
https://www.youtube.com/watch?v=tyrln17maxs
In diesem Projektleitungswechsel werde ich mitteilen, wie es geht Analysieren Sie eine Kaggle Information Science -Umfrage Kernfähigkeiten für Datenwissenschaftsfachkräfte zu praktizieren und Einblicke in die Gehaltserwartungen zu erhalten, die auf jahrelanger Erfahrung beruhen. Diese Analyse verwendet grundlegende Python -Fähigkeiten wie Hear, Schleifen und bedingte Logik. Während fortschrittlichere Instruments wie Pandas diesen Prozess rationalisieren könnten, können Sie mit Fundamental Python eine starke Grundlage für die Manipulation und Analyse von Daten aufbauen.
Projektübersicht
Für dieses Projekt übernehmen wir die Rolle eines Datenanalystens für Kaggle, in dem Umfragedaten von Datenwissenschaftlern untersucht werden, die Particulars über:
- Ihre jahrelange Codierungserfahrung (
experience_coding) - Programmiersprachen, die sie verwenden (
python_userAnwesendr_userAnwesendsql_user) - Bevorzugte Bibliotheken und Instruments (
most_used) - Entschädigung (
compensation)
Unser Ziel ist es, zwei wichtige Fragen zu beantworten:
- Welche Programmiersprachen sind unter Datenwissenschaftlern am häufigsten?
- Wie hängt die Vergütung auf jahrelange Erfahrung zusammen?
Einrichten der Umgebung
1. Richten Sie Ihren Arbeitsbereich ein
Wir werden mit einem arbeiten .ipynb Datei, die in den folgenden Instruments wiedergegeben werden kann:
2. Laden Sie die Ressourcendatei herunter
Um dem Tutorial zu folgen, benötigen Sie zwei wesentliche Ressourcen: die Fundamentals.ipynb Jupyter -Notizbuch mit allen Code- und Analyseschritten, die wir gemeinsam untersuchen, und die kaggle2021-short.csv Datensatzdatei, in der die Kaggle -Umfrageantworten untergebracht sind, werden wir analysieren.
Beginnen wir zunächst unsere Daten aus der CSV -Datei. Für diesen anfängerfreundlichen Ansatz werden wir Pythons integriertes CSV-Modul anstelle von Pandas verwenden:
import csv
with open('kaggle2021-short.csv') as f:
reader = csv.reader(f, delimiter=",")
kaggle_data = record(reader)
column_names = kaggle_data(0)
survey_responses = kaggle_data(1:)
print(column_names)
for row in vary(0,5):
print(survey_responses(row))Die Ausgabe zeigt die Säulenstruktur und die ersten Zeilen unserer Daten:
('experience_coding', 'python_user', 'r_user', 'sql_user', 'most_used', 'compensation')
('6.1', 'TRUE', 'FALSE', 'TRUE', 'Scikit-learn', '124267')
('12.3', 'TRUE', 'TRUE', 'TRUE', 'Scikit-learn', '236889')
('2.2', 'TRUE', 'FALSE', 'FALSE', 'None', '74321')
('2.7', 'FALSE', 'FALSE', 'TRUE', 'None', '62593')
('1.2', 'TRUE', 'FALSE', 'FALSE', 'Scikit-learn', '36288')Ausbilderer Perception: Als ich dieses Projekt zum ersten Mal startete, conflict es wichtig, die Rohdaten wie diese zu betrachten. Es zeigte mir sofort, dass alle Werte als Zeichenfolgen gespeichert wurden (beachten Sie die Zitate um die Zahlen), was für numerische Berechnungen nicht funktionieren würde. Nehmen Sie sich immer Zeit, um Ihre Datenstruktur zu verstehen, bevor Sie in die Analyse eintauchen!
Datenreinigung
Die Daten benötigen eine gewisse Reinigung, bevor wir sie ordnungsgemäß analysieren können. Wenn wir die CSV -Datei lesen, kommt alles als Zeichenfolgen, aber wir brauchen:
experience_codingals Float (Dezimalzahl)python_userAnwesendr_userUndsql_userals boolesche Werte (wahr/falsch)most_usedalsNoneoder eine Zeichenfolgecompensationals Ganzzahl
So habe ich jede Spalte in den entsprechenden Datentyp konvertiert:
# Iterate over the indices in order that we are able to replace the entire information
num_rows = len(survey_responses)
for i in vary(num_rows):
# experience_coding
survey_responses(i)(0) = float(survey_responses(i)(0))
# python_user
if survey_responses(i)(1) == "TRUE":
survey_responses(i)(1) = True
else:
survey_responses(i)(1) = False
# r_user
if survey_responses(i)(2) == "TRUE":
survey_responses(i)(2) = True
else:
survey_responses(i)(2) = False
# sql_user
if survey_responses(i)(3) == "TRUE":
survey_responses(i)(3) = True
else:
survey_responses(i)(3) = False
# most_used
if survey_responses(i)(4) == "None":
survey_responses(i)(4) = None
else:
survey_responses(i)(4) = survey_responses(i)(4)
# compensation
survey_responses(i)(5) = int(survey_responses(i)(5))Überprüfen Sie, ob unsere Datenkonvertierung korrekt funktioniert hat:
print(column_names)
for row in vary(0,4):
print(survey_responses(row))Ausgabe:
('experience_coding', 'python_user', 'r_user', 'sql_user', 'most_used', 'compensation')
(6.1, True, False, True, 'Scikit-learn', 124267)
(12.3, True, True, True, 'Scikit-learn', 236889)
(2.2, True, False, False, None, 74321)
(2.7, False, False, True, None, 62593)
Ausbilderer Perception: Ich habe einmal Stunden damit verbracht, zu debuggen, warum Berechnungen nicht funktionierten, nur um zu erkennen, dass ich versuchte, mathematische Operationen für Saiten anstelle von Zahlen auszuführen! Das Überprüfen von Datentypen ist nun einer meiner ersten Schritte in jeder Analyse.
Analyse der Verwendung von Programmiersprache
Nachdem unsere Daten gereinigt werden, lassen Sie uns herausfinden, wie viele Datenwissenschaftler jede Programmiersprache verwenden:
# Initialize counters
python_user_count = 0
r_user_count = 0
sql_user_count = 0
for i in vary(num_rows):
# Detect if python_user column is True
if survey_responses(i)(1):
python_user_count = python_user_count + 1
# Detect if r_user column is True
if survey_responses(i)(2):
r_user_count = r_user_count + 1
# Detect if sql_user column is True
if survey_responses(i)(3):
sql_user_count = sql_user_count + 1Um die Ergebnisse in einem lesbareren Format anzuzeigen, werde ich ein Wörterbuch und formatierte Zeichenfolgen verwenden:
user_counts = {
"Python": python_user_count,
"R": r_user_count,
"SQL": sql_user_count
}
for language, depend in user_counts.gadgets():
print(f"Variety of {language} customers: {depend}")
print(f"Proportion of {language} customers: {depend / num_rows}n")Ausgabe:
Variety of Python customers: 21860
Proportion of Python customers: 0.8416432449081739
Variety of R customers: 5335
Proportion of R customers: 0.20540561352173412
Variety of SQL customers: 10757
Proportion of SQL customers: 0.4141608593539445Ausbilderer Perception: Ich liebe es, F-Strings zu verwenden (formatierte Saiten) zum Anzeigen von Ergebnissen. Bevor ich sie entdeckte, verwendete ich eine String -Verkettung mit + Zeichen und mussten Zahlen in Zeichenfolgen verwendeten str(). F-Sader machen alles sauberer und lesbarer. Fügen Sie einfach eine hinzu f Vor der Zeichenfolge und verwenden Sie lockige Klammern {} Variablen einbeziehen!
Die Ergebnisse zeigen deutlich, dass Python im Bereich Information Science dominiert, wobei über 84% der Befragten es verwenden. SQL ist mit rund 41% die zweitbeliebteste, während R von etwa 20% der Befragten verwendet wird.
Erfahrung und Kompensationsanalyse
Lassen Sie uns nun die zweite Frage untersuchen: Wie hängt die Vergütung auf jahrelange Erfahrung zusammen? Zunächst werde ich diese Spalten in ihre eigenen Hear trennen, damit sie einfacher zu arbeiten können:
# Aggregating all years of expertise and compensation collectively right into a single record
experience_coding_column = ()
compensation_column = ()
for i in vary(num_rows):
experience_coding_column.append(survey_responses(i)(0))
compensation_column.append(survey_responses(i)(5))
# testing that the loop acted as-expected
print(experience_coding_column(0:5))
print(compensation_column(0:5))
Ausgabe:
(6.1, 12.3, 2.2, 2.7, 1.2)
(124267, 236889, 74321, 62593, 36288)Schauen wir uns einige zusammenfassende Statistiken für jahrelange Erfahrung an:
# Summarizing the experience_coding column
min_experience_coding = min(experience_coding_column)
max_experience_coding = max(experience_coding_column)
avg_experience_coding = sum(experience_coding_column) / num_rows
print(f"Minimal years of expertise: {min_experience_coding}")
print(f"Most years of expertise: {max_experience_coding}")
print(f"Common years of expertise: {avg_experience_coding}")Ausgabe:
Minimal years of expertise: 0.0
Most years of expertise: 30.0
Common years of expertise: 5.297231740653729Obwohl diese zusammenfassenden Statistiken hilfreich sind, wird uns eine Visualisierung ein besseres Verständnis für die Verteilung verleihen. Lassen Sie uns ein Histogramm jahrelanger Erfahrung erstellen:
import matplotlib.pyplot as plt
%matplotlib inline
plt.hist(experience_coding_column)
plt.present()
Das Histogramm zeigt, dass die meisten Datenwissenschaftler in der Umfrage relativ wenige Jahre Erfahrung (0-5 Jahre) haben, wobei ein langer Schwanz von Fachleuten mehr Erfahrung verfügen.
Schauen wir uns nun die Vergütungsdaten an:
# Summarizing the compensation column
min_compensation = min(compensation_column)
max_compensation = max(compensation_column)
avg_compensation = sum(compensation_column) / num_rows
print(f"Minimal compensation: {min_compensation}")
print(f"Most compensation: {max_compensation}")
print(f"Common compensation: {spherical(avg_compensation, 2)}")Ausgabe:
Minimal compensation: 0
Most compensation: 1492951
Common compensation: 53252.82Ausbilderer Perception: Als ich zum ersten Mal die maximale Entschädigung von quick 1,5 Millionen US -Greenback sah, conflict ich schockiert! Dies ist wahrscheinlich ein Ausreißer und könnte unser Durchschnitt verzerren. In einer gründlicheren Analyse würde ich dies weiter untersuchen und möglicherweise excessive Ausreißer entfernen. Fragen Sie immer Datenpunkte, die ungewöhnlich hoch oder niedrig erscheinen.
Erstellen wir auch ein Histogramm zur Kompensation:
plt.hist(compensation_column)
plt.present()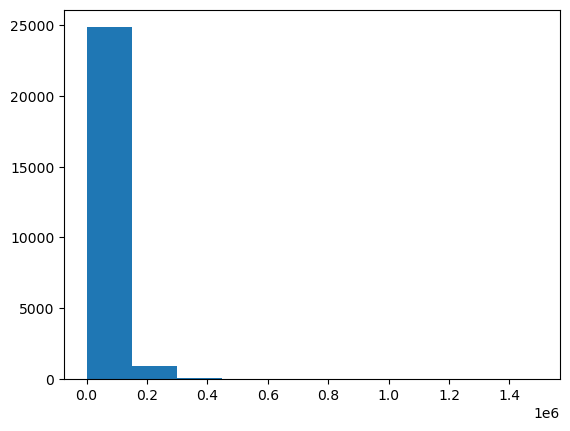
Das Histogramm zur Kompensation ist extrem rechts geschleudert. Die meisten Werte sind auf der linken Seite und einige extrem hohe Werte nach rechts. Dies macht es schwierig, die Particulars der Verteilung zu erkennen.
Analyse der Vergütung nach Erfahrung auf der Ebene
Um die Beziehung zwischen Erfahrung und Kompensation besser zu verstehen, kategorisieren wir die Erfahrung in Behälter und analysieren die durchschnittliche Kompensation für jeden Behälter.
Fügen wir zunächst unserem Datensatz eine neue kategoriale Spalte hinzu, in der jahrelange Erfahrung gruppiert wird:
for i in vary(num_rows):
if survey_responses(i)(0) < 5:
survey_responses(i).append("<5 Years")
elif survey_responses(i)(0) >= 5 and survey_responses(i)(0) < 10:
survey_responses(i).append("5-10 Years")
elif survey_responses(i)(0) >= 10 and survey_responses(i)(0) < 15:
survey_responses(i).append("10-15 Years")
elif survey_responses(i)(0) >= 15 and survey_responses(i)(0) < 20:
survey_responses(i).append("15-20 Years")
elif survey_responses(i)(0) >= 20 and survey_responses(i)(0) < 25:
survey_responses(i).append("20-25 Years")
else:
survey_responses(i).append("25+ Years")Erstellen wir nun separate Hear für die Entschädigung in jedem Erfahrungsbehälter:
bin_0_to_5 = ()
bin_5_to_10 = ()
bin_10_to_15 = ()
bin_15_to_20 = ()
bin_20_to_25 = ()
bin_25_to_30 = ()
for i in vary(num_rows):
if survey_responses(i)(6) == "<5 Years":
bin_0_to_5.append(survey_responses(i)(5))
elif survey_responses(i)(6) == "5-10 Years":
bin_5_to_10.append(survey_responses(i)(5))
elif survey_responses(i)(6) == "10-15 Years":
bin_10_to_15.append(survey_responses(i)(5))
elif survey_responses(i)(6) == "15-20 Years":
bin_15_to_20.append(survey_responses(i)(5))
elif survey_responses(i)(6) == "20-25 Years":
bin_20_to_25.append(survey_responses(i)(5))
else:
bin_25_to_30.append(survey_responses(i)(5))Mal sehen, wie viele Menschen in jeden Erfahrungsbehälter fallen:
# Checking the distribution of expertise within the dataset
print("Individuals with < 5 years of expertise: " + str(len(bin_0_to_5)))
print("Individuals with 5 - 10 years of expertise: " + str(len(bin_5_to_10)))
print("Individuals with 10 - 15 years of expertise: " + str(len(bin_10_to_15)))
print("Individuals with 15 - 20 years of expertise: " + str(len(bin_15_to_20)))
print("Individuals with 20 - 25 years of expertise: " + str(len(bin_20_to_25)))
print("Individuals with 25+ years of expertise: " + str(len(bin_25_to_30)))Ausgabe:
Individuals with < 5 years of expertise: 18753
Individuals with 5 - 10 years of expertise: 3167
Individuals with 10 - 15 years of expertise: 1118
Individuals with 15 - 20 years of expertise: 1069
Individuals with 20 - 25 years of expertise: 925
Individuals with 25+ years of expertise: 941Lassen Sie uns diese Verteilung visualisieren:
bar_labels = ("<5", "5-10", "10-15", "15-20", "20-25", "25+")
experience_counts = (len(bin_0_to_5),
len(bin_5_to_10),
len(bin_10_to_15),
len(bin_15_to_20),
len(bin_20_to_25),
len(bin_25_to_30))
plt.bar(bar_labels, experience_counts)
plt.title("Years of Expertise")
plt.xlabel("Years")
plt.ylabel("Rely")
plt.present()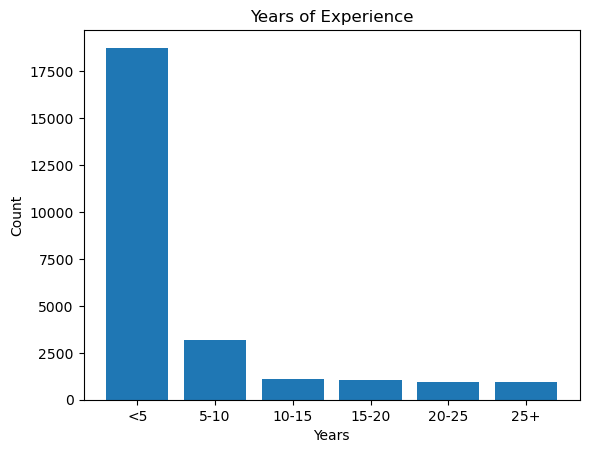
Ausbilderer Perception: Diese Visualisierung zeigt deutlich, dass die überwiegende Mehrheit der Befragten (über 18.000) weniger als 5 Jahre Erfahrung hat. Dies ist sinnvoll, angesichts der schnellen Anlage des Datenwissenschaftsfeldes in den letzten Jahren, und viele Neuankömmlinge treten in den Beruf ein.
Berechnen und zeigen wir nun die durchschnittliche Kompensation für jeden Erfahrungsbehälter:
avg_0_5 = sum(bin_0_to_5) / len(bin_0_to_5)
avg_5_10 = sum(bin_5_to_10) / len(bin_5_to_10)
avg_10_15 = sum(bin_10_to_15) / len(bin_10_to_15)
avg_15_20 = sum(bin_15_to_20) / len(bin_15_to_20)
avg_20_25 = sum(bin_20_to_25) / len(bin_20_to_25)
avg_25_30 = sum(bin_25_to_30) / len(bin_25_to_30)
salary_averages = (avg_0_5,
avg_5_10,
avg_10_15,
avg_15_20,
avg_20_25,
avg_25_30)
# Checking the distribution of expertise within the dataset
print(f"Common wage of individuals with < 5 years of expertise: {avg_0_5}")
print(f"Common wage of individuals with 5 - 10 years of expertise: {avg_5_10}")
print(f"Common wage of individuals with 10 - 15 years of expertise: {avg_10_15}")
print(f"Common wage of individuals with 15 - 20 years of expertise: {avg_15_20}")
print(f"Common wage of individuals with 20 - 25 years of expertise: {avg_20_25}")
print(f"Common wage of individuals with 25+ years of expertise: {avg_25_30}")Ausgabe:
Common wage of individuals with < 5 years of expertise: 45047.87484669119
Common wage of individuals with 5 - 10 years of expertise: 59312.82033470161
Common wage of individuals with 10 - 15 years of expertise: 80226.75581395348
Common wage of individuals with 15 - 20 years of expertise: 75101.82694106642
Common wage of individuals with 20 - 25 years of expertise: 103159.80432432433
Common wage of individuals with 25+ years of expertise: 90444.98512221042Schließlich visualisieren wir diese Beziehung:
plt.bar(bar_labels, salary_averages)
plt.title("Common Wage by Years of Expertise")
plt.xlabel("Years")
plt.ylabel("Wage Common")
plt.axhline(avg_compensation, linestyle="--", shade="black", label="total avg")
plt.present()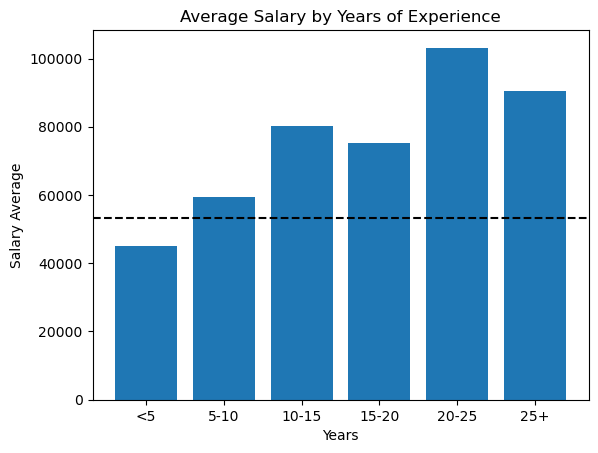
Ausbilderer Perception: Ich conflict überrascht zu sehen, dass die Beziehung zwischen Erfahrung und Gehalt nicht perfekt linear ist. Während die Gehälter im Allgemeinen mit Erfahrung zunehmen, gibt es im Bereich von 15 bis 20 Jahren einen unerwarteten Einbruch. Ich vermute, dass dies möglicherweise auf andere Faktoren wie Industrie, Rollentyp oder Standort zurückzuführen ist, die die Kompensation beeinflussen. Es ist eine Erinnerung daran, dass die Korrelation nicht immer dem Muster folgt, das wir erwarten!
Die horizontale gestrichelte Linie repräsentiert die gesamte durchschnittliche Kompensation über alle Erfahrungsniveaus. Beachten Sie, dass es nur höher als die niedrigste Erfahrung ist, was sinnvoll ist, wenn man bedenkt, dass die Mehrheit der Befragten weniger als 5 Jahre Erfahrung hat und den Gesamtdurchschnitt abfährt.
Schlüsselergebnisse
Aus dieser Analyse können wir mehrere interessante Schlussfolgerungen ziehen:
- Popularität der Programmiersprache: Popularität:
- Python ist bei weitem die beliebteste Sprache, die von 84% der Datenwissenschaftler verwendet wird
- SQL ist mit 41% Nutzung auf dem zweiten Platz
- R ist seltener, aber bei 20% Nutzung immer noch signifikant
- Erfahrungverteilung:
- Die Mehrheit der Datenwissenschaftler (72%) verfügt über weniger als 5 Jahre Erfahrung
- Dies deutet darauf hin, dass Datenwissenschaft ein relativ junges Feld mit vielen Neuankömmlingen ist
- Kompensationstrends:
- Es gibt einen allgemeinen Aufwärtsstrend bei der Entschädigung, wenn die Erfahrung zunimmt
- Die höchste durchschnittliche Vergütung ist für diejenigen mit 20 bis 25 Jahren Erfahrung (~ 103.000 USD)
- Die Beziehung ist nicht perfekt linear, mit einigen Schwankungen des Traits
Nächste Schritte und weitere Analyse
Diese Analyse liefert wertvolle Erkenntnisse, aber es gibt verschiedene Möglichkeiten, sie zu erweitern:
- Untersuchung der Vergütungsausreißer:
- Die maximale Entschädigung von quick 1,5 Millionen US -Greenback scheint ungewöhnlich hoch zu sein und kann unsere Durchschnittswerte verzerren,
- Das Reinigen der Daten zum Entfernen oder Kappenausreißer kann genauere Ergebnisse liefern
- Tiefere Sprachanalyse:
- Korrelieren bestimmte Programmiersprachen mit höheren Gehältern?
- Werden Menschen, die mehrere Sprachen kennen (z. B. Python und SQL), besser?
- Bibliotheks- und Werkzeuganalyse:
- Wir haben das noch nicht erkundet
most_usedSpalte - Verdienen Benutzer bestimmter Bibliotheken (wie TensorFlow vs. Scikit-Study) unterschiedliche Gehälter?
- Wir haben das noch nicht erkundet
- Zeitbasierte Analyse:
- Dieser Datensatz stammt von 2021 – der Vergleich mit neueren Umfragen könnte sich ändernde Traits ergeben
Wenn Sie neu in Python sind, beginnen Sie mit unserer Python -Grundlagen für die Datenanalyse **** Fähigkeitspfad zum Aufbau der für dieses Projekt erforderlichen grundlegenden Fähigkeiten.
Letzte Gedanken
Ich hoffe, dass dieser Vorgang hilfreich conflict, um zu demonstrieren, wie Datenanalyse mit grundlegenden Python -Fähigkeiten durchgeführt werden. Auch ohne fortschrittliche Instruments wie Pandas können wir mithilfe grundlegender Programmierungstechniken aussagekräftige Erkenntnisse aus Daten extrahieren.
Wenn Sie Fragen zu dieser Analyse haben oder Ihre eigenen Erkenntnisse teilen möchten, können Sie sich an der Diskussion in der beteiligen Dataquest -Neighborhood. Ich würde gerne hören, wie Sie sich diesem Datensatz nähern würden!