

Bild vom Herausgeber
# Einführung
ChatGPT, Claude, Zwillinge. Sie kennen die Namen. Aber hier ist eine Frage: Was wäre, wenn Sie stattdessen Ihr eigenes Modell ausführen würden? Es klingt ehrgeizig. Das ist es nicht. Sie können ein funktionierendes bereitstellen großes Sprachmodell (LLM) in weniger als 10 Minuten, ohne einen Greenback auszugeben.
Dieser Artikel schlüsselt es auf. Zunächst ermitteln wir, was Sie tatsächlich benötigen. Dann schauen wir uns die tatsächlichen Kosten an. Schließlich werden wir TinyLlama kostenlos auf Hugging Face bereitstellen.
Bevor Sie Ihr Modell auf den Markt bringen, haben Sie wahrscheinlich viele Fragen im Kopf. Welche Aufgaben erwarte ich zum Beispiel von meinem Modell?
Versuchen wir, diese Frage zu beantworten. Wenn Sie einen Bot für 50 Benutzer benötigen, benötigen Sie GPT-5 nicht. Oder wenn Sie eine Stimmungsanalyse für mehr als 1.200 Tweets professional Tag planen, benötigen Sie möglicherweise kein Modell mit 50 Milliarden Parametern.
Schauen wir uns zunächst einige beliebte Anwendungsfälle und die Modelle an, die diese Aufgaben ausführen können.
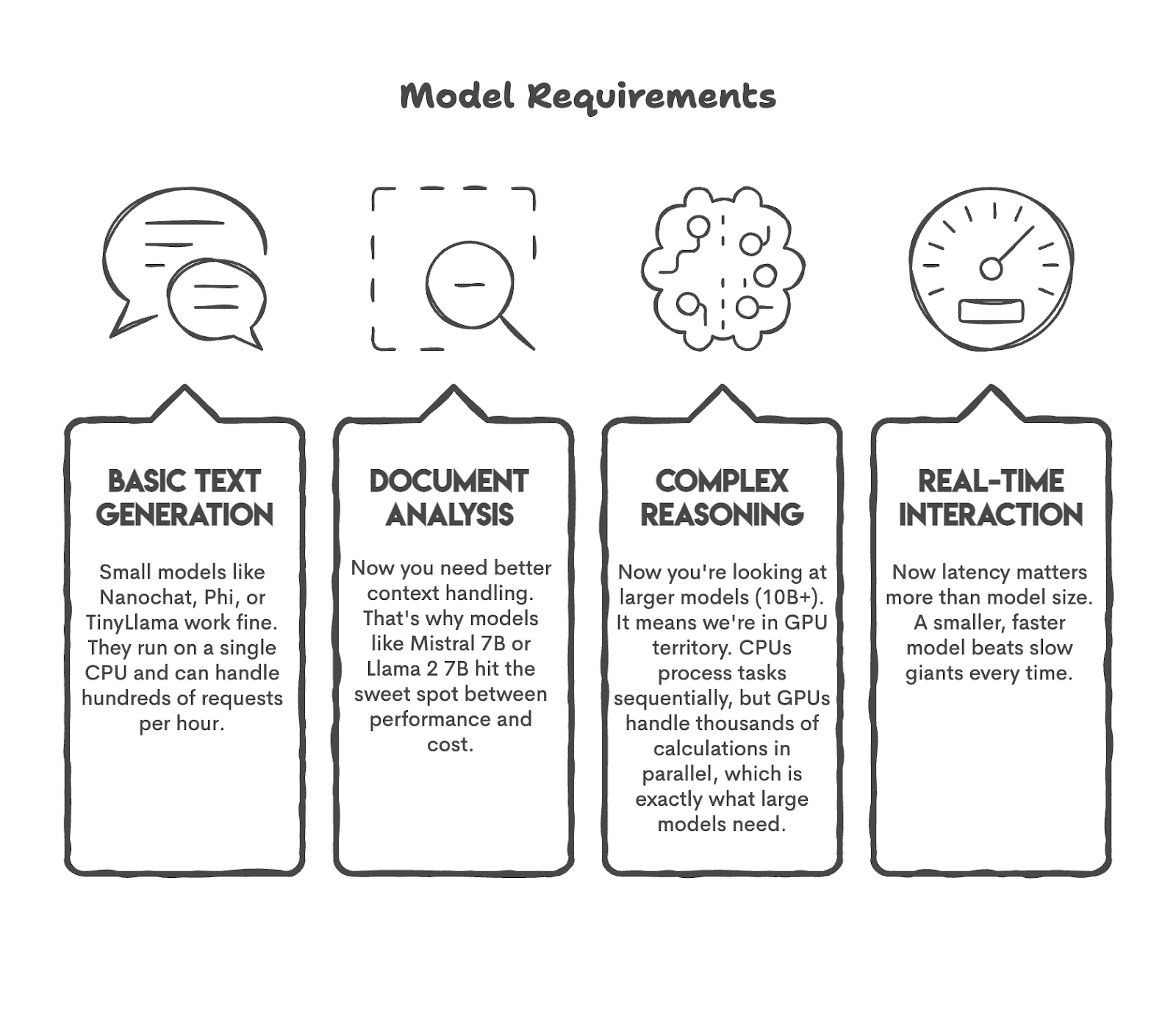
Wie Sie sehen, haben wir das Modell an die Aufgabe angepasst. Dies sollten Sie tun, bevor Sie beginnen.
# Aufschlüsselung der tatsächlichen Kosten für die Durchführung eines LLM
Nachdem Sie nun wissen, was Sie brauchen, möchte ich Ihnen zeigen, wie viel es kostet. Beim Hosten eines Fashions geht es nicht nur um das Mannequin; Es geht auch darum, wo dieses Modell ausgeführt wird, wie häufig es ausgeführt wird und wie viele Personen damit interagieren. Lassen Sie uns die tatsächlichen Kosten entschlüsseln.
// Computing: Die höchsten Kosten, die Ihnen entstehen werden
Wenn Sie a ausführen Zentraleinheit (CPU) 24/7 an Amazon Net Providers (AWS) EC2, das würde etwa 36 $ professional Monat kosten. Wenn Sie jedoch a ausführen Grafikverarbeitungseinheit (GPU)-Instanz würde es etwa 380 US-Greenback professional Monat kosten – mehr als das Zehnfache der Kosten. Seien Sie additionally vorsichtig bei der Berechnung der Kosten Ihres großen Sprachmodells, denn dies ist der Hauptkostenfaktor.
(Bei den Berechnungen handelt es sich um Näherungswerte. Den tatsächlichen Preis finden Sie hier: AWS EC2-Preise).
// Lagerung: Geringe Kosten, es sei denn, Ihr Modell ist riesig
Berechnen wir grob den Speicherplatz. Ein 7B-Modell (7 Milliarden Parameter) benötigt etwa 14 Gigabyte (GB). Die Kosten für Cloud-Speicher liegen bei etwa 0,023 $ professional GB und Monat. Der Unterschied zwischen einem 1-GB-Modell und einem 14-GB-Modell beträgt additionally nur etwa 0,30 $ professional Monat. Die Speicherkosten können vernachlässigbar sein, wenn Sie nicht vorhaben, ein 300-B-Parametermodell zu hosten.
// Bandbreite: Günstig, bis Sie skalieren
Bandbreite ist wichtig, wenn Ihre Daten verschoben werden, und wenn andere Ihr Modell verwenden, werden Ihre Daten verschoben. AWS berechnet nach dem ersten GB 0,09 $ professional GB, es handelt sich additionally um ein paar Cent. Aber wenn Sie auf Millionen von Anfragen skalieren, sollten Sie auch dies sorgfältig kalkulieren.
(Bei den Berechnungen handelt es sich um Näherungswerte. Den tatsächlichen Preis finden Sie hier: Preise für AWS-Datenübertragungen).
// Kostenlose Internet hosting-Optionen, die Sie noch heute nutzen können
Gesichtsräume umarmen ermöglicht das kostenlose Hosten kleiner Modelle mit CPU. Machen Und Eisenbahn Bieten Sie kostenlose Stufen an, die für Demos mit geringem Datenverkehr geeignet sind. Wenn Sie experimentieren oder einen Proof-of-Idea erstellen, können Sie ziemlich weit kommen, ohne einen Cent auszugeben.
# Wählen Sie ein Modell, das Sie tatsächlich ausführen können
Jetzt kennen wir die Kosten, aber welches Modell sollten Sie verwenden? Natürlich hat jedes Modell seine Vor- und Nachteile. Wenn Sie beispielsweise ein 100-Milliarden-Parameter-Modell auf Ihren Laptop computer herunterladen, funktioniert es garantiert nicht, es sei denn, Sie verfügen über eine erstklassige, speziell gebaute Workstation.
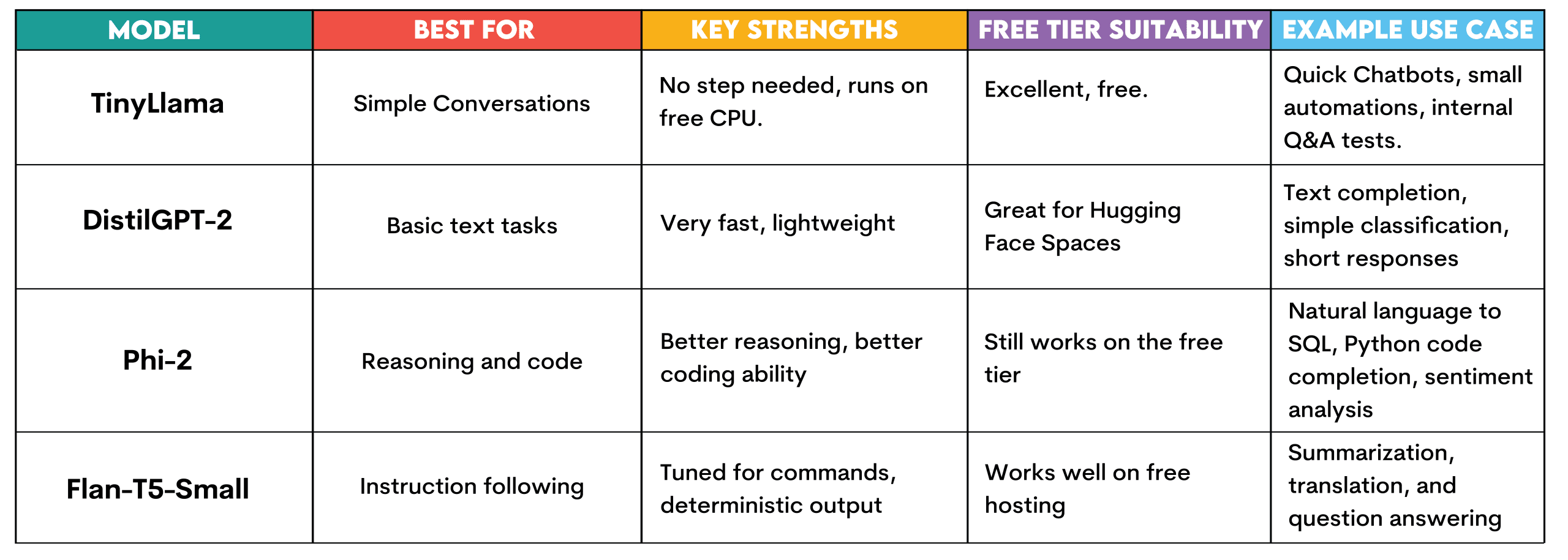
Sehen wir uns die verschiedenen Modelle an, die auf Hugging Face verfügbar sind, damit Sie sie kostenlos ausführen können, wie wir es im nächsten Abschnitt tun werden.
TinyLlama: Dieses Modell erfordert keine Einrichtung und läuft mit der kostenlosen CPU-Stufe von Hugging Face. Es ist für einfache Konversationsaufgaben, die Beantwortung einfacher Fragen und die Texterstellung konzipiert.
Es kann verwendet werden, um schnell Chatbots zu erstellen und zu testen, schnelle Automatisierungsexperimente durchzuführen oder interne Frage-Antwort-Systeme zum Testen zu erstellen, bevor es zu einer Infrastrukturinvestition wird.
DestillierenGPT-2: Es ist außerdem schnell und leicht. Dies macht es perfekt zum Umarmen von Gesichtsräumen. Geeignet zum Vervollständigen von Texten, für sehr einfache Klassifizierungsaufgaben oder für kurze Antworten. Geeignet, um zu verstehen, wie LLMs ohne Ressourcenbeschränkungen funktionieren.
Phi-2: Ein kleines, von Microsoft entwickeltes Modell, das sich als sehr effektiv erweist. Es läuft immer noch auf der kostenlosen Stufe von Hugging Face, bietet jedoch verbesserte Argumentation und Codegenerierung. Nutzen Sie es für die Abfragegenerierung in natürlicher Sprache in SQL, die einfache Vervollständigung von Python-Code oder die Stimmungsanalyse von Kundenbewertungen.
Flan-T5-Klein: Dies ist das Anweisungs-Tuning-Modell von Google. Geschaffen, um auf Befehle zu reagieren und Antworten zu geben. Nützlich für die Generierung, wenn Sie deterministische Ausgaben auf kostenlosem Internet hosting wünschen, z. B. Zusammenfassung, Übersetzung oder Beantwortung von Fragen.
# Stellen Sie TinyLlama in 5 Minuten bereit
Lassen Sie uns TinyLlama erstellen und bereitstellen, indem wir Hugging Face Areas kostenlos verwenden. Keine Kreditkarte, kein AWS-Konto, keine Docker-Probleme. Nur ein funktionierender Chatbot, den Sie mit einem Hyperlink teilen können.
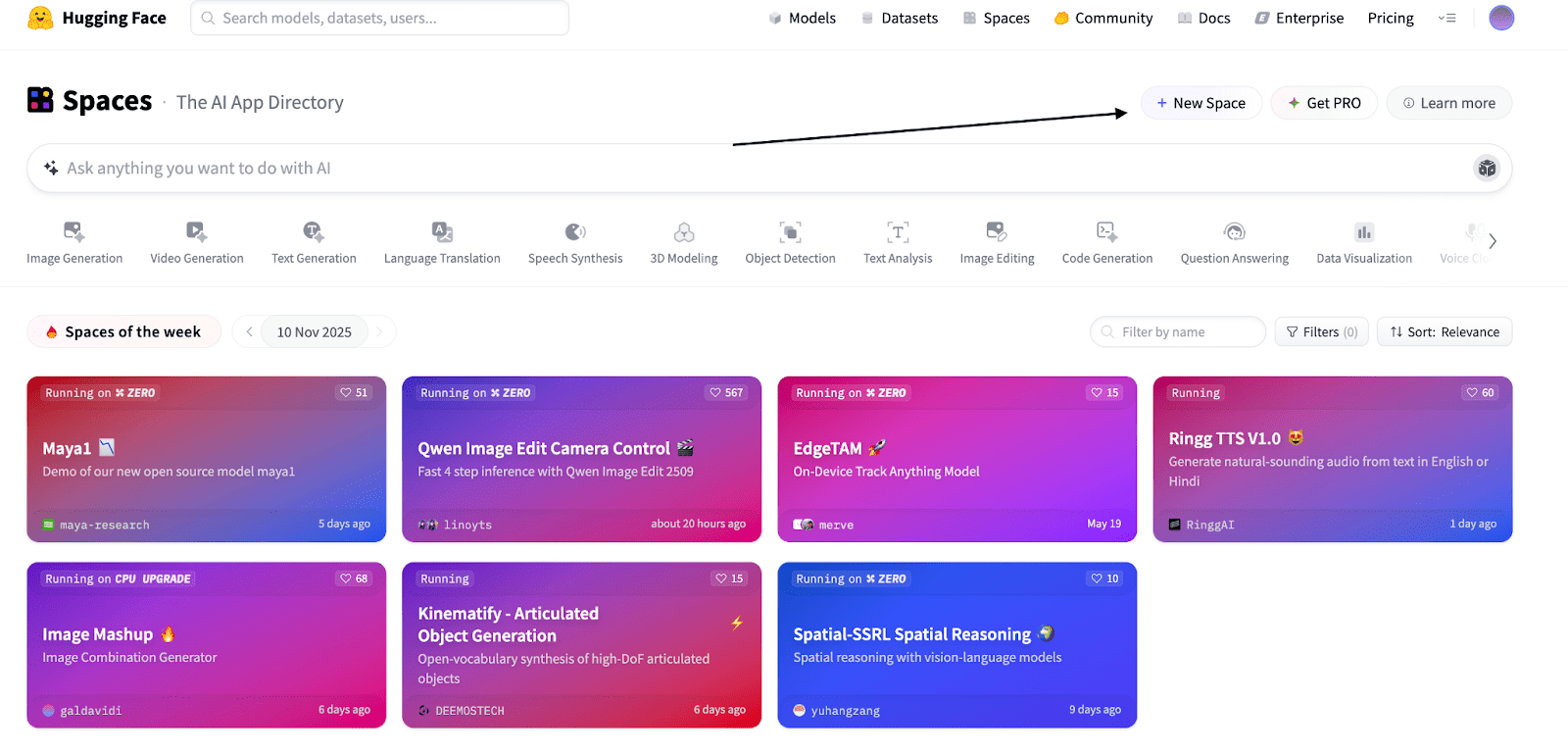
// Schritt 1: Gehen Sie zu „Gesichtsräume umarmen“.
Gehen Sie zu Huggingface.co/areas und klicken Sie auf „Neuer Bereich“, wie im Screenshot unten.
Benennen Sie den Raum nach Ihren Wünschen und fügen Sie eine kurze Beschreibung hinzu.
Die anderen Einstellungen können Sie unverändert lassen.
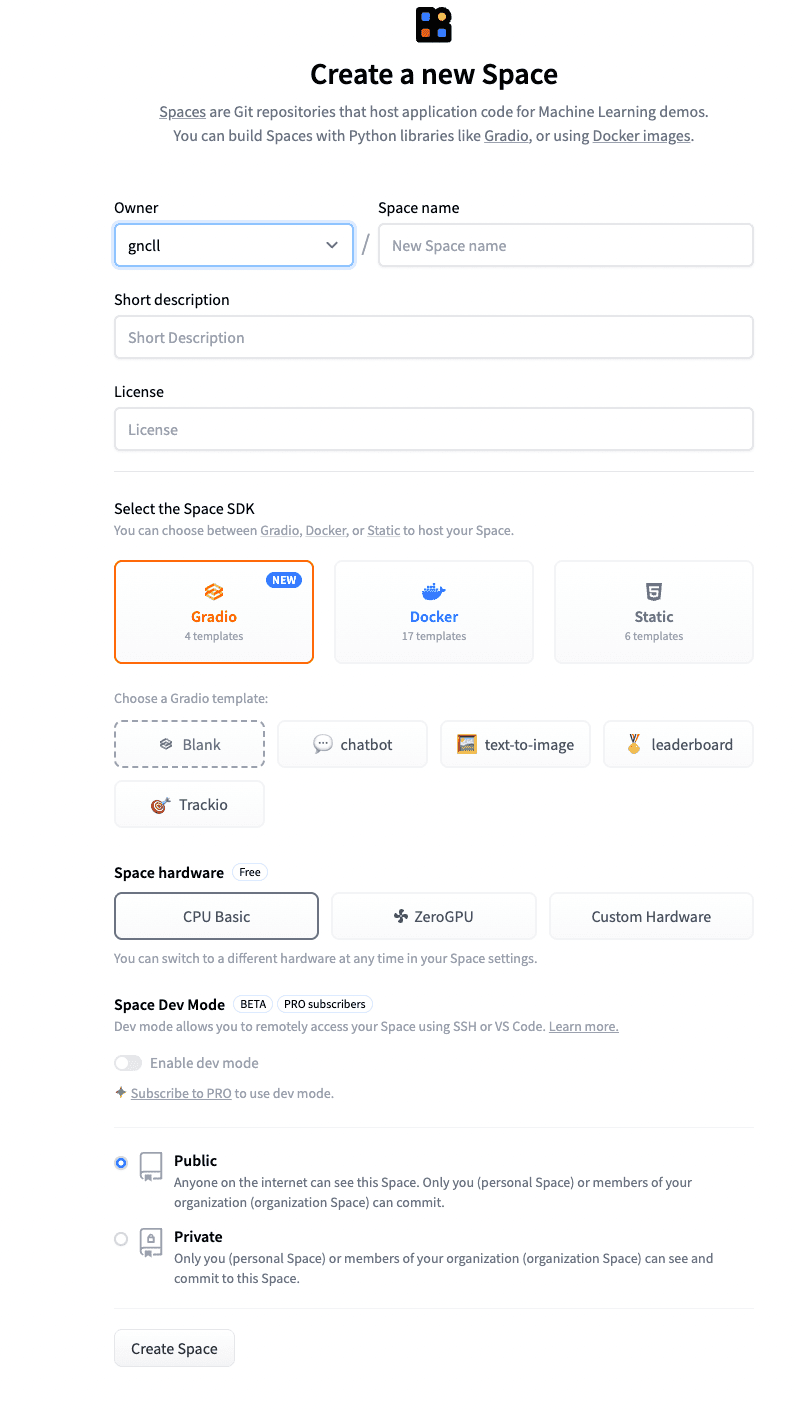
Klicken Sie auf „Bereich erstellen“.
// Schritt 2: Schreiben Sie die app.py
Klicken Sie nun im Bildschirm unten auf „App.py erstellen“.
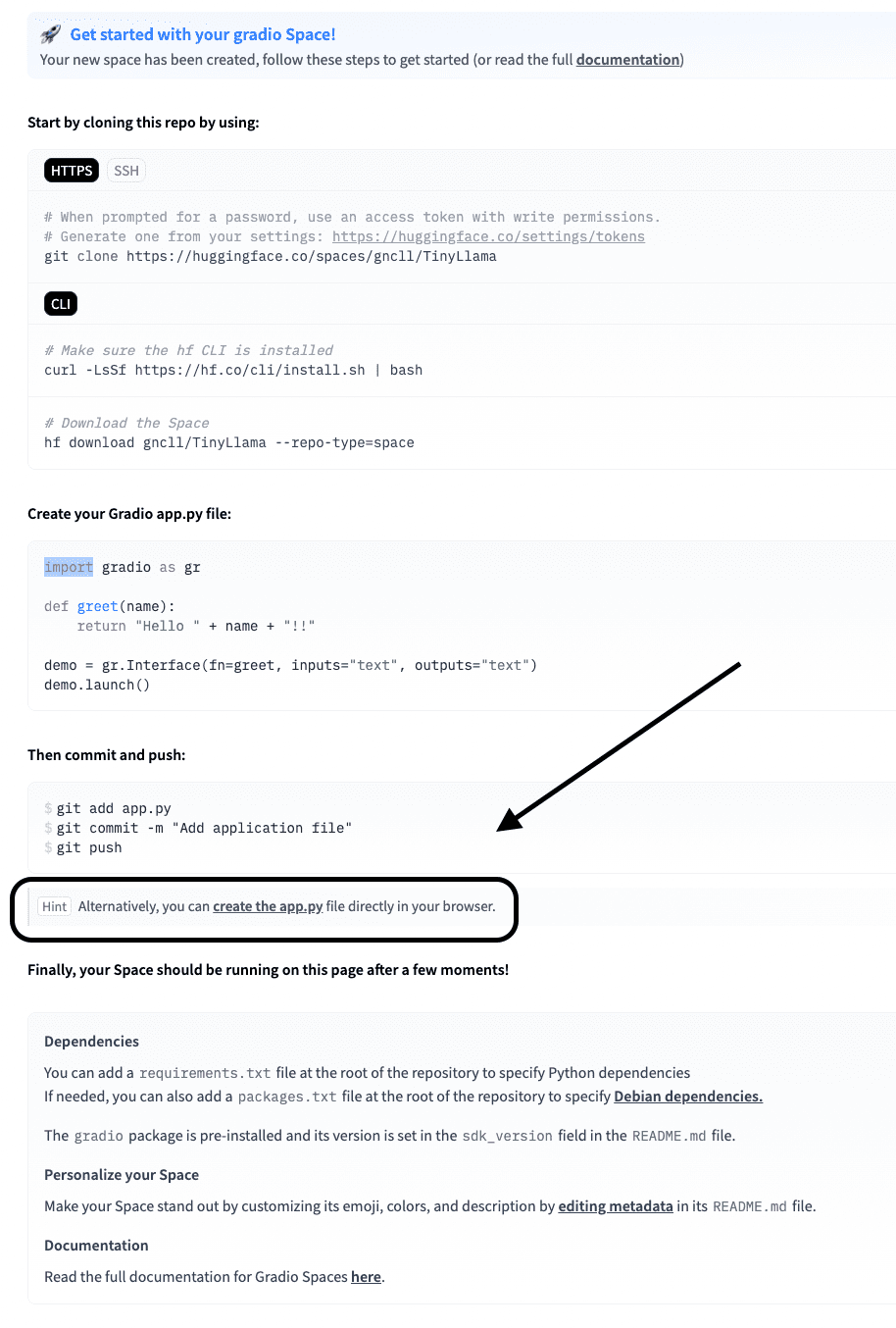
Fügen Sie den folgenden Code in diese app.py ein.
Dieser Code lädt TinyLlama (mit den bei Hugging Face verfügbaren Construct-Dateien), verpackt es in eine Chat-Funktion und verwendet Gradio um eine Weboberfläche zu erstellen. Der chat() Die Methode formatiert Ihre Nachricht korrekt, generiert eine Antwort (bis zu maximal 100 Token) und gibt nur die Antwort des Modells (ohne Wiederholungen) auf die von Ihnen gestellte Frage zurück.
Hier ist die Seite, auf der Sie lernen können, wie Sie Code für jedes Hugging Face-Modell schreiben.
Schauen wir uns den Code an.
import gradio as gr
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "TinyLlama/TinyLlama-1.1B-Chat-v1.0"
tokenizer = AutoTokenizer.from_pretrained(model_name)
mannequin = AutoModelForCausalLM.from_pretrained(model_name)
def chat(message, historical past):
# Put together the immediate in Chat format
immediate = f"<|consumer|>n{message}n<|assistant|>n"
inputs = tokenizer(immediate, return_tensors="pt")
outputs = mannequin.generate(
**inputs,
max_new_tokens=100,
temperature=0.7,
do_sample=True,
pad_token_id=tokenizer.eos_token_id
)
response = tokenizer.decode(outputs(0)(inputs('input_ids').form(1):), skip_special_tokens=True)
return response
demo = gr.ChatInterface(chat)
demo.launch()Klicken Sie nach dem Einfügen des Codes auf „Neue Datei in die Hauptdatei übertragen“. Bitte sehen Sie sich den folgenden Screenshot als Beispiel an.
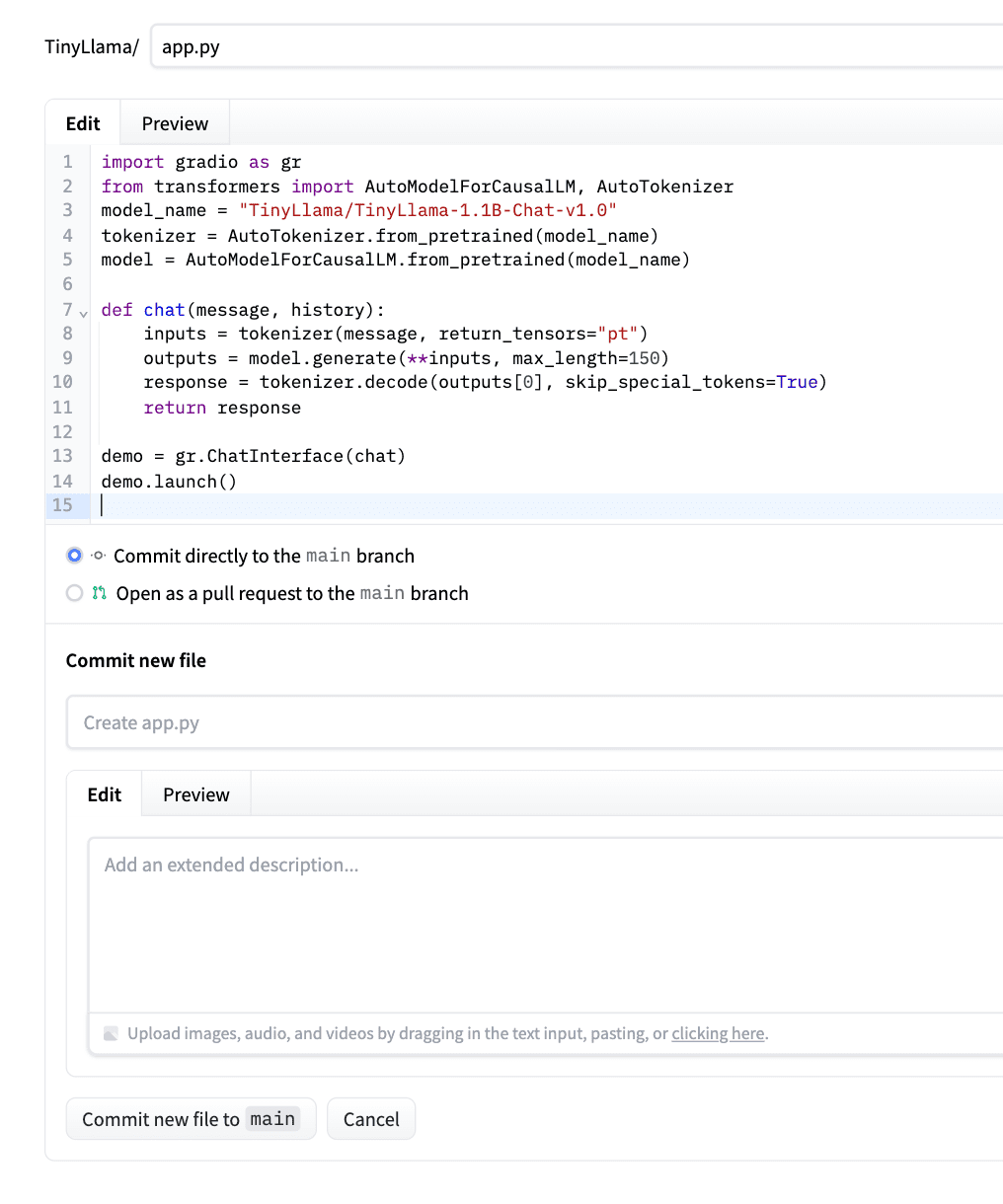
Hugging Face erkennt es automatisch, installiert Abhängigkeiten und stellt Ihre App bereit.

Erstellen Sie in dieser Zeit eine necessities.txt Datei oder Sie erhalten eine Fehlermeldung wie diese.

// Schritt 3: Erstellen Sie die Datei „Necessities.txt“.
Klicken Sie oben rechts auf dem Bildschirm auf „Dateien“.

Klicken Sie hier auf „Neue Datei erstellen“, wie im Screenshot unten.

Benennen Sie die Datei „necessities.txt“ und fügen Sie drei Python-Bibliotheken hinzu, wie im folgenden Screenshot gezeigt (transformers, torch, gradio).
Transformatoren Hier lädt das Modell und kümmert sich um die Tokenisierung. Fackel führt das Modell aus, da es die neuronale Netzwerk-Engine bereitstellt. Gradio erstellt eine einfache Weboberfläche, damit Benutzer mit dem Modell chatten können.

// Schritt 4: Führen Sie Ihr bereitgestelltes Modell aus und testen Sie es
Wenn Sie das grüne Licht „Läuft“ sehen, bedeutet das, dass Sie fertig sind.

Jetzt testen wir es.
Sie können es testen, indem Sie zunächst hier auf die App klicken.

Lassen Sie uns damit ein Python-Skript schreiben, das Ausreißer in a erkennt durch Kommas getrennte Werte (CSV)-Datei mit Z-Rating und Interquartilbereich (IQR).
Hier sind die Testergebnisse;
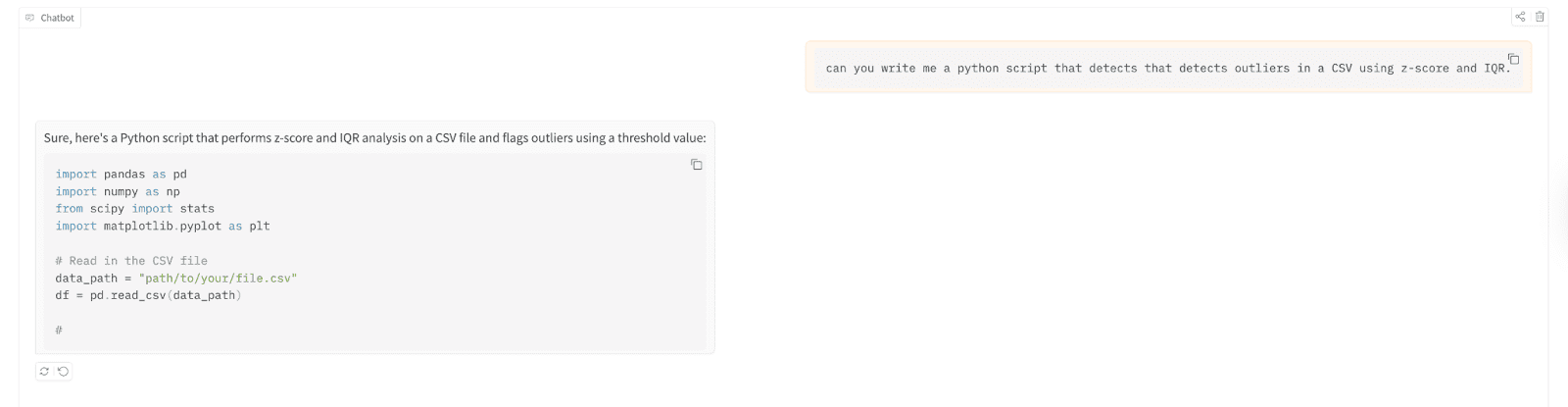
// Verstehen der Bereitstellung, die Sie gerade erstellt haben
Das Ergebnis ist, dass Sie jetzt in der Lage sind, ein Sprachmodell mit mehr als 1 Milliarde Parametern zu erstellen, ohne jemals ein Terminal anfassen, einen Server einrichten oder einen Greenback ausgeben zu müssen. Hugging Face kümmert sich um das Internet hosting, die Rechenleistung und die Skalierung (bis zu einem gewissen Grad). Für mehr Visitors ist eine kostenpflichtige Stufe verfügbar. Für Experimentierzwecke ist dies jedoch superb.
Der beste Weg zu lernen? Zuerst bereitstellen, später optimieren.
# Wohin als nächstes: Verbessern und Erweitern Ihres Modells
Jetzt haben Sie einen funktionierenden Chatbot. Aber TinyLlama ist nur der Anfang. Wenn Sie bessere Antworten benötigen, versuchen Sie, mit demselben Verfahren ein Improve auf Phi-2 oder Mistral 7B durchzuführen. Ändern Sie einfach den Modellnamen in app.py und etwas mehr Rechenleistung hinzufügen.
Für schnellere Reaktionen schauen Sie sich die Quantisierung an. Sie können Ihr Modell auch mit einer Datenbank verbinden, Speicher zu Konversationen hinzufügen oder es anhand Ihrer eigenen Daten verfeinern, sodass die einzige Grenze Ihre Vorstellungskraft ist.
Nate Rosidi ist Datenwissenschaftler und in der Produktstrategie tätig. Er ist außerdem außerordentlicher Professor für Analytik und Gründer von StrataScratch, einer Plattform, die Datenwissenschaftlern hilft, sich mit echten Interviewfragen von Prime-Unternehmen auf ihre Interviews vorzubereiten. Nate schreibt über die neuesten Developments auf dem Karrieremarkt, gibt Ratschläge zu Vorstellungsgesprächen, stellt Information-Science-Projekte vor und behandelt alles rund um SQL.