Überblick
Nur optische Illusionen oder umwerfende Rätsel. Sie können auch logisch sein, was bei näherer Untersuchung anfänglichen Beobachtungen abfällt. In der Information Science entstehen Paradoxien, wenn wir Zahlen zum Nennwert nehmen, ohne in den Kontext dahinter zu prüfen. Man kann die schärfsten Bilder haben und immer noch mit der falschen Geschichte weggehen.
In diesem Artikel diskutieren wir drei logische Paradoxe, die für alle, die Daten zu schnell interpretieren, als Vorsicht dienen, ohne den Kontext anzuwenden. Wir untersuchen, wie Paradoxe in den Anwendungsfällen von Information Science & Enterprise Intelligence (BI) entstehen, und erweitern dann die Erkenntnisse in das Abrufen von RAG-Systemen (RAGMent-Augmented Era), in denen ähnliche Paradoxe die Qualität der Eingabeaufforderung und der Ausgabe des Modells untergraben können.
Simpsons Paradox in Enterprise Intelligence
Das Paradox von Simpson beschreibt das Szenario, in dem Tendencies umgekehrt sind, wenn Daten aggregiert werden. Mit anderen Worten, die Tendencies, die Sie in Untergruppen beobachten, werden umgedreht, wenn Sie die Zahlen kombinieren und analysieren. Nehmen wir an, wir analysieren den Verkauf von vier Standorten einer beliebten Eiskette. Wenn die Verkäufe für jeden Standort einzeln analysiert werden, deutet dies vor, dass der Schokoladengeschmack bei den Kunden am meisten bevorzugt ist. Wenn sich der Umsatz jedoch summiert, verschwindet der Pattern und die neuen kombinierten Ergebnisse deuten darauf hin, dass Vanille am meisten bevorzugt wird. Diese Trendumkehr wird mit Simpsons Paradoxon bezeichnet. Wir verwenden die fiktiven Daten unten, um dies zu demonstrieren.
| Standort | Schokolade | Vanille | Gesamtkunden | Schokolade % | Vanille % | Gewinner |
| Vorort a | 15 | 5 | 20 | 75,0% | 25,0% | Schokolade |
| Stadt b | 33 | 27 | 60 | 55,0% | 45,0% | Schokolade |
| Einkaufszentrum | 2080 | 1920 | 4000 | 52,0% | 48,0% | Schokolade |
| Flughafen | 1440 | 2160 | 3600 | 40,0% | 60,0% | Vanille |
| Gesamt | 3568 | 4112 | 7680 | 46,5% | 53,5% | Vanille! |
Unten ist eine visuelle Illustration.

Ein Datenanalyst, der diese Dynamik der Untergruppe übersieht, kann davon ausgehen, dass Schokolade unterdurchschnittlich ist. Daher ist es wichtig, Zahlen nach Untergruppen zu aggregieren und nach dem Vorhandensein von Simpsons Paradoxon zu überprüfen. Wenn eine Umkehrung des Tendencies auftritt, sollte die lauernde Variable als nächster Schritt identifiziert werden. Eine lauernde Variable ist der versteckte Faktor, der die Gruppenergebnisse beeinflusst. In diesem Fall handelt es sich bei dem Speicherort in der lauerhaften Variablen. Es ist ein tiefes kontextbezogenes Verständnis erforderlich, um zu interpretieren, warum der Verkauf von Vanille -Eis am Flughafen hoch conflict und das Gesamtergebnis umdrehte. Einige Fragen, die zur Untersuchung verwendet werden könnten, sind:
• Halten Sie Flughafengeschäfte weniger Schokoladenoptionen an?
• Bevorzugen Reisenden milder Aromen?
• Gab es eine Werbekampagne, die Vanille in Geschäften am Flughafen begünstigte?
Simpsons Paradox in Rag -Systemen
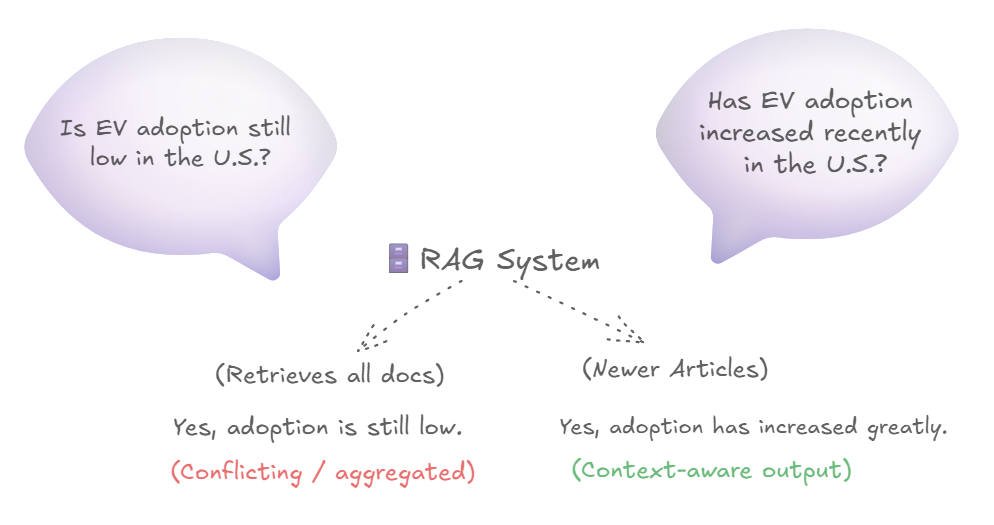
Nehmen wir an, Sie haben ein Modell mit einem Lappen (retrieval-generierter Era), das die öffentliche Stimmung gegenüber Elektrofahrzeugen (EVs) (EVs) misst, und beantwortet Fragen rund um dieselben. Das Modell verwendet Nachrichtenartikel von 2010 bis 2024. Bis 2016 erhielten EVs aufgrund ihres begrenzten Bereichs, ihres höheren Kaufpreises und des Mangels an Ladestationen gemischte Meinungen. All diese Faktoren machten das Fahren in EVs für große Strecken unmöglich. Zeitungsberichte vor 2017 haben solche Mängel hervorgehoben. Ab 2017 wurde EVs jedoch aufgrund der Verbesserung der Leistung und der Verfügbarkeit von Ladestationen in einem guten Licht wahrgenommen. Diese Wahrnehmungsverschiebung ereignete sich insbesondere nach dem erfolgreichen Begin des Premium -EV von Tesla. Ein Lappenmodell, das Nachrichtenberichte von 2010 bis 2024 verwendet, würde höchstwahrscheinlich widersprüchliche Antworten auf ähnliche Fragen geben, was das Paradoxon des Simpson auslösen wird.
Wenn der Lappen beispielsweise gefragt wird, „ist die EV -Einführung in den USA noch niedrig?“ Wenn der Lappen gefragt wird, „hat die EV -Adoption in letzter Zeit in den USA zugenommen?“ In diesem Fall ist die lauernde Variable das Veröffentlichungsdatum. Eine praktische Lösung für dieses Drawback besteht darin, Dokumente (Artikel) in zeitbasierte Mülleimer während der Vorverarbeitungsphase zu markieren. Weitere Optionen sind die Ermutigung der Benutzer, einen Zeitbereich in ihrer Eingabeaufforderung anzugeben (z. B. in den letzten fünf Jahren, wie die Einführung von EV?) Oder die Feinabstimmung des LLM, um die Zeitleiste ausdrücklich zu erklären, die sie für seine Reaktion in Betracht ziehen (z. B. um 2024, die EV-Annahme hat stark zugenommen.).
Genauigkeitsparadox in Datenwissenschaftsproblemen
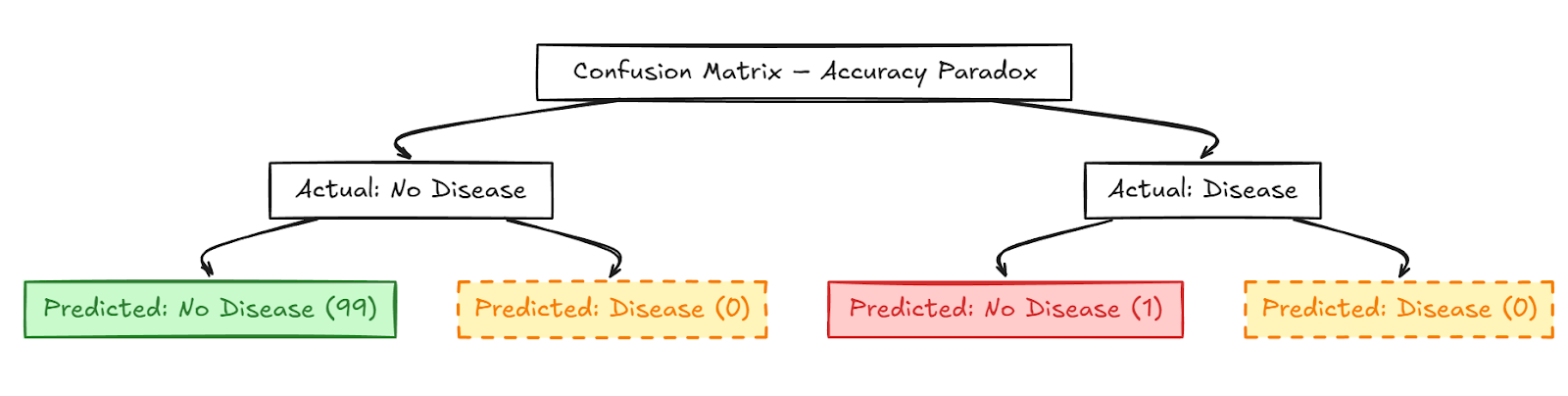
Der Kern des Genauigkeitsparadoxons ist, dass eine hohe Genauigkeit nicht auf eine nützliche Ausgabe hinweist. Nehmen wir an, Sie bauen ein Klassifizierungsmodell auf, um festzustellen, ob ein Affected person eine seltene Krankheit hat, die nur 1 von 100 betrifft. Das Modell identifiziert und bezeichnet diejenigen, die keine Krankheit haben, und erreicht dadurch eine Genauigkeit von 99%. Es kann jedoch nicht die Particular person identifizieren, die die Krankheit hat und dringend medizinische Hilfe benötigt. Dadurch wird das Modell nutzlos, um die Krankheit zu erkennen, was ihr Zweck ist. Dies geschieht insbesondere in unausgeglichenen Datensätzen, in denen die Beobachtungen für eine Klasse minimal sind. Dies wurde in der Abbildung unten dargestellt.
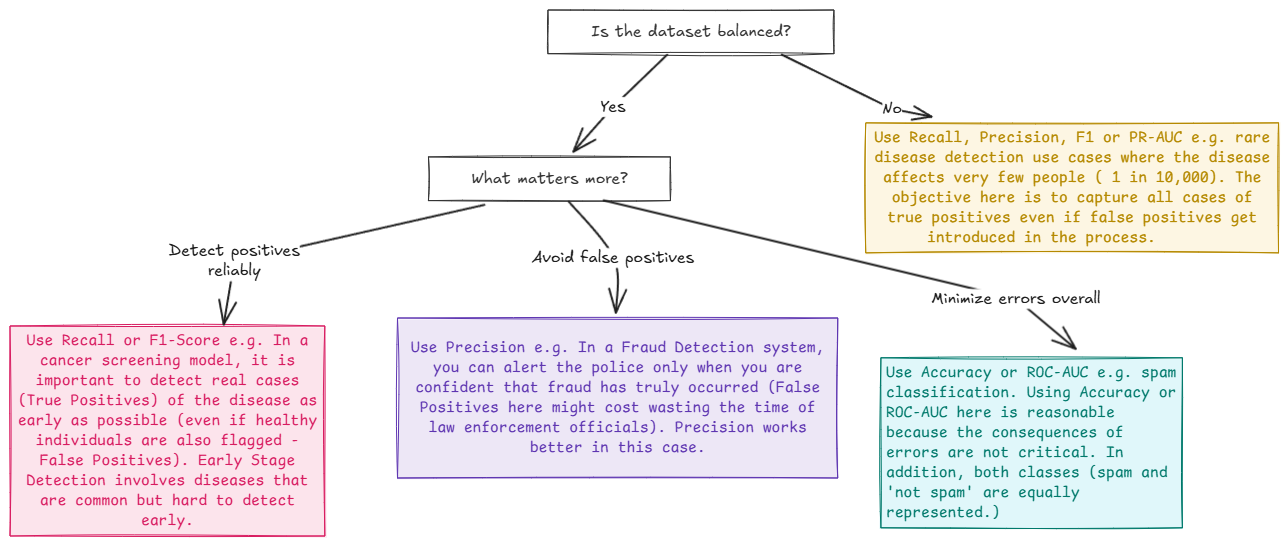
Der beste Weg, um das Genauigkeitsparadoxon anzugehen, besteht darin, Metriken zu verwenden, die die Leistung der Minderheitenklassen wie Präzision, Rückruf und F1-Rating erfassen. Ein weiterer Ansatz, der befolgt wird, besteht darin, unausgewogene Datensätze als Anomalie -Erkennungsprobleme zu behandeln, als Klassifizierungsprobleme. Man könnte auch in Betracht ziehen, mehr Minderheitenklassendaten (wenn möglich) zu sammeln, die Minderheitenklasse zu übertreffen oder die Mehrheitsklasse zu untermachten. Im Folgenden finden Sie eine schnelle Anleitung, die feststellt, welche Metrik je nach Anwendungsfall, Objektiv und Folgen von Fehlern verwendet werden soll.
Genauigkeitsparadox in LLMs
Während das Genauigkeitsparadox ein häufiges Thema ist, das viele Datenwissenschaftler angehen, werden ihre Auswirkungen auf LLMs weitgehend ignoriert. Die Genauigkeitsmetrik kann in Anwendungsfällen, die Sicherheit, Toxizitätserkennung und Vorspannungsminderung beinhalten, gefährlich überverpunden. Eine hohe Genauigkeit bedeutet nicht, dass ein Modell honest und sicher zu bedienen ist. Zum Beispiel ist ein LLM -Modell mit einer Genauigkeit von 98% nützlich, wenn es 2 böswillige Aufforderungen als sicher und harmlos falsch klassifiziert. In LLM-Bewertungen ist es daher eine gute Idee, Rückruf, Präzision oder PR-Auc über die Genauigkeit zu verwenden, da sie angeben, wie intestine das Modell Minderheitenklassen angeht.
Goodharts Gesetz in Enterprise Intelligence
Wirtschaftswissenschaftler Charles Goodhart erklärte das „Wenn ein Maß zum Ziel wird, ist es nicht mehr ein gutes Maß.“ Dieses Gesetz ist eine sanfte Erinnerung daran, dass das Modell nach hinten losdreht, wenn Sie eine Metrik nicht optimieren, ohne die Auswirkungen und den Kontext zu verstehen.
Ein Supervisor einer fiktiven On-line -Nachrichtenagentur legt einen KPI für sein Crew fest. Er bittet das Crew, die Sitzungsdauer um 20percentzu erhöhen. Das Crew erweitert die Einführung künstlich und fügt auch Füllstoffinhalte hinzu, um die Sitzungsdauer zu erhöhen. Die Sitzungsdauer steigt, aber die Videoqualität geht verloren, und infolgedessen wird der Wert, den Benutzer aus dem Video erhalten, verringert.
Ein weiteres Beispiel bezieht sich auf die Kundendehnung. In dem Versuch, die Kundenabweiche zu reduzieren, beschließt eine abonnementbasierte Unterhaltungs-App, die Schaltfläche „Abbestellen“ an einem schwer zu findenden Ort im Webportal zu platzieren. Infolgedessen reduziert sich der Kunde ab, ist jedoch nicht auf eine verbesserte Kundenzufriedenheit zurückzuführen. Dies liegt ausschließlich an begrenzten Ausstiegsoptionen – einer Phantasm der Kundenbindung. Im Folgenden finden Sie eine visuelle Abbildung, die zeigt, wie die Bemühungen, Wachstumsziele zu erreichen oder zu übertreffen (z. B. die zunehmende Sitzungsdauer oder das Engagement der Benutzer), häufig zu unbeabsichtigten Konsequenzen führen, was zu einem Rückgang der Benutzererfahrung führen kann. Wenn Groups auf künstliche Inflationstaktiken zurückgreifen, um die Leistungsmetriken zu verbessern, sieht die metrische Verbesserung auf dem Papier intestine aus, aber sie sind in keiner Weise aussagekräftig.
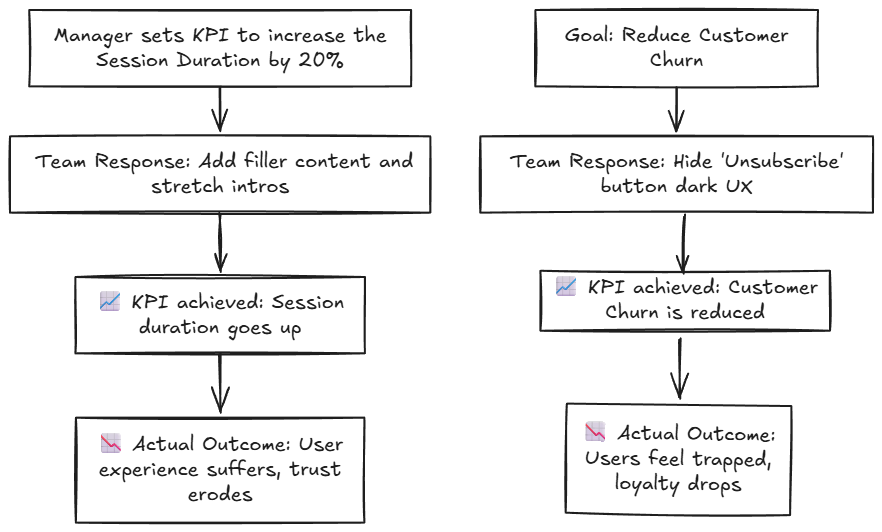
Goodharts Gesetz in LLMs
Wenn Sie ein LLM zu viel in einem bestimmten Datensatz (insbesondere eines Benchmarks) trainieren, kann es Muster aus diesen Trainingsdaten auswendig lernen, anstatt zu lernen, dass sie verallgemeinert werden. Dies ist ein klassisches Beispiel für eine Überanpassung, bei der das Modell in diesen Trainingsdaten äußerst intestine abschneidet, aber bei Eingaben in der realen Welt schlecht abschneidet.
Nehmen wir an, Sie schulen einen LLM, um Nachrichtenartikel zusammenzufassen. Sie verwenden die Rouge-Metrik (Rückruf-orientierte Zweitbesetzung für die Gisting-Bewertung), um die Leistung des LLM zu bewerten. Die Rouge Metric Rewards Actual oder nahezu passende Übereinstimmungen von N-Gramm mit den Referenzzusammenfassungen. Im Laufe der Zeit beginnt das LLM, große Textphrasen aus den Eingangsartikeln zu kopieren, um einen erhöhten Rouge -Rating zu erhalten. Es wird auch Schlagworte verwendet, die in Referenzzusammenfassungen viel erscheinen. Nehmen wir an, im Enter -Artikel ist der Textual content „Die Financial institution erhöhte die Zinsen zur Eindämmung der Inflation, und dies führte dazu, dass die Aktienkurse stark zurückgingen.“ Das Overfit -Modell würde es als „die Financial institution erhöhten Zinssätze zur Eindämmung der Inflation“ zusammenfassen, während ein Verallgemeinerungsmodell es als „Zinswanderung aus löste einen Rückgang der Aktienmärkte aus“ zusammen. Die folgende Abbildung zeigt, wie die Optimierung Ihres Modells zu viel für eine Bewertungsmetrik zu minderwertigen Antworten führen kann (Antworten, die auf Papier intestine sind, aber nicht hilfreich sind).
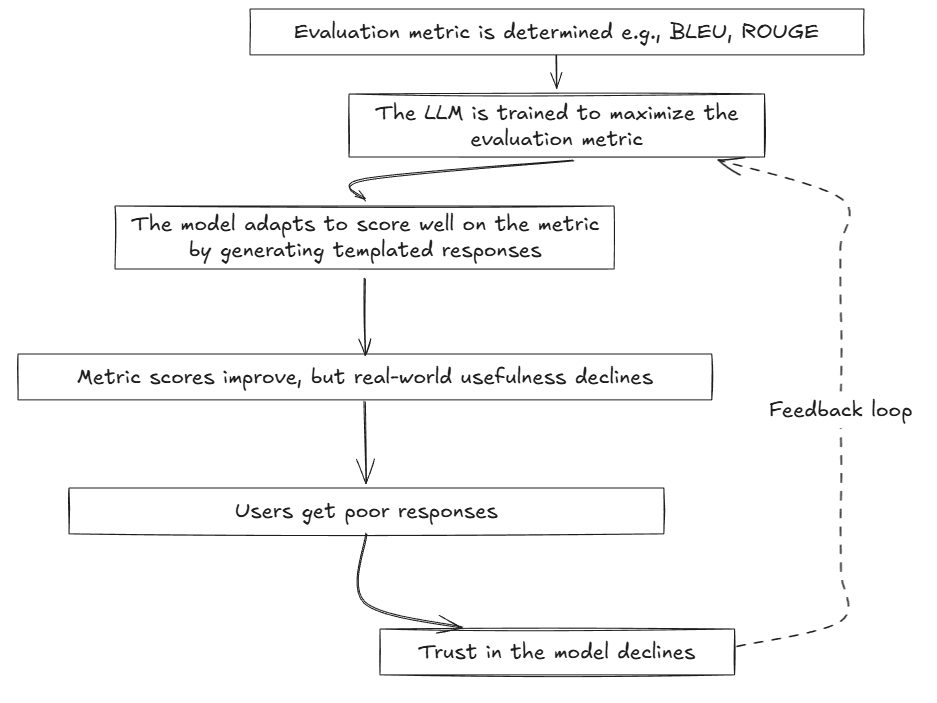
Schließende Bemerkungen
Egal, ob es sich um Enterprise Intelligence oder LLMs handelt, Paradoxe können sich einschleichen, wenn Zahlen und Metriken ohne die zugrunde liegende Nuance und den zugrunde liegenden Kontext behandelt werden. Es ist auch wichtig, sich daran zu erinnern, dass Überanpassungen das größere Bild schädigen können. Die Kombination der quantitativen Analyse mit menschlichen Einsichten ist entscheidend, um solche Fallstricke zu vermeiden und zuverlässige Berichte und leistungsstarke LLMs zu erstellen, die wirklich Wert liefern.