
In einem früheren Tutorial haben wir behandelt Die Grundlagen von Python for Schleifenuntersuchen, wie man über Hear und Hear von Hear iteriert. Aber es gibt noch viel mehr zu tun for Schleifen als durch Hear abschließend! In realer Datenwissenschaftsarbeit möchten Sie möglicherweise Superior Python verwenden for Schleifen mit anderen Datenstrukturen, einschließlich Numpy Arrays und Pandas DataFrames.
Dieses Tutorial beginnt mit der Verwendung for Schleifen, die durch gemeinsame Python -Datenstrukturen als Hear (wie Tupel und Wörterbücher) iteriert werden. Dann werden wir uns mit dem Gebrauch einlassen for Schleifen im Tandem mit gemeinsamen Python -Datenwissenschaftbibliotheken wie numpyAnwesend pandasUnd matplotlib. Wir werden uns auch das genauer ansehen vary() Funktion und wie es beim Schreiben nützlich ist for Schleifen.
Bevor wir anfangen, möchten Sie sich vielleicht ansehen Der vollständige Python -Leitfaden von DataQuest für Anfänger.
Eine kurze Bewertung: die Python for Schleife
A for Loop ist eine Programmieranweisung, die Python sagt, er solle eine Sammlung von Objekten iterieren und die gleiche Operation für jedes Objekt nacheinander ausführen. Die grundlegende Syntax ist:
for object in collection_of_objects:
# code you wish to execute on every object
Jedes Mal, wenn Python durch die Schleife iteriert, die Variable object übernimmt den Wert des nächsten Objekts in unserer Sequenz collection_of_objectsund Python führt den Code aus, von dem wir in jedem Objekt geschrieben haben collection_of_objects nacheinander.
Lassen Sie uns nun in den Einsatz eingehen for Schleifen mit verschiedenen Arten von Datenstrukturen. Wir werden Hear überspringen, da diese im vorherigen Tutorial behandelt wurden. Wenn Sie eine weitere Überprüfung benötigen, lesen Sie die Einführend Python for Loops Tutorial oder DataQuest Interaktive Lektion auf Hear und for Schleifen.
Datenstrukturen
Tupel
Tupel sind Sequenzen, genau wie Hear. Der Unterschied zwischen Tupeln und Hear besteht darin, dass Tupel unveränderlich sind; das heißt, sie können nicht geändert werden (Erfahren Sie mehr über veränderliche und unveränderliche Objekte in Python). Tupel verwenden auch Klammern anstelle von quadratischen Klammern.
Unabhängig von diesen Unterschieden ist das Schleifen über Tupel sehr ähnlich zu Hear.
x = (10, 20, 30, 40, 50)
for var in x:
print("index "+ str(x.index(var)) + ":", var)
index 0: 10
index 1: 20
index 2: 30
index 3: 40
index 4: 50
Wenn wir eine Liste von Tupeln haben, können wir auf die einzelnen Elemente in jedem Tupel in unserer Liste zugreifen, indem wir sie beide als Variablen in der einbeziehen for Schleife wie so:
x = ((1,2), (3,4), (5,6))
for a, b in x:
print(a, "plus", b, "equals", a+b)
1 plus 2 equals 3
3 plus 4 equals 7
5 plus 6 equals 11
Wörterbücher
Zusätzlich zu Hear und Tupeln sind Wörterbücher ein weiterer häufiger Python -Datentyp, auf den Sie beim Arbeiten mit Daten wahrscheinlich begegnen, und for Schleifen können auch durch Wörterbücher iterieren.
Python-Wörterbücher bestehen aus Schlüsselwertpaaren, sodass in jeder Schleife zwei Elemente, auf die wir zugreifen müssen (den Schlüssel und den Wert). Anstatt zu verwenden enumerate() Wie wir es mit Hear tun würden, um beide Schlüsseln und die entsprechenden Werte für jedes Schlüsselwertpaar zu überschreiten, müssen wir das aufrufen .gadgets() Verfahren.
Stellen Sie sich zum Beispiel vor, wir haben ein Wörterbuch namens shares Das enthält sowohl Aktienkarten als auch die entsprechenden Aktienkurse. Wir werden die verwenden .gadgets() Methode in unserem Wörterbuch zum Generieren eines Schlüssels und Werts für jede Iteration:
shares = {
'AAPL': 187.31,
'MSFT': 124.06,
'FB': 183.50
}
for key, worth in shares.gadgets() :
print(key + " : " + str(worth))
AAPL : 187.31
MSFT : 124.06
FB : 183.5
Beachten Sie, dass die von uns ausgewählten Variablennamen (key Und worth) sind völlig willkürlich – nun nicht völlig willkürlich Da wir uns für beschreibende Namen für sie entschieden haben, was immer eine gute Idee ist, wenn wir uns für variable Namen entscheiden! Alles in allem hätten wir diese Variablen als initialisieren können ok Und v oder x Und y Wenn wir wollten.
Saiten
Wie im Einführungs -Tutorial erwähnt, for Schleifen können auch durch jedes Zeichen in einer Saite iterieren. Als kurze Bewertung funktioniert das, wie das funktioniert:
print("information science")
for c in "information science":
print(c)
information science
d
a
t
a
s
c
i
e
n
c
e
Numpy Arrays
Schauen wir uns nun an, wie for Schleifen können mit gemeinsamen Python -Datenwissenschaftspaketen und ihren Datentypen verwendet werden.
Wir werden uns zunächst ansehen, wie man benutzt for Schleifen mit numpy Arrays, additionally beginnen wir damit, einige Arrays von Zufallszahlen zu erstellen.
import numpy as np
np.random.seed(0)
x = np.random.randint(10, measurement=6)
y = np.random.randint(10, measurement=6)
Das Iterieren über ein eindimensionales Numpy-Array ist dem Iterieren einer Liste sehr ähnlich:
for val in x:
print(val)
5
0
3
3
7
9
Was ist, wenn wir durch ein zweidimensionales Array iterieren wollen? Wenn wir dieselbe Syntax verwenden, um ein zweidimensionales Array wie oben zu iterieren, können wir bei jeder Iteration nur ganze Arrays wiederholen.
z = np.array((x, y))
for val in z:
print(val)
(5 0 3 3 7 9)
(3 5 2 4 7 6)
Ein zweidimensionales Array wird aus einem Paar eindimensionaler Arrays aufgebaut. Um jedes Factor und nicht jedes Array zu besuchen, können wir die Numpy -Funktion verwenden nditer()ein mehrdimensionales Iteratorobjekt, das ein Array als Argument nennt.
Im folgenden Code schreiben wir a for Schleife, die jedes Factor durch Passieren iteriert zunser zweidimensionales Array, als Argument für nditer():
for val in np.nditer(z):
print(val)
5
0
3
3
7
9
3
5
2
4
7
6
Wie wir sehen können, listet dies zuerst alle Elemente in x, dann alle Elemente von y auf.
Erinnern! Wenn Sie diese verschiedenen Datenstrukturen durchlaufen, benötigen Wörterbücher a VerfahrenNumpy Arrays benötigen a Funktion.
Pandas DataFrames
Wenn wir mit Daten in Python arbeiten, verwenden wir oft pandas Datenrahmen. Und zum Glück können wir benutzen for Schleifen auch durch diese iterieren.
Üben wir dies, während wir mit der Arbeit mit dem Arbeiten arbeiten Eine kleine CSV -Datei Dadurch werden das BIP, die Hauptstadt und die Bevölkerung für sechs verschiedene Länder aufgezeichnet. Wir werden dies unten in einem Pandas -Datenframe lesen.
Pandas arbeitet etwas anders als Numpy, sodass wir den Numpy -Prozess, den wir bereits gelernt haben, nicht einfach wiederholen können. Wenn wir versuchen, über einen Pandas -Datenfreame wie ein Numpy -Array zu iterieren, würde dies nur die Spaltennamen ausdrucken:
import pandas as pd
df = pd.read_csv('gdp.csv', index_col=0)
for val in df:
print(val)
Capital
GDP ($US Trillion)
Inhabitants
Stattdessen müssen wir explizit erwähnen, dass wir über die Zeilen des Datenrahmens iterieren möchten. Wir tun dies, indem wir das anrufen iterrows() Methode auf dem DataFrame- und Drucken von Zeilenbezeichnungen und Zeilendaten, wobei eine Zeile die gesamte Pandas -Serie ist.
for label, row in df.iterrows():
print(label)
print(row)
Eire
Capital Dublin
GDP ($US Trillion) 0.3337
Inhabitants 4784000
Identify: Eire, dtype: object
United Kingdom
Capital London
GDP ($US Trillion) 2.622
Inhabitants 66040000
Identify: United Kingdom, dtype: object
United States
Capital Washington, D.C.
GDP ($US Trillion) 19.39
Inhabitants 327200000
Identify: United States, dtype: object
China
Capital Beijing
GDP ($US Trillion) 12.24
Inhabitants 1386000000
Identify: China, dtype: object
India
Capital New Delhi
GDP ($US Trillion) 2.597
Inhabitants 1339000000
Identify: India, dtype: object
Germany
Capital Berlin
GDP ($US Trillion) 3.677
Inhabitants 82790000
Identify: Germany, dtype: object
Wir können auch auf bestimmte Werte aus einer Pandas -Serie zugreifen. Angenommen, wir möchten nur die Hauptstadt jedes Landes ausdrucken. Wir können angeben, dass wir nur aus der Spalte „Kapital“ wie SO OUTIONIEREN möchten:
for label, row in df.iterrows():
print(label + " : " + row("Capital"))
Eire : Dublin
United Kingdom : London
United States : Washington, D.C.
China : Beijing
India : New Delhi
Germany : Berlin
Um die Dinge weiter zu nehmen als einfache Ausdrucke, fügen wir eine Spalte mit a hinzu for Schleife. Fügen wir ein BIP -Professional -Kopf -Spalte hinzu. Denken Sie daran .loc() ist labelbasiert. In dem folgenden Code fügen wir die Spalte hinzu und berechnen ihren Inhalt für jedes Land, indem wir sein Gesamt -BIP von ihrer Bevölkerung trennen und das Ergebnis um eine Billion multiplizieren (da die BIP -Nummern in Billionen aufgeführt sind).
for label, row in df.iterrows():
df.loc(label,'gdp_per_cap') = row('GDP ($US Trillion)')/row('Inhabitants ') * 1000000000000
print(df)
Capital GDP ($US Trillion) Inhabitants
Nation
Eire Dublin 0.3337 4784000
United Kingdom London 2.6220 66040000
United States Washington, D.C. 19.3900 327200000
China Beijing 12.2400 1386000000
India New Delhi 2.5970 1339000000
Germany Berlin 3.6770 82790000
gdp_per_cap
Nation
Eire 69753.344482
United Kingdom 39703.210176
United States 59260.391198
China 8831.168831
India 1939.507095
Germany 44413.576519
Für jede Zeile in unserem Datenrahmen erstellen wir ein neues Etikett und setzen die Zeilendaten dem gesamten BIP auf, das durch die Bevölkerung des Landes geteilt ist, und multiplizieren Sie sie mit $ 1T für Tausende von Greenback.
Der vary() Funktion
Wir haben gesehen, wie wir benutzen können for Schleifen zur ITERATION über jede Sequenz- oder Datenstruktur. Aber was ist, wenn wir diese Sequenzen in einer bestimmten Reihenfolge oder für eine bestimmte Anzahl von Malen übernehmen möchten?
Dies kann mit Pythons eingebautem erreicht werden vary() Funktion. Abhängig davon, wie viele Argumente Sie an die Funktion übergeben, können Sie entscheiden, wo diese Reihe von Zahlen beginnen und enden, und wie groß der Unterschied zwischen einer und nächsten Zahl sein wird. Beachten Sie, dass ähnlich wie Hear die vary() Die Anzahl der Funktionen beginnt von 0 und nicht von 1.
Es gibt drei Möglichkeiten, wie wir anrufen können vary():
vary(cease)vary(begin, cease)vary(begin, cease, step)
vary(cease)
Wenn wir über eine Reihe von aufeinanderfolgenden Ganzzahlen iterieren wollen, die bei 0 beginnen und jede Zahl bis zu, aber bis zu, aber nicht einschließlichDie cease Wert, wir verwenden vary(cease).
for i in vary(3):
print(i)
0
1
2
vary(begin, cease)
Hier wollen wir auch das Ende der Serie festlegen (cease) aber auch der Anfang (begin) sowie. Wir können die verwenden vary() Funktion zum Generieren einer Integer -Serie von A Zu B (Nicht einbezogen B) Verwenden vary(A, B).
for i in vary(1, 8):
print(i)
1
2
3
4
5
6
7
vary(begin, cease, step)
Neben der Möglichkeit, das festzulegen begin Und cease Werte können wir auch die Differenz zwischen einer Zahl in der Sequenz und der nächsten einstellen a festlegen a step Wert beim Anruf vary(begin, cease, step). Der Customary step Der Wert ist 1, wenn keiner bereitgestellt wird.
for i in vary(3, 16, 3):
print(i)
3
6
9
12
15
Beachten Sie, dass step Funktioniert auch für nicht numerische Sequenzen.
Wir können den Elementindex auch in einer Sequenz verwenden, um zu iterieren. Die Schlüsselidee besteht darin, zuerst die Länge der Liste zu berechnen und dann die Sequenz innerhalb des Bereichs dieser Länge zu iterieren. Schauen wir uns ein Beispiel an:
languages = ('Spanish', 'English', 'French', 'German', 'Irish', 'Chinese language')
for idx in vary(len(languages)):
print('Language:', languages(idx))
Language: Spanish
Language: English
Language: French
Language: German
Language: Irish
Language: Chinese language
In unserem for Schleifen oben verwenden wir den Index der Variablen (idx) und Sprache die in Schlüsselwort und die vary() Funktion zum Erstellen einer Abfolge von Zahlen. Beachten Sie, dass wir auch die verwenden len() Funktion in diesem Fall, da die Liste nicht numerisch ist.
Für jede Iteration führen wir unsere aus print Stellungnahme. Additionally für jeden Index im Bereich len(languages)Wir möchten seine zugehörige Sprache drucken. Weil die Länge unserer languages Sequenz ist 6 (das ist der Wert, der len(langauges) bewertet), wir können die Aussage wie folgt umschreiben:
for idx in vary(6):
print('Language:', languages(idx))
Language: Spanish
Language: English
Language: French
Language: German
Language: Irish
Language: Chinese language
Planung mit for Schleifen
Angenommen, wir wollen durch eine Sammlung iterieren und jedes Factor verwenden, um eine Nebenhandlung oder sogar für jede Spur in einem einzelnen Diagramm zu erzeugen. Nehmen wir zum Beispiel die Bevölkerung Iris -Datensatz (Erfahren Sie mehr über diese Daten) und etwas planen mit for Schleifen. Betrachten Sie die Grafik unten.
import pandas as pd
import matplotlib.pyplot as plt
%config InlineBackend.figure_format = 'retina' # used to set determine format when working in an interactive pocket book
df = pd.read_csv('iris.csv')
fig, ax = plt.subplots()
ax.scatter(df('sepal_length'), df('sepal_width'))
ax.set_title('Iris Dataset')
ax.set_xlabel('sepal_length')
ax.set_ylabel('sepal_width')
Textual content(0,0.5,'sepal_width')
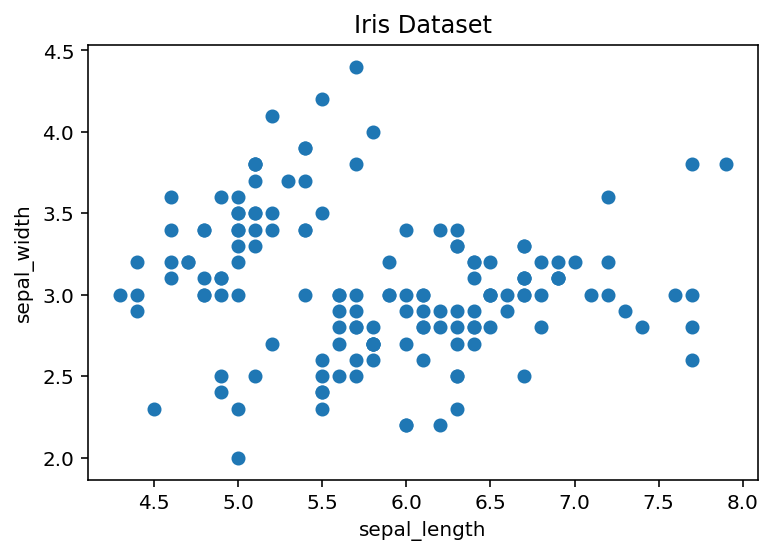
Oben haben wir jede Sepallänge im Vergleich zur Sepalbreite aufgetragen, aber wir können den Diagramm mehr Bedeutung geben, indem wir in jedem Datenpunkt der Artenklasse der einzelnen Blume färben. Eine Möglichkeit, dies zu tun for Schleifen und in die jeweilige Farbe übergeben.
colours = {'setosa':'r', 'versicolor':'g', 'virginica':'b'}
fig, ax = plt.subplots()
for i in vary(len(df('sepal_length'))):
ax.scatter(df('sepal_length')(i), df('sepal_width')(i), colour=colours(df('species')(i)))
ax.set_title('Iris Dataset')
ax.set_xlabel('sepal_length')
ax.set_ylabel('sepal_width')
Textual content(0,0.5,'sepal_width')
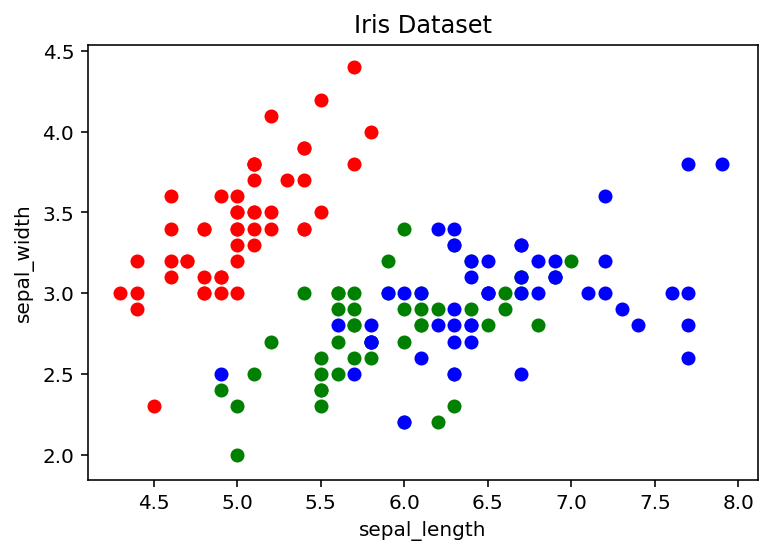
Was ist, wenn wir die univariate Verteilung bestimmter Funktionen unseres Iris -Datensatzes visualisieren möchten? Wir können das mit tun plt.subplot()was eine einzelne Nebenhandlung innerhalb eines Rasters erzeugt, die Zahlen der Spalten und Zeilen, die wir festlegen können.
fig, axes = plt.subplots(nrows=2, ncols=2, figsize=(8, 6))
fig.subplots_adjust(hspace=0.8)
fig.suptitle('Distributions of Iris Options')
for ax, characteristic, identify in zip(axes.flatten(), df.drop('species',axis=1).values.T, df.columns.values):
ax.hist(characteristic, bins=len(np.distinctive(df.drop('species',axis=1).values.T(0))//2))
ax.set(title=identify(:-4).higher(), xlabel='cm')
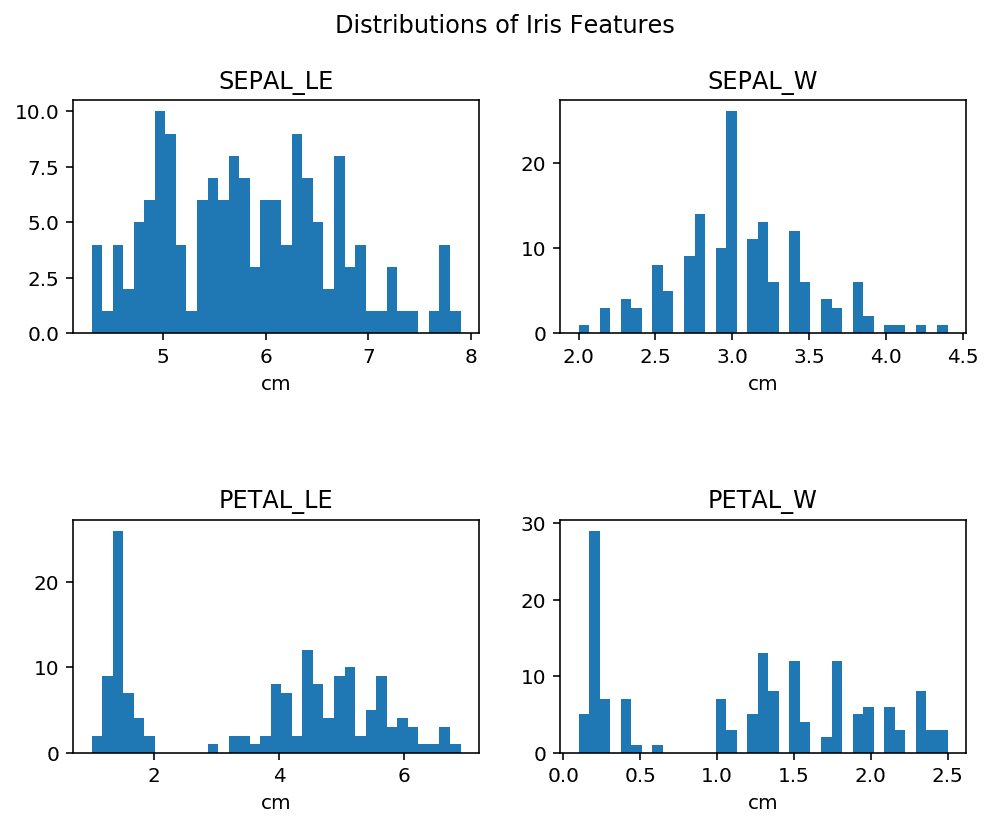
Ohne zu tief in die Matplotlib -Syntax zu tauchen, ist unten eine kurze Beschreibung jeder Hauptkomponente unseres Diagramms:
plt.subplot( )-Wird verwendet, um unser 2-mal-2-Gitter zu erstellen und die Gesamtgröße festzulegen.zip( )– Dies ist eine eingebaute Python-Funktion, die es tremendous einfach macht, in gleichzeitiger Länge über mehrere iterable derselben Länge zu schalten.axes.flatten( )Woflatten( )ist eine Numpy Array -Methode – dies gibt eine abgeflachte Model unserer Arrays (Spalten) zurück.ax.set( )– ermöglicht es uns, alle Attribute unserer festzulegenaxesObjekt mit einer einzelnen Methode.
Zusätzliche Operationen
Verschachtelte Schleifen
Mit Python können wir eine Schleife in einer anderen Schleife verwenden. Dies beinhaltet eine äußere Schleife, die in seinen Befehlen eine innere Schleife hat.
Betrachten Sie die folgende Struktur:
for inner_sequence in sequence:
for factor in inner_sequence:
# code appearing on the element-level goes right here
Verschachtelt for Schleifen können nützlich sein, um Elemente in Hear zu iterieren, die aus Hear bestehen. In einer Liste, die aus Hear besteht, wenn wir nur eine beschäftigen for Schleife gibt das Programm jede interne Liste als Factor aus:
languages = (('Spanish', 'English', 'French', 'German'),
('Python', 'Java', 'Javascript', 'C++'))
for row in languages:
print(row)
('Spanish', 'English', 'French', 'German')
('Python', 'Java', 'Javascript', 'C++')
Um auf jedes einzelne Factor der internen Hear zuzugreifen (dh von, von row), wir definieren eine verschachtelte for Schleife über die Iterationsvariable der Außenschleife (Iterationrow):
for row in languages:
print("------")
for lang in row:
print(lang)
------
Spanish
English
French
German
------
Python
Java
Javascript
C++
Oben die Außen for Die Schleife durchläuft durch die Hauptlistenlisten (die zwei Hear in diesem Beispiel enthält) und das Innere for Die Schleife durchläuft die einzelnen Hear selbst. Die äußere Schleife führt 2 Iterationen aus (für jede Unterliste) und bei jeder Iteration führen wir unsere innere Schleife aus, wodurch alle Elemente der jeweiligen Unterlisten gedruckt werden.
Dies sagt uns, dass die Kontrolle aus der äußersten Schleife bewegt, die innere Schleife durchquert und dann wieder zum Außenbereich zurück for Schleifen Sie fort, bis die Kontrolle den gesamten Bereich abdeckt, der in diesem Fall zweimal beträgt.
Fortsetzung und Brechen for Schleifen
Schleifensteuerungsanweisungen ändern die Ausführung von a for Schleife aus seiner normalen Sequenz.
Was ist, wenn wir eine bestimmte Sprache in unserer inneren Schleife herausfiltern möchten? Wir können a verwenden proceed Aussagen dazu, mit der wir einen bestimmten Teil unserer Schleife überspringen können, wenn ein externer Zustand ausgelöst wird.
for x in languages:
print("------")
for lang in x:
if lang == "German":
proceed
print(lang)
------
Spanish
English
French
------
Python
Java
Javascript
C++
In unserer obigen Schleife in der inneren Schleife überspringen wir diese Iteration nur und fahren mit dem Relaxation der Schleife fort. Beachten Sie, dass die Schleife nicht beendet wird, wenn sie in a eingeht proceed Stellungnahme.
Schauen wir uns ein numerisches Beispiel an, um zu sehen, wie wir verwenden können proceed Um bestimmte Werte in einer Schleife zu überspringen:
from math import sqrt
quantity = 0
for i in vary(10):
quantity = i ** 2
if i % 2 == 0:
proceed
print(str(spherical(sqrt(quantity))) + ' squared is the same as ' + str(quantity))
1 squared is the same as 1
3 squared is the same as 9
5 squared is the same as 25
7 squared is the same as 49
9 squared is the same as 81
Hier haben wir additionally eine Schleife definiert, die über alle Zahlen 0 bis 9 iteriert und jede Zahl quadriert. In unserer Schleife prüfen wir bei jeder Iteration, ob die Zahl durch 2 teilbar ist. An diesem Punkt wird die Schleife weiter ausgeführt, und überspringt die Iteration, wenn i ist eine gleichmäßige Zahl.
Was ist mit a break Stellungnahme? Dies ermöglicht es uns, eine Schleife vollständig zu verlassen, wenn ein externer Zustand erfüllt ist. Lassen Sie uns eine einfache Demonstration sehen, wie dies funktioniert, wie dies oben verwendet wird wie oben:
quantity = 0
for i in vary(10):
quantity = i ** 2
if i == 7:
break
print(str(spherical(sqrt(quantity))) + ' squared is the same as ' + str(quantity))
0 squared is the same as 0
1 squared is the same as 1
2 squared is the same as 4
3 squared is the same as 9
4 squared is the same as 16
5 squared is the same as 25
6 squared is the same as 36
Im obigen Beispiel unsere if Aussage zeigt die Bedingung, dass wenn unsere Variable i Bewertet bis 7, unsere Schleife wird brechen, sodass unsere Schleife über Ganzzahlen 0 bis 6 iteriert, bevor sie vollständig aus der Schleife fallen.
Auf der Suche nach mehr? Hier sind einige zusätzliche Ressourcen, die nützlich sein könnten:
Nächste Schritte
In diesem Tutorial haben wir einige fortgeschrittenere Anwendungen von erfahren für Schleifenund wie sie in typischen Python -Datenwissenschaftsworkflows verwendet werden können.
Wir haben gelernt, wie man verschiedene Arten von Datenstrukturen iteriert und wie Loops mit Pandas-Datenrahmen und Matplotlib verwendet werden können, um programmgesteuert mehrere Spuren oder Unterhandlungen zu erstellen.
Schließlich haben wir uns einige fortgeschrittenere Techniken angesehen, die uns mehr Kontrolle über den Betrieb und die Ausführung unserer für Schleifen geben.
Wenn Sie mehr über dieses Thema erfahren möchten, lesen Sie die DataQuests Datenwissenschaftler in Python Karriereweg, der Ihnen dabei hilft, in wenigen Monaten berufsfertig zu werden.