
Ob Genai nur ein Hype oder externes Rauschen ist. Ich dachte auch, dass dies ein Hype ist, und ich konnte diesen aussetzen, bis der Staub geräumt conflict. Oh, Junge, conflict ich falsch. Genai hat reale Anwendungen. Es generiert auch Einnahmen für Unternehmen. Wir erwarten daher, dass Unternehmen stark in Forschung investieren. Jedes Mal, wenn eine Technologie etwas stört, bewegt sich der Prozess im Allgemeinen durch die folgenden Phasen: Ablehnung, Wut und Akzeptanz. Das gleiche geschah, als Laptop eingeführt wurden. Wenn wir im Bereich Software program oder {Hardware} arbeiten, müssen wir Genai möglicherweise irgendwann verwenden.
In diesem Artikel berichte ich, wie Sie Ihre Anwendung mit großartigen Modellen mit großer Sprachmodellen versorgen können (Llms) und diskutieren Sie die Herausforderungen, mit denen ich beim Einrichten von LLMs konfrontiert conflict. Fangen wir an.
1. Definieren Sie Ihren Anwendungsfall klar klar
Bevor wir auf LLM springen, sollten wir uns einige Fragen stellen
A. Welches Downside wird mein LLM lösen?
B. Kann meine Bewerbung auf LLM ausgehen?
C. Habe ich genügend Ressourcen und berechnet die Macht, um diese Anwendung zu entwickeln und bereitzustellen?
Begrenzen Sie Ihren Anwendungsfall und dokumentieren Sie ihn. In meinem Fall arbeitete ich an einer Datenplattform als Dienst. Wir hatten unzählige Informationen zu Wikis, Slack, Staff -Kanälen usw. Wir wollten, dass ein Chatbot diese Informationen lesen und Fragen in unserem Namen beantwortet. Der Chatbot würde Kundenfragen und Anfragen in unserem Namen beantworten, und wenn die Kunden noch unglücklich wären, würden sie an einen Ingenieur weitergeleitet.
2. Wählen Sie Ihr Modell aus

Sie haben zwei Optionen: trainieren Sie Ihr Modell von Grund auf oder verwenden Sie ein vorgebildetes Modell und bauen Sie darüber auf. Letzteres würde in den meisten Fällen funktionieren, es sei denn, Sie haben einen bestimmten Anwendungsfall. Das Coaching Ihres Modells von Grund auf erfordert unter anderem eine large Rechenleistung, erhebliche technische Bemühungen und Kosten. Jetzt ist die nächste Frage, welches vorgebildete Modell sollte ich wählen? Sie können ein Modell basierend auf Ihrem Anwendungsfall auswählen. 1B -Parametermodell verfügt über grundlegende Kenntnisse und Musteranpassungen. Anwendungsfälle können Restaurantbewertungen sein. Das 10B -Parametermodell verfügt über hervorragende Kenntnisse und kann Anweisungen wie ein Chatbot für Lebensmittelbestellungen befolgen. Ein 100B+ -Parametermodell verfügt über reichhaltige Weltwissen und komplexes Denken. Dies kann als Brainstorming -Companion verwendet werden. Es gibt viele Modelle, wie z. Lama Und Chatgpt. Sobald Sie ein Modell vorhanden haben, können Sie das Modell erweitern.
3. Erweitern Sie das Modell gemäß Ihren Daten
Sobald Sie ein Modell vorhanden haben, können Sie das Modell erweitern. Das LLM -Modell ist nach allgemein verfügbaren Daten geschult. Wir möchten es an unseren Daten trainieren. Unser Modell benötigt mehr Kontext, um Antworten zu geben. Nehmen wir an, wir möchten einen Restaurant -Chatbot bauen, der Kundenfragen beantwortet. Das Modell kennt keine Informationen zu Ihrem Restaurant. Additionally möchten wir dem Modell einige zur Verfügung stellen Kontext. Es gibt viele Möglichkeiten, wie wir dies erreichen können. Tauchen wir in einige von ihnen ein.
Schnelltechnik
Umkämpfte Engineering beinhaltet die Erweiterung der Eingabeaufforderung mit mehr Kontext während der Inferenzzeit. Sie bieten einen Kontext in Ihrem Eingabezitat selbst. Dies ist am einfachsten zu tun und hat keine Verbesserungen. Aber das kommt mit seinen Nachteilen. Sie können keinen großen Kontext innerhalb der Eingabeaufforderung geben. Die Kontextaufforderung ist begrenzt. Sie können auch nicht erwarten, dass der Benutzer immer einen vollständigen Kontext bietet. Der Kontext könnte umfangreich sein. Dies ist eine schnelle und einfache Lösung, aber es hat mehrere Einschränkungen. Hier ist eine Probe -prompt -Engineering.
„Klassifizieren Sie diese Bewertung
Ich liebe den Movie
Gefühle: positivKlassifizieren Sie diese Überprüfung
Ich hasste den Movie.
Gefühl: negativKlassifizieren Sie den Movie
Das Ende conflict aufregend “
Verstärktes Lernen mit menschlichem Suggestions (RLHF)

RLHF ist eine der am häufigsten verwendeten Methoden zur Integration von LLM in eine Anwendung. Sie geben einige kontextbezogene Daten an, aus denen das Modell lernen kann. Hier ist der folgende Fluss: Das Modell ergreifen eine Aktion aus dem Aktionsraum und beobachtet die staatliche Änderung der Umgebung infolge dieser Aktion. Das Belohnungsmodell erzeugte ein Belohnungsranking basierend auf der Ausgabe. Das Modell aktualisiert sein Gewicht entsprechend, um die Belohnung zu maximieren, und lernt iterativ. Zum Beispiel ist in LLM Aktion das nächste Wort, das der LLM generiert, und der Aktionsraum ist das Wörterbuch aller möglichen Wörter und Vokabeln. Die Umgebung ist der Textkontext; Der Zustand ist der aktuelle Textual content im Kontextfenster.
Die obige Erklärung ähnelt eher einer Lehrbucherklärung. Schauen wir uns ein Beispiel für ein echtes Leben an. Sie möchten, dass Ihr Chatbot Fragen zu Ihren Wiki -Dokumenten beantwortet. Jetzt wählen Sie ein vorgebildetes Modell wie Chatgpt. Ihre Wikis werden Ihre Kontextdaten sein. Sie können das nutzen Langchain Bibliothek zur Ausführung von Lappen. Sie können hier ein Beispielcode in Python sind
from langchain.document_loaders import WikipediaLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import FAISS
from langchain.chat_models import ChatOpenAI
from langchain.chains import RetrievalQA
import os
# Set your OpenAI API key
os.environ("OPENAI_API_KEY") = "your-openai-key-here"
# Step 1: Load Wikipedia paperwork
question = "Alan Turing"
wiki_loader = WikipediaLoader(question=question, load_max_docs=3)
wiki_docs = wiki_loader.load()
# Step 2: Cut up the textual content into manageable chunks
splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=100)
split_docs = splitter.split_documents(wiki_docs)
# Step 3: Embed the chunks into vectors
embeddings = OpenAIEmbeddings()
vector_store = FAISS.from_documents(split_docs, embeddings)
# Step 4: Create a retriever
retriever = vector_store.as_retriever(search_type="similarity", search_kwargs={"okay": 3})
# Step 5: Create a RetrievalQA chain
llm = ChatOpenAI(temperature=0, model_name="gpt-3.5-turbo")
qa_chain = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff", # It's also possible to attempt "map_reduce" or "refine"
retriever=retriever,
return_source_documents=True,
)
# Step 6: Ask a query
query = "What did Alan Turing contribute to pc science?"
response = qa_chain(query)
# Print the reply
print("Reply:", response("outcome"))
print("n--- Sources ---")
for doc in response("source_documents"):
print(doc.metadata)4. Bewerten Sie Ihr Modell
Jetzt haben Sie Ihrem Modell Lappen hinzugefügt. Wie überprüfen Sie, ob sich Ihr Modell richtig verhält? Dies ist kein Code, in dem Sie einige Eingabeparameter angeben und eine feste Ausgabe erhalten, gegen die Sie testen können. Da dies eine sprachbasierte Kommunikation ist, kann es geben Mehrfach richtig Antworten. Was Sie jedoch sicher wissen können, ist, ob die Antwort falsch ist. Es gibt viele Metriken, gegen die Sie Ihr Modell testen können.
Manuell bewerten
Sie können Ihr Modell kontinuierlich manuell bewerten. Zum Beispiel hatten wir einen Slack -Chatbot integriert, der mit Lappen mit unseren Wikis und Jira verbessert wurde. Sobald wir den Chatbot zum Slack -Kanal hinzugefügt haben, haben wir seine Antworten zunächst beschattet. Die Kunden konnten die Antworten nicht anzeigen. Nachdem wir das Vertrauen gewonnen hatten, machten wir den Chatbot den Kunden öffentlich sichtbar. Wir haben seine Reaktion manuell bewertet. Aber dies ist ein schneller und vage Ansatz. Sie können durch solche manuellen Checks nicht Vertrauen gewinnen. Die Lösung besteht additionally darin, gegen einige Benchmark wie Rouge zu testen.
Bewerten Sie mit Rouge -Rating.
Rouge -Metriken werden für die Textübersicht verwendet. Rouge -Metriken vergleichen die generierte Zusammenfassung mit Referenzzusammenfassungen unter Verwendung verschiedener Rouge -Metriken. Rouge -Metriken bewerten das Modell mithilfe von Rückruf-, Präzisions- und F1 -Scores. Rouge -Metriken sind in verschiedenen Typen vorhanden, und eine schlechte Fertigstellung kann immer noch zu einer guten Punktzahl führen. Daher verweisen wir auf verschiedene Rouge -Metriken. Für einen Kontext ist ein Unigramm ein einzelnes Wort; Ein Bigram ist zwei Wörter; Und ein N-Gramm ist N Wörter.
Rouge-1-Rückruf = Unigram-Übereinstimmungen/Unigramm in Bezug
Rouge-1 Precision = Unigram Matches/Unigram in der generierten Ausgabe
Rouge-1 F1 = 2 * (Rückruf * Präzision / (Rückruf + Präzision))
Rouge-2 Recall = Bigram Matches/Bigram Referenz
Rouge-2 Precision = Bigram Matches / Bigram in der generierten Ausgabe
Rouge-2 F1 = 2 * (Rückruf * Präzision / (Rückruf + Präzision))
Rouge-L-Rückruf = längste gemeinsame Untersequenz/Unigramm in Bezug
Rouge-L präzision = längste gemeinsame Subsequenz/Unigramm in der Ausgabe
Rouge-L f1 = 2 * (Rückruf * Präzision / (Rückruf + Präzision))
Zum Beispiel,
Referenz: „Es ist draußen kalt.“
Erzeugte Ausgabe: „Es ist draußen sehr kalt.“
Rouge-1-Rückruf = 4/4 = 1,0
Rouge-1-Präzision = 4/5 = 0,8
Rouge-1 F1 = 2 * 0,8/1,8 = 0,89
Rouge-2-Rückruf = 2/3 = 0,67
Rouge-2 Präzision = 2/4 = 0,5
Rouge-2 F1 = 2 * 0,335/1,17 = 0,57
Rouge-L-Rückruf = 2/4 = 0,5
Rouge-L Precision = 2/5 = 0,4
Rouge-L f1 = 2 * 0,335/1,17 = 0,44
Reduzieren Sie den Ärger mit dem externen Benchmark
Der Rouge -Rating wird verwendet, um zu verstehen, wie die Modellbewertung funktioniert. Es gibt andere Benchmarks, wie die Bleu -Punktzahl. Wir können den Datensatz jedoch nicht praktisch erstellen, um unser Modell zu bewerten. Wir können externe Bibliotheken nutzen, um unsere Modelle zu bewerten. Die am häufigsten verwendeten sind die Klebemaßstab Und SUVERGLE -Benchmark.
5. Optimieren und bereitstellen Sie Ihr Modell
Dieser Schritt ist möglicherweise nicht von entscheidender Bedeutung, aber die Reduzierung der Rechenkosten und das Erreichen schnellerer Ergebnisse ist immer intestine. Sobald Ihr Modell fertig ist, können Sie es optimieren, um die Leistung zu verbessern und Speicheranforderungen zu reduzieren. Wir werden einige Konzepte ansprechen, die mehr technische Anstrengungen, Kenntnisse, Zeit und Kosten erfordern. Diese Konzepte helfen Ihnen dabei, einige Techniken kennenzulernen.
Quantisierung der Gewichte
Modelle haben Parameter, interne Variablen innerhalb eines Modells, die während des Trainings aus Daten gelernt werden und deren Werte bestimmen, wie das Modell Vorhersagen macht. 1 Parameter erfordert normalerweise 24 Bytes des Prozessorspeichers. Wenn Sie additionally 1B wählen, benötigen die Parameter 24 GB Prozessorspeicher. Die Quantisierung wandelt die Modellgewichte von den Gleitkomma-Zahlen mit höherer Präzision zu Gleitkomma-Zahlen mit niedrigerer Präzision für eine effiziente Speicherung um. Das Ändern der Speicherpräzision kann die Anzahl der Bytes erheblich beeinflussen, die erforderlich sind, um einen einzelnen Wert des Gewichts zu speichern. Die folgende Tabelle zeigt verschiedene Präzisionen für das Speichern von Gewichten.
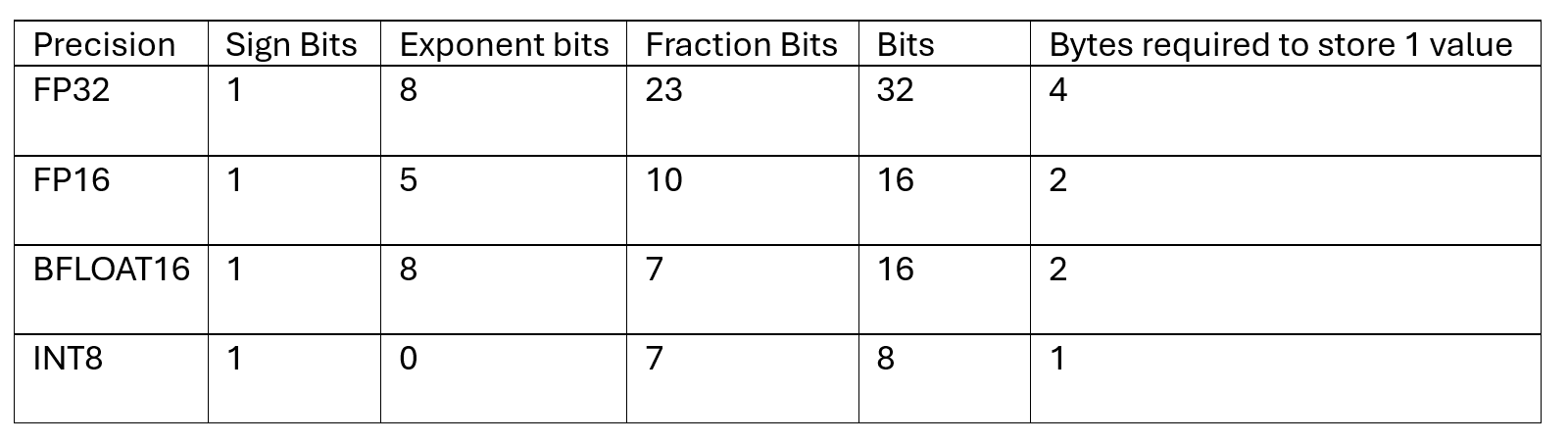
Beschneidung
Das Beschneiden beinhaltet das Entfernen von Gewichten in einem Modell, das weniger wichtig ist und nur geringe Auswirkungen hat, z. B. Gewichte, die gleich oder nahe Null sind. Einige Techniken des Beschneidens sind
A. Vollständige Modellumschulung
B. Peft wie Lora
C. Nach der Ausbildung.
Abschluss
Abschließend können Sie ein vorgebildetes Modell wie Chatgpt oder Flan-T5 auswählen und darüber hinaus aufbauen. Erstellen Sie Ihr vorgebildetes Modell, erfordert Fachwissen, Ressourcen, Zeit und Finances. Sie können es bei Bedarf gemäß Ihrem Anwendungsfall optimieren. Anschließend können Sie Ihre LLM verwenden, um Anwendungen durchzuführen und sie mit Techniken wie Rag auf Ihr Anwendungsgebrauch zu verapfen. Sie können Ihr Modell anhand einiger Benchmarks bewerten, um festzustellen, ob es sich korrekt verhält. Sie können dann Ihr Modell bereitstellen.