
Suchmaschinen wie Google Pictures, Bing Visible Search und Pinterests Objektiv erscheinen sehr einfach, wenn wir ein paar Wörter eingeben oder ein Bild hochladen, und sofort kommen wir die relevantesten ähnlichen Bilder aus Milliarden von Möglichkeiten zurück.
Unter der Haube verwenden diese Systeme riesige Datenstapel und erweiterte Deep -Studying -Modelle, um sowohl Bilder als auch Textual content in numerische Vektoren (als Emboden) umzuwandeln, die im selben „semantischen Raum“ leben.
In diesem Artikel werden wir eine erstellen Mini -Model von dieser Artwork von Suchmaschine, aber mit einem viel kleineren Tierdatensatz mit Bildern von Tigern, Löwen, Elefanten, Zebras, Giraffen, Pandas und Pinguinen.
Sie können den gleichen Ansatz mit anderen Datensätzen wie folgen CocoAnwesend Nicht plash -Fotosoder sogar Ihre persönliche Bildsammlung.
Was wir bauen
Unsere Bildsuchmaschine wird:
- Verwenden Blip automatisch Bildunterschriften (Beschreibungen) für jedes Bild generieren.
- Verwenden Clip Um beide Bilder und Textual content in Einbettungen umzuwandeln.
- Speichern Sie diese Einbettungen in einem Vektordatenbank (Chromadb).
- Ermöglicht es Ihnen, vorbei zu suchen Textabfrage und die relevantesten Bilder abrufen.
Warum platzieren und klemmen?
Blip (Bootstrapping-Sprachbild-Vorabbildung)
Blip ist ein Deep -Studying -Modell, das Textbeschreibungen für Fotos erstellen kann (auch als Bildunterschrift bezeichnet). Wenn unser Datensatz noch keine Beschreibung hat, kann Blip eine erstellen, indem ein Bild wie einen Tiger betrachtet und so etwas wie „eine große orangefarbene Katze mit schwarzen Streifen, die auf Gras liegen“, produzieren.
Dies hilft besonders wo:
- Der Datensatz ist nur ein Ordner von Bildern ohne ihnen zugewiesene Etiketten.
- Und wenn Sie reichere, natürlichere generalisierte Beschreibungen für Ihre Bilder wollen.
Mehr lesen: Bildunterschrift mit Deep Studying
Clip (kontrastive Sprache-Picture vor der Ausbildung)
Clip von Openai lernt die Verbindung zu verbinden Textual content und Bilder Innerhalb eines gemeinsamen Vektorraums.
Es kann:
- Konvertieren Sie ein Bild in eine Einbettung.
- Textual content in eine Einbettung umwandeln.
- Vergleichen Sie die beiden direkt; Wenn sie sich in diesem Bereich eng neigen, bedeutet dies, dass sie semantisch übereinstimmen.
Beispiel:
- Textual content: „Ein großes Tier mit einem langen Hals“ → Vektor A
- Bild einer Giraffe → Vektor B
- Wenn Vektoren A Und B sind nah, sagt Clip, sagt, „Ja, das ist wahrscheinlich eine Giraffe.“

Schritt-für-Schritt-Implementierung
Wir werden alles im Inneren machen Google Colab, Sie brauchen additionally kein lokales Setup. Sie können über diesen Hyperlink auf das Notizbuch zugreifen: Einbettung_similarity_animals
1. Installieren Sie Abhängigkeiten
Wir werden Pytorch, Transformers (für Blip und Clip) und Chromadb (Vector -Datenbank) installieren. Dies sind die Hauptabhängigkeiten für unser Mini -Projekt.
!pip set up transformers torch -q
!pip set up chromadb -q2. Laden Sie den Datensatz herunter
Für diese Demo werden wir die verwenden Tierdatensatz von Kaggle.
import kagglehub
# Obtain the newest model
path = kagglehub.dataset_download("likhon148/animal-data")
print("Path to dataset recordsdata:", path)Wechseln Sie in die /Inhalt Verzeichnis in Colab:
!mv /root/.cache/kagglehub/datasets/likhon148/animal-data/variations/1 /content material/Überprüfen Sie, welche Klassen wir haben:
!ls -l /content material/1/animal_dataSie werden Ordner wie:
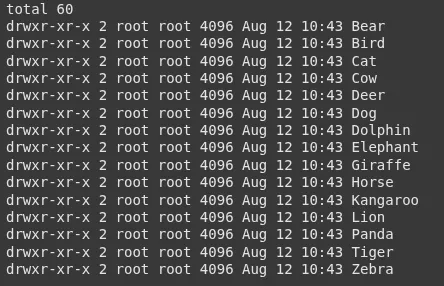
3.. Zählen Sie Bilder professional Klasse
Nur um eine Vorstellung von unserem Datensatz zu bekommen.
import os
base_path = "/content material/1/animal_data"
for folder in sorted(os.listdir(base_path)):
folder_path = os.path.be a part of(base_path, folder)
if os.path.isdir(folder_path):
rely = len((f for f in os.listdir(folder_path) if os.path.isfile(os.path.be a part of(folder_path, f))))
print(f"{folder}: {rely} pictures")Ausgabe:
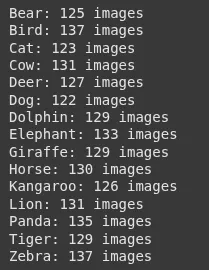
4. Lastklammermodell laden
Wir werden Clip für Einbettungen verwenden.
from transformers import CLIPProcessor, CLIPModel
import torch
model_id = "openai/clip-vit-base-patch32"
processor = CLIPProcessor.from_pretrained(model_id)
mannequin = CLIPModel.from_pretrained(model_id)
machine="cuda" if torch.cuda.is_available() else 'cpu'
mannequin.to(machine)5. Load -Blip -Modell für Bildunterschriften laden
Blip erzeugt eine Bildunterschrift für jedes Bild.
from transformers import BlipProcessor, BlipForConditionalGeneration
blip_model_id = "Salesforce/blip-image-captioning-base"
caption_processor = BlipProcessor.from_pretrained(blip_model_id)
caption_model = BlipForConditionalGeneration.from_pretrained(blip_model_id).to(machine)6. Bildwege vorbereiten
Wir werden alle Bildwege aus dem Datensatz sammeln.
image_paths = ()
for root, _, recordsdata in os.stroll(base_path):
for f in recordsdata:
if f.decrease().endswith((".jpg", ".jpeg", ".png", ".bmp", ".webp")):
image_paths.append(os.path.be a part of(root, f))7. Erzeugen Sie Beschreibungen und Einbettungen
Für jedes Bild:
- Blip generiert eine Beschreibung für dieses Bild.
- Clip Erzeugt ein Bild, das auf den Pixeln des Bildes basiert.
import pandas as pd
from PIL import Picture
information = ()
for img_path in image_paths:
picture = Picture.open(img_path).convert("RGB")
# BLIP: Generate caption
caption_inputs = caption_processor(picture, return_tensors="pt").to(machine)
with torch.no_grad():
out = caption_model.generate(**caption_inputs)
description = caption_processor.decode(out(0), skip_special_tokens=True)
# CLIP: Get picture embeddings
inputs = processor(pictures=picture, return_tensors="pt").to(machine)
with torch.no_grad():
image_features = mannequin.get_image_features(**inputs)
image_features = image_features.cpu().numpy().flatten().tolist()
information.append({
"image_path": img_path,
"image_description": description,
"image_embeddings": image_features
})
df = pd.DataFrame(information)8. In Chromadb speichern
Wir drücken unsere Einbettungen in eine Vektor -Datenbank.
import chromadb
consumer = chromadb.Consumer()
assortment = consumer.create_collection(identify="animal_images")
for i, row in df.iterrows():
assortment.add( # upserting to our chroma assortment
ids=(str(i)),
paperwork=(row("image_description")),
metadatas=({"image_path": row("image_path")}),
embeddings=(row("image_embeddings"))
)
print("✅ All pictures saved in Chroma")9. Erstellen Sie eine Suchfunktion
Bei einer Textabfrage:
- Clip kodiert es in eine Einbettung.
- Chromadb Findet die engsten Bildeinbettungen.
- Wir zeigen die Ergebnisse an.
import matplotlib.pyplot as plt
def search_images(question, top_k=5):
inputs = processor(textual content=(question), return_tensors="pt", truncation=True).to(machine)
with torch.no_grad():
text_embedding = mannequin.get_text_features(**inputs)
text_embedding = text_embedding.cpu().numpy().flatten().tolist()
outcomes = assortment.question(
query_embeddings=(text_embedding),
n_results=top_k
)
print("Prime outcomes for:", question)
for i, meta in enumerate(outcomes("metadatas")(0)):
img_path = meta("image_path")
print(f"{i+1}. {img_path} ({outcomes('paperwork')(0)(i)})")
img = Picture.open(img_path)
plt.imshow(img)
plt.axis("off")
plt.present()
return outcomes10. Testen Sie die Suchmaschine
Probieren Sie einige Fragen aus:
search_images("a big wild cat with stripes")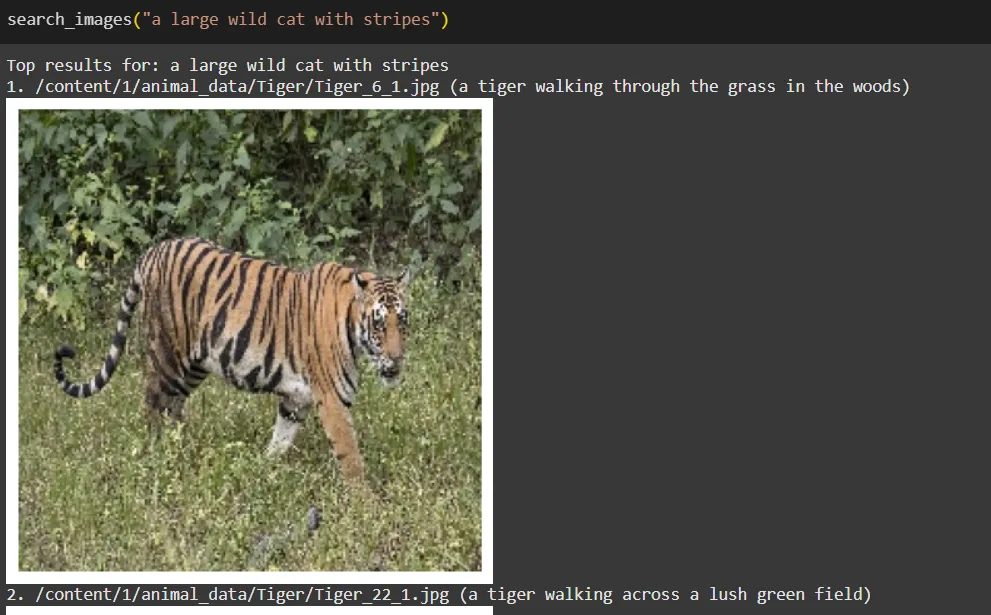
search_images("predator with a mane")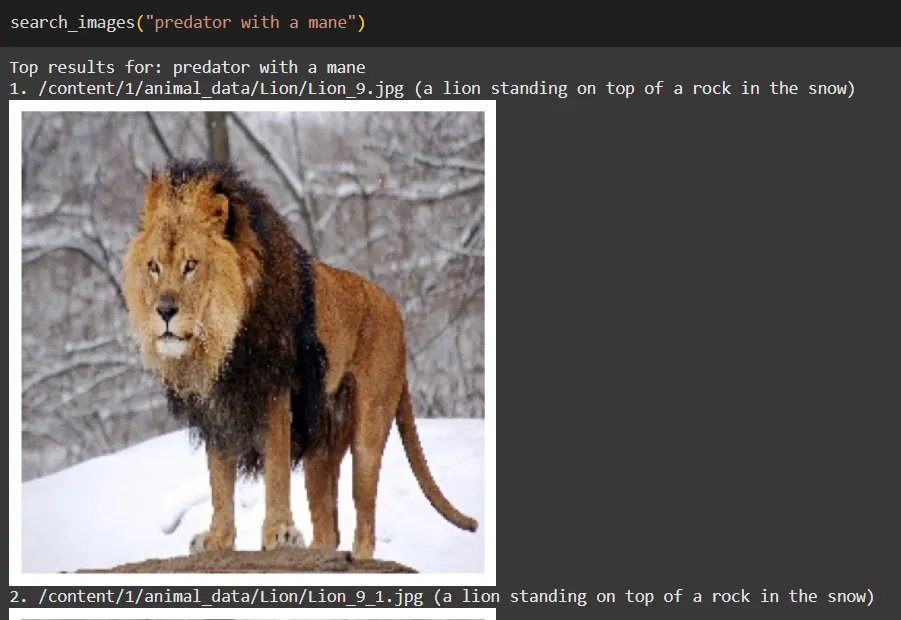
search_images("striped horse-like animal")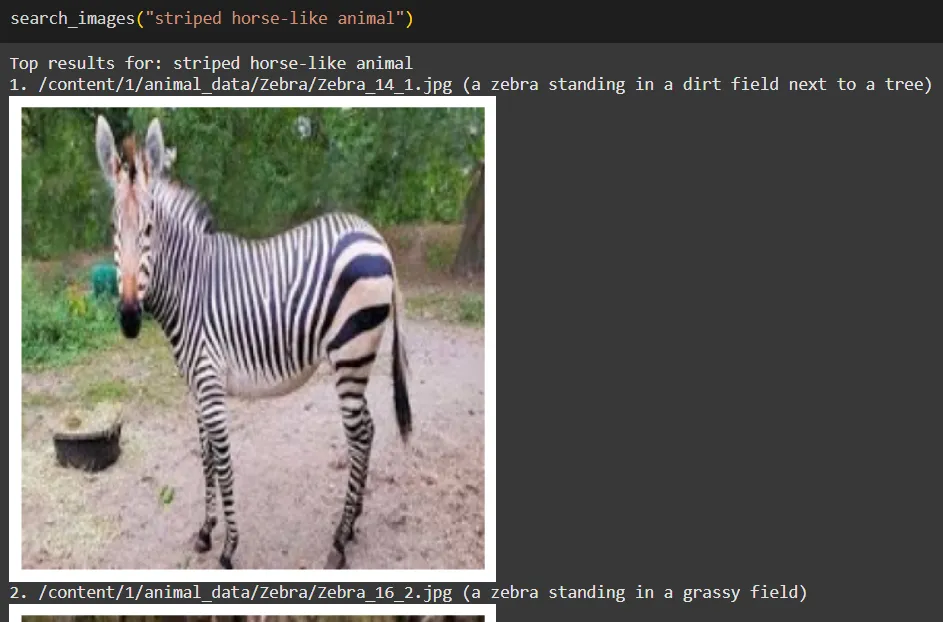
Wie es in einfachen Worten funktioniert
- Blip: Schaut jedes Bild an und schreibt eine Bildunterschrift (dies wird unser „Textual content“ für das Bild).
- Clip: Wandelt sowohl Untertitel als auch Bilder in Einbettungen im selben Raum.
- Chromadb: Speichert diese Einbettungen und findet bei der Suche das engste Übereinstimmung.
- Suchfunktion (Retriever): Verwandelt Ihre Anfrage in eine Einbettung und fragt Chromadb: „Welche Bilder sind dieser Abfrage am nächsten?“
Denken Sie daran, dass diese Suchmaschine effektiver wäre, wenn wir einen viel größeren Datensatz hätten und wenn wir eine bessere Beschreibung für jedes Bild verwenden würden, würden in unserem einheitlichen Repräsentationsraum viel effektive Einbettungen führen.
Einschränkungen
- Blip -Bildunterschriften können für einige Bilder generisch sein.
- Die Einbettungen von Clip eignen sich intestine für allgemeine Konzepte, könnten jedoch mit sehr domänenspezifischen oder feinkörnigen Unterschieden zu kämpfen, es sei denn, es wird auf ähnliche Daten geschult.
- Die Suchqualität hängt stark von der Größe und Vielfalt der Datensätze ab.
Abschluss
Zusammenfassend lässt sich sagen, dass das Erstellen einer Miniaturbild -Suchmaschine unter Verwendung von Vektordarstellungen von Textual content und Bildern aufregende Möglichkeiten zur Verbesserung des Picture -Abrufs bietet. Durch Nutzung Blip Für Bildunterschriften und Clips zum Einbetten können wir ein vielseitiges Device erstellen, das sich an verschiedene Datensätze anpasst, von persönlichen Fotos bis hin zu speziellen Sammlungen.
Mit Blick auf die Zukunft können Funktionen wie Picture-to-Picture-Suche die Benutzererfahrung weiter bereichern und eine einfache Entdeckung visuell ähnlicher Bilder ermöglichen. Zusätzlich einsetzen, dass größer wird Clip Modelle und Feinabstimmung in bestimmten Datensätzen können die Suchgenauigkeit erheblich verbessern.
Dieses Projekt dient nicht nur als solide Grundlage für die KI-gesteuerte Bildsuche, sondern lädt auch zu weiteren Erkundungen und Innovationen ein. Nehmen Sie das Potenzial dieser Technologie ein und verändern Sie die Artwork und Weise, wie wir uns mit Bildern beschäftigen.
Häufig gestellte Fragen
A. BLIP generiert Bildunterschriften für Bilder und erstellt Textbeschreibungen, die eingebettet und mit Suchanfragen verglichen werden können. Dies ist nützlich, wenn der Datensatz noch keine Etiketten enthält.
A. Clip wandelt sowohl Bilder als auch Textual content in Einbettungen innerhalb desselben Vektorraums um und ermöglicht den direkten Vergleich zwischen ihnen semantische Übereinstimmungen.
A. Chromadb speichert die Einbettungen und ruft die relevantesten Bilder ab, indem sie die engsten Übereinstimmungen der Einbettung einer Suchanfrage finden.
Genai Praktikant @ Analytics Vidhya | Letzte Jahr @ Vit Chennai
Leidenschaftlich für KI und maschinelles Lernen, ich bin bestrebt, als KI/ML -Ingenieur oder Datenwissenschaftler in Rollen einzutauchen, wo ich einen echten Einfluss haben kann. Ich freue mich sehr, progressive Lösungen und hochmoderne Fortschritte auf den Tisch zu bringen. Meine Neugier treibt mich an, KI über verschiedene Bereiche hinweg zu erkunden und die Initiative zu ergreifen, um sich mit Information Engineering zu befassen, um sicherzustellen, dass ich vorne bleibe und wirksame Projekte liefere.
Melden Sie sich an, um weiter zu lesen und Experten-Kuratinhalte zu genießen.