
NVIDIA hat VIBETENSOR veröffentlicht, einen Open-Supply-Software program-Stack für Forschungssysteme für Deep Studying. VIBETENSOR wird von LLM-gestützten Kodierungsagenten unter hochrangiger menschlicher Anleitung generiert.
Das System stellt eine konkrete Frage: Können Codierungsagenten eine kohärente Deep-Studying-Laufzeit generieren, die Python- und JavaScript-APIs bis hin zu C++-Laufzeitkomponenten und CUDA-Speicherverwaltung umfasst, und diese nur durch Instruments validieren?
Architektur vom Frontend bis zur CUDA-Laufzeit
VIBETENSOR implementiert eine Keen-Tensor-Bibliothek im PyTorch-Stil mit einem C++20-Kern für CPU und CUDA, einem Torch-ähnlichen Python-Overlay über Nanobind und einer experimentellen Node.js/TypeScript-Schnittstelle. Es zielt über CUDA auf Linux x86_64- und NVIDIA-GPUs ab und Builds ohne CUDA werden absichtlich deaktiviert.
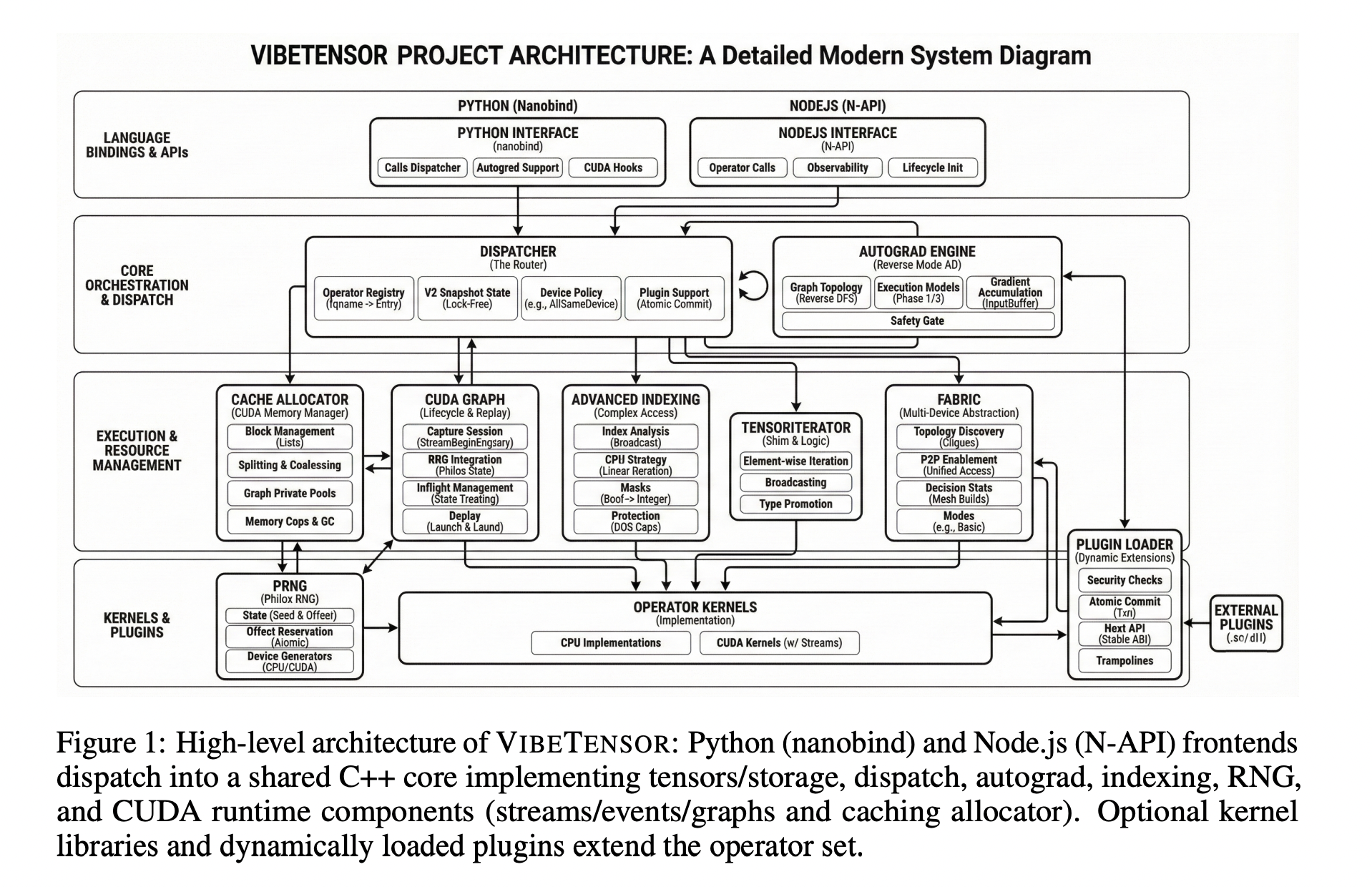
Der Kernstapel umfasst ein eigenes Tensor- und Speichersystem, einen Schema-Lite-Dispatcher, eine Reverse-Mode-Autograd-Engine, ein CUDA-Subsystem mit Streams, Ereignissen und CUDA-Graphen, einen Stream-geordneten Caching-Allokator mit Diagnose und ein stabiles C-ABI für dynamisch geladene Operator-Plugins. Frontends in Python und Node.js teilen sich einen C++-Dispatcher, eine Tensor-Implementierung, eine Autograd-Engine und eine CUDA-Laufzeit.
Das Python-Overlay macht a verfügbar vibetensor.torch Namespace mit Tensorfabriken, Operator Dispatch und CUDA-Dienstprogrammen. Das Node.js-Frontend basiert auf der Node-API und konzentriert sich auf die asynchrone Ausführung, wobei Employee-Scheduling mit Einschränkungen für gleichzeitige Inflight-Arbeiten verwendet wird, wie in den Implementierungsabschnitten beschrieben.
Auf der Laufzeitebene TensorImpl stellt eine Ansicht über referenzgezählt dar Storagemit Größen, Schritten, Speicheroffsets, Dtype, Gerätemetadaten und einem gemeinsamen Versionszähler. Dies unterstützt nicht zusammenhängende Ansichten und Aliasing. A TensorIterator Das Subsystem berechnet Iterationsformen und pro-Operanden-Schritte für elementweise und Reduktionsoperatoren, und die gleiche Logik wird durch die Plugin-ABI verfügbar gemacht, sodass externe Kernel denselben Aliasing- und Iterationsregeln folgen.
Der Dispatcher ist Schema-Lite. Es ordnet Operatornamen Implementierungen über CPU- und CUDA-Dispatch-Schlüssel hinweg zu und ermöglicht Wrapper-Layer für Autograd- und Python-Überschreibungen. Geräterichtlinien erzwingen Invarianten wie „alle Tensor-Eingaben auf demselben Gerät“ und lassen gleichzeitig Raum für spezielle Richtlinien für mehrere Geräte.
Autograd, CUDA-Subsystem und Multi-GPU-Cloth
Autograd im umgekehrten Modus verwendet Knoten- und Kantendiagrammobjekte und einen Tensor AutogradMeta. Beim Rückwärtslauf verwaltet die Engine die Abhängigkeitsanzahl, Gradientenpuffer professional Eingabe und eine Bereitschaftswarteschlange. Bei CUDA-Tensoren werden CUDA-Ereignisse aufgezeichnet und darauf gewartet, um stromübergreifende Gradientenflüsse zu synchronisieren. Das System enthält außerdem einen experimentellen Autograd-Modus für mehrere Geräte zur Erforschung der geräteübergreifenden Ausführung.
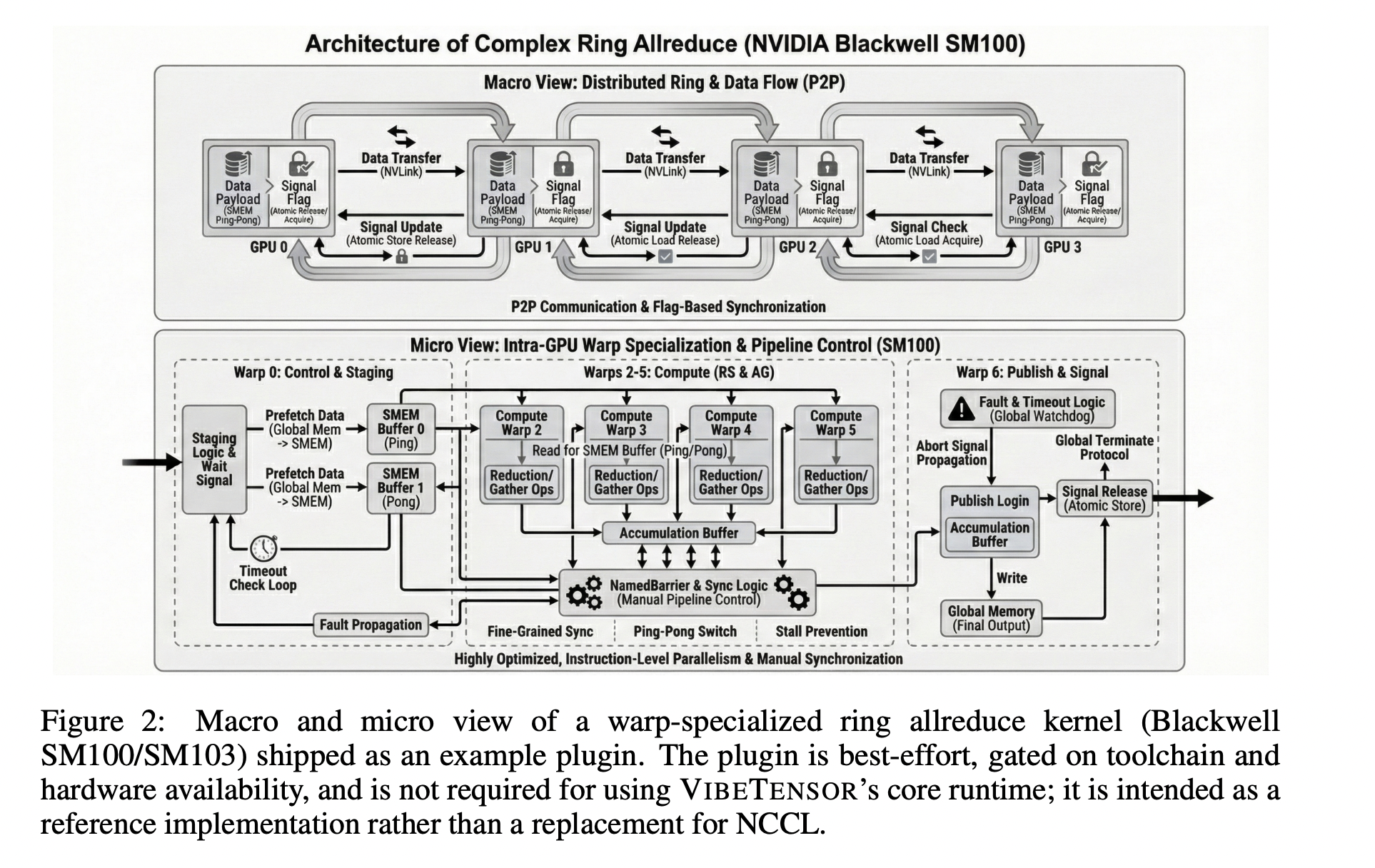
Das CUDA-Subsystem bietet C++-Wrapper für CUDA-Streams und -Ereignisse, einen Caching-Allokator mit Stream-geordneter Semantik sowie die Erfassung und Wiedergabe von CUDA-Graphen. Der Allokator umfasst Diagnosefunktionen wie Snapshots, Statistiken, Speicheranteilobergrenzen und GC-Leiter, um das Speicherverhalten bei Checks und Debugging beobachtbar zu machen. CUDA-Diagramme lassen sich in Allokator-„Diagrammpools“ integrieren, um die Speicherlebensdauer bei der Erfassung und Wiedergabe zu verwalten.
Das Cloth-Subsystem ist eine experimentelle Multi-GPU-Schicht. Es stellt expliziten Peer-to-Peer-GPU-Zugriff über CUDA P2P und einheitliche virtuelle Adressierung bereit, wenn die Topologie dies unterstützt. Cloth konzentriert sich auf die Multi-GPU-Ausführung in einem Prozess und bietet Beobachtbarkeitsprimitive wie Statistiken und Ereignis-Snapshots anstelle eines vollständig verteilten Trainingsstapels.
Als Referenzerweiterung liefert VIBETENSOR ein Finest-Effort-CUTLASS-basiertes Ring-Allreduce-Plugin für NVIDIA-GPUs der Blackwell-Klasse aus. Dieses Plugin bindet experimentelle Ring-Allreduce-Kernel, ruft NCCL nicht auf und dient als anschauliches Beispiel, nicht als NCCL-Ersatz. Die Multi-GPU-Ergebnisse im Artikel basieren auf Cloth und diesem optionalen Plugin und werden nur für Blackwell-GPUs gemeldet.
Interoperabilität und Erweiterungspunkte
VIBETENSOR unterstützt den DLPack-Import und -Export für CPU- und CUDA-Tensoren und bietet einen C++20-Safetensors-Loader und -Saver für die Serialisierung. Zu den Erweiterbarkeitsmechanismen gehören Überschreibungen auf Python-Ebene, die von inspiriert sind torch.libraryein versioniertes C-Plugin ABI und Hooks für benutzerdefinierte GPU-Kernel, die in Triton- und CUDA-Vorlagenbibliotheken wie CUTLASS erstellt wurden. Das Plugin ABI stellt DLPack-basierte dtype- und Gerätemetadaten bereit und TensorIterator Helfer, sodass externe Kernel mit denselben Iterations- und Aliasing-Regeln wie integrierte Operatoren integriert werden.
KI-gestützte Entwicklung
VIBETENSOR wurde unter Verwendung von LLM-gestützten Codierungsagenten als Hauptcodeautoren entwickelt, die sich ausschließlich an menschlichen Spezifikationen auf hoher Ebene orientierten. Etwa zwei Monate lang definierten Menschen Ziele und Einschränkungen, dann schlugen Agenten Codeunterschiede vor und führten Builds und Checks durch, um sie zu validieren. Die Arbeit führt kein neues Agenten-Framework ein, sondern behandelt Agenten als Black-Field-Instruments, die die Codebasis unter werkzeugbasierten Prüfungen modifizieren. Die Validierung basiert auf C++-Checks (CTest), Python-Checks über Pytest und Differenzprüfungen anhand von Referenzimplementierungen wie PyTorch für ausgewählte Operatoren. Das Forschungsteam umfasst außerdem längere Trainingsregressionen sowie Allokator- und CUDA-Diagnosen, um zustandsbehaftete Fehler und Leistungspathologien zu erkennen, die in Unit-Checks nicht auftauchen.
Wichtige Erkenntnisse
- KI-generierter, CUDA-first Deep-Studying-Stack: VIBETENSOR ist eine Open-Supply-Laufzeitumgebung im PyTorch-Stil für Apache 2.0, deren Implementierungsänderungen von LLM-Coding-Brokers generiert wurden und auf Linux x86_64 mit NVIDIA-GPUs und CUDA als zwingende Anforderung abzielen.
- Vollständige Laufzeitarchitektur, nicht nur Kernel: Das System umfasst einen C++20-Tensorkern (TensorImpl/Storage/TensorIterator), einen Schema-Lite-Dispatcher, Reverse-Mode-Autograd, ein CUDA-Subsystem mit Streams, Ereignissen, Diagrammen, einen Stream-geordneten Caching-Allokator und eine versionierte C-Plugin-ABI, die über Python verfügbar gemacht wird (
vibetensor.torch) und experimentelle Node.js-Frontends. - Toolgesteuerter, agentenzentrierter Entwicklungsworkflow: Über einen Zeitraum von etwa zwei Monaten spezifizierten Menschen übergeordnete Ziele, während Agenten Diffs vorschlugen und diese über CTest, Pytest, Differentialprüfungen gegen PyTorch, Allokatordiagnose und Lengthy-Horizon-Trainingsregressionen validierten, ohne manuelle Codeüberprüfung professional Diff.
- Starke Mikrokernel-Beschleunigung, langsameres Finish-to-Finish-Coaching: KI-generierte Kernel in Triton/CuTeDSL erreichen in isolierten Benchmarks bis zu ~5–6-fache Geschwindigkeitssteigerungen gegenüber PyTorch-Basislinien, aber komplette Trainings-Workloads (Transformer-Spielzeugaufgaben, CIFAR-10 ViT, LM im MiniGPT-Stil) laufen 1,7-mal bis 6,2-mal langsamer als PyTorch, was die Lücke zwischen der Leistung auf Kernel- und Systemebene unterstreicht.
Schauen Sie sich das an Papier Und Repo hier. Sie können uns auch gerne weiter folgen Twitter und vergessen Sie nicht, bei uns mitzumachen 100.000+ ML SubReddit und Abonnieren Unser Publication. Warten! Bist du im Telegram? Jetzt können Sie uns auch per Telegram kontaktieren.
