Eine Schritt-für-Schritt-Anleitung zum Erstellen eines mehrsprachigen thailändischen Unterwort-Tokenizers basierend auf einem BPE-Algorithmus, der nur mit Python anhand thailändischer und englischer Datensätze trainiert wurde.

Die Hauptaufgabe des Tokenisierer besteht darin, die Roheingabetexte (in unserem Fall Thai, aber es können auch beliebige Fremdsprachen sein) in Zahlen zu übersetzen und sie an die Transformatoren des Modells weiterzuleiten. Der Transformator des Modells generiert dann die Ausgabe als Zahlen. Auch hier gilt: Tokenisierer übersetzt diese Zahlen zurück in Texte, die für Endbenutzer verständlich sind. Das folgende Übersichtsdiagramm beschreibt den oben erläuterten Ablauf.

Im Allgemeinen sind viele von uns nur daran interessiert, zu erfahren, wie die Transformer-Architektur des Modells im Hintergrund funktioniert. Wir übersehen oft, einige wichtige Komponenten wie Tokenizer im Element zu lernen. Wenn wir verstehen, wie Tokenizer im Hintergrund funktionieren, und seine Funktionen intestine kontrollieren können, haben wir gute Möglichkeiten, die Genauigkeit und Leistung unseres Modells zu verbessern.
Ähnlich wie beim Tokenizer sind einige der wichtigsten Komponenten der LLM-Implementierungspipelines Datenvorverarbeitung, Auswertung, Leitplanken/Sicherheit und Testen/Überwachen. Ich würde Ihnen dringend empfehlen, sich näher mit diesen Themen zu befassen. Die Bedeutung dieser Komponenten wurde mir erst bewusst, als ich an der tatsächlichen Implementierung meines grundlegenden mehrsprachigen Modells ThaiLLM in der Produktion arbeitete.
Warum benötigen Sie einen thailändischen oder einen anderen fremdsprachigen Tokenizer?
- Angenommen, Sie verwenden generische, auf Englisch basierende Tokenisierer, um ein mehrsprachiges, großes Sprachmodell wie Thailändisch, Hindi, Indonesisch, Arabisch, Chinesisch usw. vorab zu trainieren. In diesem Fall liefert Ihr Modell wahrscheinlich keine geeignete Ausgabe, die für Ihre spezifische Domäne oder Anwendungsfälle sinnvoll ist. Daher trägt das Erstellen Ihres eigenen Tokenisierers in der Sprache Ihrer Wahl sicherlich dazu bei, die Ausgabe Ihres Modells viel kohärenter und verständlicher zu machen.
- Wenn Sie Ihren eigenen Tokenizer erstellen, haben Sie außerdem die volle Kontrolle darüber, wie umfassend und inklusives Vokabular Sie aufbauen möchten. Während des Aufmerksamkeitsmechanismus kann das Token aufgrund des umfassenden Vokabulars innerhalb der begrenzten Kontextlänge der Sequenz mehr Token berücksichtigen und von ihnen lernen. Dadurch wird das Lernen kohärenter, was letztendlich zu einer besseren Modellinferenz beiträgt.
Die gute Nachricht ist, dass Sie nach der Erstellung des Thai Tokenizers problemlos einen Tokenizer in jeder anderen Sprache erstellen können. Alle Erstellungsschritte sind gleich, außer dass Sie mit dem Datensatz der von Ihnen gewählten Sprache trainieren müssen.
Jetzt haben wir alle guten Gründe, unseren eigenen Tokenizer zu erstellen. Nachfolgend finden Sie die Schritte zum Erstellen unseres Tokenizers in thailändischer Sprache.
- Erstellen Sie unseren eigenen BPE-Algorithmus
- Trainieren des Tokenizers
- Tokenizer-Kodier- und Dekodierungsfunktion
- Laden und Testen des Tokenizers
Schritt 1: Erstellen Sie unseren eigenen BPE-Algorithmus (Byte Pair Encoding):
Der BPE-Algorithmus wird in vielen beliebten LLMs wie Llama, GPT und anderen zum Erstellen ihres Tokenizers verwendet. Wir können einen dieser LLM-Tokenizer auswählen, wenn unser Modell auf der englischen Sprache basiert. Da wir den thailändischen Tokenizer erstellen, ist es am besten, unseren eigenen BPE-Algorithmus von Grund auf neu zu erstellen und ihn zum Erstellen unseres Tokenizers zu verwenden. Lassen Sie uns zunächst mithilfe des einfachen Flussdiagramms unten verstehen, wie der BPE-Algorithmus funktioniert, und beginnen Sie dann, ihn entsprechend zu erstellen.

Zur besseren Verständlichkeit werden die Beispiele im Flussdiagramm auf Englisch dargestellt.
Schreiben wir Code, um den BPE-Algorithmus für unseren Thai-Tokenizer zu implementieren.
# A easy follow instance to get familiarization with utf-8 encoding to transform strings to bytes.
textual content = "How are you คุณเป็นอย่างไร" # Textual content string in each English and Thai
text_bytes = textual content.encode("utf-8")
print(f"Textual content in byte: {text_bytes}")text_list = record(text_bytes) # Converts textual content bytes to a listing of integer
print(f"Textual content record in integer: {text_list}")
# As I do not need to reinvent the wheel, I can be referencing many of the code block from Andrej Karpathy's GitHub (https://github.com/karpathy/minbpe?tab=readme-ov-file).
# Nonetheless, I will be modifying code blocks particular to constructing our Thai language tokenizer and in addition explaining the codes so as to perceive how every code block works and make it straightforward while you implement code to your use case later.# This module supplies entry to the Unicode Character Database (UCD) which defines character properties for all Unicode characters.
import unicodedata
# This perform returns a dictionary with consecutive pairs of integers and their counts within the given record of integers.
def get_stats(ids, stats=None):
stats = {} if stats is None else stats
# zip perform permits to iterate consecutive gadgets from given two record
for pair in zip(ids, ids(1:)):
# If a pair already exists within the stats dictionary, add 1 to its worth else assign the worth as 0.
stats(pair) = stats.get(pair, 0) + 1
return stats
# As soon as we discover out the record of consecutive pairs of integers, we'll then exchange these pairs with new integer tokens.
def merge(ids, pair, idx):
newids = ()
i = 0
# As we'll be merging a pair of ids, therefore the minimal id within the record ought to be 2 or extra.
whereas i < len(ids):
# If the present id and subsequent id(id+1) exist within the given pair, and the place of id will not be the final, then exchange the two consecutive id with the given index worth.
if ids(i) == pair(0) and that i < len(ids) - 1 and ids(i+1) == pair(1):
newids.append(idx)
i += 2 # If the pair is matched, the subsequent iteration begins after 2 positions within the record.
else:
newids.append(ids(i))
i += 1 # For the reason that present id pair did not match, so begin iteration from the 1 place subsequent within the record.
# Returns the Merged Ids record
return newids
# This perform checks that utilizing 'unicodedata.class' which returns "C" as the primary letter if it's a management character and we'll have to interchange it readable character.
def replace_control_characters(s: str) -> str:
chars = ()
for ch in s:
# If the character will not be distorted (which means the primary letter does not begin with "C"), then append the character to chars record.
if unicodedata.class(ch)(0) != "C":
chars.append(ch)
# If the character is distorted (which means the primary letter has the letter "C"), then exchange it with readable bytes and append to chars record.
else:
chars.append(f"u{ord(ch):04x}")
return "".be part of(chars)
# A number of the tokens similar to management characters like Escape Characters cannot be decoded into legitimate strings.
# Therefore these have to be exchange with readable character similar to �
def render_token(t: bytes) -> str:
s = t.decode('utf-8', errors='exchange')
s = replace_control_characters(s)
return s
Die beiden Funktionen Statistiken abrufen Und verschmelzen Oben im Codeblock definiert ist die Implementierung des BPE-Algorithmus für unseren Thai-Tokenizer. Jetzt, da der Algorithmus fertig ist, schreiben wir Code, um unseren Tokenizer zu trainieren.
Schritt 2: Trainieren Sie den Tokenizer:
Das Coaching des Tokenizers beinhaltet die Generierung eines Vokabulars, das eine Datenbank mit eindeutigen Token (Wörter und Teilwörter) sowie eine eindeutige Indexnummer ist, die jedem Token zugewiesen wird. Wir verwenden der Thai-Wiki-Datensatz von Hugging Face, um unseren Thai-Tokenizer zu trainieren. So wie das Trainieren eines LLM eine große Datenmenge erfordert, benötigen Sie auch eine große Datenmenge, um einen Tokenizer zu trainieren. Sie können auch denselben Datensatz verwenden, um das LLM und den Tokenizer zu trainieren, obwohl dies nicht zwingend erforderlich ist. Für ein mehrsprachiges LLM ist es ratsam, sowohl den englischen als auch den thailändischen Datensatz im Verhältnis 2:1 zu verwenden, was ein Standardansatz ist, dem viele Praktiker folgen.
Beginnen wir mit dem Schreiben des Trainingscodes.
# Import Common Expression
import regex as re # Create a Thai Tokenizer class.
class ThaiTokenizer():
def __init__(self):
# The byte pair ought to be finished throughout the associated phrases or sentences that give a correct context. Pairing between unrelated phrases or sentences could give undesirable output.
# To stop this habits, we'll implement the LLama 3 common expression sample to make significant chunks of our textual content earlier than implementing the byte pair algorithm.
self.sample = r"(?i:'s|'t|'re|'ve|'m|'ll|'d)|(^rnp{L}p{N})?p{L}+|p{N}{1,3}| ?(^sp{L}p{N})+(rn)*|s*(rn)+|s+(?!S)|s+"
self.compiled_pattern = re.compile(self.sample)
# Particular tokens are used to offer coherence within the sequence whereas coaching.
# Particular tokens are assigned a singular index quantity and saved in vocabulary.
self.special_tokens = end_of_text
# Initialize merges with empty dictionary
self.merges = {}
# Initialize the vocab dictionary by calling the perform _build_vocab which is outlined later on this class.
self.vocab = self._build_vocab()
# Tokenizer coaching perform
def prepare(self, textual content, vocab_size):
# Make sure that the vocab dimension have to be a minimum of 256 because the utf-8 encoding for the vary 0-255 are similar because the Ascii character.
assert vocab_size >= 256
# Complete variety of merges into the vocabulary.
num_merges = vocab_size - 256
# Step one is to ensure to separate the textual content up into textual content chunks utilizing the sample outlined above.
text_chunks = re.findall(self.compiled_pattern, textual content)
# Every text_chunks can be utf-8 encoded to bytes after which transformed into an integer record.
ids = (record(ch.encode("utf-8")) for ch in text_chunks)
# Iteratively merge the most typical pairs to create new tokens
merges = {} # (int, int) -> int
vocab = {idx: bytes((idx)) for idx in vary(256)} # idx -> bytes
# Till the full num_merges is reached, discover the widespread pair of consecutive id within the ids record and begin merging them to create a brand new token
for i in vary(num_merges):
# Rely the variety of occasions each consecutive pair seems
stats = {}
for chunk_ids in ids:
# Passing in stats will replace it in place, including up counts
get_stats(chunk_ids, stats)
# Discover the pair with the best rely
pair = max(stats, key=stats.get)
# Mint a brand new token: assign it the subsequent out there id
idx = 256 + i
# Exchange all occurrences of pair in ids with idx
ids = (merge(chunk_ids, pair, idx) for chunk_ids in ids)
# Save the merge
merges(pair) = idx
vocab(idx) = vocab(pair(0)) + vocab(pair(1))
# Save class variables for use later throughout tokenizer encode and decode
self.merges = merges
self.vocab = vocab
# Perform to return a vocab dictionary combines with merges and particular tokens
def _build_vocab(self):
# The utf-8 encoding for the vary 0-255 are similar because the Ascii character.
vocab = {idx: bytes((idx)) for idx in vary(256)}
# Iterate by way of merge dictionary and add into vocab dictionary
for (p0, p1), idx in self.merges.gadgets():
vocab(idx) = vocab(p0) + vocab(p1)
# Iterate by way of particular token dictionary and add into vocab dictionary
for particular, idx in self.special_tokens.gadgets():
vocab(idx) = particular.encode("utf-8")
return vocab
# After coaching is full, use the save perform to save lots of the mannequin file and vocab file.
# Mannequin file can be used to load the tokenizer mannequin for additional use in llm
# Vocab file is only for the aim of human verification
def save(self, file_prefix):
# Writing to mannequin file
model_file = file_prefix + ".mannequin" # mannequin file title
# Mannequin write begins
with open(model_file, 'w') as f:
f.write("thai tokenizer v1.0n") # write the tokenizer model
f.write(f"{self.sample}n") # write the sample utilized in tokenizer
f.write(f"{len(self.special_tokens)}n") # write the size of particular tokens
# Write every particular token within the particular format like under
for tokens, idx in self.special_tokens.gadgets():
f.write(f"{tokens} {idx}n")
# Write solely the keys half from the merges dict
for idx1, idx2 in self.merges:
f.write(f"{idx1} {idx2}n")
# Writing to the vocab file
vocab_file = file_prefix + ".vocab" # vocab file title
# Change the place of keys and values of merge dict and retailer into inverted_merges
inverted_merges = {idx: pair for pair, idx in self.merges.gadgets()}
# Vocab write begins
with open(vocab_file, "w", encoding="utf-8") as f:
for idx, token in self.vocab.gadgets():
# render_token perform processes tokens and prevents distorted bytes by changing them with readable character
s = render_token(token)
# If the index of vocab is current in merge dict, then discover its baby index, convert their corresponding bytes in vocab dict and write the characters
if idx in inverted_merges:
idx0, idx1 = inverted_merges(idx)
s0 = render_token(self.vocab(idx0))
s1 = render_token(self.vocab(idx1))
f.write(f"({s0})({s1}) -> ({s}) {idx}n")
# If index of vocab will not be current in merge dict, simply write it is index and the corresponding string
else:
f.write(f"({s}) {idx}n")
# Perform to load tokenizer mannequin.
# This perform is invoked solely after the coaching is full and the tokenizer mannequin file is saved.
def load(self, model_file):
merges = {} # Initialize merge and special_tokens with empty dict
special_tokens = {} # Initialize special_tokens with empty dict
idx = 256 # Because the vary (0, 255) is already reserved in vocab. So the subsequent index solely begins from 256 and onwards.
# Learn mannequin file
with open(model_file, 'r', encoding="utf-8") as f:
model = f.readline().strip() # Learn the tokenizer model as outlined throughout mannequin file writing
self.sample = f.readline().strip() # Learn the sample utilized in tokenizer
num_special = int(f.readline().strip()) # Learn the size of particular tokens
# Learn all of the particular tokens and retailer in special_tokens dict outlined earlier
for _ in vary(num_special):
particular, special_idx = f.readline().strip().break up()
special_tokens(particular) = int(special_idx)
# Learn all of the merge indexes from the file. Make it a key pair and retailer it in merge dictionary outlined earlier.
# The worth of this key pair can be idx(256) as outlined above and carry on enhance by 1.
for line in f:
idx1, idx2 = map(int, line.break up())
merges((idx1, idx2)) = idx
idx += 1
self.merges = merges
self.special_tokens = special_tokens
# Create a closing vocabulary dictionary by combining merge, special_token and vocab (0-255). _build_vocab perform helps to just do that.
self.vocab = self._build_vocab()
Schritt 3: Tokenizer-Kodier- und Dekodierungsfunktion:
- Tokenizer-Kodierung: Die Tokenizer-Kodierungsfunktion durchsucht das Vokabular und übersetzt die angegebenen Eingabetexte oder Eingabeaufforderungen in die Liste der ganzzahligen IDs. Diese IDs werden dann in die Transformerblöcke eingespeist.
- Tokenizer-Dekodierung: Die Tokenizer-Dekodierfunktion untersucht das Vokabular und übersetzt die Liste der aus dem Klassifikatorblock des Transformators generierten IDs in Ausgabetexte.
Werfen wir zur weiteren Verdeutlichung einen Blick auf das folgende Diagramm.

Schreiben wir Code, um die Codier- und Decodierungsfunktion des Tokenizers zu implementieren.
# Tokenizer encode perform takes textual content as a string and returns integer ids record
def encode(self, textual content): # Outline a sample to determine particular token current within the textual content
special_pattern = "(" + "|".be part of(re.escape(ok) for ok in self.special_tokens) + ")"
# Cut up particular token (if current) from the remainder of the textual content
special_chunks = re.break up(special_pattern, textual content)
# Initialize empty ids record
ids = ()
# Loop by way of every of components within the particular chunks record.
for half in special_chunks:
# If the a part of the textual content is the particular token, get the idx of the half from the particular token dictionary and append it to the ids record.
if half in self.special_tokens:
ids.append(self.special_tokens(half))
# If the a part of textual content will not be a particular token
else:
# Cut up the textual content into a number of chunks utilizing the sample we have outlined earlier.
text_chunks = re.findall(self.compiled_pattern, textual content)
# All textual content chunks are encoded individually, then the outcomes are joined
for chunk in text_chunks:
chunk_bytes = chunk.encode("utf-8") # Encode textual content to bytes
chunk_ids = record(chunk_bytes) # Convert bytes to record of integer
whereas len(chunk_ids) >= 2: # chunks ids record have to be a minimum of 2 id to kind a byte-pair
# Rely the variety of occasions each consecutive pair seems
stats = get_stats(chunk_ids)
# Some idx pair is perhaps created with one other idx within the merge dictionary. Therefore we'll discover the pair with the bottom merge index to make sure we cowl all byte pairs within the merge dict.
pair = min(stats, key=lambda p: self.merges.get(p, float("inf")))
# Break the loop and return if the pair will not be current within the merges dictionary
if pair not in self.merges:
break
# Discover the idx of the pair current within the merges dictionary
idx = self.merges(pair)
# Exchange the occurrences of pair in ids record with this idx and proceed
chunk_ids = merge(chunk_ids, pair, idx)
ids.lengthen(chunk_ids)
return ids
# Tokenizer decode perform takes a listing of integer ids and return strings
def decode(self, ids):
# Initialize empty byte record
part_bytes = ()
# Change the place of keys and values of special_tokens dict and retailer into inverse_special_tokens
inverse_special_tokens = {v: ok for ok, v in self.special_tokens.gadgets()}
# Loop by way of idx within the ids record
for idx in ids:
# If the idx is present in vocab dict, get the bytes of idx and append them into part_bytes record
if idx in self.vocab:
part_bytes.append(self.vocab(idx))
# If the idx is present in inverse_special_tokens dict, get the token string of the corresponding idx, convert it to bytes utilizing utf-8 encode after which append it into part_bytes record
elif idx in inverse_special_tokens:
part_bytes.append(inverse_special_tokens(idx).encode("utf-8"))
# If the idx will not be present in each vocab and particular token dict, throw an invalid error
else:
increase ValueError(f"invalid token id: {idx}")
# Be part of all the person bytes from the part_byte record
text_bytes = b"".be part of(part_bytes)
# Convert the bytes to textual content string utilizing utf-8 decode perform. Make sure that to make use of "errors=exchange" to interchange distorted characters with readable characters similar to �.
textual content = text_bytes.decode("utf-8", errors="exchange")
return textual content
Schritt 4: Laden und testen Sie den Tokenizer:
Zum Schluss kommt hier der beste Teil dieses Artikels. In diesem Abschnitt führen wir zwei interessante Aufgaben aus.
- Trainieren Sie zunächst unseren Tokenizer mit dem Thai-Wiki-Datensatz von Hugging Face. Wir haben eine kleine Datensatzgröße (2,2 MB) gewählt, um das Coaching zu beschleunigen. Für die Implementierung in der Praxis sollten Sie jedoch einen viel größeren Datensatz wählen, um bessere Ergebnisse zu erzielen. Nachdem das Coaching abgeschlossen ist, speichern wir das Modell.
- Zweitens laden wir das gespeicherte Tokenizer-Modell und testen die Codier- und Decodierungsfunktion des Tokenizers.
Lassen Sie uns eintauchen.
# Practice the tokenizerimport time # To caculate the period of coaching completion
# Load coaching uncooked textual content information (thai_wiki dataset) from huggingface. thai_wiki_small.textual content: https://github.com/tamangmilan/thai_tokenizer
texts = open("/content material/thai_wiki_small.txt", "r", encoding="utf-8").learn()
texts = texts.strip()
# Outline vocab dimension
vocab_size = 512
# Initialize a tokenizer mannequin class
tokenizer = ThaiTokenizer()
# Begin prepare a tokenizer
start_time = time.time()
tokenizer.prepare(texts, vocab_size)
end_time = time.time()
# Save tokenizer: you may change path and filename.
tokenizer.save("./fashions/thaitokenizer")
print(f"Complete time to finish tokenizer coaching: {end_time-start_time:.2f} seconds")
# Output: Complete time to finish tokenizer coaching: 186.11 seconds (3m 6s) (Word: Coaching period can be longer if vocab_size is larger and lesser for smaller vocab_size)
# Check the tokenizer# Initialize a tokenizer mannequin class
tokenizer = ThaiTokenizer()
# Load tokenizer mannequin. This mannequin was saved throughout coaching.
tokenizer.load("./fashions/thaitokenizer.mannequin")
# Invoke and confirm the tokenizer encode and decode perform for English Language
eng_texts = "When society developed in several lands"
print(f"English Textual content: {eng_texts}")
encoded_ids = tokenizer.encode(eng_texts)
print(f"Encoded Ids: {encoded_ids}")
decoded_texts = tokenizer.decode(encoded_ids)
print(f"Decoded Texts: {decoded_texts}n")
# Invoke and confirm the tokenizer encode and decode perform for Thai Language
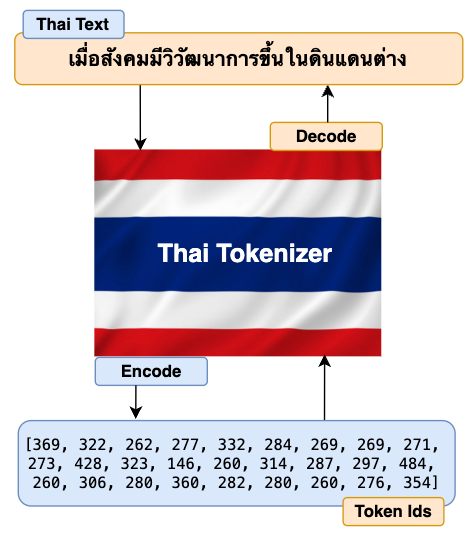
thai_texts = "เมื่อสังคมมีวิวัฒนาการขึ้นในดินแดนต่าง"
print(f"Thai Textual content: {thai_texts}")
thai_encoded_ids = tokenizer.encode(thai_texts)
print(f"Encoded Ids: {thai_encoded_ids}")
thai_decoded_texts = tokenizer.decode(thai_encoded_ids)
print(f"Decoded Texts: {thai_decoded_texts}")

Perfekt. Unser Thai-Tokenizer kann jetzt Texte in thailändischer und englischer Sprache erfolgreich und genau kodieren und dekodieren.
Ist Ihnen aufgefallen, dass die codierten IDs für englische Texte länger sind als die codierten IDs für Thai? Das liegt daran, dass wir unseren Tokenizer nur mit dem thailändischen Datensatz trainiert haben. Daher kann der Tokenizer nur ein umfassendes Vokabular für die thailändische Sprache aufbauen. Da wir nicht mit einem englischen Datensatz trainiert haben, muss der Tokenizer direkt auf Zeichenebene codieren, was zu längeren codierten IDs führt. Wie ich bereits erwähnt habe, sollten Sie für mehrsprachiges LLM sowohl den englischen als auch den thailändischen Datensatz im Verhältnis 2:1 trainieren. Dadurch erhalten Sie ausgewogene und qualitativ hochwertige Ergebnisse.
Und das ist es! Wir haben jetzt erfolgreich unseren eigenen Thai-Tokenizer von Grund auf nur mit Python erstellt. Und ich finde, das struggle ziemlich cool. Damit können Sie ganz einfach einen Tokenizer für jede Fremdsprache erstellen. Dies verschafft Ihnen bei der Implementierung Ihres mehrsprachigen LLM einen großen Vorteil.
Vielen Dank fürs Lesen!
Hyperlink zum Google Colab-Notizbuch
Verweise
(1) Andrej Karpathy, Git Hub: Karpthy/minbpe