Wir interagieren jeden Tag mit LLMs.
Wir schreiben Eingabeaufforderungen, fügen Dokumente ein, führen lange Gespräche fort und erwarten, dass sich das Modell an das erinnert, was wir zuvor gesagt haben. Wenn das der Fall ist, machen wir weiter. Wenn dies nicht der Fall ist, wiederholen wir uns oder gehen davon aus, dass etwas schief gelaufen ist.
Was die meisten Menschen selten bedenken, ist, dass jede Antwort durch etwas eingeschränkt wird, das als Kontextfenster bezeichnet wird. Es entscheidet im Stillen, wie viel von Ihrer Eingabeaufforderung das Modell sehen kann, wie lange ein Gespräch kohärent bleibt und warum ältere Informationen plötzlich wegfallen.
Jedes große Sprachmodell verfügt über ein Kontextfenster, doch die meisten Benutzer erfahren nie, was es ist oder warum es wichtig ist. Dennoch spielt es eine entscheidende Rolle dabei, ob ein Mannequin kurze Chats, lange Dokumente oder komplexe mehrstufige Aufgaben bewältigen kann.
In diesem Artikel werden wir untersuchen, wie das Kontextfenster funktioniert, wie es sich in modernen LLMs unterscheidet und warum das Verständnis davon die Artwork und Weise verändert, wie Sie Sprachmodelle aufrufen, auswählen und verwenden.
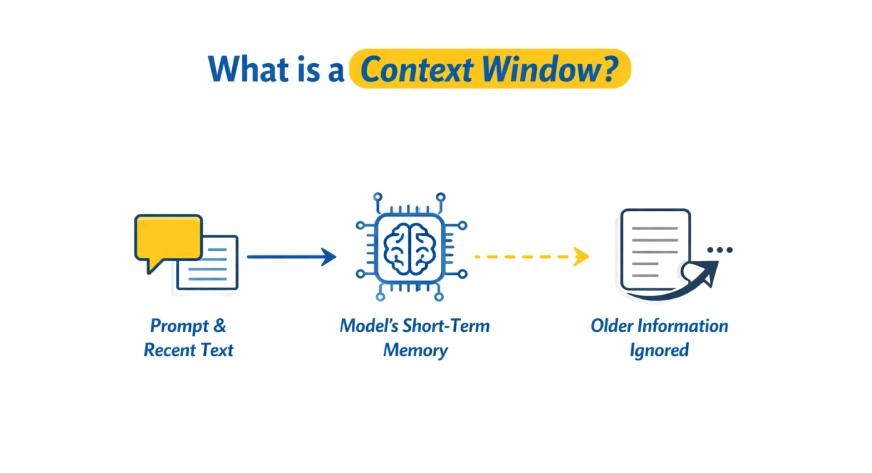
Was ist ein Kontextfenster?
Ein Kontextfenster ist die maximale Textmenge, die ein Sprachmodell gleichzeitig lesen und sich merken kann, während es eine Antwort generiert. Es fungiert als Kurzzeitgedächtnis des Modells, einschließlich der Aufforderung und des letzten Gesprächs. Sobald das Restrict überschritten wird, werden ältere Informationen ignoriert oder vergessen.
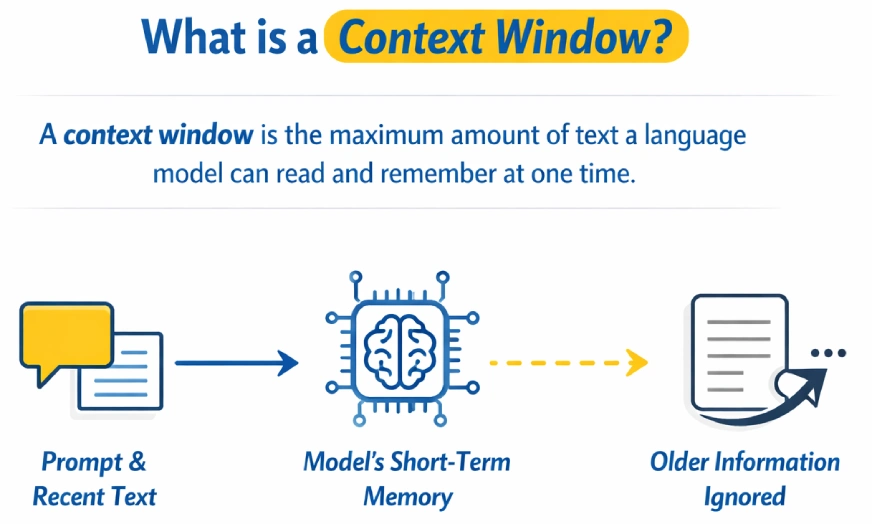
Warum ist die Größe des Kontextfensters wichtig?
Das Kontextfenster bestimmt, wie viele Informationen ein Sprachmodell gleichzeitig verarbeiten und begründen kann.
Kleinere Kontextfenster erzwingen das Abschneiden von Eingabeaufforderungen oder Dokumenten, wodurch häufig die Kontinuität unterbrochen wird und wichtige Particulars verloren gehen. Größere Kontextfenster ermöglichen es dem Modell, mehr Informationen gleichzeitig zu speichern, was die Argumentation bei langen Gesprächen, Dokumenten oder Codebasen erleichtert.
Stellen Sie sich das Kontextfenster als Arbeitsspeicher des Modells vor. Alles, was außerhalb der aktuellen Eingabeaufforderung liegt, wird praktisch vergessen. Größere Fenster tragen dazu bei, mehrstufige Überlegungen und lange Dialoge beizubehalten, während kleinere Fenster dazu führen, dass frühere Informationen schnell verblassen.
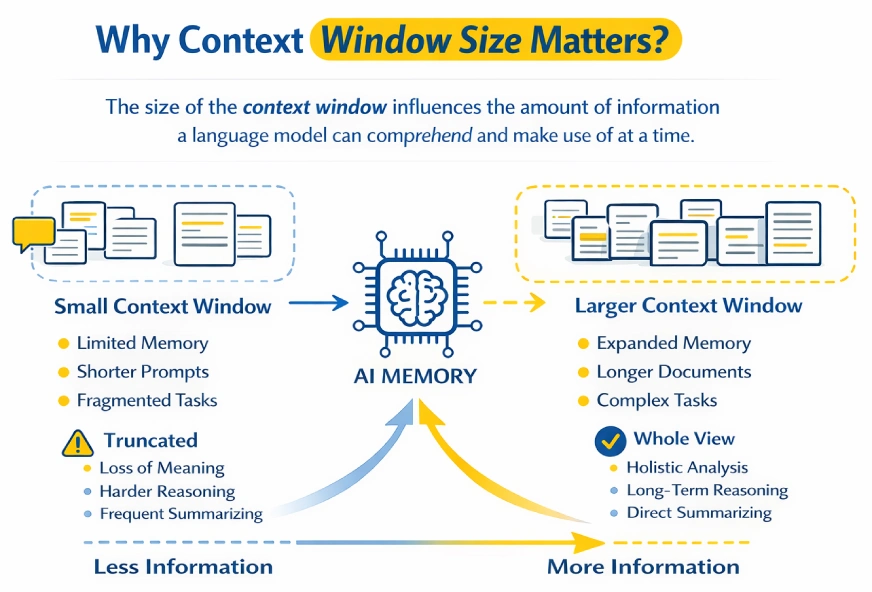
Aufgaben wie das Analysieren langer Berichte oder das Zusammenfassen großer Dokumente in einem Durchgang werden mit größeren Kontextfenstern möglich. Sie bringen jedoch Nachteile mit sich: höhere Rechenkosten, langsamere Antworten und potenzielles Rauschen, wenn irrelevante Informationen einbezogen werden.
Der Schlüssel liegt im Gleichgewicht. Stellen Sie genügend Kontext zur Verfügung, um die Aufgabe zu begründen, aber achten Sie darauf, dass die Eingaben fokussiert und related bleiben.
Lesen Sie auch: Immediate Engineering Information 2026
Kontextfenstergrößen in verschiedenen LLMs
Die Größe der Kontextfenster variiert stark große Sprachmodelle und sind mit neueren Generationen schnell gewachsen. Frühe Modelle waren auf nur wenige tausend Token beschränkt, was sie auf kurze Eingabeaufforderungen und kleine Dokumente beschränkte.
Moderne Modelle unterstützen viel größere Kontextfenster und ermöglichen so ausführliches Denken, Analysen auf Dokumentebene und ausgedehnte Gespräche mit mehreren Runden innerhalb einer einzigen Interaktion. Diese Steigerung hat die Fähigkeit eines Modells, die Kohärenz über komplexe Aufgaben hinweg aufrechtzuerhalten, erheblich verbessert.
Die folgende Tabelle fasst die häufig gemeldeten Kontextfenstergrößen für beliebte Modellfamilien zusammen OpenAIAnthropic, Google und Meta.
Beispiele für Kontextfenstergrößen
| Modell | Organisation | Kontextfenstergröße | Notizen |
|---|---|---|---|
| GPT-3 | OpenAI | ~2.048 Token | Frühe Technology; sehr begrenzter Kontext |
| GPT-3.5 | OpenAI | ~4.096 Token | Standardmäßiges frühes ChatGPT-Restrict |
| GPT-4 (Grundlinie) | OpenAI | Bis zu ~32.768 Token | Größerer Kontext als GPT-3.5 |
| GPT-4o | OpenAI | 128.000 Token | Weit verbreitetes Lengthy-Context-Modell |
| GPT-4.1 | OpenAI | ~1.000.000+ Token | Large Unterstützung für erweiterten Kontext |
| GPT-5.1 | OpenAI | ~128.000–196.000 Token | Flaggschiff der nächsten Technology mit verbesserter Argumentation |
| Claude 3,5 / 3,7 Sonett | Anthropisch | 200.000 Token | Starke Stability zwischen Geschwindigkeit und langem Kontext |
| Claude 4,5 Sonett | Anthropisch | ~200.000 Token | Verbesserte Argumentation durch großes Fenster |
| Claude 4,5 Opus | Anthropisch | ~200.000 Token | Hochwertiges Claude-Modell |
| Gemini 3 / Gemini 3 Professional | Google DeepMind | ~1.000.000 Token | Branchenführende Kontextlänge |
| Kimi K2 | Moonshot-KI | ~256.000 Token | Großer Kontext, starke, lange Argumentation |
| LLaMA 3.1 | Meta | ~128.000 Token | Erweiterter Kontext für Open-Supply-Modelle |
Vorteile und Nachteile größerer Kontextfenster
Vorteile
- Unterstützt weitaus längere Eingaben, egal ob vollständige Dokumente, lange Konversationen oder große Codebasen.
- Verbessert die Konnektivität mehrstufiger Argumentation und längerer Gespräche.
- Ermöglicht die gleichzeitige Ausführung komplizierter Aufgaben wie die Analyse langer Berichte oder ganzer Bücher.
- Eliminiert die Notwendigkeit von Chunking-, Zusammenfassungs- oder externen Abrufsystemen.
- Hilft dabei, Antworten auf einen vorgegebenen Referenztext zu stützen, der Halluzinationen verringern kann.
Kompromisse
- Erhöht die Kosten, Latenz und API-Nutzungskosten.
- Es erweist sich als ineffizient, wenn ein breiter Kontext angewendet wird, obwohl er nicht erforderlich ist.
- Der Wert von Angeboten sinkt, wenn das Schüchterne irrelevante oder laute Informationen enthält.
- Kann zu Verwirrung oder Inkonsistenz führen, wenn in langen Eingaben widersprüchliche Particulars enthalten sind.
- Bei sehr langen Aufforderungen kann es zu Aufmerksamkeitsproblemen kommen, z. B. Informationen, die nicht in der Mitte hervorgehoben werden.
In der Praxis sind die größeren Kontextfenster leistungsfähiger und effektiver, wenn sie mit einer konzentrierten, qualitativ hochwertigen Eingabe anstelle der standardmäßigen maximalen Länge kombiniert werden.
Lesen Sie auch: Was ist ein Modellkollaps? Beispiele, Ursachen und Lösungen
Wie wirkt sich das Kontextfenster auf wichtige Anwendungsfälle aus?
Da das Kontextfenster die Menge an Informationen einschränkt, die ein Modell zu einem bestimmten Zeitpunkt anzeigen kann, hat es großen Einfluss darauf, was das Modell ohne zusätzliche Instruments oder Problemumgehungen erreichen kann.
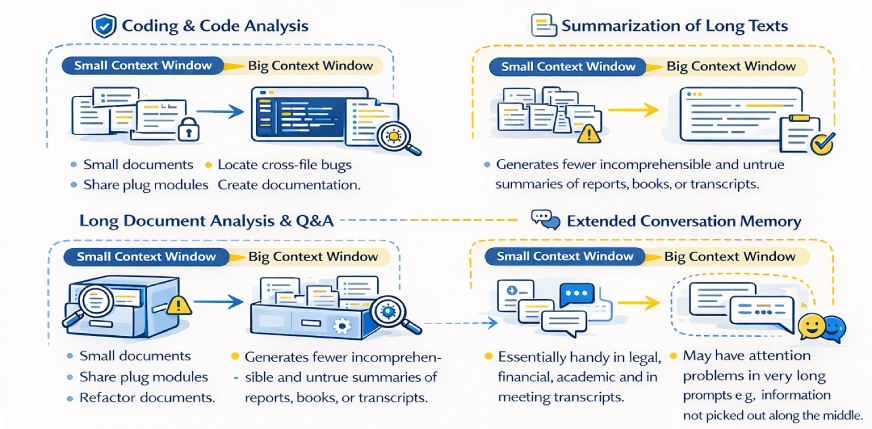
Codierung und Codeanalyse
- Die Kontextfenster sind klein, wodurch das Modell auf eine einzelne Datei oder eine Handvoll Funktionen gleichzeitig beschränkt ist.
- Das Modell ist sich der größeren Codebasis nicht bewusst, es sei denn, sie wird angegeben.
- Große Kontextfenster ermöglichen die Anzeige von zwei oder mehr Dateien oder Repositorys.
- Ermöglicht systemweite Aufgaben wie das Refactoring von Modulen, das Auffinden von dateiübergreifenden Fehlern und das Erstellen von Dokumentation.
- Eliminiert manuelles Chunking oder den wiederholten Austausch von Codefragmenten.
- Bei sehr großen Projekten ist weiterhin eine Selektivität erforderlich, um Lärm und Kontextverschwendung zu vermeiden.
Zusammenfassung langer Texte
- Minimale Fenster ermöglichen die Aufteilung und Zusammenfassung von Dokumenten in Fragmenten.
- Kleine Zusammenfassungen neigen dazu, die globale Struktur und wichtige Beziehungen zu verlieren.
- Große Kontextfenster ermöglichen eine Zusammenfassung ganzer Dokumente in einem Durchgang.
- Erzeugt weniger unverständliche und unwahre Zusammenfassungen von Berichten, Büchern oder Transkripten.
- Im Wesentlichen praktisch für juristische, finanzielle, akademische und Besprechungsprotokolle.
- Der Kompromiss besteht darin, mehr zu bezahlen und bei großen Eingaben langsamer zu verarbeiten.
Lange Dokumentenanalyse und Fragen und Antworten
- Kleine Fenster erfordern Abrufsysteme oder eine manuelle Abschnittsauswahl.
- Riesige Fenster bieten die Möglichkeit, komplette Dokumente abzufragen oder mehrere Dokumente zu öffnen.
- Ermöglicht auch Querverweise auf Informationen, die sich an entfernten Standorten befinden.
- Gilt für Verträge, Forschungsarbeiten, Richtlinien und Wissensdatenbanken.
- Vereinfacht Pipelines durch Vermeidung der Verwendung von Such- und Chunking-Logik.
- Auch wenn es unter mehrdeutigen Anleitungen und nicht zusammenhängenden Eingabemöglichkeiten nicht möglich ist, genau zu sein, kann die Genauigkeit dennoch verbessert werden.
Erweiterter Gesprächsspeicher
- Chatbots haben kleine Fenstergrößen, was dazu führt, dass frühere Abschnitte einer langen Konversation vergessen werden.
- Wenn der Kontext verschwindet, muss der Benutzer Informationen wiederholen oder neu formulieren.
- Der Gesprächsverlauf ist länger und dauert in großen Kontextfenstern länger.
- Ermöglicht eine weniger roboterhafte, natürlichere und persönlichere Kommunikation.
- Intestine geeignet für Help-Chats, gemeinsames Schreiben und langwieriges Brainstorming.
- Ein größerer Speicher geht mit einer höheren Nutzung von Token sowie mit Kosten bei der Nutzung langer Chats einher.
Lesen Sie auch: Wie funktioniert das LLM-Gedächtnis?
Abschluss
Das Kontextfenster definiert, wie viele Informationen ein Sprachmodell gleichzeitig verarbeiten kann und fungiert als sein Kurzzeitgedächtnis. Modelle mit größeren Kontextfenstern bewältigen lange Konversationen, große Dokumente und komplexen Code effektiver, während kleinere Fenster Probleme haben, wenn die Eingaben zunehmen.
Allerdings erhöhen größere Kontextfenster auch die Kosten und die Latenz und helfen nicht, wenn die Eingabe unnötige Informationen enthält. Die richtige Kontextgröße hängt von der Aufgabe ab: Kleine Fenster eignen sich intestine für schnelle oder einfache Aufgaben, während größere Fenster besser für tiefgreifende Analysen und ausführliche Überlegungen geeignet sind.
Wenn Sie das nächste Mal eine Eingabeaufforderung schreiben, beziehen Sie nur den Kontext ein, den das Modell tatsächlich benötigt. Mehr Kontext ist wirkungsvoll, aber fokussierter Kontext funktioniert am besten.
Häufig gestellte Fragen
A. Wenn das Kontextfenster überschritten wird, beginnt das Modell, ältere Teile der Eingabe zu ignorieren. Dies kann dazu führen, dass es frühere Anweisungen vergisst, den Überblick über das Gespräch verliert oder inkonsistente Antworten liefert.
A. Nein. Während größere Kontextfenster dem Modell ermöglichen, mehr Informationen zu verarbeiten, verbessern sie nicht automatisch die Ausgabequalität. Wenn die Eingabe irrelevante oder verrauschte Informationen enthält, kann es tatsächlich zu Leistungseinbußen kommen.
A. Wenn Ihre Aufgabe lange Dokumente, ausgedehnte Konversationen, Codebasen mit mehreren Dateien oder komplexe mehrstufige Überlegungen umfasst, ist ein größeres Kontextfenster hilfreich. Für kurze Fragen, einfache Eingabeaufforderungen oder schnelle Aufgaben reichen in der Regel kleinere Fenster aus.
A. Ja. Größere Kontextfenster erhöhen die Token-Nutzung, was zu höheren Kosten und langsameren Antwortzeiten führt. Aus diesem Grund ist die standardmäßige Verwendung des maximal verfügbaren Kontexts oft ineffizient.
Hallo, ich bin Janvi, ein leidenschaftlicher Knowledge-Science-Fanatic, der derzeit bei Analytics Vidhya arbeitet. Meine Reise in die Welt der Daten begann mit einer tiefen Neugier, wie wir aus komplexen Datensätzen aussagekräftige Erkenntnisse gewinnen können.
Melden Sie sich an, um weiterzulesen und von Experten kuratierte Inhalte zu genießen.