Google Analysis hat enthüllt Eine bahnbrechende Methode für die Feinabstimmung Großspracher-Modelle (LLMs), die die Anzahl der erforderlichen Trainingsdaten um bis zu 10.000x senktwährend der Aufrechterhaltung oder sogar Verbesserung der Modellqualität. Dieser Ansatz konzentriert sich auf das aktive Lernen und Fokussierungsexpertenkennzeichnungsbemühungen auf die informativsten Beispiele – die „Grenzfälle“, in denen die Modellunsicherheit Höhe erreicht.
Der traditionelle Engpass
Feinabstimmende LLMs für Aufgaben, die ein tiefes kontextbezogenes und kulturelles Verständnis erfordern-wie die Sicherheit oder Moderation von Anzeigeninhalten-sind in der Regel huge, qualitativ hochwertige Datensätze erforderlich. Die meisten Daten sind gutartig, was bedeutet, dass für die Erkennung von Verstößen gegen die Richtlinien nur ein kleiner Teil von Beispielen wichtig ist, was die Kosten und die Komplexität der Datenkuration erhöht. Standardmethoden haben auch Schwierigkeiten, sich zu halten, wenn sich Richtlinien oder problematische Muster verschieben, was eine teure Umschulung erfordert.
Googles aktiver Lernbrachung
Wie es funktioniert:
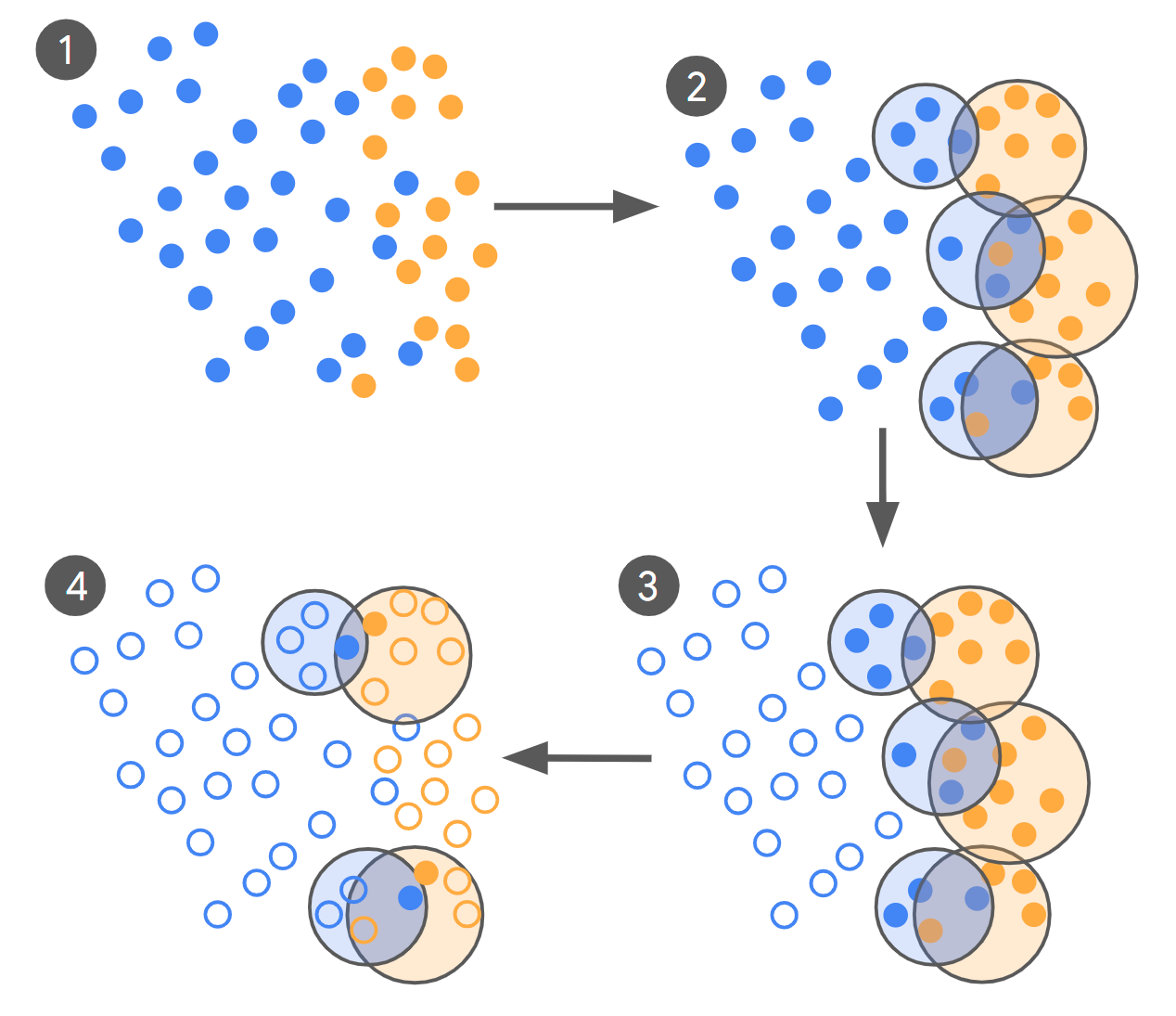
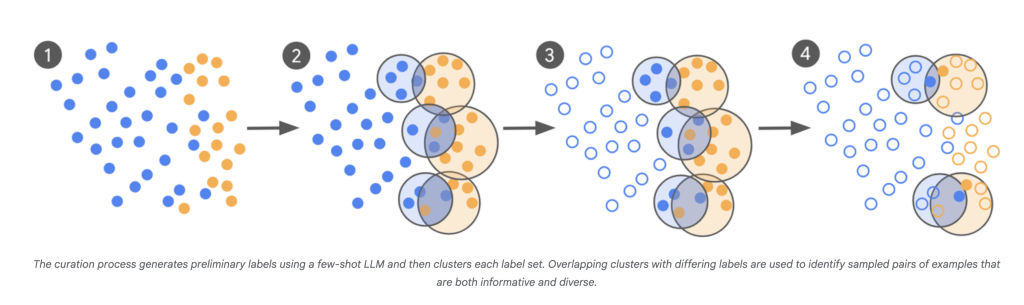
- LLM-as-Scout: Das LLM wird verwendet, um einen riesigen Korpus (Hunderte von Milliarden Beispielen) zu scannen und Fälle zu identifizieren, über die es am wenigsten sicher ist.
- Gezielte Expertenkennzeichnung: Anstatt Tausende von zufälligen Beispielen zu kennzeichnen, kommentieren menschliche Experten nur diese grenzüberschreitenden und verwirrenden Gegenstände.
- Iterative Kuration: Dieser Vorgang wiederholt sich, wobei jede Cost neuer „problematischer“ Beispiele, die durch die Verwirrungspunkte des neuesten Modells informiert sind.
- Schnelle Konvergenz: Die Modelle sind in mehreren Runden fein abgestimmt, und die Iteration wird fortgesetzt, bis sich die Ausgabe des Modells eng mit dem Expertenurteil übereinstimmt-von Cohens Kappa gemessen, das die Vereinbarung zwischen Annotatoren über den Zufall hinaus vergleicht.
Auswirkungen:
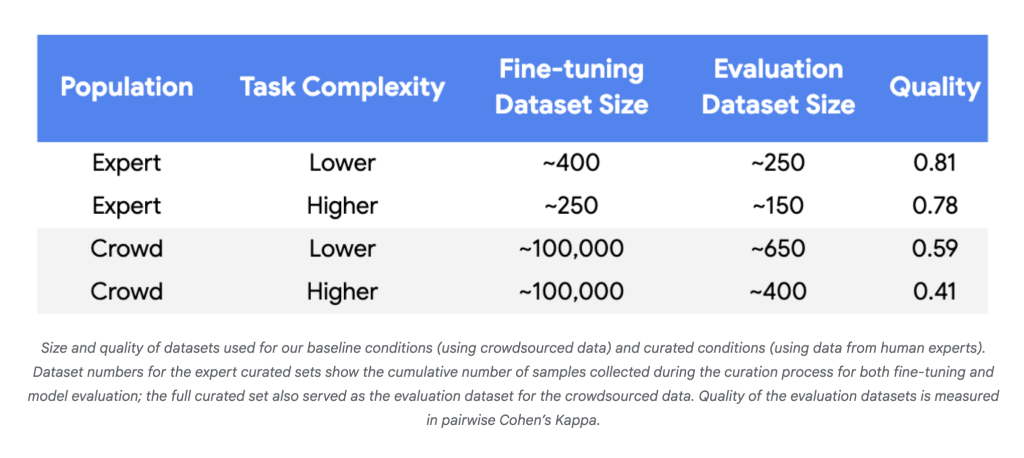
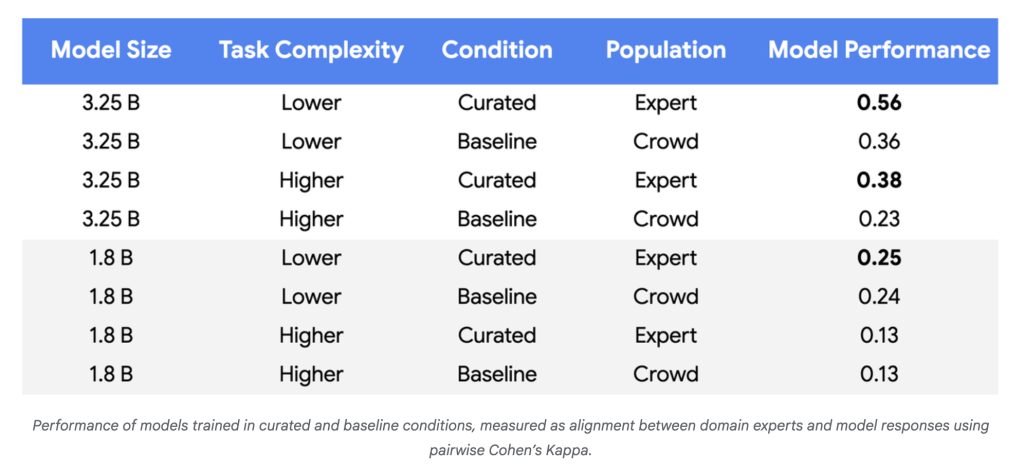
- Datenbedürfnisse sinken: In Experimenten mit Gemini-Nano-1- und Nano-2-Modellen erreichte die Ausrichtung auf menschliche Experten Parität oder bessere Verwendung 250–450 intestine ausgewählte Beispiele anstelle von ~ 100.000 zufälligen Crowdsourcing -Labels – eine Reduzierung von drei bis vier Größenordnungen.
- Modellqualität steigt: Für komplexere Aufgaben und größere Modelle erreichten die Leistungsverbesserungen 55–65% gegenüber dem Basislinie, was zu einer zuverlässigeren Ausrichtung zu politischen Experten zeigte.
- Etiketteneffizienz: Für zuverlässige Gewinne mit winzigen Datensätzen battle eine hohe Etikettenqualität durchweg erforderlich (Cohens Kappa> 0,8).
Warum ist es wichtig
Dieser Ansatz dreht das traditionelle Paradigma. Anstatt Modelle in riesigen Swimming pools von lauten, redundanten Daten zu ertrinken, nutzt es sowohl die Fähigkeit von LLMs, mehrdeutige Fälle zu identifizieren, als auch das Area -Experience menschlicher Annotatoren, bei denen ihre Enter am wertvollsten ist. Die Vorteile sind tiefgreifend:
- Kostensenkung: Weitaus weniger Beispiele zur Kennzeichnung, um die Arbeits- und Investitionsausgaben dramatisch zu senken.
- Schnellere Updates: Die Fähigkeit, Modelle an einer Handvoll Beispiele zu übertreffen, ermöglicht die Anpassung an neue Missbrauchsmuster, Richtlinienänderungen oder Verschiebungen von Domänen schnell und machbar.
- Gesellschaftliche Auswirkungen: Eine verbesserte Kapazität für kontextbezogenes und kulturelles Verständnis erhöht die Sicherheit und Zuverlässigkeit von automatisierten Systemen, die mit sensiblen Inhalten umgehen.
Zusammenfassend
Die neue Methodik von Google ermöglicht die Feinabstimmung von LLM in komplexen, sich entwickelnden Aufgaben mit nur Hunderten (nicht Hunderttausenden) zielgerichteter, hochgeschwindiger Bezeichnungen-die in weitaus schlankeren, agileren und kostengünstigeren Modellentwicklung geändert werden.

Michal Sutter ist ein Datenwissenschaftler bei einem Grasp of Science in Knowledge Science von der College of Padova. Mit einer soliden Grundlage für statistische Analyse, maschinelles Lernen und Datentechnik setzt Michal aus, um komplexe Datensätze in umsetzbare Erkenntnisse umzuwandeln.