
Die Wahl eines Datenkennzeichnungsmodells sieht auf dem Papier einfach aus: Stellen Sie ein Staff ein, nutzen Sie eine Crowd oder lagern Sie es an einen Anbieter aus. In der Praxis handelt es sich um eine der Entscheidungen mit der größten Hebelwirkung, die Sie treffen werden – denn die Kennzeichnung wirkt sich aus Modellgenauigkeit, Iterationsgeschwindigkeit und die Menge an Engineering-Zeit, die Sie für Nacharbeiten aufwenden müssen.
Organisationen stellen häufig Probleme bei der Kennzeichnung fest nach Die Modellleistung ist enttäuschend – und dann ist die Zeit bereits versunken.
Was ein „Datenkennzeichnungsansatz“ wirklich bedeutet
Viele Groups definieren den Ansatz als wo die Etikettierer sitzen (in Ihrem Büro, auf einer Plattform oder bei einem Händler). Eine bessere Definition ist:
Datenkennzeichnungsansatz = Menschen + Prozess + Plattform.
- Menschen: Fachkompetenz, Schulung und Verantwortlichkeit
- Verfahren: Richtlinien, Stichproben, Audits, Beurteilung und Änderungsmanagement
- Plattform: Instruments, Aufgabendesign, Analysen und Workflow-Kontrollen (einschließlich Human-in-the-Loop-Mustern)
Wenn Sie nur „Menschen“ optimieren, können Sie immer noch durch schlechte Prozesse verlieren. Auch wenn Sie nur Werkzeuge kaufen, vergiften inkonsistente Richtlinien Ihren Datensatz.
Schnellvergleichstabelle (die Government-Ansicht)
Analogie: Stellen Sie sich die Etikettierung wie eine Restaurantküche vor.
- Inhouse baut Ihre eigene Küche und bildet Köche aus.
- Crowdsourcing bedeutet, bei tausend heimischen Küchen gleichzeitig zu bestellen.
- Beim Outsourcing wird ein Catering-Unternehmen mit standardisierten Rezepten, Private und Qualitätssicherung eingestellt.
Die beste Wahl hängt davon ab, ob Sie ein „Signature Dish“ (Domänennuance) oder „hohen Durchsatz“ (Skala) benötigen und wie teuer Fehler sind.
Interne Datenkennzeichnung: Vor- und Nachteile
Wenn Inhouse glänzt
Eigene Etikettierung ist am stärksten, wenn Sie es brauchen strenge Kontrolle, tiefer Kontext und schnelle Iterationsschleifen zwischen Etikettierern und Modellbesitzern.
Typische Finest-Match-Situationen:
- Hochsensible Daten (reguliert, proprietär oder kundenvertraulich)
- Komplexe Aufgaben, die Fachwissen erfordern (medizinische Bildgebung, juristisches NLP, spezialisierte Ontologien)
- Langlebige Programme, bei denen der Aufbau interner Fähigkeiten mit der Zeit zunimmt
Die Kompromisse, die Sie spüren werden
Der Aufbau eines kohärenten internen Kennzeichnungssystems ist insbesondere für Startups teuer und zeitaufwändig. Häufige Schmerzpunkte:
- Rekrutierung, Schulung und Bindung von Etikettierern
- Entwerfen von Richtlinien, die auch bei der Weiterentwicklung von Projekten konsistent bleiben
- Instrument-Lizenzierungs-/Construct-Kosten (und der Betriebsaufwand für die Ausführung des Instrument-Stacks)
Realitätscheck: Die „wahren Kosten“ der unternehmensinternen Arbeit sind nicht nur die Löhne, sondern die Ebene des Betriebsmanagements: Qualitätssicherung, Umschulung, Entscheidungsbesprechungen, Workflow-Analysen und Sicherheitskontrollen.
Crowdsourcing-Datenkennzeichnung: Vor- und Nachteile
Wenn Crowdsourcing Sinn macht
Crowdsourcing kann äußerst effektiv sein, wenn:
- Beschriftungen sind relativ einfach (Klassifizierung, einfache Begrenzungsrahmen, grundlegende Transkription).
- Sie benötigen schnell eine große Menge an Etikettierkapazität
- Sie führen frühe Experimente durch und möchten die Machbarkeit testen, bevor Sie sich auf ein größeres Betriebsmodell festlegen
Die „Pilot-First“-Idee: Betrachten Sie Crowdsourcing als Lackmustest vor der Skalierung.
Wo Crowdsourcing scheitern kann
Zwei Risiken dominieren:
- Qualitätsvarianz (verschiedene Arbeitnehmer interpretieren Richtlinien unterschiedlich)
- Reibungspunkte zwischen Sicherheit und Compliance (Sie verteilen Daten weiter, oft über mehrere Gerichtsbarkeiten hinweg)
Aktuelle Forschungen zum Thema Crowdsourcing zeigen, wie Qualitätskontrollstrategien und Datenschutz sich gegenseitig beeinträchtigen können, insbesondere in großen Umgebungen.
Ausgelagerte Datenkennzeichnungsdienste: Vor- und Nachteile
Was Sie durch Outsourcing tatsächlich gewinnen
Ein verwalteter Anbieter möchte Folgendes liefern:
- Eine geschulte Belegschaft (häufig überprüft und geschult)
- Wiederholbare Produktionsabläufe
- Integrierte QA-Ebenen, Werkzeuge und Durchsatzplanung
Höhere Konsistenz als Crowdsourcing, geringerer interner Construct-Aufwand als intern.
Die Kompromisse
Outsourcing kann Folgendes einführen:
- Anlaufzeit zur Abstimmung von Richtlinien, Beispielen, Randfällen und Akzeptanzmetriken
- Geringeres internes Lernen (Ihr Staff entwickelt möglicherweise nicht so schnell eine Instinct für Anmerkungen)
- Anbieterrisiko: Sicherheitslage, Personalkontrollen und Prozesstransparenz
Wenn Sie auslagern, sollten Sie Ihren Anbieter wie eine Erweiterung Ihres ML-Groups behandeln – mit klaren SLAs, QA-Metriken und Eskalationspfaden.
Das Spielbuch zur Qualitätskontrolle
Wenn Sie sich aus diesem Artikel nur an eine Sache erinnern, machen Sie es so:
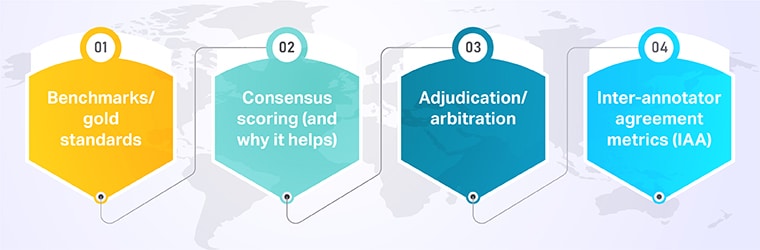
Qualität entsteht nicht am Ende – sie wird in den Arbeitsablauf integriert.
Hier sind die Qualitätsmechanismen, die immer wieder in glaubwürdigen Werkzeugdokumenten und Fallstudien aus der Praxis auftauchen:
1. Benchmarks/Goldstandards
Labelbox beschreibt „Benchmarking“ als die Verwendung einer Goldstandardreihe zur Bewertung der Etikettengenauigkeit.
So verwandeln Sie „sieht intestine aus“ in messbare Akzeptanz.
2. Konsensbewertung (und warum sie hilft)
Bei der Konsensbewertung werden mehrere Anmerkungen zu demselben Component verglichen, um die Übereinstimmung abzuschätzen.
Dies ist besonders nützlich, wenn Aufgaben subjektiv sind (Gefühl, Absicht, medizinische Befunde).
3. Entscheidung/Schiedsverfahren
Wenn Meinungsverschiedenheiten zu erwarten sind, benötigen Sie einen Tie-Break-Prozess. Shaips Fallstudie zur klinischen Annotation bezieht sich ausdrücklich auf die doppelte Abstimmung und Schlichtung, um die Qualität unter Volumen aufrechtzuerhalten.
4. Inter-Annotator-Vereinbarungsmetriken (IAA)
Für technische Groups sind IAA-Metriken wie Cohens Kappa/Fleiss‘ Kappa gängige Methoden zur Quantifizierung der Zuverlässigkeit. Beispielsweise werden in einem medizinischen Segmentierungspapier der US-amerikanischen Nationwide Library of Medication die Kappa-basierte Übereinstimmungsbewertung und verwandte Methoden erörtert.
Checkliste für Sicherheit und Zertifizierung
Wenn Sie Daten außerhalb Ihres internen Perimeters senden, wird Sicherheit zum Auswahlkriterium und nicht zur Fußnote.
Zwei weithin referenzierte Frameworks zur Anbietersicherung sind:
- ISO/IEC 27001 (Informationssicherheitsmanagementsysteme)
- SOC 2 (Kontrollen bezüglich Sicherheit, Verfügbarkeit, Verarbeitungsintegrität, Vertraulichkeit, Datenschutz)
Für eine tiefergehende Lektüre können Sie sich auf Folgendes beziehen:
Was man Verkäufer fragen sollte
- Wer kann auf Rohdaten zugreifen und wie wird der Zugriff gewährt/entzogen?
- Werden Daten im Ruhezustand/bei der Übertragung verschlüsselt?
- Werden Etikettierer überprüft, geschult und überwacht?
- Gibt es eine rollenbasierte Zugriffskontrolle und Audit-Protokollierung?
- Können wir einen maskierten/minimierten Datensatz ausführen (nur das, was für die Aufgabe benötigt wird)?
Ein pragmatischer Entscheidungsrahmen
Nutzen Sie diese fünf Fragen als schnellen Filter:
- Wie sensibel sind die Daten?
Bei hoher Sensibilität lieber firmenintern oder einen Anbieter mit nachweisbaren Kontrollen (Zertifizierungen + Prozesstransparenz) beauftragen. - Wie komplex sind die Etiketten?
Wenn Sie KMUs und eine Rechtsprechung benötigen, ist Outsourcing (verwaltet) oder Inhouse-Sourcing in der Regel besser als reines Crowdsourcing. - Benötigen Sie langfristige Leistungsfähigkeit oder kurzfristigen Durchsatz?
- Langfristig: Inhouse-Compounding kann sich lohnen
- Kurzfristig: Crowdsourcing/Anbieter kauft Geschwindigkeit
- Verfügen Sie über „Annotation Ops“-Bandbreite?
Crowdsourcing kann trügerisch Administration-lastig sein; Anbieter reduzieren diese Belastung oft. - Was kostet es, falsch zu liegen?
Wenn Etikettenfehler zu Modellausfällen in der Produktion führen, sind Qualitätskontrollen und Wiederholbarkeit wichtiger als die günstigsten Stückkosten.
Die meisten Groups landen auf einem Hybrid:
- Intern für wise und mehrdeutige Randfälle
- Anbieter/Crowd für skalierbare Basiskennzeichnung
- Eine gemeinsame QC-Ebene (Goldsätze + Beurteilung) für alles
Wenn Sie ein tieferes Objektiv im Vergleich zum Kauf bevorzugen, ist Shaip’s die richtige Wahl Kaufratgeber für Datenanmerkungen ist speziell auf Outsourcing-Entscheidungspunkte und Lieferanteneinbindung ausgelegt.
Abschluss
„Interne vs. Crowdsourcing vs. ausgelagerte Datenkennzeichnung“ ist keine philosophische Entscheidung – es ist eine betriebliche Designentscheidung. Ihr Ziel sind keine billigen Etiketten; es ist nutzbare, konsistente Grundwahrheit Lieferung in dem Tempo, das Ihr Modelllebenszyklus erfordert.
Wenn Sie jetzt Optionen prüfen, beginnen Sie mit zwei Schritten:
- Definieren Sie Ihren QS-Balken (Goldsätze + Beurteilung).
- Wählen Sie das Betriebsmodell, das diese Anforderungen zuverlässig erfüllt – ohne Ihr Engineering-Staff zu belasten.
Informationen zu produktionstauglichen Optionen und Werkzeugunterstützung finden Sie bei Shaip Datenanmerkungsdienste Und Übersicht über die Datenplattform.