
Robbyant, die verkörperte KI-Einheit innerhalb der Ant Group, verfügt über LingBot-World als Open-Supply-Lösung, ein groß angelegtes Weltmodell, das die Videogenerierung in einen interaktiven Simulator für verkörperte Agenten, autonomes Fahren und Spiele verwandelt. Das System ist darauf ausgelegt, kontrollierbare Umgebungen mit hoher visueller Wiedergabetreue, starker Dynamik und langen Zeithorizonten darzustellen und gleichzeitig reaktionsfähig genug für eine Echtzeitsteuerung zu bleiben.
Vom Textual content zum Video zum Textual content zur Welt
Die meisten Textual content-zu-Video-Modelle erzeugen kurze Clips, die realistisch aussehen, sich aber wie passive Filme verhalten. Sie modellieren nicht, wie Handlungen die Umgebung im Laufe der Zeit verändern. LingBot-World ist stattdessen als aktionsbedingtes Weltmodell aufgebaut. Es lernt die Übergangsdynamik einer virtuellen Welt, sodass Tastatur- und Mauseingaben zusammen mit Kamerabewegungen die Entwicklung zukünftiger Frames vorantreiben.
Formal lernt das Modell die bedingte Verteilung zukünftiger Video-Tokens anhand vergangener Frames, Sprachaufforderungen und diskreter Aktionen. Zur Trainingszeit werden Sequenzen mit einer Länge von bis zu etwa 60 Sekunden vorhergesagt. Zur Inferenzzeit kann es autoregressiv kohärente Videostreams mit einer Länge von etwa 10 Minuten bereitstellen und dabei die Szenenstruktur stabil halten.
Daten-Engine, vom Webvideo bis hin zu interaktiven Flugbahnen
Ein Kerndesign in LingBot-World ist eine einheitliche Daten-Engine. Es bietet umfassende, aufeinander abgestimmte Einblicke in die Artwork und Weise, wie Handlungen die Welt verändern, und deckt gleichzeitig verschiedene reale Szenen ab.
Die Datenerfassungspipeline kombiniert drei Quellen:
- Großformatige Webvideos von Menschen, Tieren und Fahrzeugen, sowohl aus der Ego- als auch aus der Third-Individual-Perspektive
- Spieldaten, bei denen RGB-Frames strikt mit Benutzersteuerungen wie W, A, S, D und Kameraparametern gekoppelt sind
- In der Unreal Engine gerenderte synthetische Flugbahnen, bei denen saubere Frames, Kamera-Intrinsics und -Extrinsics sowie Objektlayouts bekannt sind
Nach der Sammlung wird dieser heterogene Korpus in einer Profilierungsphase standardisiert. Es filtert nach Auflösung und Dauer, segmentiert Movies in Clips und schätzt fehlende Kameraparameter anhand von Geometrie- und Posenmodellen. Ein Imaginative and prescient-Language-Modell bewertet Clips nach Qualität, Bewegungsstärke und Ansichtstyp und wählt dann eine kuratierte Teilmenge aus.
Darüber hinaus baut ein hierarchisches Untertitelmodul drei Ebenen der Textüberwachung auf:
- Erzählerische Bildunterschriften für ganze Flugbahnen, einschließlich Kamerabewegungen
- Statische Szenenuntertitel, die das Umgebungslayout ohne Bewegung beschreiben
- Dichte zeitliche Untertitel für kurze Zeitfenster, die sich auf lokale Dynamiken konzentrieren
Durch diese Trennung kann das Modell die statische Struktur von Bewegungsmustern trennen, was für die Konsistenz über lange Horizonte wichtig ist.
Architektur, MoE-Video-Spine und Aktionskonditionierung
LingBot-World beginnt mit Wan2.2, einem 14B-Parameter-Bild-zu-Video-Diffusionstransformator. Dieses Spine erfasst bereits starke Open-Area-Video-Prioritäten. Das Robbyant-Workforce erweitert es zu einem DiT-Expertenmix mit 2 Experten. Jeder Experte verfügt über etwa 14B Parameter, sodass die Gesamtparameteranzahl 28B beträgt, aber bei jedem Entrauschungsschritt ist nur 1 Experte aktiv. Dadurch bleiben die Inferenzkosten ähnlich wie bei einem dichten 14B-Modell und erhöhen gleichzeitig die Kapazität.
Ein Lehrplan verlängert Trainingssequenzen von 5 Sekunden auf 60 Sekunden. Der Zeitplan erhöht den Anteil von Zeitschritten mit hohem Rauschen, was globale Layouts über lange Kontexte hinweg stabilisiert und den Moduskollaps bei langen Rollouts reduziert.
Um das Modell interaktiv zu machen, werden Aktionen direkt in die Transformatorblöcke eingefügt. Kameradrehungen werden mit Plücker-Einbettungen codiert. Tastaturaktionen werden als Multi-Sizzling-Vektoren über Tasten wie W, A, S, D dargestellt. Diese Codierungen werden zusammengeführt und durch adaptive Layer-Normalisierungsmodule geleitet, die verborgene Zustände im DiT modulieren. Nur die Aktionsadapterebenen werden fein abgestimmt, das Hauptvideo-Spine bleibt eingefroren, sodass das Modell die visuelle Qualität aus dem Vortraining beibehält und gleichzeitig die Aktionsreaktionsfähigkeit aus einem kleineren interaktiven Datensatz lernt.
Bei der Schulung werden sowohl Bild-zu-Video- als auch Video-zu-Video-Fortsetzungsaufgaben verwendet. Anhand eines einzelnen Bildes kann das Modell zukünftige Frames synthetisieren. Bei einem unvollständigen Clip kann die Sequenz verlängert werden. Dadurch entsteht eine interne Übergangsfunktion, die zu beliebigen Zeitpunkten starten kann.
LingBot World Quick, Destillation für den Echtzeiteinsatz
Das mitteltrainierte Modell, LingBot-World Base, basiert immer noch auf mehrstufiger Diffusion und vollständiger zeitlicher Aufmerksamkeit, was für Echtzeitinteraktion kostspielig ist. Das Robbyant-Workforce führt LingBot-World-Quick als beschleunigte Variante ein.
Das schnelle Modell wird vom Experten für hohes Rauschen initialisiert und ersetzt die volle zeitliche Aufmerksamkeit durch blockkausale Aufmerksamkeit. Innerhalb jedes Zeitblocks ist die Aufmerksamkeit bidirektional. Blockübergreifend ist es kausal. Dieses Design unterstützt das Caching von Schlüsselwerten, sodass das Modell Frames autoregressiv und kostengünstiger streamen kann.
Bei der Destillation kommt eine Diffusionsstrategie zum Einsatz. Der Schüler wird mit einem kleinen Satz von Zielzeitschritten, einschließlich Zeitschritt 0, trainiert, sodass er sowohl verrauschte als auch saubere latente Signale erkennt. Die Verteilungsanpassungsdestillation wird mit einem kontradiktorischen Diskriminatorkopf kombiniert. Der gegnerische Verlust aktualisiert nur den Diskriminator. Das Studentennetzwerk wird mit dem Destillationsverlust aktualisiert, was die Ausbildung stabilisiert und gleichzeitig die Handlungsfolge und die zeitliche Kohärenz bewahrt.
In Experimenten erreicht LingBot World Quick 16 Bilder professional Sekunde bei der Verarbeitung von 480p-Movies auf einem System mit 1 GPU-Knoten und hält die Finish-to-Finish-Interaktionslatenz zur Echtzeitkontrolle unter 1 Sekunde.
Emergentes Gedächtnis und Langzeitverhalten
Eine der interessantesten Eigenschaften von LingBot-World ist das entstehende Gedächtnis. Das Modell behält die globale Konsistenz ohne explizite 3D-Darstellungen wie Gaußsches Splatting bei. Wenn sich die Kamera von einem Wahrzeichen wie Stonehenge entfernt und nach etwa 60 Sekunden zurückkehrt, erscheint die Struktur wieder mit konsistenter Geometrie. Wenn ein Auto den Rahmen verlässt und später wieder betritt, erscheint es an einer physikalisch plausiblen Stelle, nicht eingefroren oder zurückgesetzt.
Das Modell kann auch extrem lange Sequenzen durchhalten. Das Forschungsteam zeigt eine kohärente Videogenerierung, die bis zu 10 Minuten dauert, mit stabilem Structure und Erzählstruktur.)
VBench-Ergebnisse und Vergleich mit anderen Weltmodellen
Zur quantitativen Auswertung verwendete das Forschungsteam VBench für einen kuratierten Satz von 100 generierten Movies, die jeweils länger als 30 Sekunden waren. LingBot-World wird mit zwei aktuellen Weltmodellen verglichen, Yume-1.5 und HY-World-1.5.
Auf VBench berichtet LingBot World:
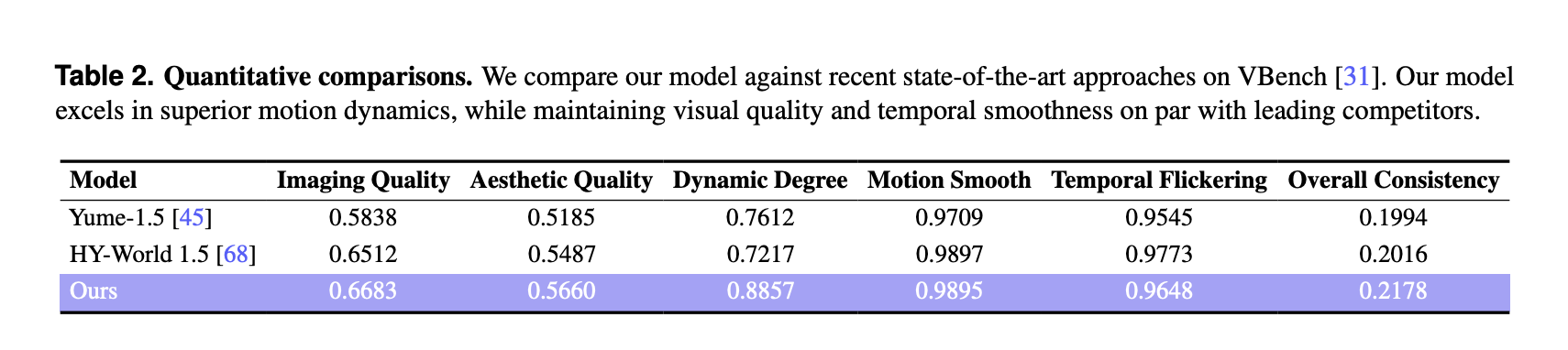
Diese Werte sind höher als beide Basiswerte für Bildqualität, ästhetische Qualität und Dynamikgrad. Der dynamische Gradspielraum ist groß, 0,8857 im Vergleich zu 0,7612 und 0,7217, was auf reichhaltigere Szenenübergänge und komplexere Bewegungen hinweist, die auf Benutzereingaben reagieren. Bewegungsglätte und zeitliches Flimmern sind mit der besten Basislinie vergleichbar und die Methode erreicht die beste Gesamtkonsistenzmetrik unter den drei Modellen.
Ein separater Vergleich mit anderen interaktiven Systemen wie Matrix-Recreation-2.0, Mirage-2 und Genie-3 zeigt, dass LingBot-World eines der wenigen vollständig Open-Supply-Weltmodelle ist, das allgemeine Domänenabdeckung, langen Generationshorizont, hohen Dynamikgrad, 720p-Auflösung und Echtzeitfähigkeiten kombiniert.

Anwendungen, aufforderungsfähige Welten, Agenten und 3D-Rekonstruktion
Über die Videosynthese hinaus ist LingBot-World als Testumgebung für verkörperte KI positioniert. Das Modell unterstützt aufrufbare Weltereignisse, bei denen Textanweisungen im Laufe der Zeit das Wetter, die Beleuchtung oder den Stil ändern oder lokale Ereignisse wie Feuerwerk oder sich bewegende Tiere einspeisen und gleichzeitig die räumliche Struktur bewahren.
Es kann auch nachgelagerte Aktionsagenten trainieren, beispielsweise mit einem kleinen Imaginative and prescient-Language-Aktionsmodell wie Qwen3-VL-2B, das Kontrollrichtlinien anhand von Bildern vorhersagt. Da die generierten Videostreams geometrisch konsistent sind, können sie als Eingabe für 3D-Rekonstruktionspipelines verwendet werden, die stabile Punktwolken für Innen-, Außen- und synthetische Szenen erzeugen.
Wichtige Erkenntnisse
- LingBot-World ist ein aktionsbedingtes Weltmodell, das Textual content-zu-Video in eine Textual content-zu-Welt-Simulation erweitert, wobei Tastaturaktionen und Kamerabewegungen Video-Rollouts über einen langen Horizont von bis zu etwa 10 Minuten direkt steuern.
- Das System basiert auf einer einheitlichen Daten-Engine, die Webvideos, Spielprotokolle mit Aktionsbezeichnungen und Unreal Engine-Trajektorien sowie hierarchische Erzählungen, statische Szenen und dichte zeitliche Untertitel kombiniert, um Structure und Bewegung zu trennen.
- Das Kernrückgrat ist eine 28B-Parametermischung aus Experten-Diffusionstransformator, aufgebaut aus Wan2.2, mit 2 Experten von jeweils 14B und Aktionsadaptern, die fein abgestimmt sind, während das visuelle Rückgrat eingefroren bleibt.
- LingBot-World-Quick ist eine destillierte Variante, die blockkausale Aufmerksamkeit, Diffusionserzwingung und Verteilungsanpassungsdestillation nutzt, um etwa 16 Bilder professional Sekunde bei 480p auf einem GPU-Knoten zu erreichen, mit einer gemeldeten Finish-to-Finish-Latenz von weniger als 1 Sekunde für die interaktive Nutzung.
- Auf VBench mit 100 generierten Movies, die länger als 30 Sekunden sind, meldet LingBot-World die höchste Bildqualität, ästhetische Qualität und den höchsten Dynamikgrad unter Yume-1.5 und HY-World-1.5, und das Modell zeigt ein Emergenzgedächtnis und eine stabile Fernstruktur, die für verkörperte Agenten und 3D-Rekonstruktion geeignet ist.
Schauen Sie sich das an Papier, Repo, Projektseite Und Modellgewichte. Sie können uns auch gerne weiter folgen Twitter und vergessen Sie nicht, bei uns mitzumachen 100.000+ ML SubReddit und Abonnieren Unser E-newsletter. Warten! Bist du im Telegram? Jetzt können Sie uns auch per Telegram kontaktieren.