
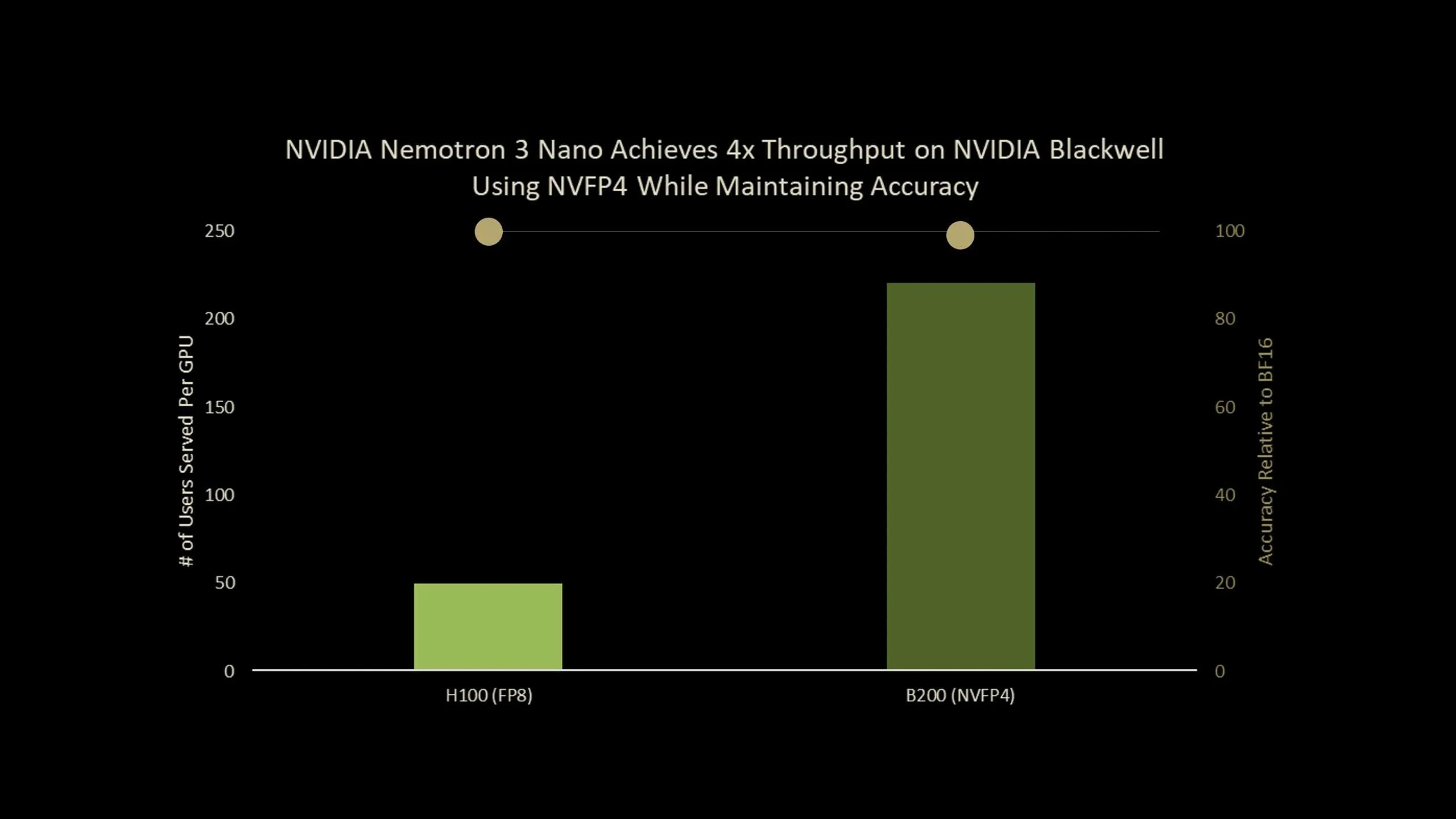
NVIDIA hat veröffentlicht Nemotron-Nano-3-30B-A3B-NVFP4ein Produktionskontrollpunkt, der ein 30B-Parameter-Argumentationsmodell ausführt 4-Bit-NVFP4 Format bei gleichzeitiger Beibehaltung der Genauigkeit nahe der BF16-Basislinie. Das Modell kombiniert einen Hybrid Mamba2 Transformer Expertenmischung Architektur mit a Quantisierungsbewusste Destillation (QAD) Rezept, das speziell für die NVFP4-Bereitstellung entwickelt wurde. Insgesamt handelt es sich um eine hocheffiziente NVFP4-Präzisionsversion von Nemotron-3-Nano, die einen bis zu viermal höheren Durchsatz beim Blackwell B200 bietet.
Was ist Nemotron-Nano-3-30B-A3B-NVFP4?
Nemotron-Nano-3-30B-A3B-NVFP4 ist eine quantisierte Model von Nemotron-3-Nano-30B-A3B-BF16vom NVIDIA-Crew von Grund auf als einheitliches Argumentations- und Chat-Modell trainiert. Es ist als gebaut Hybrid Mamba2 Transformer MoE Netzwerk:
- Insgesamt 30B Parameter
- 52 Schichten tief
- 23 Mamba2- und MoE-Schichten
- 6 gruppierte Abfrageaufmerksamkeitsebenen mit 2 Gruppen
- Jede MoE-Schicht verfügt über 128 weitergeleitete Experten und 1 gemeinsamen Experten
- Professional Token sind 6 Experten aktiv, was etwa 3,5 Milliarden aktive Parameter professional Token ergibt
Das Modell ist vorab trainiert 25T-Token mit a Aufwärmstabiler Zerfall Lernratenplan mit einer Stapelgröße von 3072, einer Spitzenlernrate von 1e-3 und einer minimalen Lernrate von 1e-5.
Nach dem Coaching folgt eine dreistufige Pipeline:
- Überwachte Feinabstimmung zu synthetischen und kuratierten Daten für Code, Mathematik, Naturwissenschaften, Werkzeugaufruf, Befehlsfolge und strukturierte Ausgaben.
- Verstärkungslernen mit synchronem GRPO über mehrstufige Software-Nutzung, Multi-Flip-Chat und strukturierte Umgebungen sowie RLHF mit einem generativen Belohnungsmodell.
- Quantisierung nach dem Coaching zu NVFP4 mit FP8 KV-Cache und einem selektiven hochpräzisen Structure, gefolgt von QAD.
Der NVFP4-Checkpoint behält die Aufmerksamkeitsschichten und die Mamba-Schichten, die in sie eingespeist werden, in BF16, quantisiert die verbleibenden Schichten auf NVFP4 und verwendet FP8 für den KV-Cache.
NVFP4-Format und warum es wichtig ist?
NVFP4 ist ein 4-Bit-Gleitkomma Format, das sowohl für Coaching als auch für Inferenz auf aktuellen NVIDIA-GPUs entwickelt wurde. Die Haupteigenschaften von NVFP4:
- Im Vergleich zu FP8 liefert NVFP4 2- bis 3-fach höherer Rechendurchsatz.
- Es reduziert den Speicherverbrauch um etwa 1,8-fach für Gewichte und Aktivierungen.
- Es erweitert MXFP4 durch Reduzierung der Blockgröße von 32 bis 16 und stellt vor zweistufige Skalierung.
Die zweistufige Skalierung verwendet E4M3-FP8 skaliert professional Block und a FP32-Skala professional Tensor. Die kleinere Blockgröße ermöglicht es dem Quantisierer, sich an lokale Statistiken anzupassen, und die doppelte Skalierung erhöht den Dynamikbereich, während der Quantisierungsfehler niedrig bleibt.
Für sehr große LLMs einfach Quantisierung nach dem Coaching (PTQ) zu NVFP4 liefert bei allen Benchmarks bereits eine ordentliche Genauigkeit. Bei kleineren Modellen, insbesondere solchen mit hohem Portoaufkommen, stellt das Forschungsteam fest, dass PTQ Ursachen hat nicht zu vernachlässigende Genauigkeitseinbußenwas eine auf Coaching basierende Erholungsmethode motiviert.
Von QAT zu QAD
Customary Quantisierungsbewusstes Coaching (QAT) fügt eine Pseudoquantisierung in den Vorwärtsdurchlauf ein und verwendet diese wieder ursprünglicher Aufgabenverlustwie zum Beispiel die Kreuzentropie des nächsten Tokens. Dies funktioniert intestine für Faltungsnetzwerke. Das Forschungsteam nennt jedoch zwei Hauptprobleme für moderne LLMs:
- Komplexe mehrstufige Submit-Coaching-Pipelines mit SFT, RL und Modellzusammenführung sind schwer zu reproduzieren.
- Ursprüngliche Trainingsdaten für offene Modelle sind oft nicht in öffentlicher Kind verfügbar.
Quantisierungsbewusste Destillation (QAD) ändert das Ziel anstelle der gesamten Pipeline. Ein gefrorenes Das Modell BF16 fungiert als Lehrer und das NVFP4-Modell ist ein Scholar. Coaching minimiert KL-Divergenz zwischen ihren Ausgabe-Token-Verteilungen, nicht das ursprünglich überwachte oder RL-Ziel.
Das Forschungsteam hebt drei Eigenschaften von QAD hervor:
- Es richtet das quantisierte Modell genauer auf den hochpräzisen Lehrer aus als QAT.
- Es bleibt auch dann stabil, wenn der Lehrer bereits mehrere Phasen durchlaufen hat, wie z. B. überwachte Feinabstimmung, verstärkendes Lernen und Modellzusammenführung, da QAD nur versucht, das endgültige Verhalten des Lehrers anzupassen.
- Es funktioniert mit partiellen, synthetischen oder gefilterten Daten, da zur Abfrage von Lehrer und Schüler nur Eingabetext erforderlich ist, nicht die ursprünglichen Bezeichnungen oder Belohnungsmodelle.
Benchmarks zu Nemotron-3-Nano-30B
Nemotron-3-Nano-30B-A3B ist eines der RL-schweren Modelle in der QAD-Forschung. Die folgende Tabelle zeigt die Genauigkeit von AA-LCR, AIME25, GPQA-D, LiveCodeBench-v5 und SciCode-TQ, NVFP4-QAT und NVFP4-QAD.

Wichtige Erkenntnisse
- Nemotron-3-Nano-30B-A3B-NVFP4 ist ein 30B-Parameter-Hybrid-Mamba2-Transformer-MoE-Modell Das läuft in 4-Bit-NVFP4 mit FP8-KV-Cache und einem kleinen Satz von BF16-Schichten, die aus Stabilitätsgründen erhalten bleiben, während etwa 3,5 Milliarden aktive Parameter professional Token beibehalten werden und Kontextfenster bis zu 1 Million Token unterstützt werden.
- NVFP4 ist ein 4-Bit-Gleitkommaformat mit Blockgröße 16 und zweistufiger Skalierungunter Verwendung von E4M3-FP8-pro-Block-Skalen und einer FP32-pro-Tensor-Skala, was einen etwa zwei- bis dreimal höheren arithmetischen Durchsatz und etwa 1,8-mal niedrigere Speicherkosten als FP8 für Gewichte und Aktivierungen ergibt.
- Quantization Conscious Distillation (QAD) ersetzt den ursprünglichen Aufgabenverlust durch KL-Divergenz zu einem eingefrorenen BF16-Lehrersodass der NVFP4-Schüler direkt mit der Ausgabeverteilung des Lehrers übereinstimmt, ohne die vollständige SFT-, RL- und Modellzusammenführungspipeline erneut abzuspielen oder die ursprünglichen Belohnungsmodelle zu benötigen.
- Mit der neuen Quantization Conscious Distillation-Methode erreicht die NVFP4-Model bis zu 99,4 % Genauigkeit von BF16
- Bei AA-LCR, AIME25, GPQA-D, LiveCodeBench und SciCode zeigt NVFP4-PTQ einen spürbaren Genauigkeitsverlust und NVFP4-QAT verschlechtert sich weiterwährend NVFP4-QAD die Leistung auf nahezu BF16-Niveau wiederherstellt und den Abstand bei diesen Argumentations- und Codierungs-Benchmarks auf nur wenige Punkte reduziert.
Schauen Sie sich das an Papier Und Modellgewichte. Sie können uns auch gerne weiter folgen Twitter und vergessen Sie nicht, bei uns mitzumachen 100.000+ ML SubReddit und Abonnieren Unser Publication. Warten! Bist du im Telegram? Jetzt können Sie uns auch per Telegram kontaktieren.