
Haben Sie jemals Zepto für die On-line -Bestellung von Lebensmitteln verwendet? Sie müssen gesehen haben, dass Zepto, wenn Sie überhaupt ein falsches Wort schreiben oder einen Namen falsch geschrieben haben, immer noch versteht und Ihnen die perfekten Ergebnisse zeigt, nach denen Sie gesucht haben. Benutzer, die „Kele -Chips“ anstelle von „Bananenchips“ tippen, haben Schwierigkeiten, zu finden, was sie wollen. Rechtschreibfehler und einheimische Abfragen führen zu schlechten Benutzererfahrungen und reduzierten Conversions. Das Information Science -Workforce von Zepto baute ein robustes System auf, um dieses Downside mithilfe von LLM und RAG anzugehen, um mehrsprachige Rechtschreibfehler zu beheben. In diesem Leitfaden werden wir diese Finish-to-Finish-Funktion von Fuzzy-Abfrage bis hin zu korrigiertem Ausgang replizieren. In diesem Leitfaden wird erläutert, wie technisch wichtig bei der Suche nach Suchqualität und mehrsprachiger Abfrageberichtung von Bedeutung ist.
Zeptos System verstehen
Technischer Fluss
Lassen Sie uns den technischen Fluss, den Zepto für seine mehrsprachige Abfrageauflösung verwendet, verstehen. Dieser Fluss umfasst mehrere Komponenten, die wir in einiger Zeit durchlaufen werden.
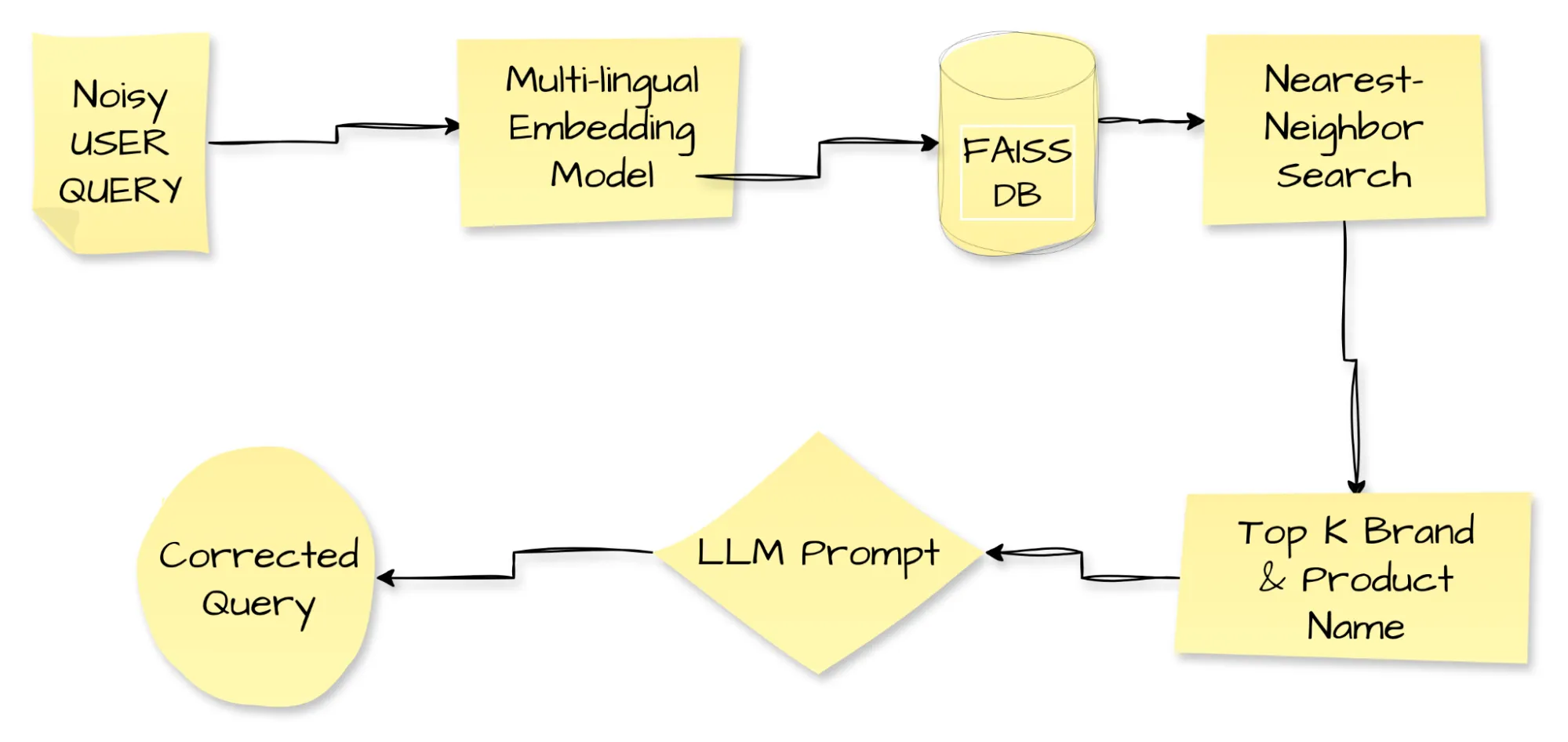
Das Diagramm verfolgt eine laute Benutzerabfrage durch seine vollständige Korrekturreise. Der falsch geschriebene oder einheimische Textual content tritt in die Pipeline ein. Ein mehrsprachiges Einbettungsmodell wandelt es in einen dichten Vektor um. Das System füttert diesen Vektor in Faiss, die Ähnlichkeitssuche-Engine von Fb, die die Marke High Ok und die Produktnamen zurückgibt, die im Einbettungsraum am nächsten stehen. Als nächstes leitet die Pipeline sowohl die laute Abfrage als auch die abgerufenen Namen an eine LLM -Eingabeaufforderung weiter, und das LLM gibt eine saubere, korrigierte Abfrage aus. Zepto setzt diese Abfrage-Auflösungsschleife ein, um die Benutzererfahrung zu schärfen und Conversions zu heben. Zepto, der falsche Schreibweisen, Code-Misch-Phrasen und regionale Sprachen bearbeitet, protokollierte einen Sprung der Conversion-Raten um 7,5 % für betroffene Abfragen, eine klare Demonstration der Macht der Technologie, die alltäglichen Interaktionen zu erhöhen.
Kernkomponenten
Konzentrieren wir uns nun auf die Kernkonzepte, die wir in diesem System verwenden.
1. falsch geschriebene Abfragen und einheimische Abfragen
Benutzer geben häufig einheimische Begriffe mit einer Mischung aus englischen und regionalen Wörtern in einer Abfrage ein. Zum Beispiel „Kele -Chips“ („Bananenchips“), „Balekayi -Chips“ (Kannada) usw. Phonetische Typisierung wie „Kothimbir“ (phonetisch tippt Marathi/Hindi -Wort für Koriander) oder „Paal“ für Milch in Tamil macht den traditionellen Suchkampf hier. Die Bedeutung geht ohne Normalisierung oder Transliterationsunterstützung verloren.
2. RAG (Retrieval-Augmented Era
Rag ist eine Pipeline, die die semantische Abruf (Vektoreinbettungen und Metadaten -Lookup) mit LLM -Generierungsfunktionen kombiniert. Zepto verwendet LAPPEN Funktionalität zum Abrufen der obersten okay relevanten Produktnamen und Marken beim Erhalt einer lauten, falsch geschriebenen und umseitigen Abfrage. Anschließend werden diese ähnlichsten abgerufenen Produkte oder Markennamen zusammen mit der lauten Abfrage zur Korrektur an LLMs zugeführt.
Vorteile der Verwendung von Lappen in Zeptos Anwendungsfall:
- Grounds LLM durch Verhinderung der Halluzination durch Kontext.
- Verbessert die Genauigkeit und sorgt für relevante Markenzeitkorrekturen.
- Reduziert die sofortige Größe und Inferenzkosten durch Verengung des Kontextes.
3. Vektordatenbank
A Vektordatenbank ist eine spezialisierte Artwork von Datenbank, die zum Speichern, Index -Wort- oder Satz -Einbettungsdings entwickelt wurde, bei denen es sich um numerische Darstellungen von Datenpunkten handelt. Diese Vektordatenbanken werden verwendet, um hochdimensionale Vektoren mithilfe einer Ähnlichkeitssuche bei einer Abfrage abzurufen. FAISS ist eine Open-Supply-Bibliothek, die speziell für die effiziente Ähnlichkeitssuche und das Clustering dichter Vektoren auf effiziente Weise entwickelt wurde. FAISS wird verwendet, um schnell nach ähnlichen Einbettungen von Multimedia -Dokumenten zu suchen. In Zeptos System verwenden sie FAISS, um die Einbettungen ihrer Markennamen, Tags und Produktnamen zu speichern.
4. schrittweise Aufforderung und JSON -Ausgabe
Zeptos Fluss erwähnt einen modularen Aufbruch, dessen Hauptmotiv darin besteht, die komplexe Aufgabe in kleine schrittweise Aufgaben zu zerlegen und sie dann ohne Fehler effizient auszuführen, wodurch die Genauigkeit verbessert wird. Es beinhaltet die Erkennung, ob die Abfrage falsch geschrieben oder einheimisch ist, die Begriffe korrigiert, in englische kanonische Begriffe übersetzt und als JSON -Struktur ausgegeben wird.
JSON Schema sorgt für die Zuverlässigkeit und Lesbarkeit, beispielsweise:
{
"original_query": "...",
"corrected_query": "...",
"translation": "..."
}Ihre System-Eingabeaufforderung umfasst nur wenige Beispiele, die eine Mischung aus englischen und umseitigen Korrekturen enthalten, um das LLM-Verhalten zu leiten.
5. Inhouse LLM Internet hosting
Zepto verwendet Meta LAMA3-8Bgehostet auf Datenbanken für Kostenkontrolle und Leistung. Sie verwenden Anweisungen Feinabstimmungdas ist eine leichte Stimmung mit schrittweisen Eingabeaufforderungen und Rollenspielanweisungen. Es stellt sicher, dass sich LLM nur auf das Verhalten auf sofortiger Ebene konzentriert und eine kostspielige Modellumschulung vermeidet
6. Implizite Suggestions über Benutzerreformulationen
Benutzer -Suggestions ist von entscheidender Bedeutung, wenn Ihre Funktion noch neu ist. Jede schnelle Korrektur und bessere Ergebnisse Zepto -Benutzer sehen als gültige Lösung. Sammeln Sie diese Signale, um der Eingabeaufforderung neue Beispiele für frische Beispiele hinzuzufügen, neue Synonyme in das Abruf-DB und die Kürbisfehler einzugeben. Der A/B -Check von Zepto zeigt einen Umbau von 7,5 Prozent.
Replikation des Abfrageauflösungssystems
Jetzt werden wir versuchen, Zeptos mehrsprachiger Abfrageauflösungssystem zu replizieren, indem wir unser System definieren. Schauen wir uns das Flussdiagramm des folgenden Methods an, das wir verwenden werden.
Unsere Implementierung folgt derselben von Zepto beschriebenen Strategie:
- Semantisches Abruf: Wir nehmen zunächst die rohe Abfrage des Benutzers und finden eine Liste der potenziell relevanten Produkte aus unserem gesamten Katalog. Dies geschieht durch Vergleich der Vektor -Einbettung der Abfrage mit den Einbettungen unserer Produkte, die in einer Vektor -Datenbank gespeichert sind. Dieser Schritt liefert den notwendigen Kontext.
- LLM-betriebene Korrektur und Auswahl: Die abgerufenen Produkte (der Kontext) und die ursprüngliche Abfrage werden dann an ein großes Sprachmodell (LLM) übergeben. Die Aufgabe des LLM besteht nicht nur darin, die Rechtschreibung zu korrigieren, sondern den Kontext zu analysieren und Wählen Sie das wahrscheinlichste Produkt aus Der Benutzer beabsichtigte zu finden. Anschließend gibt es eine saubere, korrigierte Abfrage und die Argumentation hinter seiner Entscheidung in einem strukturierten Format zurück.
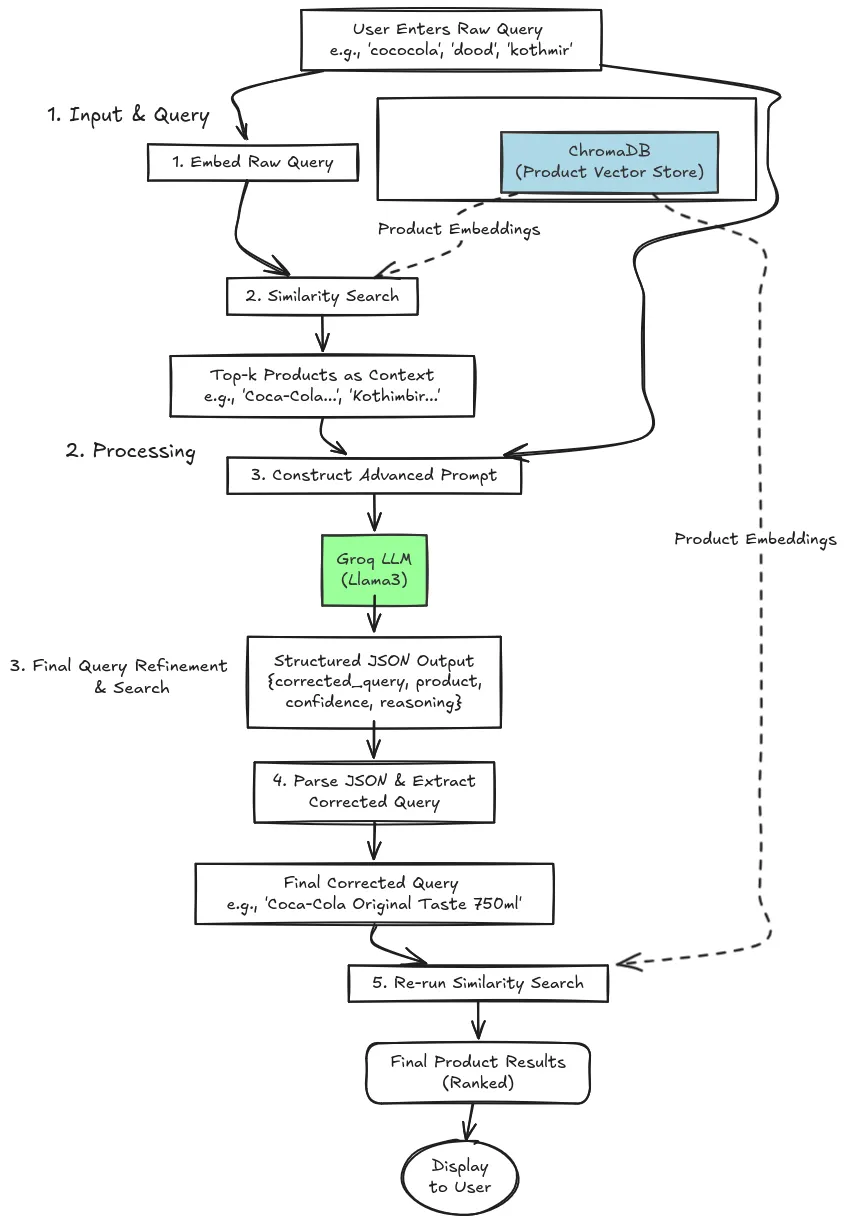
Verfahren
Der Prozess kann in den folgenden 3 Schritten vereinfacht werden:
- Eingabe und Abfrage
Der Benutzer tritt in die rohe Abfrage ein, die möglicherweise etwas Lärm enthalten oder sich in einer anderen Sprache befindet. Unser System verleiht die rohe Abfrage direkt in mehrsprachige Einbettungen. Eine Ähnlichkeitssuche wird in der Chroma DB-Vektor-Datenbank durchgeführt, die einige vordefinierte Einbettungen aufweist. Es gibt das oberste okay relevanteste Produkteinbettungen zurück.
- Verarbeitung
Füttern Sie sie zusammen mit der lauten Nutzerabfrage in LLAMA3 über eine fortgeschrittene Systemaufforderung, nachdem Sie das High-Ok-Produkteinbettung abgerufen haben. Das Modell gibt einen knusprigen JSON zurück, der die gereinigte Abfrage, den Produktnamen, die Vertrauensbewertung und seine Argumentation hält, sodass Sie genau sehen können, warum es diese Marke ausgewählt hat. Dies gewährleistet eine transparente Korrektur der Abfrage, in der wir Zugriff auf die LLM -Argumentation haben, warum es dieses Produkt und den Namen der Marke als korrigierte Abfrage ausgewählt hat.
- Abfragesteuerung und Suche
In dieser Section wird die Analyse der JSON -Ausgabe aus der LLM analysiert. Durch Extrahieren der korrigierten Abfrage haben wir Zugriff auf das relevanteste Produkt oder Markenname basierend auf der vom Benutzer eingegebenen RAW -Abfrage. In der letzten Stufe werden die Ähnlichkeitssuche auf dem Vektor -DB noch einmal aufgeführt, um die Particulars des durchsuchten Produkts zu finden. Auf diese Weise können wir das mehrsprachige Abfrageauflösungssystem implementieren.
Praktische Implementierung
Wir haben die Arbeit unseres Abfrageauflösungssystems verstanden und nun das System mithilfe von Code praktisch implementieren. Wir werden alles Schritt für Schritt alles ausführen, von der Set up der Abhängigkeiten bis zur letzten Ähnlichkeitssuche.
Schritt 1: Set up der Abhängigkeiten
Zunächst installieren wir die notwendigen Python -Bibliotheken. Wir werden Langchain zum Orchestrieren der Komponenten, Langchain-Groq für die schnelle LLM-Inferenz, FASTEMBED für effiziente Einbettungen, Langchain-Chroma für die Vektordatenbank und Pandas für die Datenbearbeitung verwenden.
!pip set up -q pandas langchain langchain-core langchain-groq langchain-chroma fastembed langchain-communitySchritt 2: Erstellen Sie einen erweiterten und komplexen Dummy -Datensatz
Um das System gründlich zu testen, benötigen wir einen Datensatz, der reale Herausforderungen widerspiegelt. Dieser CSV enthält:
- Eine breitere Vielfalt von Produkten (20+).
- Gemeinsame Markennamen (z. B. Coca-Cola, Maggi).
- Mehrsprachige und einheimische Begriffe (Dhaniya, Kanda, Nimbu).
- Potenziell mehrdeutige Gegenstände (Käseverbreitung, Käsescheiben).
import pandas as pd
from io import StringIO
csv_data = """product_id,product_name,class,tags
1,Aashirvaad Choose Atta 5kg,Staples,"atta, flour, gehu, aata, wheat"
2,Amul Gold Milk 1L,Dairy,"milk, doodh, paal, full cream milk"
3,Tata Salt 1kg,Staples,"salt, namak, uppu"
4,Kellogg's Corn Flakes 475g,Breakfast,"cornflakes, breakfast cereal, makkai"
5,Parle-G Gold Biscuit 1kg,Snacks,"biscuit, cookies, biscuits"
6,Cadbury Dairy Milk Silk,Candies,"chocolate, choco, silk, dairy milk"
7,Haldiram's Basic Banana Chips,Snacks,"kele chips, banana wafers, chips"
8,MDH Deggi Mirch Masala,Spices,"mirchi, masala, spice, pink chili powder"
9,Recent Coriander Bunch (Dhaniya),Greens,"coriander, dhaniya, kothimbir, cilantro"
10,Recent Mint Leaves Bunch (Pudina),Greens,"mint, pudhina, pudina patta"
11,Taj Mahal Crimson Label Tea 500g,Drinks,"tea, chai, chaha, pink label"
12,Nescafe Basic Espresso 100g,Drinks,"espresso, koffee, nescafe"
13,Onion 1kg (Kanda),Greens,"onion, kanda, pyaz"
14,Tomato 1kg,Greens,"tomato, tamatar"
15,Coca-Cola Authentic Style 750ml,Drinks,"coke, coca-cola, delicate drink, chilly drink"
16,Maggi 2-Minute Noodles Masala,Snacks,"maggi, noodles, on the spot meals"
17,Amul Cheese Slices 100g,Dairy,"cheese, cheese slice, paneer slice"
18,Britannia Cheese Unfold 180g,Dairy,"cheese, cheese unfold, creamy cheese"
19,Recent Lemon 4pcs (Nimbu),Greens,"lemon, nimbu, lime"
20,Saffola Gold Edible Oil 1L,Staples,"oil, tel, cooking oil, saffola"
21,Basmati Rice 1kg,Staples,"rice, chawal, basmati"
22,Kurkure Masala Munch,Snacks,"kurkure, snacks, chips"
"""
df = pd.read_csv(StringIO(csv_data))
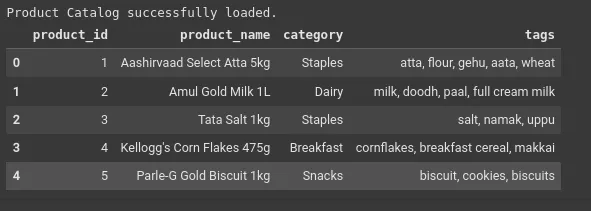
print("Product Catalog efficiently loaded.")
df.head()Ausgabe:
Schritt 3: Initialisieren Sie eine Vektordatenbank
Wir werden unsere Produktdaten in numerische Darstellungen (Einbettungen) umwandeln, die semantische Bedeutung erfassen. Wir verwenden dafür Fastembed, da es schnell ist und lokal läuft. Lagern Sie diese Einbettungen in Chromadb, einem leichten Vektor Retailer.
Einbettungsstrategie: Für jedes Produkt erstellen wir ein einzelnes Textdokument, das seinen Namen, seine Kategorie und seine Tags kombiniert. Dies schafft eine reichhaltige, beschreibende Einbettung, die die Chancen eines erfolgreichen semantischen Spiels verbessert.
Einbettungsmodell: Wir verwenden hier das Baai/BGE-Small-en-V1.5-Modell. Die „kleine“ Model des Modells ist ressourceneffizient, schnell und ein geeignetes Einbettungsmodell für mehrsprachige Aufgaben. Baai/BGE-Small-en-V1.5 ist ein starkes englisches Texteinbettungsmodell und kann in bestimmten Kontexten nützlich sein. Es bietet wettbewerbsfähige Leistung bei Aufgaben, die semantische Ähnlichkeit und Textabnahme betreffen.
import os
import json
from langchain.schema import Doc
from langchain.embeddings import FastEmbedEmbeddings
from langchain_chroma import Chroma
# Create LangChain Paperwork
paperwork = (
Doc(
page_content=f"{row('product_name')}. Class: {row('class')}. Tags: {row('tags')}",
metadata={
"product_id": row('product_id'),
"product_name": row('product_name'),
"class": row('class')
}
) for _, row in df.iterrows()
)
# Initialize embedding mannequin and vector retailer
embedding_model = FastEmbedEmbeddings(model_name="BAAI/bge-small-en-v1.5")
vectorstore = Chroma.from_documents(paperwork, embedding_model)
# The retriever shall be used to fetch the top-k most comparable paperwork
retriever = vectorstore.as_retriever(search_kwargs={"okay": 5})
print("Vector database initialized and retriever is prepared.")Ausgabe:
Wenn Sie dieses Widget sehen können, können Sie das herunterladen Baai/bge-small-en-v1.5 lokal.
Schritt 4: Entwerfen Sie die erweiterte LLM -Eingabeaufforderung
Dies ist der kritischste Schritt. Wir entwerfen eine Eingabeaufforderung, die die LLM anweist, als Experten -Abfrage -Dolmetscher zu fungieren. Die Eingabeaufforderung zwingt die LLM, einem strukturierten JSON -Objekt einen strengen Prozess zu befolgen und zurückzugeben. Dies stellt sicher, dass die Ausgabe in unserer Anwendung vorhersehbar und einfach zu bedienen ist.
Schlüsselmerkmale der Eingabeaufforderung:
- Klare Rolle: Dem LLM wird gesagt, dass es sich um ein Expertensystem für ein Lebensmittelgeschäft handelt.
- Kontext ist der Schlüssel: Es muss seine Entscheidung auf der Liste der abgerufenen Produkte stützen.
- Obligatorische JSON -Ausgabe: Wir wenden es an, ein JSON -Objekt mit einem bestimmten Schema zurückzugeben: CORRECTED_QUEYAnwesend Identified_ProductAnwesend VertrauenUnd Argumentation. Dies ist für die Systemzuverlässigkeit von entscheidender Bedeutung.
from langchain_groq import ChatGroq
from langchain_core.prompts import ChatPromptTemplate
# IMPORTANT: Set your Groq API key right here or as an surroundings variable
os.environ("GROQ_API_KEY") = "YOUR_API_KEY” # Exchange together with your key
llm = ChatGroq(
temperature=0,
model_name="llama3-8b-8192",
model_kwargs={"response_format": {"kind": "json_object"}},
)
prompt_template = """
You're a world-class search question interpretation engine for a grocery supply service like Zepto.
Your major aim is to know the consumer's *intent*, even when their question is misspelled, in a special language, or makes use of slang.
Analyze the consumer's `RAW QUERY` and the `CONTEXT` of semantically comparable merchandise retrieved from our catalog.
Primarily based on this, decide the almost certainly product the consumer is trying to find.
**INSTRUCTIONS:**
1. Examine the `RAW QUERY` towards the product names within the `CONTEXT`.
2. Establish the only finest match from the `CONTEXT`.
3. Generate a clear, corrected search question for that product.
4. Present a confidence rating (Excessive, Medium, Low) and a quick reasoning to your alternative.
5. Return a single JSON object with the next schema:
- "corrected_query": A clear, corrected search time period.
- "identified_product": The total title of the only almost certainly product from the context.
- "confidence": Your confidence within the resolution: "Excessive", "Medium", or "Low".
- "reasoning": A short, one-sentence rationalization of why you made this alternative.
If the question is just too ambiguous or has no good match within the context, confidence must be "Low" and `identified_product` might be `null`.
---
CONTEXT:
{context}
RAW QUERY:
{question}
---
JSON OUTPUT:
"""
immediate = ChatPromptTemplate.from_template(prompt_template)
print("LLM and Immediate Template are configured.")Schritt 5: Erstellen der Finish-to-Finish-Pipeline
Wir ketten jetzt alle Komponenten mit Verwendung Langchain Expressionssprache (LCEL). Dies erzeugt einen nahtlosen Fluss von der Abfrage zum Endergebnis.
Pipelinefluss:
- Die Abfrage des Benutzers wird an den Retriever übergeben, um den Kontext zu holen.
- Der Kontext und die ursprüngliche Abfrage werden in die Eingabeaufforderung formatiert und eingespeist.
- Die formatierte Eingabeaufforderung wird an die LLM gesendet.
- Die JSON -Ausgabe des LLM wird in ein Python -Wörterbuch analysiert.
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnablePassthrough
def format_docs(docs):
"""Codecs the retrieved paperwork for the immediate."""
return "n".be a part of((f"- {d.metadata('product_name')}" for d in docs))
# The primary RAG chain
rag_chain = (
format_docs, "question": RunnablePassthrough()
| immediate
| llm
| StrOutputParser()
)
def search_pipeline(question: str):
"""Executes the total search and correction pipeline."""
print(f"n{'='*50}")
print(f"Executing Pipeline for Question: '{question}'")
print(f"{'='*50}")
# --- Stage 1: Semantic Retrieval ---
initial_context = retriever.get_relevant_documents(question)
print("n(Stage 1: Semantic Retrieval)")
print("Discovered the next merchandise for context:")
for doc in initial_context:
print(f" - {doc.metadata('product_name')}")
# --- Stage 2: LLM Correction & Choice ---
print("n(Stage 2: LLM Correction & Choice)")
llm_output_str = rag_chain.invoke(question)
strive:
llm_output = json.masses(llm_output_str)
print("LLM efficiently parsed the question and returned:")
print(json.dumps(llm_output, indent=2))
corrected_query = llm_output.get('corrected_query', question)
besides (json.JSONDecodeError, AttributeError) as e:
print(f"LLM output did not parse. Error: {e}")
print(f"Uncooked LLM output: {llm_output_str}")
corrected_query = question # Fallback to authentic question
# --- Remaining Step: Search with Corrected Question ---
print("n(Remaining Step: Search with Corrected Question)")
print(f"Looking for the corrected time period: '{corrected_query}'")
final_results = vectorstore.similarity_search(corrected_query, okay=3)
print("nTop 3 Product Outcomes:")
for i, doc in enumerate(final_results):
print(f" {i+1}. {doc.metadata('product_name')} (ID: {doc.metadata('product_id')})")
print(f"{'='*50}n")
print("Finish-to-end search pipeline is prepared.")Schritt 6: Demonstration & Ergebnisse
Testen wir das System nun mit einer Vielzahl von herausfordernden Fragen, um zu sehen, wie es funktioniert.
# --- Check Case 1: Easy Misspelling ---
search_pipeline("aata")
# --- Check Case 2: Vernacular Time period ---
search_pipeline("kanda")
# --- Check Case 3: Model Title + Misspelling ---
search_pipeline("cococola")
# --- Check Case 4: Ambiguous Question ---
search_pipeline("chese")
# --- Check Case 5: Extremely Ambiguous / Obscure Question ---
search_pipeline("drink")Ausgabe:
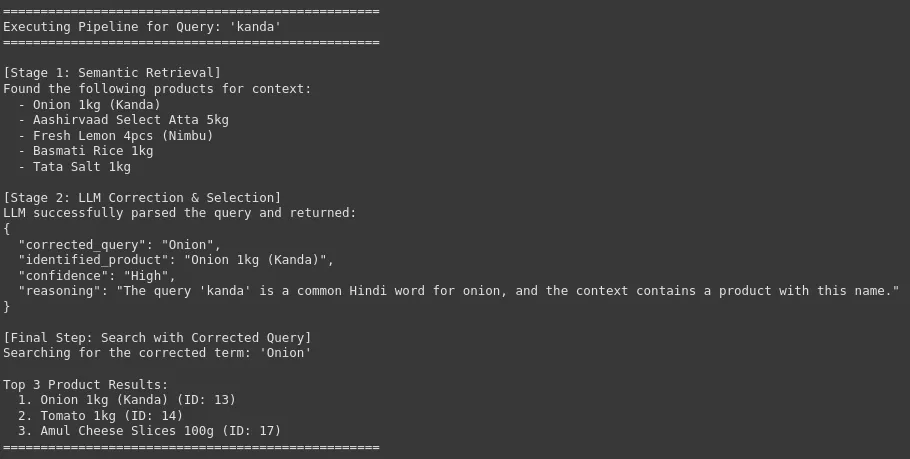
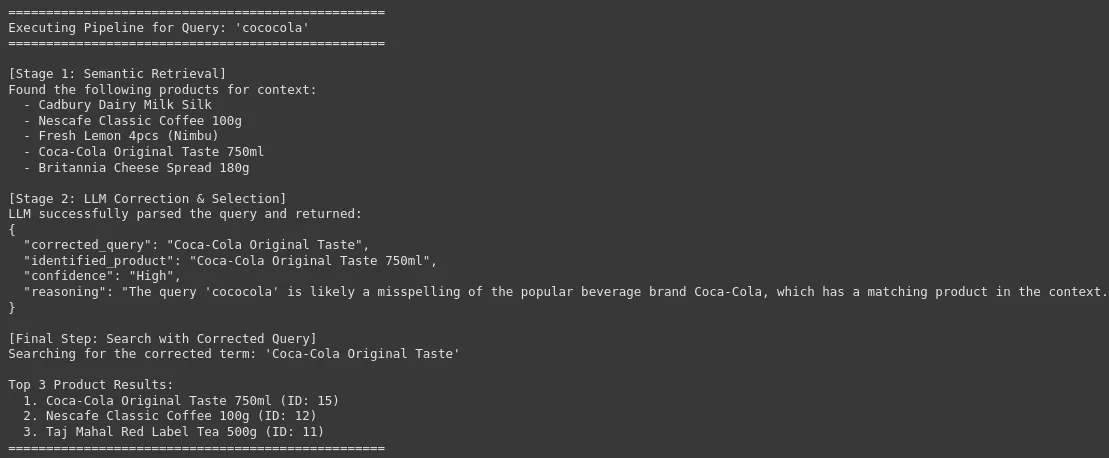
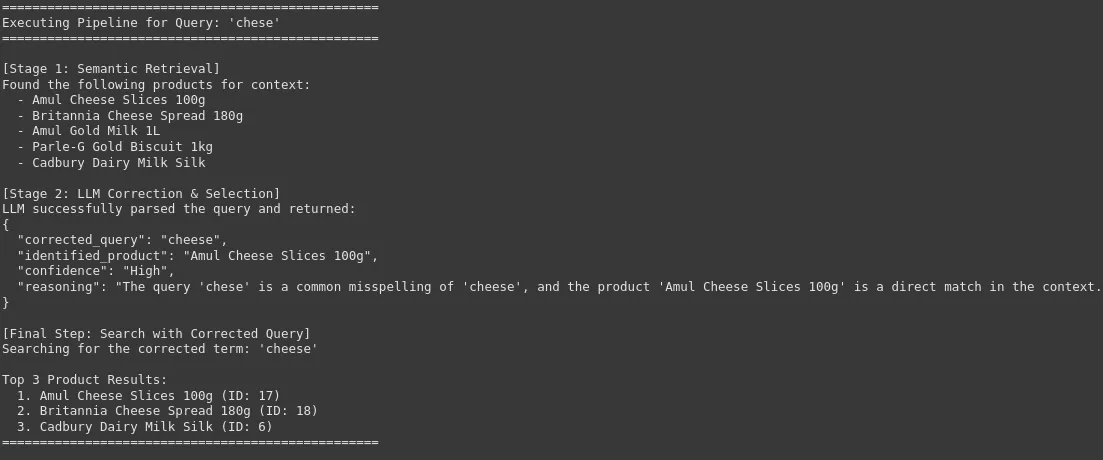
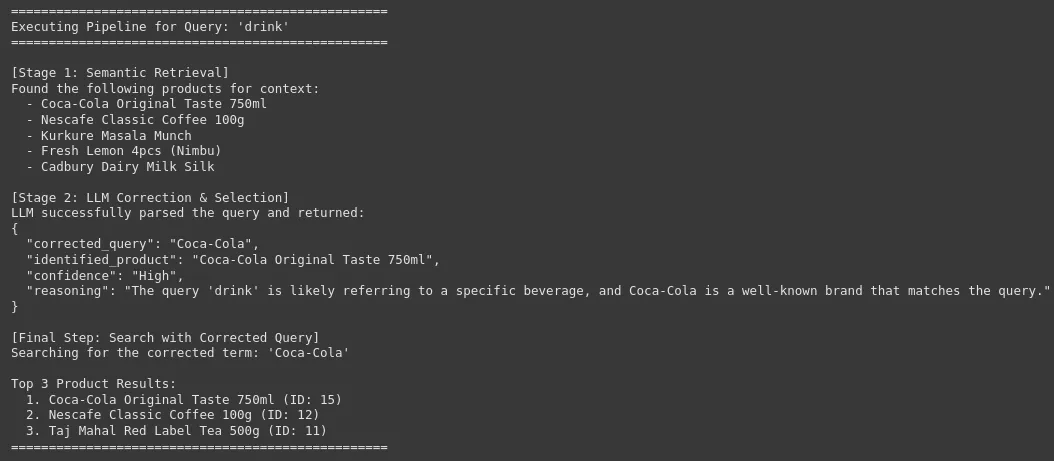
Wir können sehen, dass unser System die Roh- und Lautnutzerabfrage mit der genauen und korrigierten Marke oder dem Produktnamen korrigieren kann, was für die Produktsuche mit hoher Genauigkeit in einer E-Commerce-Plattform von entscheidender Bedeutung ist. Dies führt zu einer Verbesserung der Benutzererfahrung und einer hohen Conversion -Fee.
Sie finden den vollständigen Code im Inneren Das Git -Repository.
Abschluss
Dieses mehrsprachige Abfrageauflösungssystem repliziert erfolgreich die Kernstrategie des erweiterten Suchsystems von Zepto. Durch die Kombination eines schnellen semantischen Abrufs mit intelligenter LLM-basierter Analyse kann das System:
- Richtige Rechtschreibfehler und Slang mit hoher Genauigkeit.
- Mehrsprachige Fragen verstehen Indem Sie sie mit den richtigen Produkten anpassen.
- Anfragen disambiguieren Verwenden Sie einen abgerufenen Kontext, um die Benutzerabsicht zu schließen (z. B. zwischen „Käsescheiben“ und „Käseverbreitung“).
- Stellen Sie strukturierte, prüfbare Outputs bereitnicht nur die Korrektur, sondern auch die Argumentation dahinter.
Diese rappenbasierte Architektur ist sturdy, skalierbar und zeigt einen klaren Weg, um die Benutzererfahrung und die Suchkonversionsraten erheblich zu verbessern.
Häufig gestellte Fragen
A. RAG verbessert die Genauigkeit der LLM, indem sie sie in echten Katalogdaten verankern, Halluzination und übermäßige Eingabeaufforderung vermeiden
A. Anstelle von Blähungen Eingabeaufforderungen injizieren Sie nur die relevanten Markenbegriffe über den Abrufschritt.
A. Ein mehrsprachiges Satztransformatormodell wie Baai/Bge-Small-en-V1.5, das für die semantische Ähnlichkeit optimiert ist, eignet sich am besten für verrückte und einheimische Eingaben.
Ich bin spezialisiert auf die Überprüfung und Verfeinerung von KI-gesteuerten Forschungen, technischen Dokumentationen und Inhalten im Zusammenhang mit aufstrebenden KI-Technologien. Meine Erfahrung umfasst das KI -Modelltraining, die Datenanalyse und das Abrufen von Informationen, sodass ich Inhalte herstellen kann, die sowohl technisch genau als auch zugänglich sind.
Melden Sie sich an, um weiter zu lesen und Experten-Kuratinhalte zu genießen.