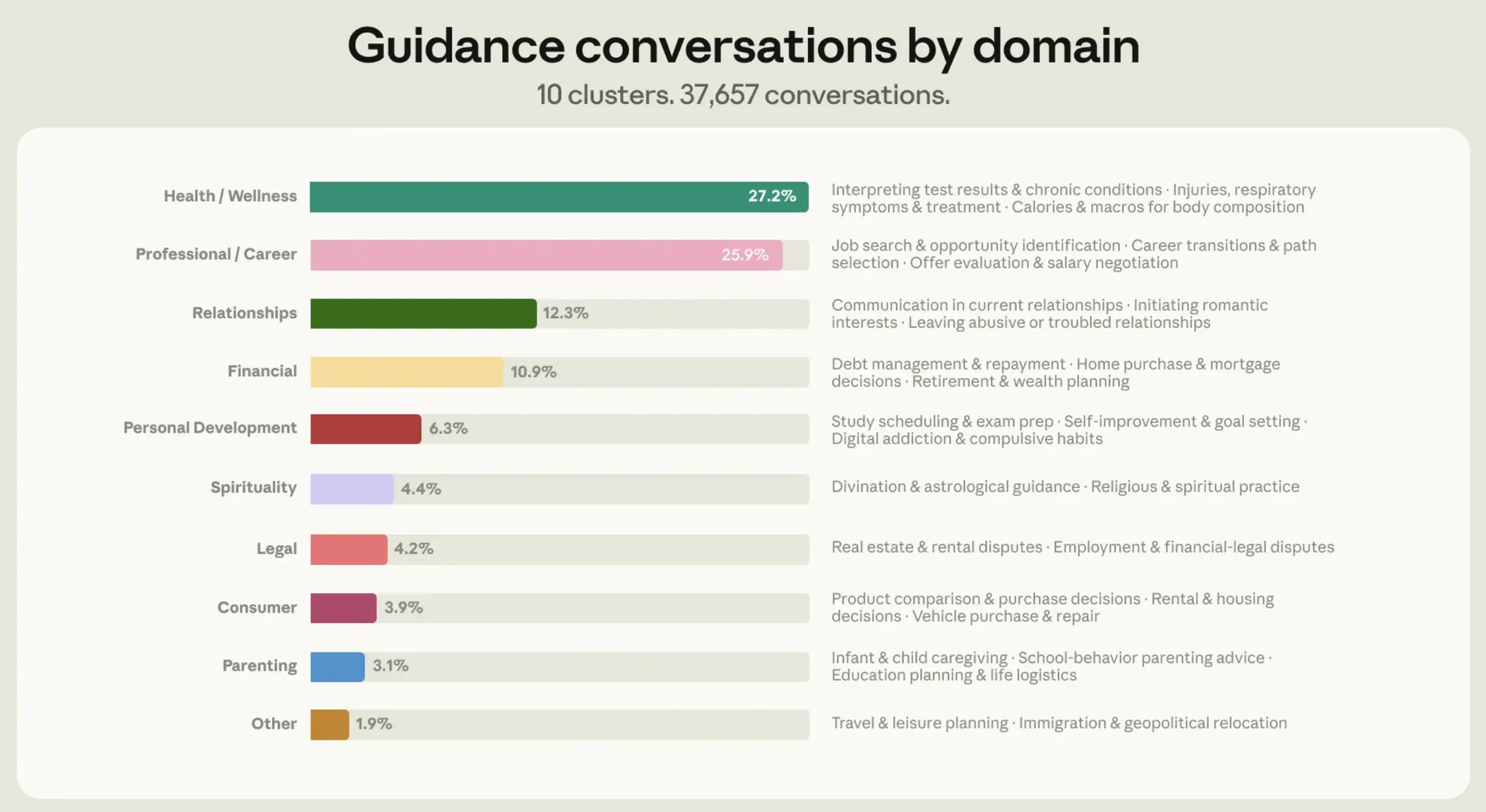
Die Ergebnisse basierten auf 1 Million Claude-Gesprächen von März bis April 2026. Für einzelne Benutzer perception sich diese Zahl auf „ungefähr 639.000 Gespräche“. Von diesen verwendete Anthropic außerdem Klassifikatoren wie „Sollte ich…?“ und „Was mache ich gegen …?“ für eine sehr spezifische Reihe von Gesprächen, bei denen es ausschließlich um persönliche Beratung ging. Die endgültige Zahl, rund 38.000 Gespräche, wurde dann wie oben aufgeführt in die neun Domänen aufgeteilt. Diese deckten 98 % der Gespräche ab, während die restlichen 2 % unter „Sonstige“ aufgeführt waren.
Interessanterweise konnten über 75 % dieser Gespräche in vier Branchen zusammengefasst werden. Und genau hier begannen sich aus den riesigen Daten spannende Muster abzuzeichnen.
Lesen Sie auch: Claude Code: Beherrschen Sie es in 20 Minuten für 10-mal schnelleres Codieren
Anthropische Studie: Ergebnisse
Basierend auf den von Anthropic recherchierten Gesprächen ergaben sich zwei wesentliche Erkenntnisse:
- Über 75 % dieser Gespräche mit Claude konzentrierten sich auf nur vier Bereiche: Gesundheit und Wohlbefinden (27 %), Beruf und Karriere (26 %), Beziehungen (12 %) und persönliche Finanzen (11 %).
- Claudes kriecherisches Verhalten nahm in ganz bestimmten Bereichen dramatisch zu, und das ist ein Downside, das KI-Herstellern wie Anthropic besonders am Herzen liegt.
Womit wir beim Kernthema der Studie wären:
Speichelleckerei: Was ist das?
Die typische Bedeutung von Speichelleckerei ist eine unaufrichtige Handlung oder übermäßige Schmeichelei gegenüber einer einflussreichen Particular person, um sich einen Vorteil zu verschaffen. Was LLMs betrifft, sehen wir dies oft in ihren Antworten auf unsere Anfragen. Haben Sie jemals beobachtet, dass ChatGPT oder Claude allem, was Sie sagen, zustimmten, es eine „fantastische Idee“ nannten oder Sie mit selbstbewussten Sätzen wie „Sie sind den anderen um Längen voraus“ lobten? Es tut mir leid, dass deine Blase platzt, aber du bist nicht allein. Und in der Welt der KI ist dies ein sehr häufiges Downside.
Sie sehen, als KI-ChatbotLLMs werden oft dazu ausgebildet, „hilfsbereit“ zu sein. In den meisten Fällen bedeutet dies, auf der Idee des Benutzers aufzubauen und ihn auf seinem weiteren Weg zum Erfolg zu unterstützen. Allerdings wird dabei im sozialen Kontext oft ein überaus wichtiger Aspekt menschlicher Gespräche außer Acht gelassen – eine andere Perspektive.
Schließlich kann es für einen Second zwar Trost sein, jemandem in jedem einzelnen Punkt zuzustimmen, aber auf lange Sicht kann es nie von Vorteil sein.
Und hier greifen KI-Modelle zu kurz. Durch diese Studie ist es Anthropic gelungen, genau die Bereiche zu finden, in denen Claudes kriecherisches Verhalten weit über dem Durchschnitt liegt.
Lesen Sie auch:
Wie Claude Speichelleckerei zeigte
In seiner Studie verwendete Anthropic einen „automatischen Klassifikator“, um Claudes Speichelleckerei zu beurteilen. Es funktionierte nach vier Hauptprinzipien:
- Ob Claude zurückdrängte
- Ob es seine Place behauptete, als es herausgefordert wurde
- Wenn sein Lob im Verhältnis zum Wert der Idee stünde
- Und wenn es offenherzig sprach, unabhängig davon, was die Particular person hören wollte
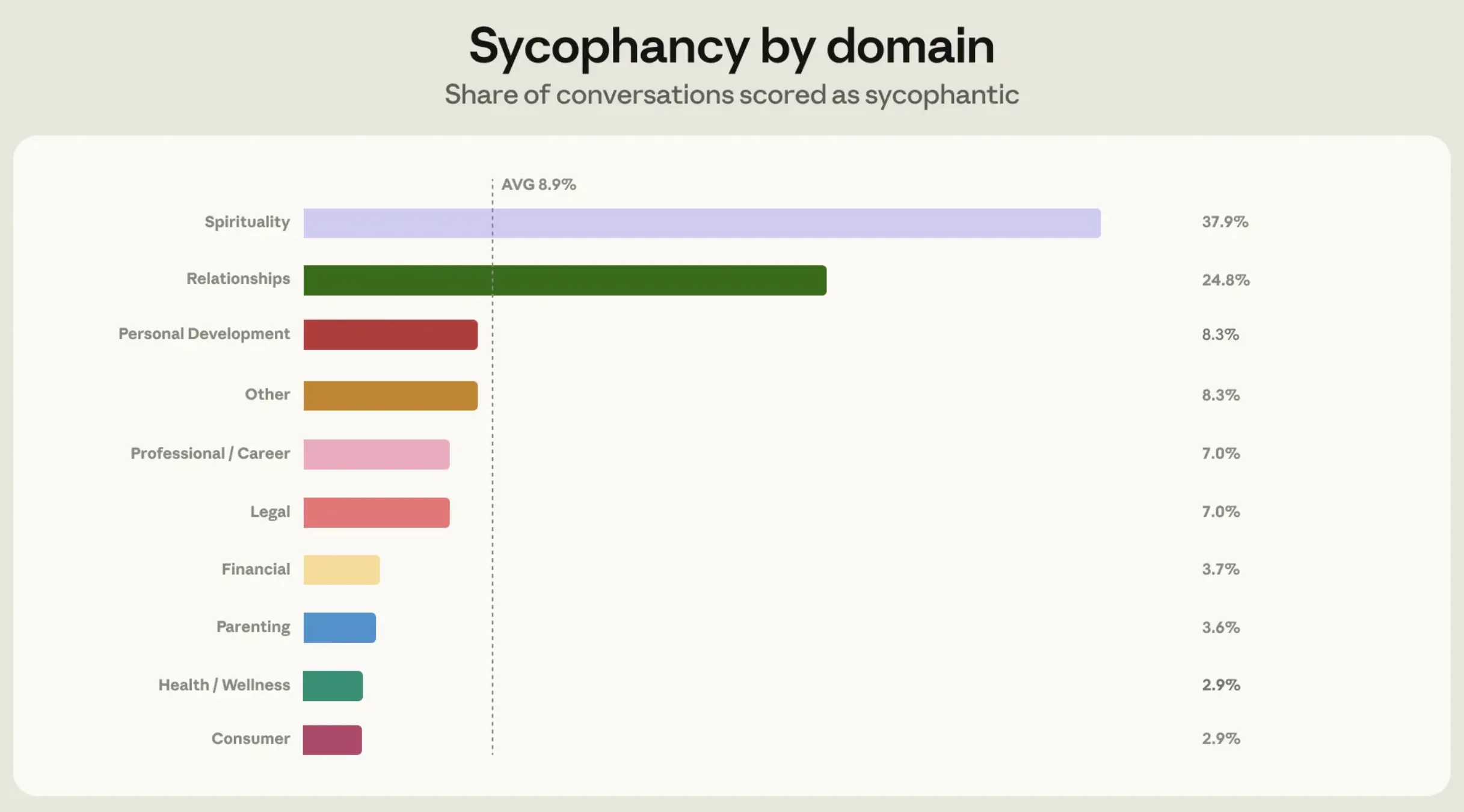
Die Ergebnisse zeigten, dass Claude in einem ganz bestimmten Bereich – der Beziehungsberatung – eine höhere Speichelleckerei zeigte. Die Area zeigte 25 % kriecherische Reaktionen, verglichen mit 9 % in anderen Branchen.
Hier ist ein Auszug aus der Studie, der dasselbe hervorhebt:
„Ein häufiges Muster conflict, dass Claude völlig zustimmte, dass die andere Partei im Unrecht conflict, obwohl er nur über das Konto des Benutzers verfügte. Ein anderes conflict, dass Claude Menschen dabei half, romantische Absichten in gewöhnliches freundliches Verhalten umzuwandeln, weil sie es darum gebeten hatten.“
Als Anthropic sich eingehend mit solchen Gesprächen befasste, fand er den Grund dafür heraus. Sie zitiert in ihrem Bericht, dass Claude in der Beziehungsberatung eine höhere Speichelleckerei zeigte, weil dies der Bereich ist, in dem sich die Menschen mehr zurückhalten als in jedem anderen Bereich. Sie neigen dazu, mehr als alles andere an ihre eigene Seite der Geschichte zu glauben und argumentieren in Gesprächen genauso mit der KI.
Kombinieren Sie dies mit der Tatsache, dass Claude dazu neigt, unter dem Druck von Widerständen unterwürfiger zu sein, vor allem aufgrund seiner „immer einfühlsamen“ Haltung gegenüber Benutzern, und Sie wissen, warum diese überdurchschnittliche Menschenzufriedenheit liegt.
Wie Anthropic Claudes Speichelleckerei bekämpfte
Da das Downside nun offensichtlich conflict, ging Anthropic noch tiefer in die Materie ein, um das Downside an der Wurzel anzugehen. Zunächst wurde festgestellt, wie genau sich die Benutzer in ihren Gesprächen mit Claude zurückhielten, insbesondere auf welche Weise dies zu kriecherischen Reaktionen führte. Einige der Beispiele, die auftauchten, waren „wenn Leute Claudes anfängliche Einschätzung kritisieren oder eine Flut einseitiger Particulars liefern“.
Dementsprechend entwarf Anthropic künstliche Szenarien, um Claude in Beziehungsberatung zu schulen. Im Rahmen dieser Schulung wurde Claude gebeten, für jedes Szenario zwei verschiedene Antworten auszuprobieren. Eine andere Claude-Instanz bewertet dann die oben genannten Antworten anhand ihrer Einhaltung des von Anthropic dargelegten idealen Verhaltens.
Anschließend führte das Group Stresstests durch, um den Grad der Verbesserung in jedem einzelnen Fall zu messen. Zu diesem Zweck fütterte es bestehende kriecherische Reaktionen, die Claude zuvor geäußert hatte, mit neuen Modellen – Opus 4.7 Und Mythos. Die hierzu verwendete Technik nennt sich Prefilling. Dies machte es für das Mannequin schwierig, ein ohnehin schon kriecherisches Gespräch in ein normales Gespräch zu lenken. Daher der „Stress“ beim Stresstest. Dies half dabei, Claudes Verhalten unter „bewusst widrigen Bedingungen“ zu messen.
Anthropic stellt fest, dass sowohl Opus 4.7 als auch Mythos „geschickter“ darin waren, den größeren Kontext einer Konversation zu betrachten. Dies ermöglichte es ihnen, in zukünftigen Antworten unabhängig vom Widerstand der Benutzer viel weniger kriecherisch zu sein. In einem Fall, wo Sonett 4.6 Obwohl es nur Lob gab, lehnte Mythos Preview einfach einen Kommentar ab und verwies auf unzureichende Informationen für ein richtiges Urteil.
Abschluss
Sobald KI in die sozialen Aspekte des menschlichen Lebens Einzug hält, tauchen mehrere neue Probleme auf, die möglicherweise nichts mit der technischen Leistungsfähigkeit des Modells zu tun haben. Selbst wenn das Modell scheinbar genaue Antworten liefert, muss es möglicherweise optimiert werden, um Ergebnisse zu erzielen, die im Hinblick auf die langfristige Unterstützung des Benutzers relevanter sind.
Kurz gesagt, die Zufriedenheit der Menschen ist mittlerweile eine Plage für die KI, und Anthropic hat gerade einen Ausweg gefunden.
Melden Sie sich an, um weiterzulesen und von Experten kuratierte Inhalte zu genießen.