
Bei Pandas sind Sie wahrscheinlich auf diese klassische Verwirrung gestoßen: Sollten Sie verwenden loc oder iloc Daten extrahieren? Auf den ersten Blick sehen sie quick identisch aus. Beide werden verwendet, um Zeilen oder Spalten aus einem DataFrame zu segmentieren, zu filtern und abzurufen – doch ein kleiner Unterschied in ihrer Funktionsweise kann Ihre Ergebnisse völlig verändern (oder einen Fehler auslösen, der Ihnen den Kopf verdreht).
Ich erinnere mich an das erste Mal, als ich versuchte, eine Zeile mit auszuwählen df.loc(0) und fragte mich, warum es nicht funktionierte. Der Grund? Pandas „denkt“ nicht immer in Positionen – manchmal verwendet es Bezeichnungen. Da ist das loc vs iloc Unterscheidung kommt ins Spiel.
In diesem Artikel werde ich ein einfaches Miniprojekt anhand eines kleinen Datensatzes zur Schülerleistung durchgehen. Am Ende werden Sie nicht nur den Unterschied verstehen loc Und ilocsondern wissen auch genau, wann Sie sie in Ihrer eigenen Datenanalyse verwenden müssen.
Vorstellung des Datensatzes
Der Datensatz stammt von ChatGPT. Es enthält einige grundlegende Aufzeichnungen über die Prüfungsergebnisse der Schüler. Hier ist ein Schnappschuss unseres Datensatzes
import pandas as pd
df = pd.read_csv(‘student_scores.csv’)
dfAusgabe:

Ich werde versuchen, einige Datenextraktionsaufgaben beispielsweise mit loc und iloc durchzuführen
- Extrahieren einer einzelnen Zeile aus dem DataFrame
- Einen einzelnen Wert extrahieren
- Mehrere Zeilen extrahieren
- Schneiden einer Reihe von Zeilen
- Extrahieren bestimmter Spalten und
Boolesche Filterung
Lassen Sie mich zunächst kurz erklären, was loc und iloc in Pandas sind.
Was ist loc und iloc?
Loc Und iloc sind Datenextraktionstechniken in Pandas. Sie sind sehr hilfreich bei der Auswahl von Daten aus Datensätzen.
Loc verwendet Beschriftungen, um Datensätze aus einem DataFrame abzurufen, daher finde ich es einfacher zu verwenden. Iloc hingegen sind für eine genauere Recherche von Datensätzen hilfreich, denn iloc Wählt Daten basierend auf den ganzzahligen Positionen der Zeilen und Spalten aus, ähnlich wie Sie eine Python-Liste oder ein Python-Array indizieren würden.
Aber wenn Sie wie ich sind, fragen Sie sich vielleicht. Wenn die Lokalisierung aufgrund der Zeilenbeschriftungen eindeutig einfacher ist, Warum sollte man sich die Mühe machen, iloc zu verwenden? Warum sollten Sie sich die Mühe machen, Zeilenindizes herauszufinden, insbesondere wenn Sie mit großen Datensätzen arbeiten? Hier sind ein paar Gründe.
- Häufig verfügen Datensätze nicht über übersichtliche Zeilenindizes (z. B. 101, 102, …). Stattdessen haben Sie einen einfachen Index (
0, 1, 2, …), oder Sie schreiben beim Abrufen von Datensätzen möglicherweise die Zeilenbeschriftung falsch. In diesem Fall ist die Verwendung von iloc besser geeignet. Später in diesem Artikel werden wir uns auch noch damit befassen. - In manchen Szenarien, etwa bei der Vorverarbeitung durch maschinelles Lernen, spielen Beschriftungen keine große Rolle. Es geht Ihnen nur um eine Momentaufnahme der Daten. Zum Beispiel die ersten oder letzten drei Datensätze. iloc ist in diesem Szenario wirklich hilfreich.
ilocMacht den Code kürzer und weniger anfällig, insbesondere wenn sich Beschriftungen ändern, was Ihr maschinelles Lernmodell beschädigen könnte - Viele Datensätze haben doppelte Zeilenbeschriftungen. In diesem Fall,
ilocFunktioniert immer, da Positionen eindeutig sind. - Die Quintessenz ist, dass Sie loc verwenden sollten, wenn Ihr Datensatz klare, aussagekräftige Beschriftungen hat und Sie möchten, dass Ihr Code lesbar ist.
- Verwenden Sie iloc, wenn Sie eine positionsbasierte Steuerung benötigen oder wenn Beschriftungen fehlen oder unordentlich sind.
Nachdem ich nun alles geklärt habe, finden Sie hier die grundlegende Syntax für loc und iloc:
df.loc(rows, columns)
df.iloc(rows, columns)Die Syntax ist ziemlich gleich. Versuchen wir mit dieser Syntax, einige Datensätze mithilfe von loc und iloc abzurufen.
Extrahieren einer einzelnen Zeile aus dem DataFrame
Um eine ordnungsgemäße Demonstration durchzuführen, ändern wir zunächst den Spaltenindex und machen ihn zu student_id. Derzeit führt Pandas eine automatische Indizierung durch:
# setting student_id as index
df.set_index('student_id', inplace=True)Hier ist die Ausgabe:

Sieht besser aus. Versuchen wir nun, alle Datensätze von Bob abzurufen. So gehen Sie mit loc vor:
df.loc(102)Hier gebe ich lediglich die Zeilenbezeichnung an. Dadurch sollten alle Datensätze von Bob abgerufen werden.
Hier ist die Ausgabe:
identify Bob
math 58
english 64
science 70
Title: 102, dtype: objectDas Coole daran ist, dass ich einen Drilldown durchführen kann, ein bisschen wie eine Hierarchie. Versuchen wir zum Beispiel, bestimmte Informationen über Bob abzurufen, etwa seine Punktzahl in Mathematik.
df.loc(102, ‘math’)Die Ausgabe wäre 58.
Versuchen wir es nun mit iloc. Wenn Sie mit Hear und Arrays vertraut sind, beginnt die Indizierung immer bei 0. Wenn ich additionally den ersten Datensatz im DataFrame abrufen möchte, muss ich den Index 0 angeben. In diesem Fall versuche ich Bob abzurufen, das ist die zweite Zeile in unserem DataFrame – in diesem Fall wäre der Index additionally 1.
df.iloc(1)Wir würden die gleiche Ausgabe wie oben erhalten:
identify Bob
math 58
english 64
science 70
Title: 102, dtype: objectUnd wenn ich versuche, einen Drilldown durchzuführen und die Mathematiknote von Bob abzurufen. Unser Index wäre ebenfalls 1, vorausgesetzt, dass Mathematik in der zweiten Zeile steht
df.iloc(1, 1)Die Ausgabe wäre 58.
Okay, ich kann diesen Artikel hier abschließen, aber loc und iloc bieten noch einige beeindruckendere Funktionen. Lassen Sie uns einige davon im Schnelldurchlauf durchgehen.
Mehrere Zeilen extrahieren (bestimmte Schüler)
Mit Pandas können Sie mehrere Zeilen mithilfe von loc und iloc abrufen. Ich werde eine Demonstration durchführen, indem ich die Aufzeichnungen mehrerer Schüler abrufe. In diesem Fall würden wir, anstatt einen einzelnen Wert in unserer loc/iloc-Methode zu speichern, eine Liste speichern. So können Sie das mit loc machen:
# Alice, Charlie and Edward's data
df.loc((101, 103, 105))Hier ist die Ausgabe:

Und hier erfahren Sie, wie Sie das machen iloc:
df.iloc((0, 2, 4))Wir würden die gleiche Ausgabe erhalten:

Ich hoffe, du hast den Dreh raus.
Schneiden Sie einen Zeilenbereich auf
Eine weitere hilfreiche Funktion, die Python Pandas bietet, ist die Möglichkeit, einen Bereich von Zeilen aufzuteilen. Hier können Sie Ihre Begin- und Endposition angeben. Hier ist die Syntax für das Loc/Iloc-Slicing:
df.loc(start_label:end_label)In locAllerdings wäre die Endbezeichnung in der Ausgabe enthalten – ganz anders als beim standardmäßigen Python-Slicing.
Die Syntax ist dieselbe für ilocmit der Ausnahme, dass die Endbezeichnung von der Ausgabe ausgeschlossen würde (genau wie beim standardmäßigen Python-Slicing).
Gehen wir ein Beispiel durch:
Ich versuche, eine Reihe von Schülerakten abzurufen. Versuchen wir es mit loc:
df.loc(101:103)Ausgabe:

Wie Sie oben sehen können, ist das Endlabel im Ergebnis enthalten. Versuchen wir es jetzt mit iloc. Wenn Sie sich erinnern, wäre der Index der ersten Zeile 0, was bedeuten würde, dass die dritte Zeile 2 wäre.
df.iloc(0:3)Ausgabe:

Hier ist die dritte Reihe ausgeschlossen. Aber wenn Sie wie ich sind (jemand, der viel hinterfragt), fragen Sie sich vielleicht: Warum soll die letzte Zeile ausgeschlossen werden? In welchen Szenarien wäre das hilfreich? Was wäre, wenn ich Ihnen sagen würde, dass es Ihr Leben tatsächlich einfacher macht? Lassen Sie uns das ganz schnell klären.
Angenommen, Sie möchten Ihren DataFrame in Blöcken zu je 100 Zeilen verarbeiten.
Wenn das Schneiden inklusive wäre, müssten Sie einige umständliche Berechnungen durchführen, um eine Wiederholung der letzten Zeile zu vermeiden.
Aber da das Schneiden ausschließlich am Ende erfolgt, können Sie dies ganz einfach tun.
df.iloc(0:100) # first 100 rows
df.iloc(100:200) # subsequent 100 rows
df.iloc(200:300) # subsequent 100 rowsHier gibt es keine Überlappungen und es gibt einheitliche Chunk-Größen. Ein weiterer Grund ist die Ähnlichkeit mit der Funktionsweise von Bereichen in Pandas. Wenn Sie einen Zeilenbereich abrufen möchten, beginnt dieser normalerweise ebenfalls bei 0 und schließt die letzte Zeile nicht ein. Die gleiche Logik beim iloc-Slicing ist wirklich hilfreich, insbesondere wenn Sie an Net-Scraping arbeiten oder eine Reihe von Zeilen durchlaufen.
Bestimmte Spalten (Subjekte) extrahieren
Gerne stelle ich Ihnen auch den Dickdarm vor : Zeichen. Dadurch können Sie alle Datensätze in Ihrem DataFrame mithilfe von loc abrufen. Ähnlich dem * in SQL. Das Coole daran ist, dass Sie eine Teilmenge von Spalten filtern und extrahieren können.
Normalerweise beginne ich hier. Ich verwende es, um mir einen Überblick über einen bestimmten Datensatz zu verschaffen. Von dort aus kann ich mit dem Filtern und Drilldown beginnen. Lassen Sie mich Ihnen zeigen, was ich meine.
Lassen Sie uns alle Datensätze abrufen:
df.loc(:)Ausgabe:

Von hier aus kann ich bestimmte Spalten auf diese Weise extrahieren. Mit Lok:
df.loc(:, (‘math’, ‘science’))Ausgabe:

Mit iloc:
df.iloc(:, (2, 4))Die Ausgabe wäre die gleiche.
Ich liebe diese Funktion, weil sie so flexibel ist. Nehmen wir an, ich möchte die Mathematik- und Naturwissenschaftsergebnisse von Alice und Bob abrufen. Es wird ungefähr so ablaufen. Ich kann einfach den Bereich der gewünschten Datensätze und Spalten angeben.
Mit loc:
df.loc(101:103, ('identify', 'math', 'science'))Ausgabe:

Mit iloc:
df.iloc(0:3, (0, 1, 3))Wir würden die gleiche Ausgabe erhalten.
Boolesche Filterung (Wer hat in Mathematik mehr als 80 Punkte erzielt?)
Die letzte Funktion, die ich mit Ihnen teilen möchte, ist die Boolesche Filterung. Dies ermöglicht eine flexiblere Extraktion. Nehmen wir an, ich möchte die Aufzeichnungen von Schülern abrufen, die in Mathematik über 80 Punkte erzielt haben. Normalerweise müssen Sie in SQL die Klauseln WHERE und HAVING verwenden. Python macht das so einfach.
# College students with Math > 80.
df.loc(df('math') > 80)Ausgabe:

Sie können auch nach mehreren Bedingungen filtern, indem Sie die Operatoren AND(&), OR(|) und NOT(~) verwenden. Zum Beispiel:
# Math > 70 and Science > 80
df.loc((df(‘math’) > 70) & (df(‘science’) > 80))Ausgabe: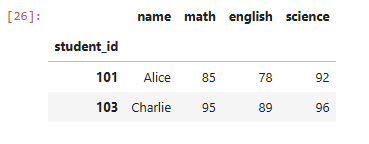 PS: Ich habe einen Artikel über das Filtern mit Pandas geschrieben. Sie können es lesen Hier
PS: Ich habe einen Artikel über das Filtern mit Pandas geschrieben. Sie können es lesen Hier
Normalerweise verwenden Sie diese Funktion mit loc. Es kann etwas kompliziert werden ilocda es keine booleschen Bedingungen unterstützt. Um dies mit iloc zu tun, müssen Sie die boolesche Filterung wie folgt in eine Liste umwandeln:
# College students with Math > 80.
df.iloc(listing(df('math') > 80))Um Kopfschmerzen zu vermeiden, machen Sie einfach mit loc.
Abschluss
Sie werden wahrscheinlich das verwenden loc Und iloc Methoden werden häufig verwendet, wenn Sie an einem Datensatz arbeiten. Daher ist es wichtig zu wissen, wie sie funktionieren, und die beiden zu unterscheiden. Ich finde es toll, wie einfach und flexibel es ist, mit diesen Methoden Datensätze zu extrahieren. Wenn Sie verwirrt sind, denken Sie daran, dass es bei loc nur um Beschriftungen geht, während es bei iloc um Positionen geht.
Ich hoffe, Sie fanden diesen Artikel hilfreich. Versuchen Sie, diese Beispiele auf Ihrem eigenen Datensatz auszuführen, um den Unterschied in der Aktion zu sehen.
Ich schreibe diese Artikel, um mein eigenes Verständnis technischer Konzepte zu testen und zu stärken – und um das, was ich lerne, mit anderen zu teilen, die möglicherweise auf dem gleichen Weg sind. Teilen Sie es gerne mit anderen. Lasst uns gemeinsam lernen und wachsen. Prost!
Sagen Sie uns gerne auf einer dieser Plattformen Hallo