Bild vom Autor
# Einführung
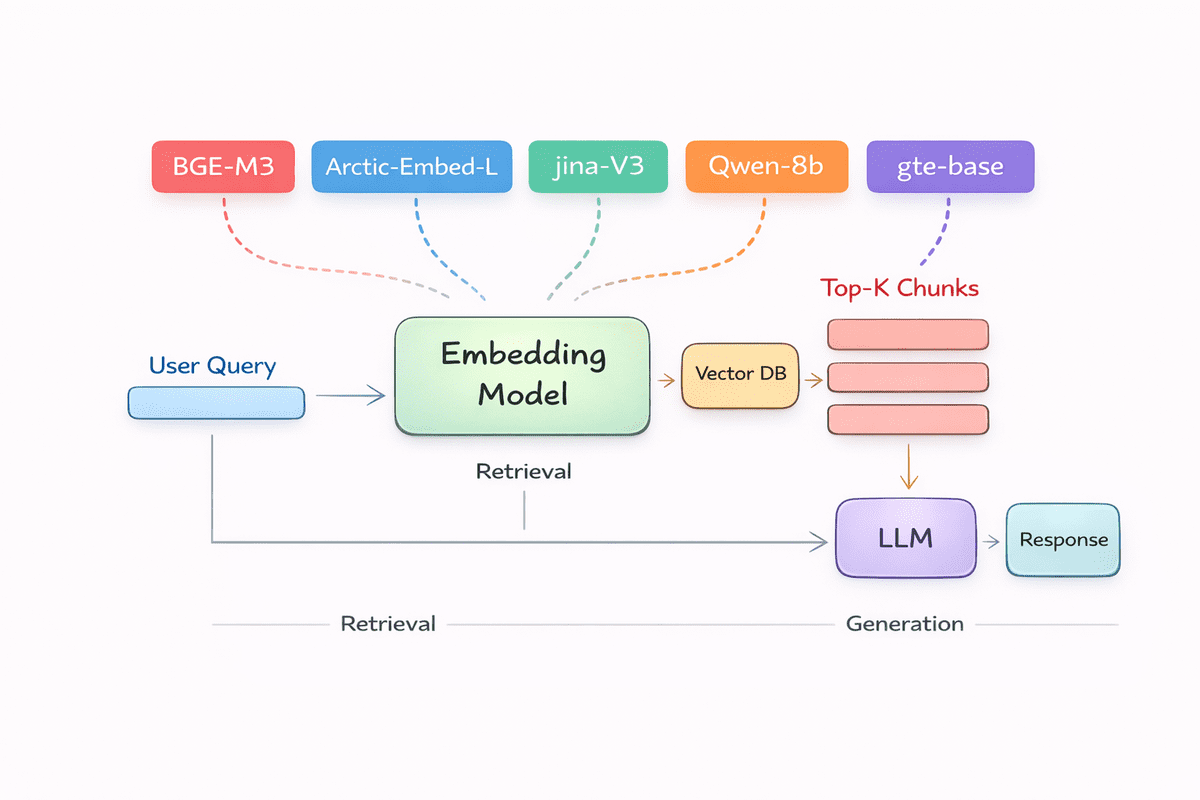
In einer RAG-Pipeline (Retrieval-Augmented Technology) bilden Einbettungsmodelle die Grundlage dafür, dass der Abruf funktioniert. Bevor ein Sprachmodell eine Frage beantworten, ein Dokument zusammenfassen oder Ihre Daten begründen kann, muss es eine Möglichkeit haben, die Bedeutung zu verstehen und zu vergleichen. Genau das tun Einbettungen.
In diesem Artikel untersuchen wir die besten Einbettungsmodelle sowohl für die rein englischsprachige als auch für die mehrsprachige Leistung, geordnet anhand eines abruforientierten Bewertungsindex. Diese Modelle erfreuen sich großer Beliebtheit, werden in realen Systemen häufig eingesetzt und liefern durchweg genaue und zuverlässige Abrufergebnisse für eine Reihe von RAG-Anwendungsfällen.
Bewertungskriterien:
- 60 Prozent Leistung: Englische Retrievalqualität und mehrsprachige Retrievalleistung
- 30 Prozent Downloads: Downloads von Hugging Face-Function-Extraktionsmodellen als Proxy für die reale Einführung
- 10 Prozent Praktikabilität: Modellgröße, Einbettungsdimensionalität und Durchführbarkeit der Bereitstellung
Das endgültige Rating bevorzugt die Einbettung von Modellen, die genau abrufen, von Groups aktiv genutzt werden und ohne excessive Infrastrukturanforderungen eingesetzt werden können.
# 1. BAAI bge-m3
BGE-M3 ist ein Einbettungsmodell, das für abruforientierte Anwendungen und RAG-Pipelines entwickelt wurde und den Schwerpunkt auf eine starke Leistung bei englischsprachigen und mehrsprachigen Aufgaben legt. Es wurde umfassend anhand öffentlicher Benchmarks evaluiert und wird häufig in realen Systemen eingesetzt, was es zu einer zuverlässigen Wahl für Groups macht, die einen genauen und konsistenten Abruf über verschiedene Datentypen und Domänen hinweg benötigen.
Hauptmerkmale:
- Einheitlicher Abruf: Kombiniert dichte, spärliche und Multi-Vektor-Abruffunktionen in einem einzigen Modell.
- Mehrsprachige Unterstützung: Unterstützt mehr als 100 Sprachen mit starker sprachübergreifender Leistung.
- Umgang mit langen Kontexten: Verarbeitet lange Dokumente mit bis zu 8192 Token.
- Bereit für die Hybridsuche: Bietet lexikalische Gewichtungen auf Token-Ebene neben dichten Einbettungen für den Hybridabruf im BM25-Stil.
- Produktionsfreundlich: Ausgewogene Einbettungsgröße und einheitliche Feinabstimmung ermöglichen eine praktische Bereitstellung im großen Maßstab.
# 2. Qwen3-Einbettung 8B
Qwen3-Embedding-8B ist ein Excessive-Finish-Einbettungsmodell aus der Qwen3-Familie, das speziell für die Texteinbettung und Rating-Workloads entwickelt wurde, die in RAG- und Suchsystemen verwendet werden. Es ist darauf ausgelegt, bei abrufintensiven Aufgaben wie Dokumentsuche, Codesuche, Clustering und Klassifizierung eine hervorragende Leistung zu erbringen, und wurde ausführlich in öffentlichen Bestenlisten bewertet, wo es zu den Spitzenmodellen für mehrsprachige Abrufqualität zählt.
Hauptmerkmale:
- Erstklassige Suchqualität: Auf Platz 1 der mehrsprachigen MTEB-Bestenliste (Stand: 5. Juni 2025) mit einer Punktzahl von 70,58
- Lange Kontextunterstützung: Verarbeitet bis zu 32.000 Token für Langtext-Abrufszenarien
- Versatile Einbettungsgröße: Unterstützt benutzerdefinierte Einbettungsmaße von 32 bis 4096
- Anleitungsbewusst: Unterstützt aufgabenspezifische Anweisungen, die normalerweise die Downstream-Leistung verbessern
- Mehrsprachig und Code-ready: Unterstützt mehr als 100 Sprachen, einschließlich starker sprachübergreifender und Code-Retrieval-Abdeckung
# 3. Snowflake Arctic Embed L v2.0
Snowflake Arctic-Embed-L-v2.0 ist ein mehrsprachiges Einbettungsmodell, das für den qualitativ hochwertigen Abruf auf Unternehmensebene entwickelt wurde. Es ist so optimiert, dass es eine starke mehrsprachige und englische Abrufleistung liefert, ohne dass separate Modelle erforderlich sind, und gleichzeitig effiziente Inferenzeigenschaften beibehält, die für Produktionssysteme geeignet sind. Arctic-Embed-L-v2.0 wurde unter der freizügigen Apache 2.0-Lizenz veröffentlicht und wurde für Groups entwickelt, die einen zuverlässigen, skalierbaren Abruf über globale Datensätze hinweg benötigen.
Hauptmerkmale:
- Mehrsprachig ohne Kompromisse: Bietet eine starke englische und nicht-englische Recherche und übertrifft viele Open-Supply- und proprietäre Modelle bei Benchmarks wie MTEB, MIRACL und CLEF
- Inferenz effizient: Verwendet einen kompakten, nicht einbettenden Parameter-Footprint für schnelle und kostengünstige Inferenz
- Kompressionsfreundlich: Unterstützt Matryoshka Illustration Studying und Quantisierung, um Einbettungen auf nur 128 Bytes bei minimalem Qualitätsverlust zu reduzieren
- Drop-in-kompatibel: Aufgebaut auf bge-m3-retromae, ermöglicht den direkten Austausch in bestehenden Einbettungsleitungen
- Lange Kontextunterstützung: Verarbeitet Eingaben von bis zu 8192 Token mithilfe der RoPE-basierten Kontexterweiterung
# 4. Jina Embeddings V3
jina-embeddings-v3 ist eines der am häufigsten heruntergeladenen Einbettungsmodelle für die Textmerkmalsextraktion auf Hugging Face und daher eine beliebte Wahl für reale Retrieval- und RAG-Systeme. Es handelt sich um ein mehrsprachiges Multitasking-Einbettungsmodell, das eine breite Palette von NLP-Anwendungsfällen unterstützt und einen starken Fokus auf Flexibilität und Effizienz legt. Aufbauend auf einem Jina XLM-RoBERTa-Spine und erweitert mit aufgabenspezifischen LoRA-Adaptern ermöglicht es Entwicklern, mithilfe eines einzigen Modells Einbettungen zu generieren, die für verschiedene Abruf- und semantische Aufgaben optimiert sind.
Hauptmerkmale:
- Aufgabenbewusste Einbettungen: Verwendet mehrere LoRA-Adapter, um aufgabenspezifische Einbettungen für den Abruf, das Clustering, die Klassifizierung und den Textabgleich zu generieren
- Mehrsprachige Berichterstattung: Unterstützt über 100 Sprachen, wobei der Fokus auf 30 wirkungsvollen Sprachen liegt, darunter Englisch, Arabisch, Chinesisch und Urdu
- Unterstützung für lange Kontexte: Verarbeitet Eingabesequenzen mit bis zu 8192 Token mithilfe von Rotary Place Embeddings
- Versatile Einbettungsgrößen: Unterstützt Matroschka-Einbettungen mit Kürzung von 32 bis 1024 Dimensionen
- Produktionsfreundlich: Weit verbreitet, einfach in Transformers und SentenceTransformers zu integrieren und unterstützt effiziente GPU-Inferenz
# 5. GTE Mehrsprachige Foundation
gte-multilingual-base ist ein kompaktes und dennoch leistungsstarkes Einbettungsmodell aus der GTE-Familie, das für den mehrsprachigen Abruf und die Textdarstellung mit langem Kontext entwickelt wurde. Der Schwerpunkt liegt auf der Bereitstellung einer hohen Abrufgenauigkeit bei gleichzeitig niedrigen {Hardware}- und Inferenzanforderungen. Dadurch eignet es sich intestine für Produktions-RAG-Systeme, die Geschwindigkeit, Skalierbarkeit und mehrsprachige Abdeckung benötigen, ohne auf große reine Decoder-Modelle angewiesen zu sein.
Hauptmerkmale:
- Starker mehrsprachiger Abruf: Erzielt hochmoderne Ergebnisse bei mehrsprachigen und mehrsprachigen Abruf-Benchmarks für Modelle ähnlicher Größe
- Effiziente Architektur: Verwendet ein reines Encoder-Transformatordesign, das eine deutlich schnellere Inferenz und geringere Hardwareanforderungen liefert
- Unterstützung für lange Kontexte: Verarbeitet Eingaben mit bis zu 8192 Token zum Abrufen langer Dokumente
- Elastische Einbettungen: Unterstützt versatile Ausgabedimensionen, um die Lagerkosten zu senken und gleichzeitig die nachgelagerte Leistung zu erhalten
- Hybrid-Abrufunterstützung: Erzeugt sowohl dichte Einbettungen als auch spärliche Tokengewichte für dichte, spärliche oder hybride Suchpipelines
# Detaillierter Vergleich der Einbettungsmodelle
Die folgende Tabelle bietet einen detaillierten Vergleich der führenden Einbettungsmodelle für RAG-Pipelines, wobei der Schwerpunkt auf der Kontextverarbeitung, der Einbettungsflexibilität, den Abruffunktionen und darauf liegt, was jedes Modell in der Praxis am besten leistet.
| Modell | Maximale Kontextlänge | Ausgabe einbetten | Abruffunktionen | Hauptstärken |
|---|---|---|---|---|
| BGE-M3 | 8.192 Token | 1.024 Dims | Dichtes, spärliches und Multi-Vektor-Abrufen | Einheitlicher Hybridabruf in einem einzigen Modell |
| Qwen3-Embedding-8B | 32.000 Token | 32 bis 4.096 Dimmungen (konfigurierbar) | Dichte Einbettungen mit anweisungsbewusstem Abruf | Höchste Abrufgenauigkeit bei langen und komplexen Abfragen |
| Arctic-Embed-L-v2.0 | 8.192 Token | 1.024 Dims (MRL komprimierbar) | Dichtes Abrufen | Hochwertige Rückholung mit starker Kompressionsunterstützung |
| jina-embeddings-v3 | 8.192 Token | 32 bis 1.024 Dims (Matroschka) | Aufgabenspezifischer dichter Abruf über LoRA-Adapter | Versatile Multitasking-Einbettungen mit minimalem Overhead |
| gte-multilingual-base | 8.192 Token | 128 bis 768 Dimmungen (elastisch) | Dichter und spärlicher Abruf | Schnelles, effizientes Abrufen mit geringen Hardwareanforderungen |
Abid Ali Awan (@1abidaliawan) ist ein zertifizierter Datenwissenschaftler, der gerne Modelle für maschinelles Lernen erstellt. Derzeit konzentriert er sich auf die Erstellung von Inhalten und das Schreiben technischer Blogs zu maschinellem Lernen und Datenwissenschaftstechnologien. Abid verfügt über einen Grasp-Abschluss in Technologiemanagement und einen Bachelor-Abschluss in Telekommunikationstechnik. Seine Imaginative and prescient ist es, ein KI-Produkt mithilfe eines graphischen neuronalen Netzwerks für Schüler mit psychischen Erkrankungen zu entwickeln.