Liquid AI hat LFM2.5-1.2B-Pondering veröffentlicht, ein Argumentationsmodell mit 1,2 Milliarden Parametern, das vollständig auf dem Gerät läuft und in etwa 900 MB auf ein modernes Telefon passt. Was vor zwei Jahren ein Rechenzentrum erforderte, kann jetzt offline auf Verbraucherhardware ausgeführt werden, wobei der Schwerpunkt auf strukturierten Argumentationsspuren, Werkzeugnutzung und Mathematik statt auf allgemeinem Chat liegt.
Place in der LFM2.5-Familie und Kernspezifikationen
LFM2.5-1.2B-Pondering ist Teil der LFM2.5-Familie von Liquid Basis-Modellen, die die frühere LFM2-Architektur um mehr Vortraining und mehrstufiges Verstärkungslernen für den Edge-Einsatz erweitert.
Das Modell ist nur für Textual content und für allgemeine Zwecke mit der folgenden Konfiguration konzipiert:
- 1,17B-Parameter, gemeldet als 1,2B-Klassenmodell
- 16 Schichten, mit 10 doppelt geschlossenen LIV-Faltungsblöcken und 6 GQA-Blöcken
- Trainingsbudget von 28T-Tokens
- Kontextlänge von 32.768 Token
- Wortschatzgröße von 65.536
- 8 Sprachen, Englisch, Arabisch, Chinesisch, Französisch, Deutsch, Japanisch, Koreanisch, Spanisch
Schlussfolgerung des ersten Verhaltens und Denkspuren
Die Variante „Denken“ wird speziell für das logische Denken trainiert. Zum Zeitpunkt der Schlussfolgerung erzeugt es interne Denkspuren vor der endgültigen Antwort. Diese Spuren sind Ketten von Zwischenschritten, die das Modell verwendet, um Werkzeugaufrufe zu planen, Teilergebnisse zu überprüfen und mehrstufige Anweisungen abzuarbeiten.
Das Liquid AI-Group empfiehlt dieses Modell für Agentenaufgaben, Datenextraktionspipelines und Abruf-Augmented-Generierungsabläufe, bei denen Sie explizite Begründungen und überprüfbare Zwischenschritte benötigen. Eine praktische Möglichkeit, darüber nachzudenken: Sie verwenden LFM2.5-1.2B-Pondering als Planungsgehirn in Agenten und Instruments und verwenden andere Modelle, wenn Sie umfassendes Weltwissen benötigen oder programmintensive Arbeitsabläufe benötigen.
Benchmarks im Vergleich zu anderen Modellen der 1B-Klasse
Das Liquid AI-Group bewertet LFM2.5-1.2B-Pondering anhand von Modellen rund um 1B-Parameter anhand einer Reihe von Argumentations- und Anleitungs-Benchmarks.

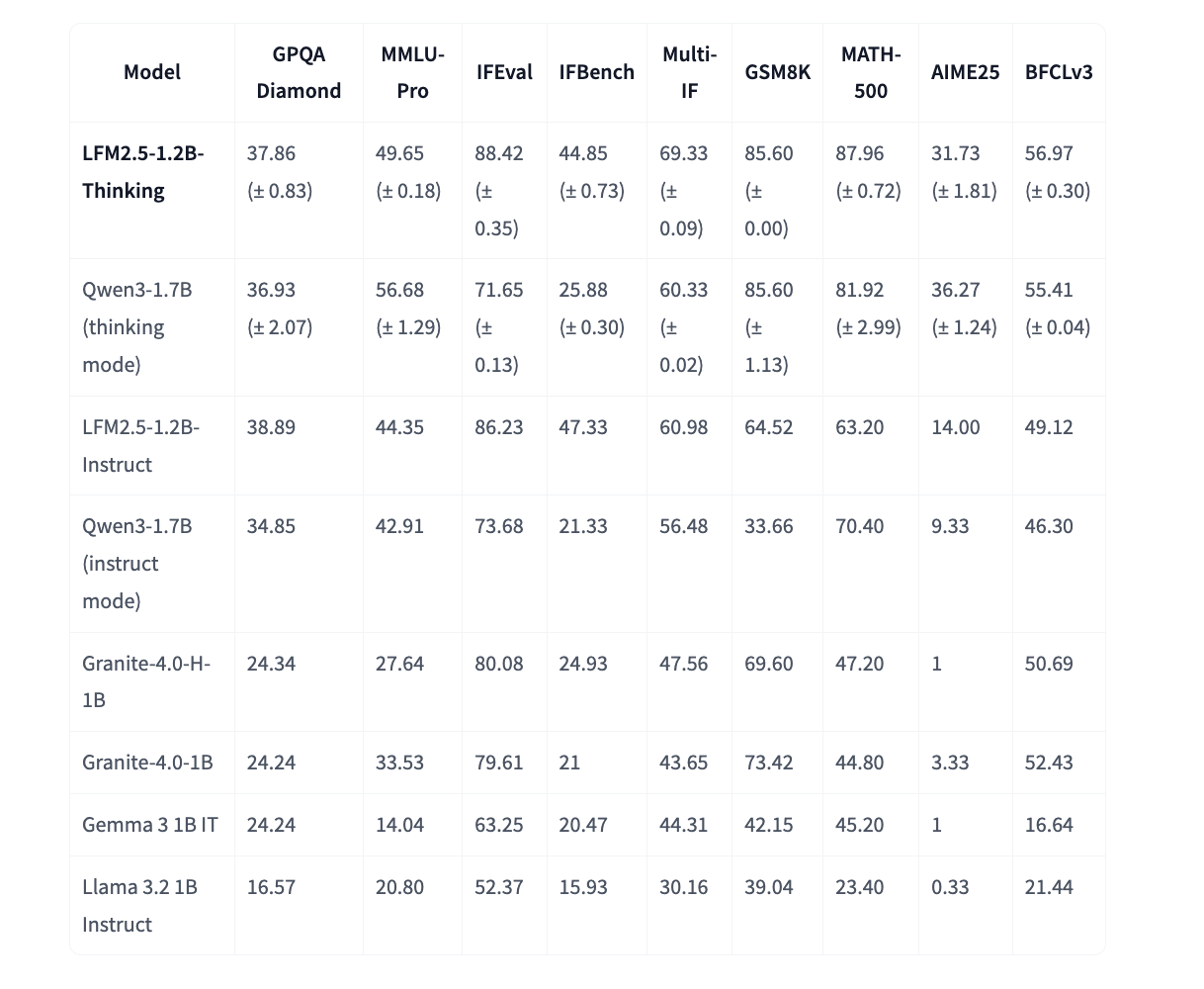
Im Vergleich zu LFM2.5-1.2B-Instruct verbessern sich drei Metriken stark, das mathematische Denken steigt von etwa 63 auf 88 bei MATH 500, das Befolgen von Anweisungen steigt von etwa 61 auf 69 bei Multi IF und die Werkzeugnutzung steigt von etwa 49 auf 57 bei BFCLv3.
LFM2.5-1.2B-Pondering konkurriert im Denkmodus bei den meisten Reasoning-Benchmarks mit Qwen3-1.7B und verwendet im Durchschnitt etwa 40 Prozent weniger Parameter und weniger Ausgabetoken. Es übertrifft auch andere Basislinien der 1B-Klasse wie Granite-4.0-H-1B, Granite-4.0-1B, Gemma-3-1B-IT und Llama-3.2-1B Instruct bei vielen dieser Aufgaben.
Trainingsrezept und Doom-Looping-Abschwächung
Argumentationsmodelle leiden häufig unter einem Doom-Looping, bei dem das Modell Fragmente seiner Gedankenkette wiederholt, anstatt die Antwort zu Ende zu bringen. LFM2.5-1.2B-Pondering nutzt eine mehrstufige Trainingspipeline, um dies zu reduzieren.
Der Prozess beginnt mitten im Coaching, das Argumentationsspuren einschließt, sodass das Modell ein Muster „Erst Grund, dann Antwort“ lernt. Anschließend verbessert eine überwachte Feinabstimmung der synthetischen Ketten die Erzeugung von Gedankenketten. Danach werden Präferenzausrichtung und RLVR angewendet. Bei der Präferenzausrichtung generiert das Forschungsteam professional Eingabeaufforderung fünf temperaturgetastete Kandidaten und einen gierigen Kandidaten und verwendet einen LLM-Richter, um bevorzugte und abgelehnte Ausgaben auszuwählen, während gleichzeitig Schleifenausgaben explizit gekennzeichnet werden. Beim RLVR fügen sie zu Beginn des Trainings eine Wiederholungsstrafe von n Gramm hinzu. Dies reduziert die Doom-Loop-Charge von 15,74 Prozent in der Mitte des Trainings auf 0,36 Prozent nach RLVR bei einer Reihe repräsentativer Eingabeaufforderungen.
Das Ergebnis ist ein kleines Argumentationsmodell, das Denkspuren erzeugen kann, ohne in langen, sich wiederholenden Ausgaben hängen zu bleiben, was für interaktive Agenten und auf der Geräte-UX wichtig ist.
Inferenzleistung und {Hardware}-Footprint
Ein wichtiges Designziel ist schnelle Inferenz mit geringem Speicherbedarf auf CPUs und NPUs. LFM2.5-1.2B-Pondering kann mit etwa 239 Token professional Sekunde auf einer AMD-CPU und etwa 82 Token professional Sekunde auf einer mobilen NPU dekodieren, während es unter 1 GB Arbeitsspeicher läuft, mit umfassender Unterstützung für llama.cpp, MLX und vLLM vom ersten Tag an.
Die detaillierte Hardwaretabelle verwendet 1K-Vorfüllung und 100 Dekodierungstokens und gibt die folgenden Beispiele für LFM2.5-1.2B-Pondering

Diese Zahlen zeigen, dass das Modell problemlos unter 1 GB auf Telefonen und eingebetteten Geräten Platz findet und dabei auch bei langen Kontexten einen brauchbaren Durchsatz aufrechterhält.
Wichtige Erkenntnisse
- LFM2.5-1.2B-Pondering ist ein 1,17-B-Parameter-Argumentationsmodell mit 32.768 Kontextlängen und läuft unter 1 GB auf Telefonen und Laptops.
- Das Modell ist für explizite Denkspuren, Agenten-Workflows, Datenextraktion und RAG optimiert.
- Es erreicht starke Werte für ein Modell der 1B-Klasse, zum Beispiel 87,96 bei MATH 500, 85,60 bei GSM8K und eine konkurrenzfähige Leistung mit Qwen3 1.7B im Denkmodus mit weniger Parametern.
- Die Trainingspipeline verwendet Midtraining mit Argumentationsspuren, überwachter Feinabstimmung, Präferenzausrichtung mit 5 Stichproben und 1 gierigen Kandidaten und RLVR mit n-Gramm-Strafen, wodurch Doom-Loops von 15,74 Prozent auf 0,36 Prozent reduziert werden.
- Das Modell läuft effizient auf AMD- und Qualcomm-NPUs und -CPUs mit Laufzeiten wie llama.cpp, FastFlowLM und NexaML, ist in den Formaten GGUF, ONNX und MLX verfügbar und kann einfach von Hugging Face für die Bereitstellung auf dem Gerät geladen werden.
Internet hosting-Anbieter/Bereitstellung
Sie können über die folgenden Anbieter und Plattformen auf das Modell zugreifen oder es hosten:
Cloud- und API-Anbieter
Modellrepositorys (Selbsthosting)
Wenn Sie das Modell lokal oder auf Ihrer eigenen Infrastruktur ausführen möchten, stehen die Gewichte in verschiedenen Formaten zur Verfügung:
Der Beitrag Liquid AI veröffentlicht LFM2.5-1.2B-Pondering: ein 1,2B Parameter Reasoning-Modell, das auf weniger als 1 GB auf dem Gerät passt erschien zuerst auf MarkTechPost.