Dieser Artikel wurde mitverfasst von Rahul Vir Und Reya Vir.
zur Token-Effizienz
Wir haben die KI-Prototyping-Part offiziell hinter uns gelassen. Aufbauend auf den Konzepten in Escaping the Prototype Mirage (1) liefern Produkt- und Entwicklungsteams in allen Branchen jetzt Agentenanwendungen aus, die Arbeitsabläufe lösen, die zuvor von manueller Arbeit dominiert wurden. Der Aufbau dieser autonomen Agenten-Prototypen ist jetzt ein Kinderspiel. Es ist so einfach wie die Verwendung von Schlüsselkonzepten wie rekursiven Agentenschleifen (Beobachten-Denken-Handeln) für die Ausführung, das Einrichten von Headless-Gateways, um Agenten über Chat-Apps zu verbinden, und das Verlassen auf gespeicherte Zustände, die über Neustarts hinweg bestehen bleiben (wie erläutert in (1)). Aber sie zu zuverlässigen Produkten weiterzuentwickeln, ist eine andere Geschichte. Die neue Grenze beweist nicht, dass Agenten arbeiten können, sie beweist vielmehr, dass sie profitabel arbeiten können.
Gleichzeitig verlagern sich interne Kennzahlen in Unternehmen wie „Token Maxing“ (uneingeschränkte Token-Nutzung zur Erzielung bester Ergebnisse), die für die Prototyping-Part geeignet waren, hin zur Messung des Verhältnisses „Wert zu ausgegebenem Token“ im Zuge der Skalierung von Agentenprodukten. Schließlich müssen die meisten Produkte profitabel sein und die Marge maximieren, da sie sich von der Nutzung kostengünstiger traditioneller Rechenleistung (TradCompute) zur Lösung von Benutzerproblemen hin zur Nutzung von KI-Intelligenz bewegen.
Aber Modelle brauchen Denkfreiheit, und aktuelle Studien haben gezeigt, dass explorative Agenten-Workflows feste Pfade übertreffen, neue Pfade eröffnen, MCP-Instruments erstellen und eine Infrastruktur aufbauen, um das Drawback in den meisten Fällen effizienter zu lösen. Dies wirft die Frage auf, den Handlungsbedarf des Modells mit der wirtschaftlichen Realität der Inferenzkosten in Einklang zu bringen.
Warum eingeschränkte Agenten nicht konvergieren
Agenten-Harnesses speichern Ihren Aufgabenkontext und Ihre Ziele in Markdown-Dateien (*.md), die normalerweise keine engen Arbeitsabläufe darstellen, sondern vielmehr die Absicht oder das Ziel umreißen, das Sie erreichen möchten.
Das Paradox des objektiven Scheiterns: In Studien zu Agenten, die komplexe Probleme lösen, stellten Forscher fest, dass die Bereitstellung strenger, stark eingeschränkter Richtlinien, bei denen jede Aktion des Agenten ihn dem Ziel näher bringt, dazu führt, dass er in lokalen Optima stecken bleibt und einen objektiven Misserfolg erleidet. Ein Beispiel aus der Forschung von Professor Jeff Clune zum ergebnisoffenen Agentenlernen veranschaulicht dies perfekt: Ein Agent in einem Labyrinth wird, wenn er ständig allein dafür belohnt wird, den direkten Weg zum Ausgang zu suchen, wiederholt gegen Wände stoßen und in einem lokalen Optimum gefangen bleiben, ohne das Ende zu erreichen (2).
Die Kraft uneingeschränkter Gurte: Zeitgenössische Agentensysteme wie Google Antigravity und Claude Code von Anthropic sind so effektiv, weil sie es Agenten ermöglichen, komplexe Aufgaben zu erstellen, zu orchestrieren, auszuführen und sogar ihre eigenen Instruments zu erstellen, ohne dass ein striktes menschliches Mikromanagement erforderlich ist. Sie haben Erfolg, weil ihnen die Freiheit gegeben wird, Umwege zu gehen.
Stellen Sie sich einen Randfall in einem routinemäßigen Arbeitsablauf bei der medizinischen Aufnahme vor: Wenn wir einen Mitarbeiter im Gesundheitswesen strikt dazu zwingen, nur einem vordefinierten Planungsablauf zu folgen, bricht dies in der realen Welt zusammen. Wenn ein Affected person mitten in der Routineeinnahme Brustschmerzen erwähnt, muss der Agentic Loop des Agenten über die Autonomie verfügen, die Dringlichkeit sofort zu erkennen, den Planungsablauf abzubrechen und eine Sicherheitseskalation auszulösen. Es sollte das verwenden, was wir zuvor als „No-Reply-Token“ definiert haben, um Buchungsgespräche zu unterdrücken und den Kontext direkt an eine menschliche Krankenschwester weiterzuleiten (1). Starr eingeschränkte Prototypen scheitern bei diesem Take a look at spektakulär, weil sie sich nicht an kritische, außerhalb der Grenzen liegende Kontexte anpassen können.
Die Suche nach unendlichen Zielen ist teuer
Während die Bereitstellung einer Agentur von entscheidender Bedeutung ist, um zunächst eine Lösung zu finden, kann die Durchführung einer vollständigen, offenen Suche für jede Benutzer-Workflow-Anfrage zu einem massiven und nicht nachhaltigen Token-Verbrauch führen. In diesem Stadium hat der Agent einen gültigen Weg gefunden und dieser Ansatz ermöglicht es ihm von Natur aus, die Workflow-Struktur erneut zu erkunden oder zu „halluzinieren“. Dies kann zwar selbstkorrigierend sein, aber solche nachfolgenden Durchläufe einer ähnlichen Anfrage zerstören die Wirtschaftlichkeit von Unternehmenstoken.
Beispielsweise kann die Weiterleitung der Arbeitsabläufe bei der medizinischen Aufnahme und sogar der Randfälle, die eine Eskalation erfordern, über einen bestimmten Zeitraum hinweg erlernt werden. Die Arbeitsabläufe einer Klinik oder eines Lösungsanbieters werden größtenteils auf deterministische Pfade umgestellt, sodass ein gewisser Grad an Autonomie ausschließlich seltenen Ausreißern und komplexen Grenzfällen vorbehalten bleibt.
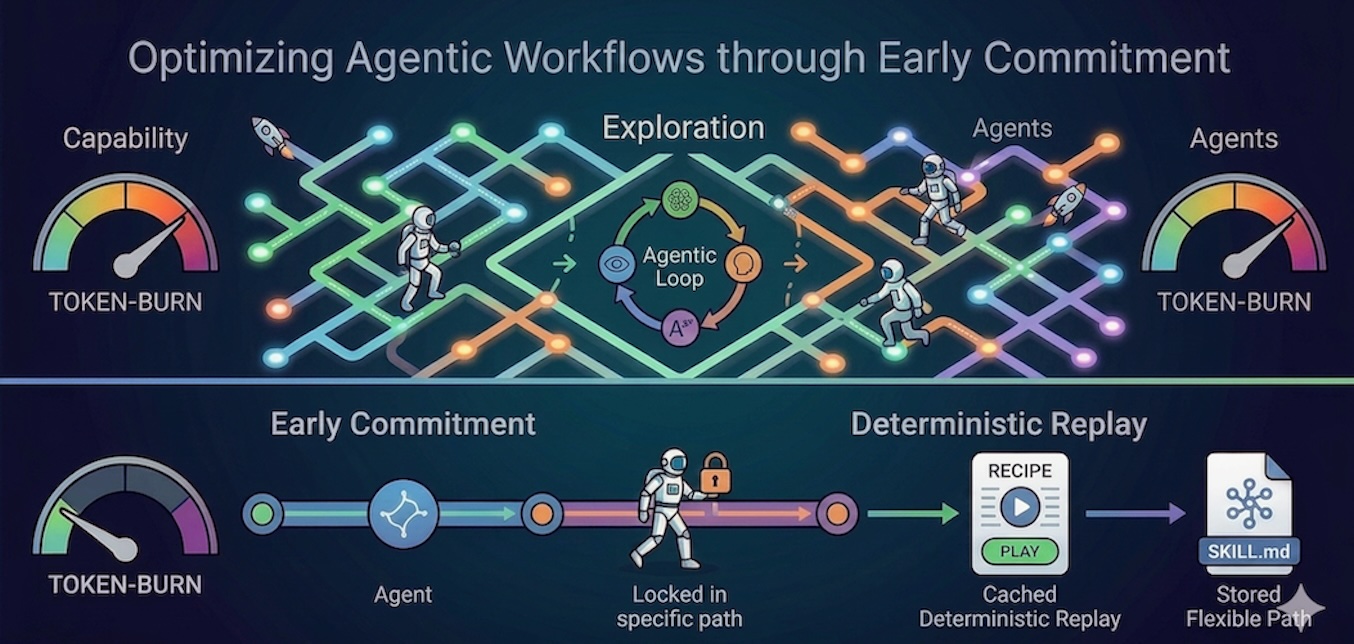
Architekturlösungen durch frühzeitiges Engagement und deterministische Wiederholung
Early Dedication hat sich bei der strukturierten Problemlösung als vielversprechend erwiesen und kann auch auf Agenten-Workflows angewendet werden (3). Dazu gehört zunächst die Klassifizierung des Issues, beispielsweise durch die Strukturierung der Systemaufforderung, sodass das Modell ein bestimmtes Klassifizierungs-Tag ausgeben muss. Indem Sie einen Agenten dazu zwingen, den Problemtyp zu klassifizieren und Einschränkungen festzulegen, bevor er die Ausführungslogik generiert, verhindern Sie, dass der Agent halluziniert oder Sackgassen erforscht. Dadurch wird Lärm vermieden und der Agent konzentriert sich ausschließlich auf die Ausführung und nicht auf die kontinuierliche Erkundung.
Beispielsweise können wir in einem Telemedizin-Triage-Workflow eine frühzeitige Zusage durchsetzen, indem wir vom Agenten verlangen, die Begegnung definitiv als „routinemäßige Nachfüllung von Rezepten“ zu klassifizieren, bevor er Maßnahmen ergreift. Sobald der Agent sich dieser spezifischen Einschränkung unterwirft, beschränkt er seine Instrument-Aufrufe strikt auf die Apothekendatenbank und umgeht dabei vollständig die teuren, ergebnisoffenen diagnostischen Argumentationspfade, die er andernfalls bei der Diagnose eines Patienten einschlagen würde.
Eine aktuelle Studie von Wang, X., et al. stellt das LOOP Talent Engine Framework vor, das durch die Verwendung eines One-Shot-Aufzeichnungs- und deterministischen Wiedergabeparadigmas ein frühzeitiges Engagement auf der Infrastrukturebene ermöglicht (4). Der Agent kann einmal autonom mit vollständiger Argumentation erkunden, und das System kompiliert dann diese erfolgreiche Ablaufverfolgung in ein verzweigungsfreies Rezept. Für alle zukünftigen Läufe kann das LLM umgangen werden, was Ausführungsdeterminismus garantiert und die Token-Nutzung bei täglichen Aufgaben um über 93,3 % und bei hochfrequenten Ausführungen um bis zu 99,98 % reduziert. Dieses Konzept kann auf Agenten-Workflows erweitert werden.
Erwägen Sie die Erstellung täglicher Klinik-Compliance-Berichte oder Standardzusammenfassungen nach der Entlassung, bei denen es sich um äußerst stabile, sich wiederholende Aufgaben handelt. Ausgehend von der explorativen Vorgehensweise und dem schnellen Übergang zu einem deterministischen Rahmen muss ein Agent die komplexe Datenextraktion aus der elektronischen Gesundheitsakte genau einmal durchdenken. Für die nächsten hundert Patienten, die mit demselben Verfahren entlassen werden, führt das System genau dieses verzweigungsfreie Rezept aus und tauscht zuverlässig die Vitalwerte und Daten des neuen Patienten aus, ohne jemals das LLM aufzurufen. Dies garantiert keine halluzinierten Daten zu sich wiederholenden Gesundheitsaufgaben und maximiert gleichzeitig die Token-Effizienz.
ML-Praktiker müssen zwischen einer rein deterministischen Wiedergabe (wie LOOP), die die Token-Einsparungen maximiert, und einem hybriden Ansatz (Speicherung des untersuchten Pfads in einer SKILL.md-Datei) entscheiden. Der hybride Ansatz tauscht einige dieser Token-Einsparungen gegen Argumente über einen geführten Pfad ein, der äußerst optimum ist, aber dennoch genügend Flexibilität lässt, um sich selbst an ein sich änderndes zugrunde liegendes Rahmenwerk anzupassen. Unabhängig davon, ob diese Talent-Datei manuell oder durch einen autonomen, sich selbst verbessernden Mechanismus aktualisiert wird, gewährleistet die Beibehaltung dieses Denkspielraums Anpassungsfähigkeit und langfristige Robustheit. Wenn sich beispielsweise die Datenbankstruktur ändert, kann der Agent die SQL-Abfragen aktualisieren und die Informationen extrahieren.
Fazit: Die Discover-Commit-Measure ML-Pipeline
ML-Ingenieure und Produktmanager müssen ihre Anwendungen anpassen, um die enorme Intelligenz autonomer Agenten zu nutzen und uneingeschränkte Agentennutzungen für die anfängliche Problemerkennung und komplexe, einmalige Randfälle zu nutzen. Dies führt zu optimalen Lösungen, ohne dass ein teurer Reinforcement-Studying-Zyklus durchgeführt werden muss (der häufig durch mangelndes Fachwissen, Plattformbeschränkungen, Schulungskosten oder geschlossene Modelle blockiert wird).
Sobald wir einen nahezu optimalen Pfad gefunden haben, erfordert die Token-Ökonomie für strukturierte und sich wiederholende Aufgaben, dass wir eine frühzeitige Verpflichtung im Immediate-Design durchsetzen und deterministische Wiedergabearchitekturen verwenden, um den Ausführungspfad zwischenzuspeichern.
Mit der Skalierung von Agentenprodukten müssen wir die Betriebsmetriken weg von einfachen Aufgabenerfolgsraten und hin zu Token-Effizienz und Wert professional generiertem Token verlagern.
Referenzen
- Vir, R. & Vir, R. (2026, 4. März). Der Phantasm des Prototyps entfliehen: Warum die Unternehmens-KI ins Stocken gerät. Auf dem Weg zur Datenwissenschaft.
- Clune, J. (2025, 12. Februar). Gastvortrag 6 CS329A von Prof. Jeff Clune: Open-Finish Agent Studying within the Period of Basis Fashions (Video). YouTube.
- Vir, R. (2026, 1. Januar). Warum frühes Engagement der KI hilft, strukturierte Probleme zu lösen. Auf dem Weg zur KI.
- Wang, X., Yu, Ok., Liang, X., Wang, L. & Han, C. (2026). Intestine gemacht: Die LOOP-Talent-Engine, die eine Erfolgsquote von 99 % erreicht und den Token-Verbrauch durch einmalige Aufzeichnung und deterministische Wiedergabe um 99 % reduziert. arXiv.