
Wenn Sie zum ersten Mal ein großes Sprachmodell verwenden, haben Sie oft das Gefühl, rohe Intelligenz in Ihren Händen zu halten. Sie neigen dazu, sehr intestine zu schreiben, zusammenzufassen und zu argumentieren. Wenn Sie jedoch ein echtes Produkt bauen und versenden, sind alle Risse im Modell sichtbar. Es erinnert sich nicht daran, was Sie gestern gesagt haben, und fängt an, Dinge zu erfinden, wenn es aus dem Zusammenhang gerät. Das liegt nicht daran, dass das Modell nicht clever ist. Dies liegt daran, dass das Modell von der Außenwelt isoliert ist und durch Kontextfenster eingeschränkt wird, die wie ein kleines Whiteboard funktionieren. Dies kann nicht durch eine bessere Eingabeaufforderung behoben werden – Sie benötigen einen tatsächlichen Kontext rund um das Modell. Hier kommt Context Engineering zum Einsatz. Dieser Artikel dient als umfassender Leitfaden zum Kontext-Engineering, indem er das Wort definiert und die beteiligten Prozesse beschreibt.
Dem Drawback kann sich niemand entziehen
LLMs sind brillant, aber in ihrem Umfang begrenzt. Dies liegt zum Teil daran, dass sie Folgendes haben:
- Kein Zugriff auf personal Dokumente
- Keine Erinnerung an vergangene Gespräche
- Eingeschränktes Kontextfenster
- Halluzination unter Druck
- Verschlechterung, wenn das Kontextfenster zu groß wird

Während einige der Einschränkungen notwendig sind (fehlender Zugriff auf personal Dokumente), ist dies bei begrenztem Gedächtnis, Halluzinationen und begrenztem Kontextfenster nicht der Fall. Dies setzt Context Engineering als Lösung und nicht als Add-on voraus.
Was ist Context Engineering?
Beim Kontext-Engineering handelt es sich um den Prozess der Strukturierung der gesamten Eingabe, die einem großen Sprachmodell bereitgestellt wird, um dessen Genauigkeit und Zuverlässigkeit zu verbessern. Dabei geht es darum, die Eingabeaufforderungen so zu strukturieren und zu optimieren, dass ein LLM den gesamten „Kontext“ erhält, den es benötigt, um eine Antwort zu generieren, die genau der erforderlichen Ausgabe entspricht.
Mehr lesen: Was ist Context Engineering?
Was bietet es?
Unter Kontext-Engineering versteht man die Praxis, dem Modell mithilfe einer orchestrierten Architektur genau die richtigen Informationen, in der richtigen Reihenfolge, zur richtigen Zeit zuzuführen. Es geht nicht darum, das Modell selbst zu ändern, sondern darum, Brücken zu bauen, die es mit der Außenwelt verbinden, externe Daten abzurufen, es mit Reside-Instruments zu verbinden und ihm ein Gedächtnis zu geben, um seine Antworten auf Fakten und nicht nur auf Trainingsdaten zu stützen. Dies ist nicht auf den Immediate beschränkt und unterscheidet sich daher vom Immediate Engineering. Es wird auf Systemdesignebene implementiert.
Kontext-Engineering hat weniger damit zu tun, was der Benutzer in die Eingabeaufforderung einfügen kann, als vielmehr mit der Architekturauswahl des vom Entwickler verwendeten Modells.
Die Bausteine
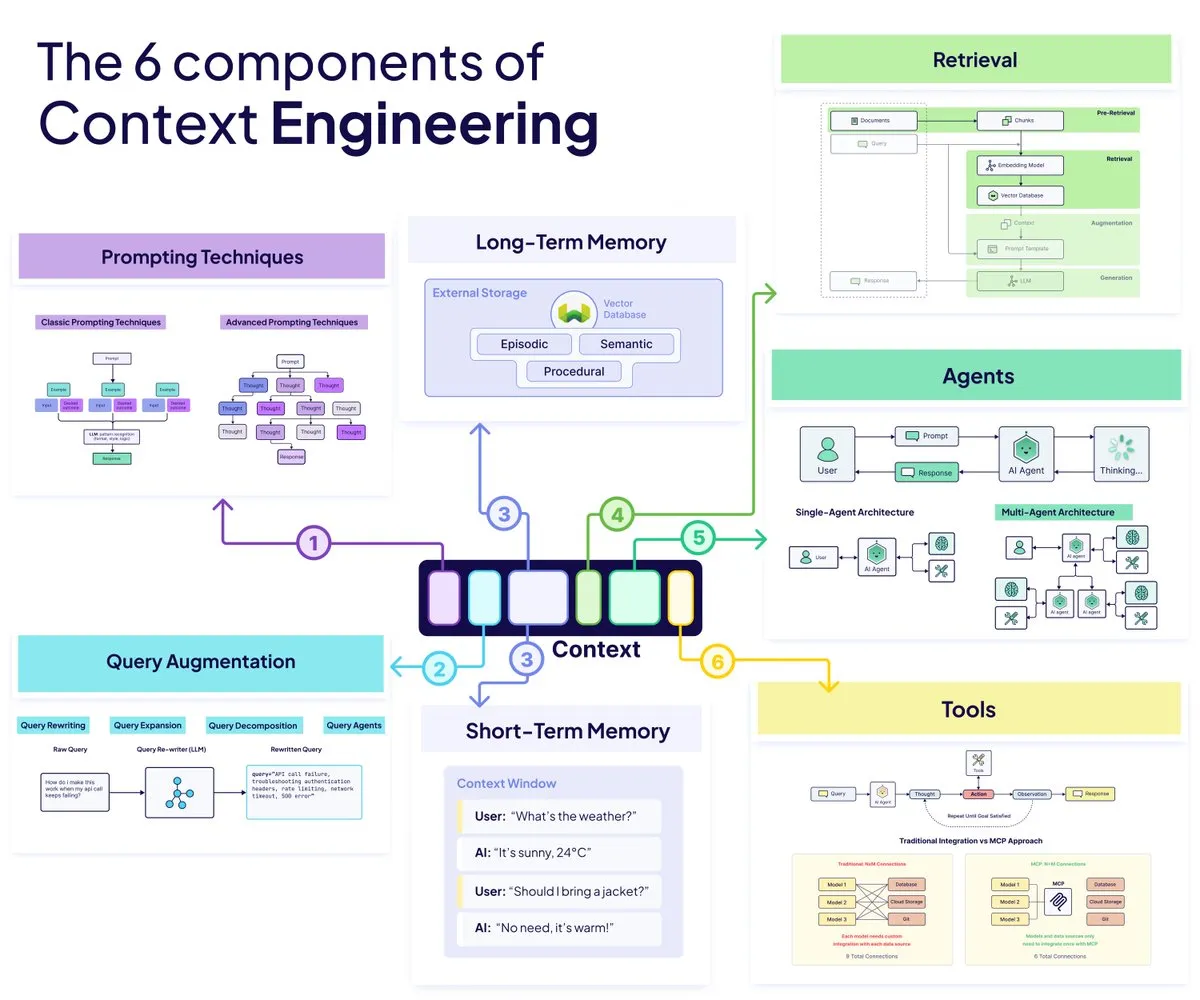
Hier sind die 6 Bausteine des Content material Engineering-Frameworks:
1. Agenten
KI-Agenten sind der Teil Ihres Techniques, der entscheidet, was als nächstes zu tun ist. Sie erkennen die State of affairs, wählen die richtigen Werkzeuge aus, passen ihren Ansatz an und stellen sicher, dass das Modell nicht blind rät. Anstelle einer starren Pipeline schaffen Agenten einen flexiblen Kreislauf, in dem das System denken, handeln und sich selbst korrigieren kann.
- Sie unterteilen Aufgaben in Schritte
- Sie leiten Informationen dorthin weiter, wo sie benötigt werden
- Sie verhindern, dass der gesamte Arbeitsablauf zusammenbricht, wenn sich etwas ändert
2. Abfrageerweiterung
Durch die Abfrageerweiterung wird alles bereinigt, was der Benutzer auf das Modell wirft. Echte Benutzer sind chaotisch, und diese Ebene verwandelt ihre Eingaben in etwas, mit dem das System tatsächlich arbeiten kann. Indem Sie die Abfrage umschreiben, erweitern oder in kleinere Teile aufteilen, stellen Sie sicher, dass das Modell nach dem Richtigen und nicht nach dem Falschen sucht.
- Das Umschreiben entfernt Rauschen und sorgt für mehr Klarheit
- Durch die Erweiterung wird die Suche erweitert, wenn die Absicht unklar ist
- Die Zerlegung verarbeitet komplexe Eingabeaufforderungen mit mehreren Fragen
3. Abrufen
Datenabruf über. Augmented Era abrufenSo bringen Sie die relevantesten Informationen aus einer riesigen Wissensdatenbank zum Vorschein. Sie teilen Dokumente so auf, dass das Modell sie verstehen kann, ziehen das richtige Section zur richtigen Zeit und geben dem Modell die Fakten, die es benötigt, ohne sein Kontextfenster zu überfordern.
- Die Blockgröße beeinflusst sowohl die Genauigkeit als auch das Verständnis
- Pre-Chunking beschleunigt die Arbeit
- Publish-Chunking passt sich an knifflige Abfragen an
4. Aufforderungstechniken
Aufforderungstechniken Steuern Sie die Argumentation des Modells, sobald ihm die richtigen Informationen vorliegen. Sie bestimmen, wie das Modell denkt, wie es seine Schritte erklärt und wie es mit Werkzeugen oder Beweisen interagiert. Die richtige Aufforderungsstruktur kann eine unscharfe Antwort in eine sichere Antwort verwandeln.
- Chain of Thought fördert schrittweises Denken
- Nur wenige Schussbeispiele zeigen das ideale Ergebnis
- ReAct verbindet Argumentation mit echten Handlungen
5. Erinnerung
Speicher sorgt für Kontinuität in Ihrem System. Es verfolgt, was zuvor passiert ist, was der Benutzer bevorzugt und was der Agent bisher gelernt hat. Ohne Speicher wird Ihr Modell jedes Mal zurückgesetzt. Damit wird das System intelligenter, schneller und persönlicher.
- Das Kurzzeitgedächtnis lebt im Kontextfenster
- Das Langzeitgedächtnis verbleibt im externen Speicher
- Der Arbeitsspeicher unterstützt mehrstufige Abläufe
6. Werkzeuge
Mithilfe von Instruments kann das Modell über den Textual content hinausgehen und mit der realen Welt interagieren. Mit dem richtigen Toolset kann das Modell Daten abrufen, Aktionen ausführen oder APIs aufrufen, anstatt zu raten. Dadurch wird aus einem Assistenten ein tatsächlicher Bediener, der Dinge erledigen kann.
- Funktionsaufrufe erstellen strukturierte Aktionen
- MCP standardisiert, wie Modelle auf externe Systeme zugreifen
- Gute Werkzeugbeschreibungen verhindern Fehler
Wie arbeiten sie zusammen?
Zeichnen Sie ein Bild einer modernen KI-App:
- Der Benutzer sendet eine chaotische Anfrage
- Der Abfrageagent schreibt es neu
- Das Retrieval-System findet Beweise durch intelligentes Chunking
- Agent validiert Informationen
- Instruments rufen externe Daten in Echtzeit ab
- Der Speicher speichert den Kontext und ruft ihn ab
Stellen Sie es sich so vor:
Der Benutzer sendet eine chaotische Anfrage. Der Abfrageagent empfängt es und schreibt es aus Gründen der Übersichtlichkeit neu. Das RAG-System findet mithilfe von Good Chunking Beweise innerhalb der Abfrage. Der Agent erhält diese Informationen und prüft deren Authentizität und Integrität. Diese Informationen werden verwendet, um über MCP entsprechende Aufrufe zu tätigen, um Echtzeitdaten abzurufen. Der Speicher speichert Informationen und Kontext, die während dieses Abrufs und Bereinigens gewonnen wurden.
Diese Informationen können später abgerufen werden, um wieder auf den richtigen Weg zu kommen, falls ein relevanter Kontext erforderlich ist. Dies erspart redundante Verarbeitung und ermöglicht den Abruf verarbeiteter Informationen für die zukünftige Verwendung.
Beispiele aus der Praxis
Hier sind einige reale Anwendungen einer Context-Engineering-Architektur:
- Helfer für den Kundensupport: Agenten überarbeiten vage Kundenanfragen, extrahieren produktspezifische Dokumente, überprüfen vergangene Tickets im Langzeitgedächtnis und nutzen Instruments, um den Bestellstatus abzurufen. Das Modell rät nicht; es antwortet mit bekanntem Kontext.
- Interne Wissensassistenten für Groups: Mitarbeiter stellen chaotische, halbfertige Fragen. Die Abfrageerweiterung bereinigt sie, der Abruf findet die richtige Richtlinie oder das richtige technische Dokument und der Speicher ruft vergangene Gespräche ab. Jetzt dient der Agent als vertrauenswürdige interne Such- und Argumentationsebene, um zu helfen.
- KI Forschungs-Co-Piloten: Das System zerlegt komplexe Forschungsanfragen in ihre Bestandteile, ruft mithilfe semantischer oder hierarchischer Aufteilung relevante Arbeiten ab und synthetisiert die Ergebnisse. Instruments können auf Reside-Datensätze zugreifen, während der Speicher frühere Hypothesen, Notizen usw. verfolgt.
- Workflow-Automatisierungsagenten: Der Agent plant eine Aufgabe mit vielen Schritten, ruft APIs auf, überprüft Kalender, aktualisiert Datenbanken und nutzt das Langzeitgedächtnis, um die Aktion zu personalisieren. Der Abruf bringt geeignete Regeln oder SOPs in den Arbeitsablauf ein, um ihn authorized und korrekt zu halten.
- Domänenspezifische Assistenten: Bei der Recherche werden geprüfte Dokumente, Richtlinien oder Vorschriften herangezogen. Der Speicher speichert frühere Fälle. Instruments greifen auf Reside-Systeme oder Datensätze zu. Das Umschreiben von Abfragen reduziert die Mehrdeutigkeit des Benutzers, um das Modell fundiert und sicher zu halten.
Was das für die Zukunft der KI-Technik bedeutet
Beim Kontext-Engineering liegt der Fokus nicht mehr auf einer laufenden Konversation mit einem Modell, sondern auf der Gestaltung des Ökosystemkontexts, der eine intelligente Leistung des Modells ermöglicht. Dabei geht es nicht nur um Eingabeaufforderungen, Abruftricks oder zusammengebastelte Architektur. Es handelt sich um ein eng koordiniertes System, in dem Agenten entscheiden, was zu tun ist, Abfragen bereinigt werden, die richtigen Fakten zur richtigen Zeit angezeigt werden, das Gedächtnis vergangene Kontexte weiterleitet und Instruments das Modell in der realen Welt agieren lassen.
Diese Elemente werden sich jedoch weiterentwickeln und weiterentwickeln. Was die erfolgreicheren Modelle, Apps oder Instruments ausmachen wird, sind diejenigen, die auf bewusster, bewusster Kontextgestaltung basieren. Größere Modelle allein werden uns nicht dorthin bringen, aber eine bessere Technik schon. Die Zukunft wird den Bauherren gehören, denen, die genauso viel an die Umwelt gedacht haben wie an die Modelle.
Häufig gestellte Fragen
A. Es behebt die Diskrepanz zwischen der Intelligenz eines LLM und seinem begrenzten Bewusstsein. Indem Sie steuern, welche Informationen wann das Modell erreichen, vermeiden Sie Halluzinationen, fehlenden Kontext und die blinden Flecken, die reale KI-Apps zerstören.
A. Schnelle Anweisungen für technische Formen. Context Engineering gestaltet das gesamte System rund um das Modell, einschließlich Abruf, Speicher, Instruments und Abfrageverarbeitung. Es handelt sich um eine architektonische Disziplin, nicht um eine schnelle Optimierung.
A. Größere Fenster sind immer noch laut, langsam und unzuverlässig. Fashions verlieren den Fokus, vermischen unzusammenhängende Particulars und halluzinieren mehr. Intelligenter Kontext übertrifft schiere Größe.
A. Nein. Es verbessert jede KI-Anwendung, die Speicher, Werkzeugnutzung, mehrstufiges Denken oder Interaktion mit privaten oder dynamischen Daten benötigt.
A. Starkes Systemdesign-Denken, Vertrautheit mit Agenten, RAG-Pipelines, Speicherspeichern und Instrument-Integration. Das Ziel besteht darin, Informationen zu orchestrieren und nicht nur einen LLM anzurufen.
Ich bin auf die Überprüfung und Verfeinerung von KI-gestützter Forschung, technischer Dokumentation und Inhalten im Zusammenhang mit neuen KI-Technologien spezialisiert. Meine Erfahrung umfasst KI-Modelltraining, Datenanalyse und Informationsabruf und ermöglicht es mir, Inhalte zu erstellen, die sowohl technisch korrekt als auch zugänglich sind.
Melden Sie sich an, um weiterzulesen und von Experten kuratierte Inhalte zu genießen.