
Möglicherweise haben Sie in irgendeiner Weise mit ChatGPT interagiert. Egal, ob Sie um Hilfe gebeten haben, um ein bestimmtes Konzept zu unterrichten, oder um einen detaillierten geführten Schritt, um ein komplexes Drawback zu lösen.
Dazwischen müssen Sie eine „Eingabeaufforderung“ (kurz oder lang) bereitstellen, um mit dem LLM zu kommunizieren, um die gewünschte Antwort zu erstellen. Die wahre Essenz dieser Modelle liegt jedoch nicht nur in ihrer Architektur, sondern auch in der intelligenten Kommunikation mit ihnen.
Hier beginnen schnelle technische Techniken. Lesen Sie diesen Weblog fort, um zu erfahren, was immediate Engineering ist, seine Techniken, Schlüsselkomponenten und einen praktischen Leitfaden zum Erstellen eines LLM mit promptem Engineering.
Was ist schnelle Engineering?
Lassen Sie uns den Begriff aufschlüsseln. Der „immediate“ Bezieht sich auf einen Textual content oder Satz, der LLM als NLP aufnimmt und die Ausgabe erzeugt. Die Antwort könnte rekursiv, iterativ oder unvollständig sein.
Daher, Schnelltechnik kommt ins Bild. Es bezieht sich auf das Erstellen und Optimieren von Aufforderungen, um eine iterative Antwort zu erzeugen. Diese Antworten erfüllen das Drawback oder erzeugen Ausgabe basierend auf dem gewünschten objektiven, daher steuerbaren Ausgangserzeugungserzeugnis.
Mit promptem Engineering drücken Sie eine Llm in eine endgültige Richtung mit einer verbesserten Aufforderung, eine effektive Antwort zu erzeugen.
Lassen Sie uns mit einem Beispiel verstehen.
Auffordert Engineering -Beispiel
Stellen Sie sich als Tech -Nachrichtenschreiber vor. Zu Ihren Aufgaben gehören die Erforschung, Herstellung und Optimierung von Tech -Artikeln mit Schwerpunkt auf Rating in Suchmaschinen.
Additionally, was ist eine grundlegende Aufforderung, die Sie einem LLM geben würden? Es könnte so sein:
“Entwerfen Sie einen Search engine optimisation-ausgerichteten Weblog-Beitrag zu diesem „Titel“ mit einigen FAQs.“
Es könnte einen Weblog -Beitrag über den angegebenen Titel mit FAQs generieren, aber es fehlt ihnen die Absicht des Lesers und die Inhaltstiefe.
Mit promptem Engineering können Sie diese State of affairs effektiv angehen. Im Folgenden finden Sie ein Beispiel für ein promptes Engineering -Skript:
Immediate: „Sie sind ein erfahrener Search engine optimisation -Content material -Editor. Ihre Aufgabe ist es, einen vollständig strukturierten, seooptimierten Weblog-Beitrag aus einem bestimmten Titel zu generieren.
Titel: „Subject hier erwähnen“
Anweisungen:
– Schreiben Sie einen Weblog -Beitrag von mehr als 1500 Wörtern mit Search engine optimisation -Finest Practices.
– Geben Sie Meta -Titel, Meta -Beschreibung, Einführung, strukturierte Überschriften (H2/H3), Schlussfolgerung und FAQs ein.
-Verwenden Sie ein klares, ansprechendes, faktenbasiertes Schreiben.
– Natürlich optimieren Sie für Search engine optimisation ohne Key phrase -Füllung.“
Der Unterschied zwischen diesen beiden Eingabeaufforderungen ist die iterative Antwort. Die erste Eingabeaufforderung kann nicht einen eingehenden Artikel, eine Schlüsselwortoptimierung, strukturierte Klarheitsinhalte usw. generieren, während die zweite Eingabeaufforderung clever alle Ziele erfüllt.
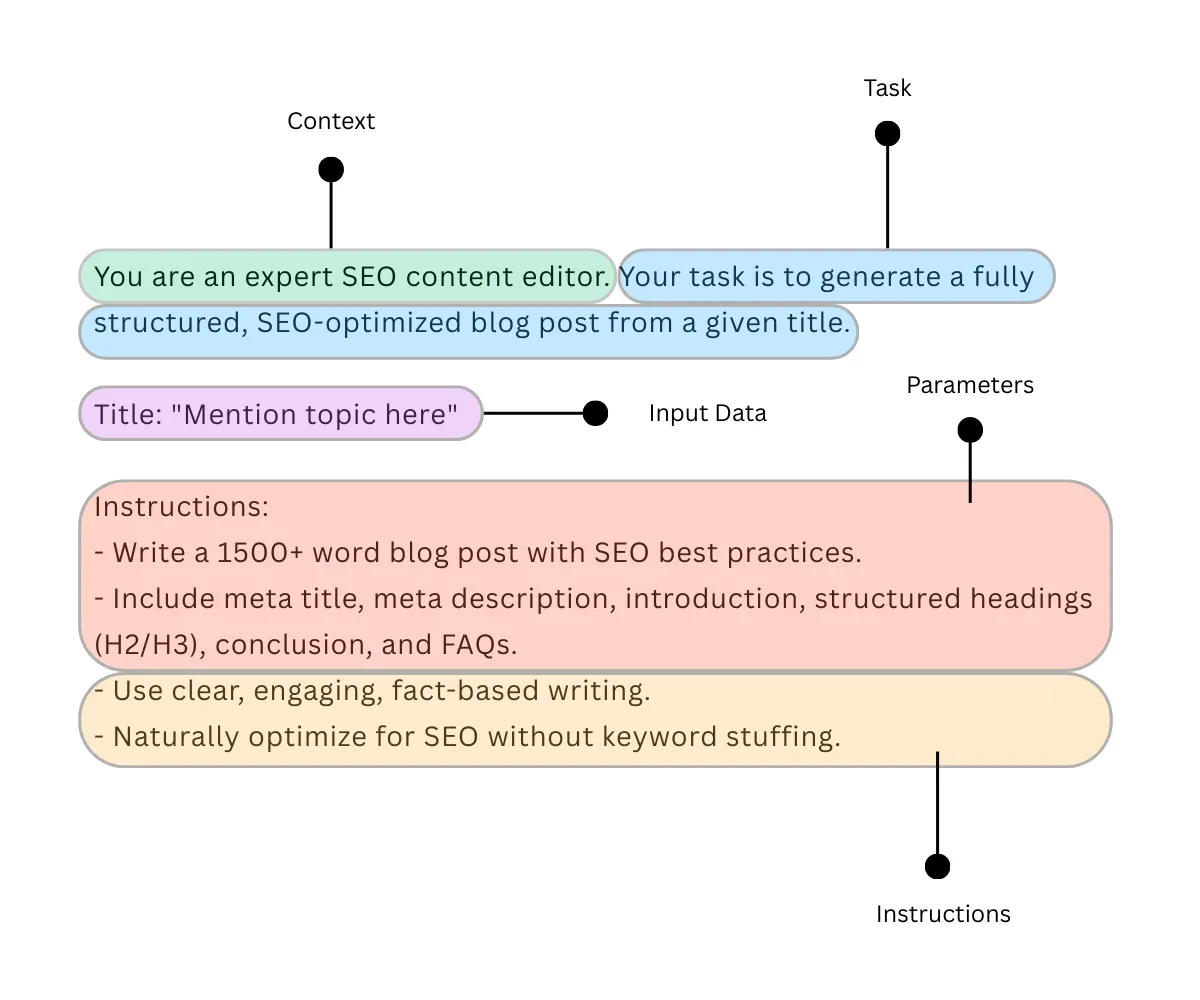
Komponenten der schnellen Technik
Möglicherweise haben Sie zuvor wichtige Dinge beobachtet. Bei der Optimierung für die Eingabeaufforderung definieren wir die Aufgabe, geben Anweisungen, Fügen Sie Kontext und Parameter hinzu, um einem LLM einen Ansatz für die Ausgabegenerierung zu verleihen.
Kritische Komponenten der schnellen Technik sind wie folgt:
- Aufgabe: In einem Anweisungsformular, den ein Benutzer speziell definiert.
- Anweisung: Geben Sie die erforderlichen Informationen an, um eine auf sinnvolle Aufgabe zu erledigen.
- Kontext: Hinzufügen einer zusätzlichen Informationsebene, die von LLM anerkannt wird, um eine relevantere Antwort zu generieren.
- Parameter: Regeln, Formate oder Einschränkungen für die Antwort auferlegen.
- Eingabedaten: Geben Sie den Textual content, das Bild oder die andere Datenklasse zur Verarbeitung an.
Die Ausgabe, die von einem LLM aus einem schnitten Engineering -Skript erzeugt wird, kann durch verschiedene Techniken weiter optimiert werden. Es gibt zwei Klassifikationen von schnellen technischen Techniken: Grundlegende und fortgeschrittene.
Im Second diskutieren wir nur grundlegende schnelle technische Techniken für Anfänger.
Schnelle technische Techniken für Anfänger
Ich habe sieben schnelle technische Techniken in einer tabellarischen Struktur mit Beispielen erklärt.
| Techniken | Erläuterung | Aufforderungsbeispiel |
|---|---|---|
| Null-Shot-Aufforderung | Erzeugen Sie die Ausgabe durch LLM ohne Beispiele. | Übersetzen Sie Folgendes von Englisch nach Hindi. „Das Match von morgen wird unglaublich sein.“ |
| Wenige Schüsse Aufforderung | Erzeugen Sie die Ausgabe durch ein LLM durch Lernen aus wenigen Beispielen für die Aufnahme. | Übersetzen Sie Folgendes von Englisch nach Hindi. „Das Match von morgen wird unglaublich sein.“ Zum Beispiel: Hallo → नमस्ते Alles intestine → सब अच्छा Toller Rat → बढ़िया सलाह |
| One-Shot-Aufforderung | Erzeugen Sie die Ausgabe durch ein LLM-Lernen aus einer Referenz mit einem Beispiel. | Übersetzen Sie Folgendes von Englisch in Hindi. „Das morgen wird erstaunlich sein.“ Zum Beispiel: Hallo → नमस्ते |
| Kette der Gedanken (COT) Aufforderung | Leiten Sie LLM, um die Argumentation in Schritte zur Verbesserung der komplexen Aufgabenleistung aufzuteilen. | Lösen: 12 + 3 * (4 – 2). Berechnen Sie zuerst 4 – 2. 2. Multiplizieren Sie das Ergebnis mit 3. Schließlich 12. |
| Denkmal (TOT) Aufforderung | Strukturieren des Denkprozesses des Modells als Baum, um das Verarbeitungsverhalten zu kennen. | Stellen Sie sich vor, drei Ökonomen, die versuchen, die Frage zu beantworten: Was wird morgen der Treibstoffpreis sein? Jeder Wirtschaftswissenschaftler schreibt jeweils einen Schritt seiner Argumentation auf und geht dann zum nächsten. Wenn zu jeder Part eins erkennt, dass ihre Argumentation fehlerhaft ist, verlassen sie den Prozess. |
| Meta -Aufforderung | Leiten Sie ein Modell, um eine Aufforderung zur Ausführung verschiedener Aufgaben zu erstellen. | Schreiben Sie eine Eingabeaufforderung, die dazu beiträgt, eine Zusammenfassung eines beliebigen Nachrichtenartikels zu generieren. |
| Reflexion | Aufforderung, das Modell anzuweisen, vergangene Antworten zu prüfen und in Zukunft die Antworten zu verbessern. | Denken Sie über die Fehler nach, die in der vorherigen Erklärung gemacht wurden, und verbessern Sie den nächsten. |
Jetzt, da Sie schnelle technische Techniken gelernt haben, lassen Sie uns üben Aufbau einer LLM -Anwendung.
Bauen von LLM -Anwendungen mit einem schnellen Engineering
Ich habe demonstriert, wie man eine benutzerdefinierte LLM -Anwendung unter Verwendung eines forcorter Engineering erstellt. Es gibt verschiedene Möglichkeiten, dies zu erreichen. Aber ich habe den Prozess einfach und anfängerfreundlich gehalten.
Voraussetzungen:
- Ein Betriebssystem mit mindestens 8 GB VRAM
- Herunterladen Python 3.13 auf Ihrem System
- Herunterladen und installieren Ollama
Objektiv: Erstellen von „Search engine optimisation Weblog Generator LLM“, bei dem das Modell einen Titel nimmt und einen Search engine optimisation-optimierten Weblog-Entwurf erzeugt.
Schritt 1 – Installieren des Lama 3: 8B -Modells
Nachdem Sie bestätigt haben, dass Sie die Voraussetzungen erfüllt haben, gehen Sie zur Befehlszeilenschnittstelle und installieren Sie die LAMA3 8B Modell, wie dies unser grundlegendes Modell für die Kommunikation ist.
ollama run llama3:8b
Die Größe des LLM beträgt ungefähr 4,3 GigabyteDas Herunterladen kann additionally ein paar Minuten dauern. Nach dem Abschluss des Downloads sehen Sie eine Erfolgsnachricht.
Schritt 2 – Vorbereitung unserer Projektdateien
Wir benötigen eine Kombination von Dateien für die Kommunikation mit dem LLM. Es enthält a Python Skript und einige Anforderungen Dateien.
Erstellen Sie einen Ordner und nennen Sie ihn “Search engine optimisation-BLOG-LLMUnd erstellen a Anforderungen.txt Datei mit Folgendes und speichern.
ollama>=0.3.0
python-slugify>=8.0.4Gehen Sie nun zur Befehlszeilenschnittstelle und führen Sie den folgenden Befehl aus.
pip set up -r necessities.txt
Schritt 3 – Erstellen Sie die Eingabeaufforderungdatei
Speichern Sie in Chic Editor oder einem codesbasierten Editor die folgende Codelogik mit dem Dateinamen forderts.py. Diese Logik führt die LLM in der Reaktion und Erzeugung von Ausgaben. Hier strahlt schnelle Engineering.
SYSTEM_PROMPT = """You're an knowledgeable Search engine optimisation content material editor. You write fact-aware, reader-first articles that rank.
Comply with these guidelines strictly:
- Output ONLY Markdown for the ultimate article; no explanations or preambles.
- Embody on the high a YAML entrance matter block with: meta_title, meta_description, slug, primary_keyword, secondary_keywords, word_count_target.
- Hold meta_title ≤ 60 chars; meta_description ≤ 160 chars.
- Use H2/H3 construction, quick paragraphs, bullets, and numbered lists the place helpful.
- Hold key phrase utilization pure (no stuffing).
- Finish with a conclusion and a 4–6 query FAQ.
- For those who insert any statistic or declare, mark it with (quotation wanted) (because you’re offline).
"""
USER_TEMPLATE = """Title: "{title}"
Write a {word_count}-word Search engine optimisation weblog for the above title.
Constraints:
- Audience: {viewers}
- Tone: easy, informative, participating (as if explaining to a 20-year-old)
- Geography: {geo}
- Major key phrase: {primary_kw}
- 5–8 secondary key phrases: {secondary_kws}
Format:
1) YAML entrance matter with: meta_title, meta_description, slug, primary_keyword, secondary_keywords, word_count_target
2) Intro (50–120 phrases)
3) Physique with clear H2/H3s together with the first key phrase naturally in a minimum of one H2
4) Sensible ideas, checklists, and examples
5) Conclusion
6) FAQ (4–6 Q&As)
Guidelines:
- Don't embody “Define” or “Draft” sections.
- Don't present your reasoning or chain-of-thought.
- Hold meta fields inside limits. If wanted, shorten.
"""Schritt 4 – Einrichten des Python -Skripts
Dies ist unsere Stammdatei, die als Mini -Anwendung für die Kommunikation mit dem LLM fungiert. Speichern Sie in Chic Editor oder einem codesbasierten Editor die folgende Codelogik mit dem Dateinamen Generator.py.
import re
import os
from datetime import datetime
from slugify import slugify
import ollama # pip set up ollama
from prompts import SYSTEM_PROMPT, USER_TEMPLATE
MODEL_NAME = "llama3:8b" # regulate if you happen to pulled a special tag
OUT_DIR = "output"
os.makedirs(OUT_DIR, exist_ok=True)
def build_user_prompt(
title: str,
word_count: int = 1500,
viewers: str = "newbie bloggers and content material entrepreneurs",
geo: str = "international",
primary_kw: str = None,
secondary_kws: record(str) = None,
):
if primary_kw is None:
primary_kw = title.decrease()
if secondary_kws is None:
secondary_kws = ()
secondary_str = ", ".be part of(secondary_kws) if secondary_kws else "n/a"
return USER_TEMPLATE.format(
title=title,
word_count=word_count,
viewers=viewers,
geo=geo,
primary_kw=primary_kw,
secondary_kws=secondary_str
)
def call_llm(system_prompt: str, user_prompt: str, temperature=0.4, num_ctx=8192):
# Chat-style name for higher instruction-following
resp = ollama.chat(
mannequin=MODEL_NAME,
messages=(
{"function": "system", "content material": system_prompt},
{"function": "consumer", "content material": user_prompt},
),
choices={
"temperature": temperature,
"num_ctx": num_ctx,
"top_p": 0.9,
"repeat_penalty": 1.1,
},
stream=False,
)
return resp("message")("content material")
def validate_front_matter(md: str):
"""
Fundamental YAML entrance matter extraction and checks for meta size.
"""
fm = re.search(r"^---s*(.*?)s*---", md, re.DOTALL | re.MULTILINE)
points = ()
meta = {}
if not fm:
points.append("Lacking YAML entrance matter block ('---').")
return meta, points
block = fm.group(1)
# naive parse (maintain easy for no dependencies)
for line in block.splitlines():
if ":" in line:
okay, v = line.cut up(":", 1)
meta(okay.strip()) = v.strip().strip('"').strip("'")
# checks
mt = meta.get("meta_title", "")
mdsc = meta.get("meta_description", "")
if len(mt) > 60:
points.append(f"meta_title too lengthy ({len(mt)} chars).")
if len(mdsc) > 160:
points.append(f"meta_description too lengthy ({len(mdsc)} chars).")
if "slug" not in meta or not meta("slug"):
# fall again to title-based slug if wanted
title_match = re.search(r'Title:s*"((^")+)"', md)
fallback = slugify(title_match.group(1)) if title_match else f"post-{datetime.now().strftime('%YpercentmpercentdpercentHpercentM')}"
meta("slug") = fallback
points.append("Lacking slug; auto-generated.")
return meta, points
def ensure_headers(md: str):
if "## " not in md:
return ("No H2 headers discovered.")
return ()
def save_article(md: str, slug: str | None = None):
if not slug:
slug = slugify("article-" + datetime.now().strftime("%YpercentmpercentdpercentHpercentMpercentS"))
path = os.path.be part of(OUT_DIR, f"{slug}.md")
with open(path, "w", encoding="utf-8") as f:
f.write(md)
return path
def generate_blog(
title: str,
word_count: int = 1500,
viewers: str = "newbie bloggers and content material entrepreneurs",
geo: str = "international",
primary_kw: str | None = None,
secondary_kws: record(str) | None = None,
):
user_prompt = build_user_prompt(
title=title,
word_count=word_count,
viewers=viewers,
geo=geo,
primary_kw=primary_kw,
secondary_kws=secondary_kws or (),
)
md = call_llm(SYSTEM_PROMPT, user_prompt)
meta, fm_issues = validate_front_matter(md)
hdr_issues = ensure_headers(md)
points = fm_issues + hdr_issues
path = save_article(md, meta.get("slug"))
return {
"path": path,
"meta": meta,
"points": points
}
if __name__ == "__main__":
parser = argparse.ArgumentParser(description="Generate Search engine optimisation weblog from title")
parser.add_argument("--title", required=True, assist="Weblog title")
parser.add_argument("--words", kind=int, default=1500, assist="Goal phrase depend")
args = parser.parse_args()
end result = generate_blog(
title=args.title,
word_count=args.phrases,
primary_kw=args.title.decrease(), # easy default key phrase
secondary_kws=(),
)
print("Saved:", end result("path"))
if end result("points"):
print("Validation notes:")
for i in end result("points"):
print("-", i)Nur um sicherzustellen, dass Sie es richtig machen. Ihr Projektordner sollte die folgenden Dateien haben. Beachten Sie, dass der Ausgangsordner und der _pycache_ Der Ordner wird explizit erstellt.
Schritt 5 – Führen Sie es aus
Sie sind quick fertig. Führen Sie in der Befehlszeilenschnittstelle den folgenden Befehl aus, um die Ausgabe zu erhalten. Eine Ausgabe wird automatisch im Ausgangsordner Ihrer Projektquelle in der (.md) -Formatdatei gespeichert.
python generator.py --title "Luxurious Inside Design Concepts for Villas & Resorts" --words 1800Und Sie würden so etwas in der Befehlszeile sehen:

So öffnen Sie die Datei für generierte Ausgabemarkdown (.MD). Verwenden Sie entweder VS-Code oder Drag-and-Drop in einen beliebigen Browser. Hier habe ich den Chrome -Browser verwendet, um die Datei zu öffnen, und die Ausgabe sieht akzeptabel aus:
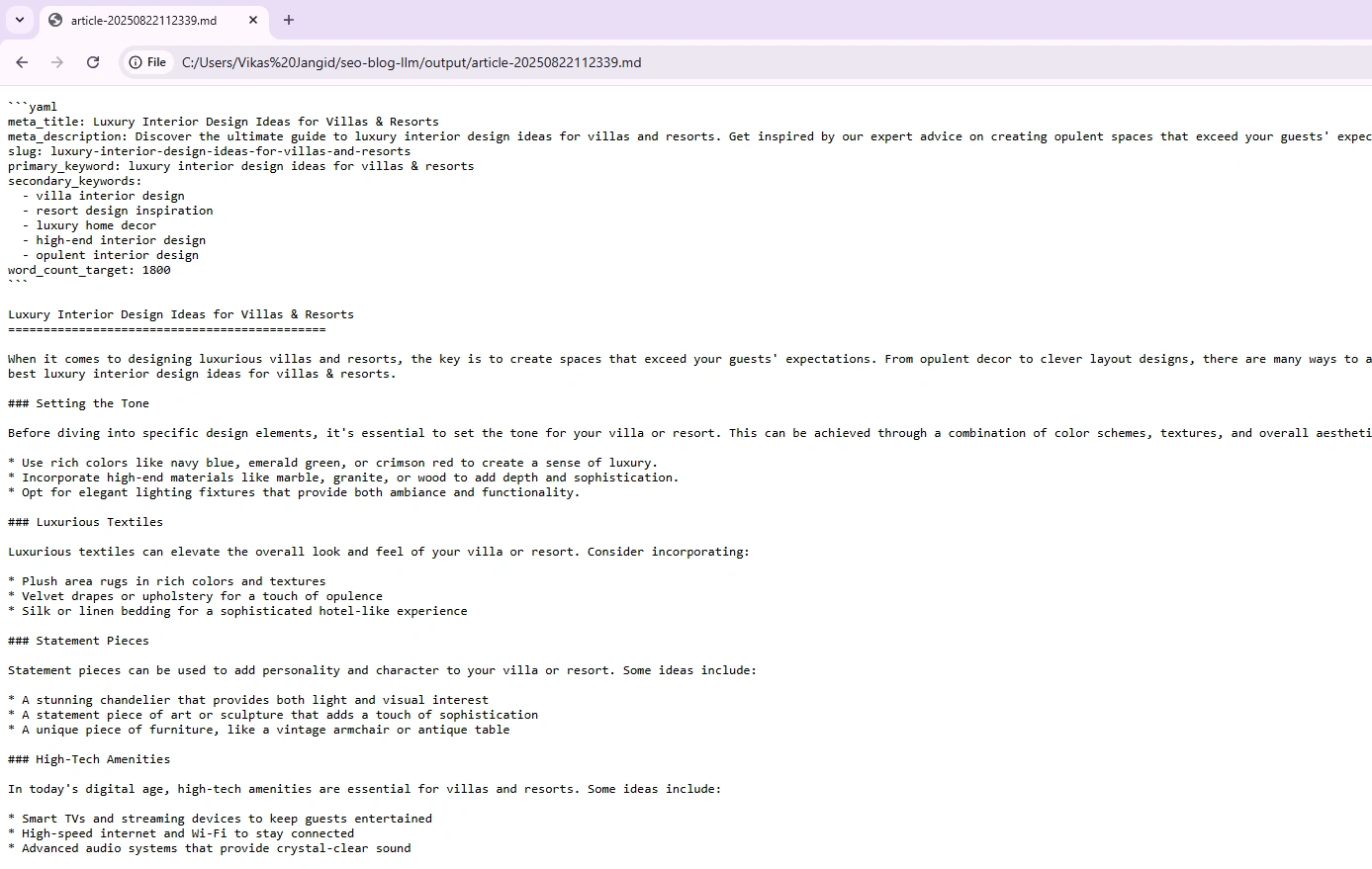
Dinge zu beachten
Hier sind einige Dinge, die Sie bei der Verwendung des obigen Codes beachten sollten:
- Das Ausführen des Setups mit nur 8 GB RAM führte zu langsamen Antworten. Für eine glattere Erfahrung empfehle ich 12 bis 16 GB RAM, wenn Sie Lama 3 lokal ausführen.
- Das Modell LLAMA3: 8B gab oft weniger zurück als die angeforderten Wörter. Die erzeugte Ausgabe beträgt weniger als 800 Wörter.
- Fügen Sie Passingparameter hinzu wie
geoAnwesendtoneUndtarget marketim Befehl run, um eine angegebene Ausgabe zu generieren.
Schlüssel zum Mitnehmen
Sie haben gerade eine benutzerdefinierte LLM-Anwendung auf Ihrem eigenen Pc erstellt. Wir haben das Uncooked Lama 3 verwendet und sein Verhalten mit promptem Engineering geprägt.
Hier ist eine kurze Zusammenfassung:
- Installierte Ollama, mit der Sie Lama 3 lokal laufen können.
- Ziehen Sie das Lama 3 8b -Modell, damit Sie sich nicht auf externe APIs verlassen.
- Schrieb immediate.py Das definiert, wie das Modell angewiesen wird.
- Schrieb Generator.py Das fungiert als Ihre Mini -App.
Letztendlich haben Sie mit seinen Techniken und praktischen Praxis, die eine LLM-Anträge entwickelt, ein schnelles Engineering-Konzept gelernt.
Mehr lesen:
Häufig gestellte Fragen
A. LLMs können keine expliziten Ausgabe generieren und erfordern daher eine Aufforderung, die sie leitet, um zu verstehen, welche Aufgabe oder Informationen erstellt werden sollen.
A. Socond Engineering weist LLM an, sich logisch und effektiv zu verhalten, bevor er die Ausgabe erzeugt. Es bedeutet, bestimmte und intestine definierte Anweisungen zu erstellen, um das LLM bei der Erzeugung der gewünschten Ausgabe zu leiten.
A. Die vier Säulen der schnellen Technik sind Einfachheit (klar und einfach), Spezifität (prägnant und spezifisch), Struktur (logisches Format) und Empfindlichkeit (truthful und unvoreingenommen).
A. Ja, sofortige Ingenieurwesen sind eine Fähigkeit und in Mode. Es erfordert ein gründliches Denken, effektive Aufforderungen zu erstellen, die die LLMs zu den gewünschten Ergebnissen führen.
A. Schnellingenieure sind qualifizierte Fachleute, um die Eingaben zu verstehen (Eingabeaufforderungen) und exzellent bei der Erstellung zuverlässiger und robuster Aufforderungen, insbesondere für große Sprachmodelle, ihre Leistung zu optimieren und sicherzustellen, dass sie hoch genaue und kreative Ausgaben erzeugen.
Ich bin Bharat Kumar, ein Content material -Editor bei der nächsten Technologie mit mehr als 3 Jahren Erfahrung in der Schreiben und Bearbeitung von Technologieinhalten. Derzeit erforscht die Erkundung generativer KI (Genai) durch Analytics Vidhya und das Teilen meiner Erkenntnisse, indem er einnehmende, geschichtsgetriebene Artikel über künstliche Intelligenz, Generativmotoren und maschinelles Lernen schreibt.
Melden Sie sich an, um weiter zu lesen und Experten-Kuratinhalte zu genießen.