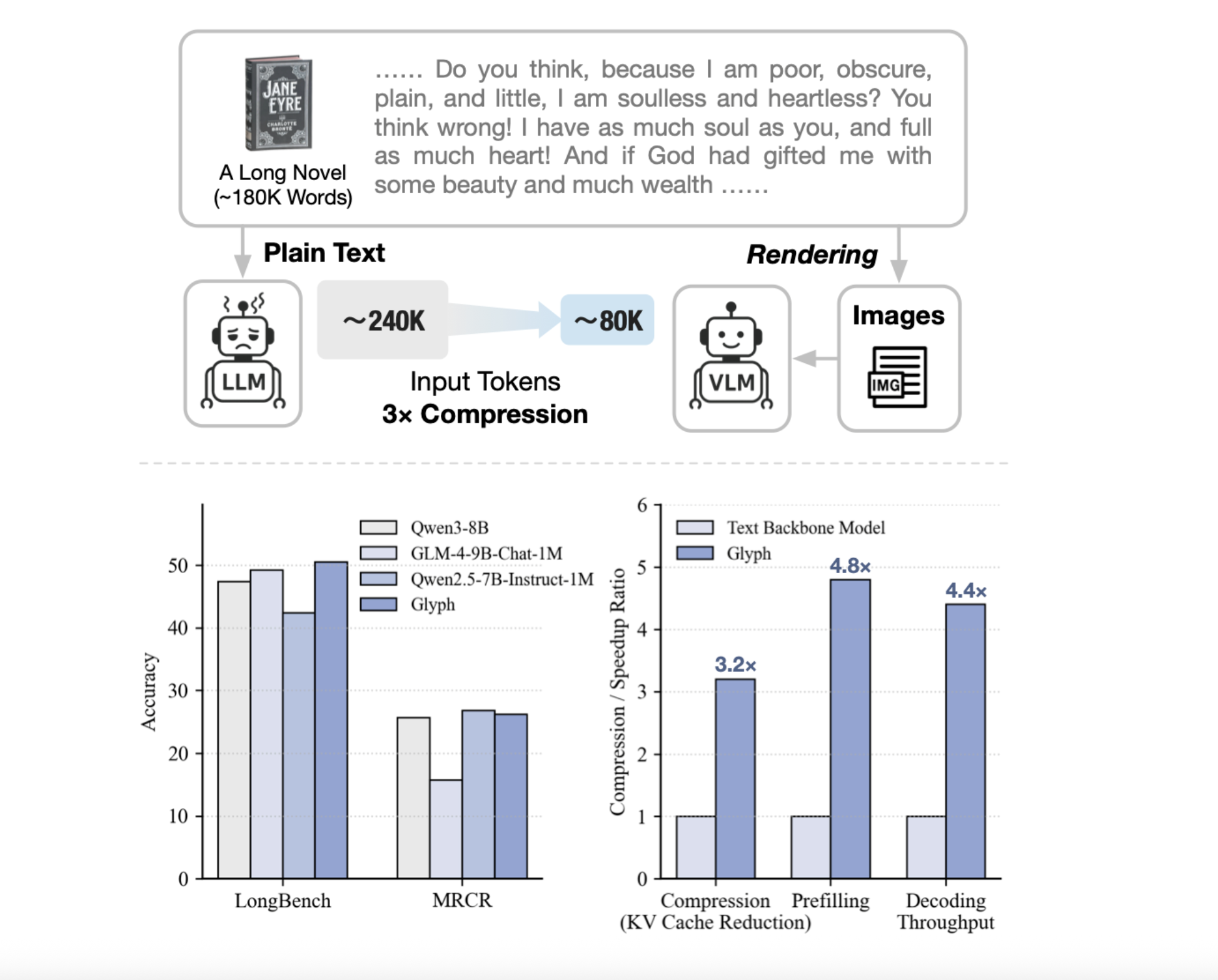
Können wir lange Texte als Bilder rendern und einen VLM verwenden, um eine 3–4-fache Token-Komprimierung zu erreichen und dabei die Genauigkeit beizubehalten und gleichzeitig einen 128-KB-Kontext für 1-M-Token-Workloads zu skalieren? Ein Forscherteam aus Zhipu AI-Veröffentlichung Glypheein KI-Framework zur Skalierung der Kontextlänge durch visuelle Textkomprimierung. Es rendert lange Textsequenzen in Bilder und verarbeitet sie mithilfe von Imaginative and prescient-Sprachmodellen. Das System rendert ultralangen Textual content in Seitenbilder, dann verarbeitet ein Imaginative and prescient-Language-Modell, VLM, diese Seiten durchgängig. Jedes visuelle Token kodiert viele Zeichen, sodass die effektive Token-Sequenz kürzer wird, während die Semantik erhalten bleibt. Glyph kann eine 3- bis 4-fache Token-Komprimierung bei langen Textsequenzen ohne Leistungseinbußen erreichen, was erhebliche Verbesserungen bei der Speichereffizienz, dem Trainingsdurchsatz und der Inferenzgeschwindigkeit ermöglicht.
Warum Glyphe?
Herkömmliche Methoden erweitern Positionskodierungen oder modifizieren Aufmerksamkeit, Rechenleistung und Speicher skalieren weiterhin mit der Tokenanzahl. Beim Abrufen werden Eingaben gekürzt, es besteht jedoch das Risiko, dass Beweise fehlen, und die Latenz erhöht sich. Glyph ändert die Darstellung, wandelt Textual content in Bilder um und verlagert die Final auf einen VLM, der bereits OCR, Format und Argumentation lernt. Dadurch wird die Informationsdichte professional Token erhöht, sodass ein festes Token-Finances mehr ursprünglichen Kontext abdeckt. Unter extremer Komprimierung zeigt das Forschungsteam, dass ein 128-KByte-Kontext-VLM Aufgaben bewältigen kann, die aus Textual content auf 1-Millionen-Token-Ebene stammen.
Systemdesign und Schulung
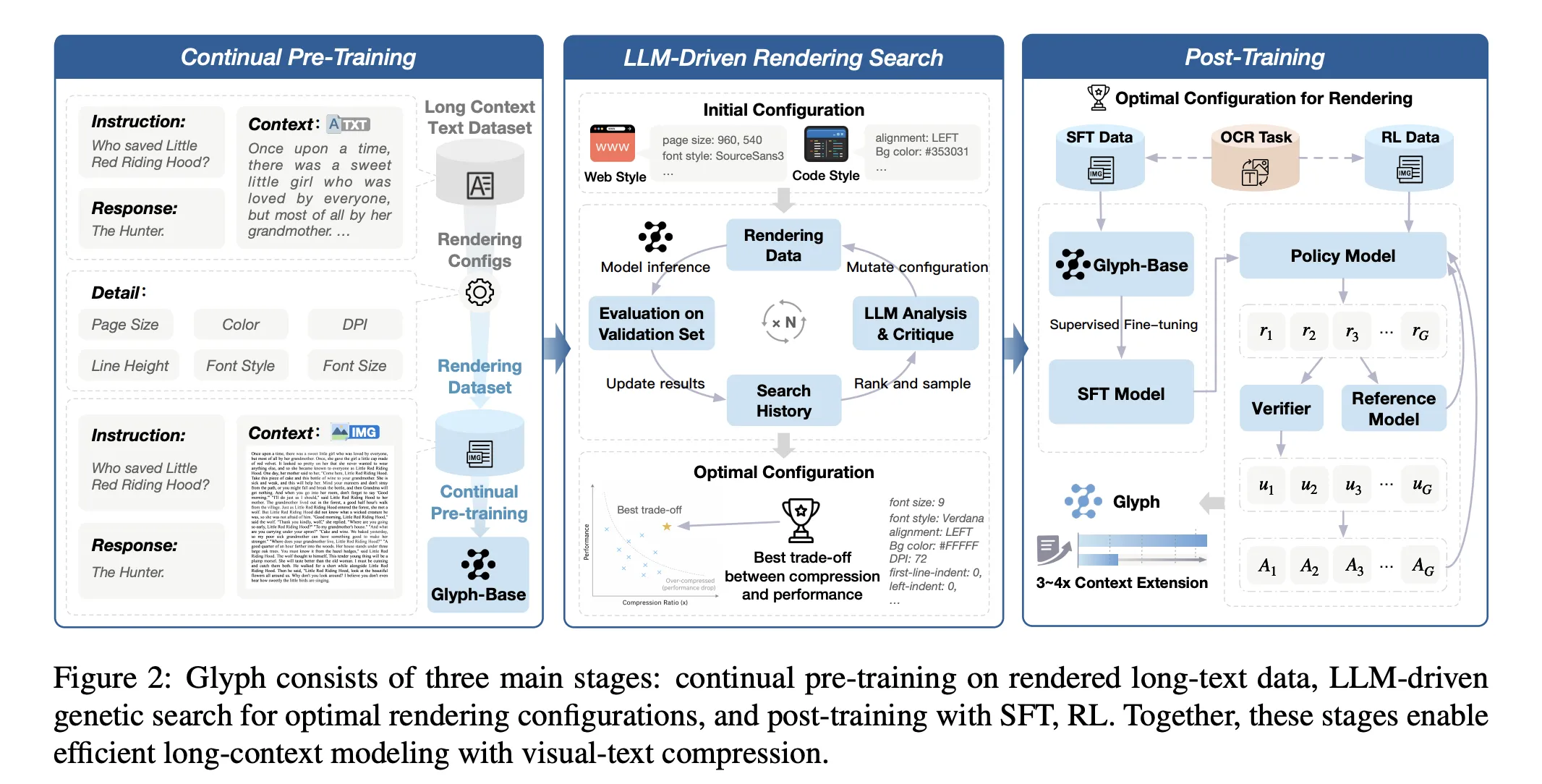
Die Methode besteht aus drei Phasen: kontinuierlichem Vortraining, LLM-gesteuerter Rendering-Suche und Nachtraining. Durch kontinuierliche Vorschulung wird der VLM mit großen Korpora gerenderter Langtexte mit unterschiedlichen Typografien und Stilen vertraut gemacht. Das Ziel bringt visuelle und textliche Darstellungen in Einklang und überträgt umfassende Kontextfähigkeiten von Textual content-Tokens auf visuelle Tokens. Die Rendering-Suche ist eine genetische Schleife, die von einem LLM gesteuert wird. Es verändert Seitengröße, DPI, Schriftfamilie, Schriftgröße, Zeilenhöhe, Ausrichtung, Einzug und Abstand. Es bewertet Kandidaten anhand eines Validierungssatzes, um Genauigkeit und Komprimierung gemeinsam zu optimieren. Nach dem Coaching werden überwachte Feinabstimmung und verstärkendes Lernen mit Group Relative Coverage Optimization sowie eine zusätzliche OCR-Ausrichtungsaufgabe verwendet. Der OCR-Verlust verbessert die Zeichentreue, wenn die Schriftarten klein und die Abstände eng sind.
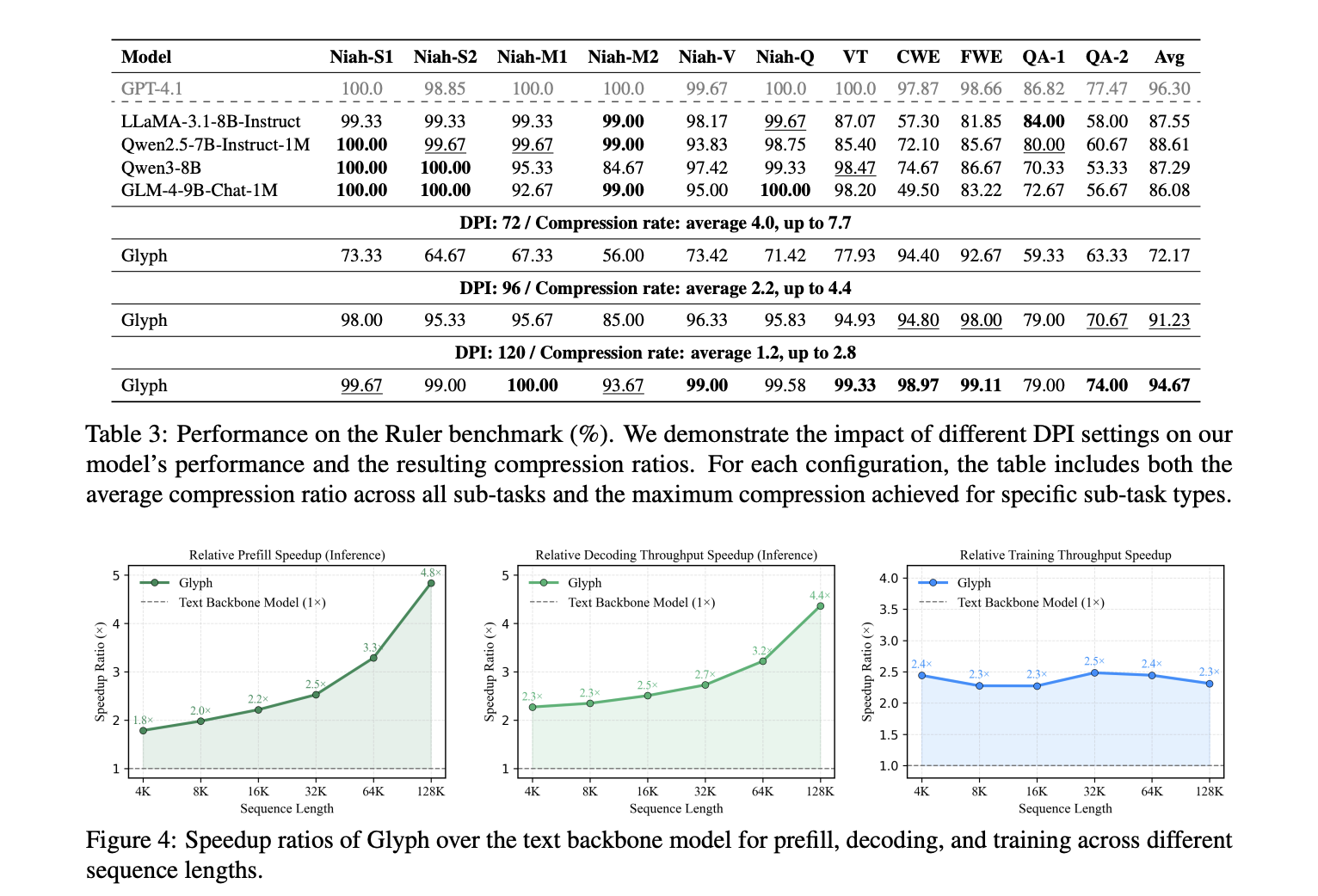
Ergebnisse, Leistung und Effizienz…
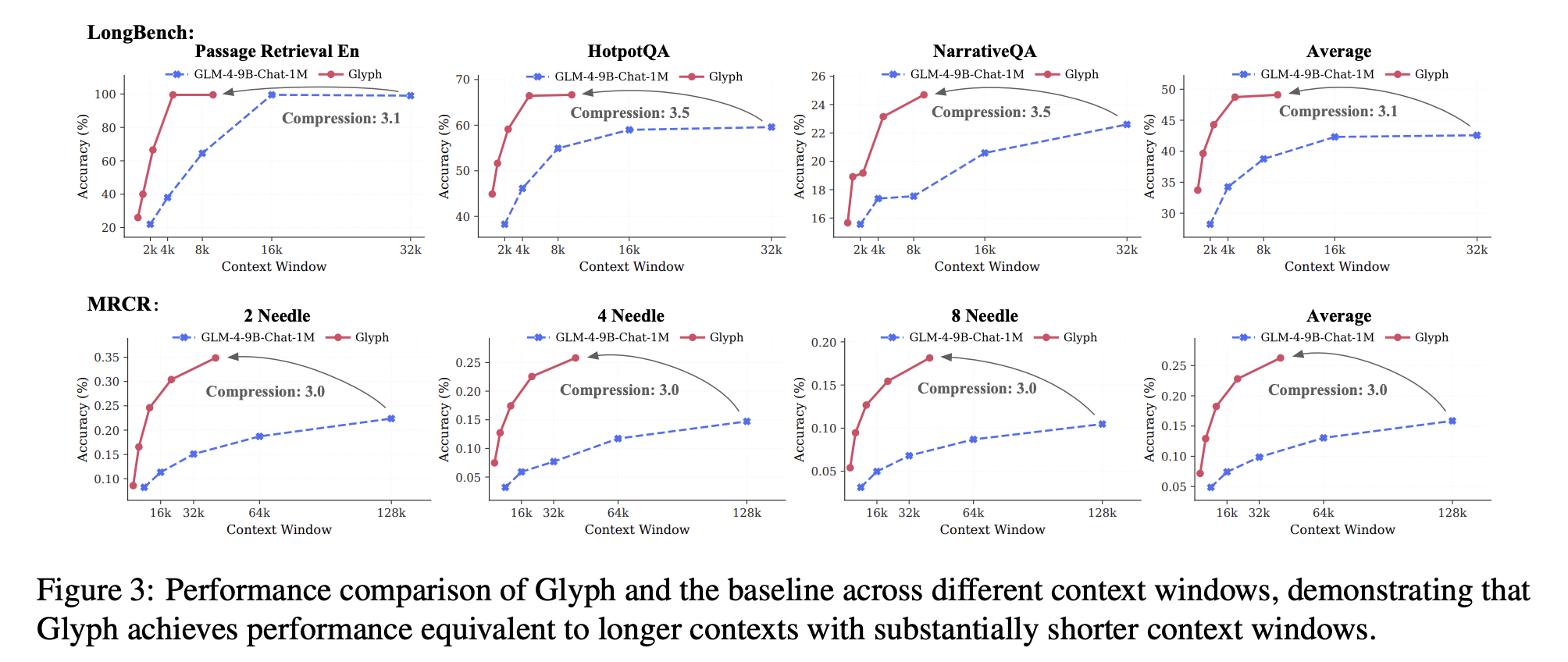
LongBench und MRCR sorgen für Genauigkeit und Komprimierung bei langen Dialogverläufen und Dokumentenaufgaben. Das Modell erreicht ein durchschnittliches effektives Komprimierungsverhältnis von etwa 3,3 bei LongBench, bei einigen Aufgaben nahe 5, und etwa 3,0 bei MRCR. Diese Gewinne skalieren mit längeren Eingaben, da jedes visuelle Token mehr Zeichen trägt. Die gemeldeten Geschwindigkeitssteigerungen im Vergleich zum Textual content-Spine bei 128K-Eingaben betragen etwa das 4,8-fache für die Vorfüllung, etwa das 4,4-fache für die Dekodierung und etwa das Zweifache für den überwachten Feinabstimmungsdurchsatz. Der Ruler-Benchmark bestätigt, dass eine höhere Auflösung bei der Inferenzzeit die Ergebnisse verbessert, da schärfere Glyphen die OCR- und Format-Analyse unterstützen. Das Forschungsteam meldet dpi 72 mit einer durchschnittlichen Komprimierung von 4,0 und maximal 7,7 für bestimmte Unteraufgaben, dpi 96 mit einer durchschnittlichen Komprimierung von 2,2 und maximal 4,4 und dpi 120 mit einer durchschnittlichen Komprimierung von 1,2 und maximal 2,8. Das Most von 7,7 gehört Ruler, nicht MRCR.
Na und? Anwendungen
Glyph fördert das Verständnis multimodaler Dokumente. Das Coaching auf gerenderten Seiten verbessert die Leistung von MMLongBench Doc im Vergleich zu einem visuellen Basismodell. Dies weist darauf hin, dass das Rendering-Ziel ein nützlicher Vorwand für echte Dokumentaufgaben ist, die Abbildungen und Format umfassen. Die Hauptfehlerursache ist die Empfindlichkeit gegenüber aggressiver Typografie. Sehr kleine Schriftarten und enge Abstände beeinträchtigen die Zeichengenauigkeit, insbesondere bei seltenen alphanumerischen Zeichenfolgen. Das Forschungsteam schließt die UUID-Unteraufgabe auf Ruler aus. Der Ansatz geht davon aus Server Seitenrendering und ein VLM mit starker OCR und Format-Priors.
Wichtige Erkenntnisse
- Glyph rendert langen Textual content in Bilder, dann verarbeitet ein Imaginative and prescient-Sprachmodell diese Seiten. Dadurch wird die Modellierung mit langem Kontext als multimodales Downside neu definiert und die Semantik bleibt erhalten, während gleichzeitig Token reduziert werden.
- Das Forschungsteam berichtet, dass die Token-Komprimierung drei- bis viermal so hoch ist, mit einer Genauigkeit, die mit starken 8B-Textbasislinien bei Langkontext-Benchmarks vergleichbar ist.
- Die Vorfüllgeschwindigkeit beträgt etwa das 4,8-fache, die Dekodierungsgeschwindigkeit beträgt etwa das 4,4-fache und der Durchsatz für die überwachte Feinabstimmung beträgt etwa das Zweifache, gemessen bei 128K-Eingängen.
- Das System verwendet kontinuierliches Vortraining auf gerenderten Seiten, eine LLM-gesteuerte genetische Suche über Rendering-Parameter, anschließend überwachte Feinabstimmung und verstärkendes Lernen mit GRPO sowie ein OCR-Ausrichtungsziel.
- Die Auswertungen umfassen LongBench, MRCR und Ruler, wobei ein Extremfall einen 128K-Kontext-VLM zeigt, der 1M-Token-Stage-Aufgaben bearbeitet. Code und Modellkarte sind auf GitHub und Hugging Face öffentlich.
Glyph behandelt die Skalierung langer Kontexte als visuelle Textkomprimierung, rendert lange Sequenzen in Bilder und lässt sie von einem VLM verarbeiten, wodurch Token reduziert und gleichzeitig die Semantik erhalten bleibt. Das Forschungsteam behauptet eine drei- bis vierfache Token-Komprimierung mit einer Genauigkeit, die mit den Qwen3 8B-Basislinien vergleichbar ist, etwa viermal schnelleres Vorfüllen und Dekodieren und etwa zweimal schnelleren SFT-Durchsatz. Die Pipeline ist diszipliniert, kontinuierliches Vortraining auf gerenderten Seiten, eine LLM-genetische Rendering-Suche über Typografie und dann Nachschulung. Der Ansatz ist für Millionen-Token-Workloads unter extremer Komprimierung pragmatisch, hängt jedoch von OCR- und Typografie-Optionen ab, die nach wie vor Stellschrauben sind. Insgesamt bietet die visuelle Textkomprimierung einen konkreten Weg zur Skalierung langer Kontexte bei gleichzeitiger Steuerung von Rechenleistung und Speicher.
Schauen Sie sich das an Papier, Gewichte Und Repo. Schauen Sie sich gerne bei uns um GitHub-Seite für Tutorials, Codes und Notebooks. Sie können uns auch gerne weiter folgen Twitter und vergessen Sie nicht, bei uns mitzumachen 100.000+ ML SubReddit und Abonnieren Unser Publication. Warten! Bist du im Telegram? Jetzt können Sie uns auch per Telegram kontaktieren.
Asif Razzaq ist CEO von Marktechpost Media Inc.. Als visionärer Unternehmer und Ingenieur setzt sich Asif dafür ein, das Potenzial der künstlichen Intelligenz für das soziale Wohl zu nutzen. Sein jüngstes Unterfangen ist die Einführung einer Medienplattform für künstliche Intelligenz, Marktechpost, die sich durch eine ausführliche Berichterstattung über maschinelles Lernen und Deep-Studying-Nachrichten auszeichnet, die sowohl technisch fundiert als auch für ein breites Publikum leicht verständlich ist. Die Plattform verfügt über mehr als 2 Millionen monatliche Aufrufe, was ihre Beliebtheit beim Publikum verdeutlicht.