
Haben Sie sich jemals gefragt, wie wenige LLMs oder einige Instruments Ihre PDFs verarbeiten und verstehen, die aus mehreren Tabellen und Bildern bestehen? Sie verwenden wahrscheinlich eine herkömmliche OCR oder ein VLM (Imaginative and prescient Language Mannequin) unter der Motorhaube. Es ist zwar erwähnenswert, dass traditioneller OCR in Bildern handgeschriebene Textual content erkennen. Es hat sogar Probleme mit ungewöhnlichen Schriftarten oder Charakteren, wie komplexen Formeln in Forschungsarbeiten. VLMs machen diesbezüglich gute Arbeit, können jedoch Schwierigkeiten haben, die Reihenfolge von tabellarischen Daten zu verstehen. Sie können auch nicht räumliche Beziehungen wie Bilder zusammen mit ihren Untertiteln erfassen.
Was ist hier die Lösung? Hier untersuchen wir ein aktuelles Modell, das sich darauf konzentriert, all diese Probleme anzugehen. Das Smoldocling -Modell, das auf dem Umarmungsgesicht öffentlich verfügbar ist. Lassen Sie uns additionally ohne weiteres eintauchen.
Hintergrund
Das Smoldocling ist ein winziges, aber mächtiges 256-m-Visionsprachmodell für das Verständnis von Dokumenten. Im Gegensatz zu Schwergewichtsmodellen benötigen es keine Auftritte und Auftritte von VRAM, um zu laufen. Es besteht aus einem Visionscodierer und einem kompakten Decoder, der zur Herstellung von Doctags geschult ist, einer Sprache im XML-Stil, die Format, Struktur und Inhalt codiert. Seine Autoren haben es auf Millionen von synthetischen Dokumenten mit Formeln, Tabellen und Codeausschnitten ausgebildet. Es ist auch erwähnenswert, dass dieses Modell auf dem Smolvlm-256m von Face auf dem Umarmungsgesicht aufgebaut ist. Lassen Sie uns in den bevorstehenden Abschnitten eine tiefere Ebene tauchen und ihre Architektur und Demo betrachten.
Modellarchitektur
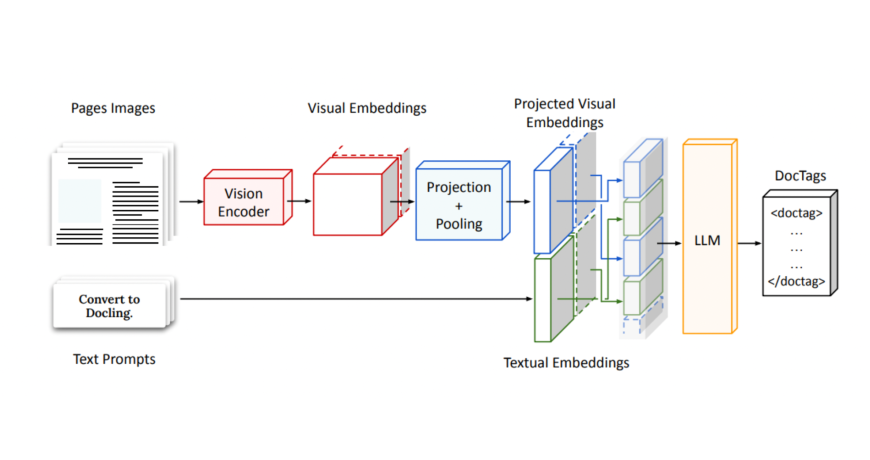
Technisch gesehen ist Smoldocling auch ein VLM, hat jedoch eine einzigartige Architektur. Das Smoldocling nimmt ein ganzseitiges Dokumentbild auf und codiert es mit einem Visionscodierer, wodurch dichte visuelle Einbettungen erzeugt. Diese werden dann projiziert und in eine feste Anzahl von Token zusammengefasst, um die Eingangsgröße eines kleinen Decoders anzupassen. Parallel dazu ist eine Benutzeraufforderung eingebettet und mit den visuellen Funktionen verkettet. Diese kombinierte Sequenz gibt dann einen Strom strukturierter
Smoldocling -Demo
Voraussetzung
Stellen Sie sicher Umarmtes Gesicht.
Du kannst Holen Sie sich hier Ihre Zugangs -Token.
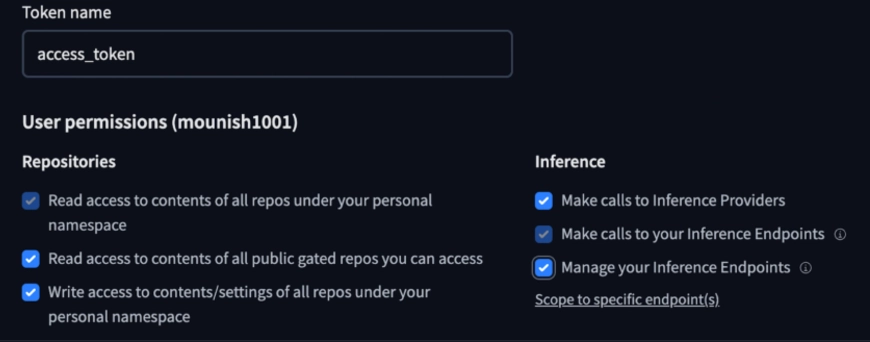
HINWEIS: Stellen Sie sicher, dass Sie die erforderlichen Berechtigungen wie den Zugang zu öffentlichen Repositories erteilen, und lassen Sie es zulässt, dass Inferenzaufrufe getätigt werden.
Verwenden wir eine Pipeline, um das Modell zu laden (alternativ können Sie auch das Modell direkt laden, das unmittelbar nach diesem untersucht wird).
Hinweis: Dieses Modell verarbeitet, wie bereits erwähnt, ein Bild eines Dokuments gleichzeitig. Sie können diese Pipeline verwenden, um das Modell mehrmals gleichzeitig zu verwenden, um das gesamte Dokument zu verarbeiten.
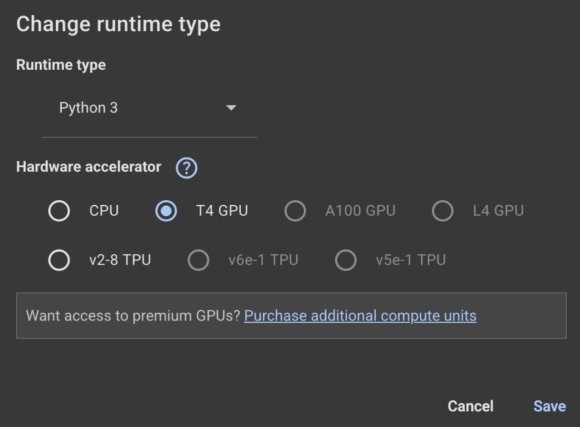
Ich werde Google Colab verwenden (lesen Sie unsere Vollständige Anleitung zu Google Colab hier) Hier. Stellen Sie sicher, dass Sie die Laufzeit in die GPU ändern:
from transformers import pipeline
pipe = pipeline("image-text-to-text", mannequin="ds4sd/SmolDocling-256M-preview")
messages = (
{
"position": "consumer",
"content material": (
{"sort": "picture", "url": "https://cdn.analyticsvidhya.com/wp-content/uploads/2024/05/Intro-1.jpg"},
{"sort": "textual content", "textual content": "Which 12 months was this convention held?"}
)
},
)
pipe(textual content=messages)Ich stellte dieses Bild eines früheren Datenhackgipfels bereit und fragte: „Welches Jahr wurde diese Konferenz abgehalten?“

Smoldocling -Reaktion
{'sort': 'textual content', 'textual content': 'Which 12 months was this convention held?'})},
{'position': 'assistant', 'content material': ' This convention was held in 2023.'})})
Is that this right? When you zoom in and look intently, you can find that it's certainly DHS 2023. This 256M parameter, with the assistance of the visible encoder, appears to be doing properly. To see its full potential, you'll be able to move a whole doc with complicated photographs and tables as an train.Versuchen wir nun, eine andere Methode zu verwenden, um auf das Modell zuzugreifen, und laden Sie es direkt mit dem Transformers -Modul:
Hier passieren wir ein Bildausschnitt aus dem Smoldocling -Forschungspapier und erhalten die Doctags als Ausgabe aus dem Modell.
Das Bild, das wir an das Modell übergeben werden:
Installieren Sie das Docking -Kernmodul zuerst vor dem Fortschritt:
! PIP Installieren Sie docle_core
Laden des Modells und geben Sie die Eingabeaufforderung an:
from transformers import AutoProcessor, AutoModelForImageTextToText
from transformers.image_utils import load_image
picture = load_image("/content material/docling_screenshot.png")
processor = AutoProcessor.from_pretrained("ds4sd/SmolDocling-256M-preview")
mannequin = AutoModelForImageTextToText.from_pretrained("ds4sd/SmolDocling-256M-preview")
messages = (
{
"position": "consumer",
"content material": (
{"sort": "picture"},
{"sort": "textual content", "textual content": "Convert this web page to docling."}
)
}
)
immediate = processor.apply_chat_template(messages, add_generation_prompt=True)
inputs = processor(textual content=immediate, photographs=(picture), return_tensors="pt")
generated_ids = mannequin.generate(**inputs, max_new_tokens=8192)
prompt_length = inputs.input_ids.form(1)
trimmed_generated_ids = generated_ids(:, prompt_length:)
doctags = processor.batch_decode(
trimmed_generated_ids,
skip_special_tokens=False,
)(0).lstrip()
print("DocTags output:n", doctags)Anzeigen der Ergebnisse:
from docling_core.sorts.doc.doc import DocTagsDocument
from docling_core.sorts.doc import DoclingDocument
doctags_doc = DocTagsDocument.from_doctags_and_image_pairs((doctags), (picture))
doc = DoclingDocument.load_from_doctags(doctags_doc, document_name="MyDoc")
md = doc.export_to_markdown()
print(md)Smoldocling -Ausgabe:
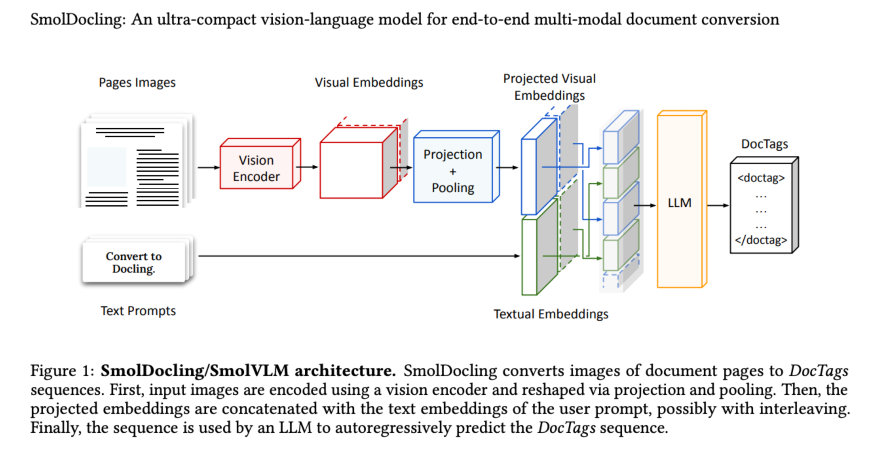
Abbildung 1: Smoldocling/Smolvlm -Architektur. Smoldocling wandelt Bilder von Dokumentseiten in Doctags -Sequenzen um. Zunächst werden Eingabebilder mit einem Sehbodierer codiert und über Projektion und Pooling umgestaltet. Anschließend werden die projizierten Einbettungen mit den Texteinbettungen der Benutzeraufforderung verkettet, möglicherweise mit Verschachtelung. Schließlich wird die Sequenz von einem LLM verwendet, um die Doctags -Sequenz autoregressiv vorherzusagen.
Schön zu sehen, wie Smoldocling über Smoldocling spricht. Der Textual content scheint auch genau zu sein. Es ist interessant, an die potenziellen Verwendungen dieses Modells zu denken. Lassen Sie uns einige Beispiele davon sehen.
Mögliche Anwendungsfälle von Smoldocling
Als Imaginative and prescient -Sprachmodell hat Smoldocling eine ausreichende potenzielle Verwendung, z. B. das Extrahieren von Daten aus strukturierten Dokumenten z. B. Forschungsarbeiten, Finanzberichte und rechtliche Verträge.
Es kann sogar für akademische Zwecke verwendet werden, z. B. für die Digitalisierung handgeschriebener Notizen und die Digitalisierung von Antwortkopien. Man kann auch Pipelines mit Smoldocling als Komponente in Anwendungen erstellen, die OCR oder Dokumentverarbeitung erfordern.
Abschluss
Zusammenfassend ist Smoldocling ein winziges, aber nützliches 256-m-Visionsprachenmodell für das Verständnis von Dokumenten. Traditionelles OCR kämpft mit handgeschriebenem Textual content und ungewöhnlichen Schriftarten, während VLMs häufig den räumlichen oder tabellarischen Kontext verpassen. Dieses kompakte Modell leistet gute Arbeit und verfügt über mehrere Anwendungsfälle, in denen es verwendet werden kann. Wenn Sie das Modell noch nicht ausprobiert haben, probieren Sie es aus und lassen Sie es mich wissen, wenn Sie dabei Probleme haben.
Häufig gestellte Fragen
Doctags sind spezielle Tags, die das Format und den Inhalt eines Dokuments beschreiben. Sie helfen dem Modell, Dinge wie Tische, Überschriften und Bilder im Auge zu behalten.
Das Pooling ist eine Ebene in neuronalen Netzwerken, die die Größe des Eingabebildes verringert. Es hilft bei der schnelleren Verarbeitung von Daten und einer schnelleren Schulung des Modells.
OCR (optische Charaktererkennung) ist eine Technologie, die Bilder oder gescannte Dokumente in bearbeitbare Textual content verwandelt. Es wird häufig verwendet, um gedruckte Papiere, Bücher oder Formen zu digitalisieren.
Leidenschaft für Technologie und Innovation, Absolvent des Vellore Institute of Know-how. Derzeit arbeitet er als Knowledge Science Trainee und konzentriert sich auf die Datenwissenschaft. Es ist sehr interessiert an tiefem Lernen und generativen KI, bestrebt, modernste Techniken zu erforschen, um komplexe Probleme zu lösen und wirkungsvolle Lösungen zu schaffen.
Melden Sie sich an, um weiter zu lesen und Experten-Kuratinhalte zu genießen.