

Bild vom Autor
# Einführung
Sie haben wahrscheinlich schon eine ganze Reihe von Information-Science- und Machine-Studying-Projekten durchgeführt.
Sie eignen sich hervorragend, um Ihre Fähigkeiten zu schärfen und zu zeigen, was Sie wissen und gelernt haben. Aber hier ist die Sache: Sie bleiben oft hinter dem zurück, was Datenwissenschaft auf Produktionsebene in der realen Welt aussieht.
In diesem Artikel nehmen wir ein Projekt – das US-Berufslohnanalyse – und verwandeln Sie es in etwas, das besagt: „Das ist bereit für den realen Einsatz.“
Dazu werden wir ein einfaches, aber solides MLOps-Setup (Machine Studying Operations) durchgehen, das alles von der Versionskontrolle bis zur Bereitstellung abdeckt.
Es eignet sich hervorragend für Datenanfänger, Freiberufler, Portfolio-Ersteller oder alle, die möchten, dass ihre Arbeit so aussieht, als ob sie aus einem professionellen Setup stammt, auch wenn dies nicht der Fall ist.
In diesem Artikel gehen wir über Pocket book-Projekte hinaus: Wir richten unsere MLOps-Struktur ein, lernen, wie man reproduzierbare Pipelines einrichtet, Artefakte modelliert, eine einfache lokale Anwendungsprogrammierschnittstelle (API), Protokollierung und schließlich, wie man nützliche Dokumentation erstellt.

Bild vom Autor
# Die Aufgabe und den Datensatz verstehen
Das Szenario für das Projekt besteht aus einem nationalen US-Datensatz, der jährliche Berufslohn- und Beschäftigungsdaten in allen 50 US-Bundesstaaten und Territorien enthält. Die Daten enthalten Einzelheiten zu Beschäftigungszahlen, Durchschnittslöhnen, Berufsgruppen, Lohnperzentilen und auch geografischen Identifikatoren.

Ihre Hauptziele sind:
- Vergleich der Lohnunterschiede in verschiedenen Bundesstaaten und Berufskategorien
- Ausführen statistischer Assessments (T-Assessments, Z-Assessments, F-Assessments)
- Erstellen Sie Regressionen, um den Zusammenhang zwischen Beschäftigung und Löhnen zu verstehen
- Visualisierung von Lohnverteilungen und Berufstrends
Einige Schlüsselspalten des Datensatzes:
OCC_TITLE— BerufsnameTOT_EMP— GesamtbeschäftigungA_MEAN— Durchschnittlicher JahreslohnPRIM_STATE— LandeskürzelO_GROUP— Berufskategorie (Hauptberuf, Gesamt, Detailliert)
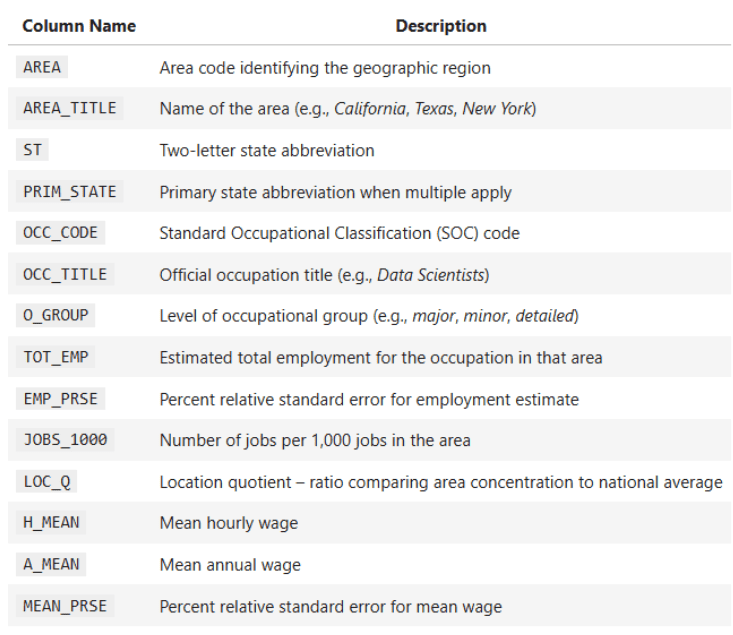
Ihre Aufgabe hier ist es, verlässliche Erkenntnisse über Lohnunterschiede, Arbeitsplatzverteilung und statistische Zusammenhänge zu gewinnen, aber das ist noch nicht alles.
Die Herausforderung besteht auch darin, das Projekt so zu strukturieren, dass es wiederverwendbar, reproduzierbar und sauber ist. Dies ist heutzutage eine sehr wichtige Fähigkeit, die für alle Datenwissenschaftler erforderlich ist.
# Beginnend mit der Versionskontrolle
Lassen Sie uns die Grundlagen nicht überspringen. Selbst kleine Projekte verdienen eine saubere Struktur und eine ordnungsgemäße Versionskontrolle. Hier ist eine Ordnereinrichtung, die sowohl intuitiv als auch für Prüfer benutzerfreundlich ist:

Einige Greatest Practices:
- Halten Sie die Rohdaten unveränderlich. Sie müssen es nicht anfassen, sondern können es einfach zur Bearbeitung kopieren.
- Erwägen Sie die Verwendung Git LFS wenn Ihre Datensätze groß und umfangreich werden.
- Behalten Sie jedes Skript bei
src/auf eine Sache konzentriert. Dein zukünftiges Ich wird es dir danken. - Engagieren Sie sich häufig und verwenden Sie klare Botschaften wie:
feat: add T-test comparability between administration and manufacturing wages.
Selbst mit dieser einfachen Struktur zeigen Sie Personalmanagern, dass Sie wie ein Profi und nicht wie ein Junior denken und planen.
# Aufbau reproduzierbarer Pipelines (und Schluss mit dem Pocket book-Chaos)
Notizbücher eignen sich hervorragend zum Erkunden. Sie probieren etwas aus, optimieren einen Filter, führen eine Zelle erneut aus, kopieren ein Diagramm, und bevor Sie es merken, haben Sie 40 Zellen und keine Ahnung, was tatsächlich zu der endgültigen Antwort geführt hat.
Damit sich dieses Projekt „produktionsmäßig“ anfühlt, nehmen wir die Logik, die bereits im Pocket book vorhanden ist, und packen sie in eine einzige Vorverarbeitungsfunktion. Diese Funktion wird zum einzigen kanonischen Ort, an dem die US-Berufslohndaten lauten:
- Aus der Excel-Datei geladen
- Bereinigt und in numerisch konvertiert
- Normalisiert (Staaten, Berufsgruppen, Berufscodes)
- Angereichert mit Hilfsspalten wie der Gesamtlohnabrechnung
Von da an wird für jede Analyse – Diagramme, T-Assessments, Regressionen, Korrelationen, Z-Assessments – derselbe bereinigte DataFrame wiederverwendet.
// Von High-of-Pocket book-Zellen zu einer wiederverwendbaren Funktion
Im Second macht das Pocket book ungefähr Folgendes:
- Lädt die Datei:
state_M2024_dl.xlsx - Analysiert das erste Blatt in einen DataFrame
- Konvertiert Spalten wie
A_MEAN,TOT_EMPzu numerisch - Verwendet diese Spalten in:
- Lohnvergleiche auf Landesebene
- Lineare Regression (
TOT_EMP→A_MEAN) - Pearson-Korrelation (Q6)
- Z-Check für Tech vs. Nicht-Tech (Q7)
- Levene-Check für Lohnvarianz
Wir werden das in eine einzelne Funktion mit dem Namen umwandeln preprocess_wage_data die Sie von überall im Projekt aufrufen können:
from src.preprocessing import preprocess_wage_data
df = preprocess_wage_data("information/uncooked/state_M2024_dl.xlsx")Jetzt sind sich Ihr Pocket book, Ihre Skripte oder Ihr zukünftiger API-Aufruf einig darüber, was „saubere Daten“ bedeutet.
// Was die Vorverarbeitungspipeline tatsächlich tut

Für diesen Datensatz führt die Vorverarbeitungspipeline Folgendes aus:
1. Laden Sie die Excel-Datei einmal.
xls = pd.ExcelFile(file_path)
df_raw = xls.parse(xls.sheet_names(0))
df_raw.head()
2. Konvertieren Sie wichtige numerische Spalten in numerische Spalten.
Dies sind die Spalten, die Ihre Analyse tatsächlich verwendet:
- Beschäftigung und Intensität:
TOT_EMP,EMP_PRSE,JOBS_1000,LOC_QUOTIENT - Lohnmaßnahmen:
H_MEAN,A_MEAN,MEAN_PRSE - Lohnperzentile:
H_PCT10,H_PCT25,H_MEDIAN,H_PCT75,H_PCT90,A_PCT10,A_PCT25,A_MEDIAN,A_PCT75,A_PCT90
Wir zwingen sie sicher:
df = df_raw.copy()
numeric_cols = (
"TOT_EMP", "EMP_PRSE", "JOBS_1000", "LOC_QUOTIENT" ….)
for col in numeric_cols:
if col in df.columns:
df(col) = pd.to_numeric(df(col), errors="coerce")Wenn eine zukünftige Datei seltsame Werte enthält (z. B. „**“ oder „N/A“), explodiert Ihr Code nicht, sondern behandelt sie einfach als fehlend und die Pipeline wird nicht unterbrochen.
3. Textbezeichner normalisieren.
Für eine konsistente Gruppierung und Filterung:
PRIM_STATEin Großbuchstaben umwandeln (z. B. „ca“ → „CA“)O_GROUPin Kleinbuchstaben umwandeln (z. B. „Dur“ → „Dur“)OCC_CODEbespannen (z.str.startswith("15")im Tech- vs. Nicht-Tech-Z-Check)
4. Fügen Sie Hilfsspalten hinzu, die in Analysen verwendet werden.
Diese sind einfach, aber praktisch. Der Helfer für die Gesamtlohnabrechnung professional Zeile ist ungefähr unter Verwendung des Durchschnittslohns:
df("TOTAL_PAYROLL") = df("A_MEAN") * df("TOT_EMP")Das Verhältnis von Lohn zu Beschäftigung ist nützlich, um Nischen mit hohem Lohn und niedriger Beschäftigung zu erkennen, mit Schutz vor Division durch Null:
df("WAGE_EMP_RATIO") = df("A_MEAN") / df("TOT_EMP").change({0: np.nan})5. Geben Sie einen sauberen DataFrame für den Relaxation des Projekts zurück.
Ihr späterer Code für:
- Darstellung der oberen/unteren Zustände
- T-Assessments (Administration vs. Produktion)
- Regression (
TOT_EMP→A_MEAN) - Korrelationen (Q6)
- Z-Assessments (Q7)
- Levenes Check
kann alles beginnen mit:
df = preprocess_wage_data("state_M2024_dl.xlsx")Vollständige Vorverarbeitungsfunktion:
Geben Sie dies ein src/preprocessing.py:
import pandas as pd
import numpy as np
def preprocess_wage_data(file_path: str = "state_M2024_dl.xlsx") -> pd.DataFrame:
"""Load and clear the U.S. occupational wage information from Excel.
- Reads the primary sheet of the Excel file.
- Ensures key numeric columns are numeric.
- Normalizes textual content identifiers (state, occupation group, occupation code).
- Provides helper columns utilized in later evaluation.
"""
# Load uncooked Excel file
xls = pd.ExcelFile(file_path)Überprüfen Sie den Relaxation des Codes Hier.
# Speichern Ihrer statistischen Modelle und Artefakte
Was sind Modellartefakte? Einige Beispiele: Regressionsmodelle, Korrelationsmatrizen, bereinigte Datensätze und Zahlen.
import joblib
joblib.dump(mannequin, "fashions/employment_wage_regression.pkl")Warum Artefakte speichern?
- Sie vermeiden die Neuberechnung von Ergebnissen während API-Aufrufen oder Dashboards
- Sie bewahren Versionen für zukünftige Vergleiche auf
- Sie halten Analyse und Schlussfolgerung getrennt
Diese kleinen Gewohnheiten machen Ihr Projekt von explorativ zu produktionsfreundlich.
# Damit es lokal funktioniert (mit einer API oder einer kleinen Internet-Benutzeroberfläche)
Sie müssen nicht direkt zu Docker und Kubernetes springen, um dies zu „bereitstellen“. Für viele reale Analysearbeiten lautet Ihre erste API einfach:
- Eine saubere Vorverarbeitungsfunktion
- Einige bekannte Analysefunktionen
- Eine kleine Skript- oder Notizbuchzelle, die sie miteinander verbindet
Das allein macht es einfach, Ihr Projekt anzurufen von:
- Noch ein Notizbuch
- Ein Streamlit/Gradio-Dashboard
- Eine zukünftige FastAPI- oder Flask-App
// Verwandeln Sie Ihre Analysen in eine kleine „Analyse-API“
Sie haben bereits die Kernlogik im Pocket book:
- T-Check: Administration vs. Produktionslöhne
- Regression:
TOT_EMP→A_MEAN - Pearson-Korrelation (Q6)
- Z-Check Tech vs. Nicht-Tech (Q7)
- Levene-Check für Lohnvarianz
Wir werden mindestens einen davon in eine Funktion einbinden, damit er sich wie ein kleiner API-Endpunkt verhält.
Beispiel: „Administration- und Produktionslöhne vergleichen“
Dies ist eine Funktionsversion des T-Check-Codes, die bereits im Pocket book enthalten ist:
from scipy.stats import ttest_ind
import pandas as pd
def compare_management_vs_production(df: pd.DataFrame):
"""Two-sample T-test between Administration and Manufacturing occupations."""
# Filter for related occupations
mgmt = df(df("OCC_TITLE").str.comprises("Administration", case=False, na=False))
prod = df(df("OCC_TITLE").str.comprises("Manufacturing", case=False, na=False))
# Drop lacking values
mgmt_wages = mgmt("A_MEAN").dropna()
prod_wages = prod("A_MEAN").dropna()
# Carry out two-sample T-test (Welch's t-test)
t_stat, p_value = ttest_ind(mgmt_wages, prod_wages, equal_var=False)
return t_stat, p_valueJetzt kann dieser Check wiederverwendet werden von:
- Ein Hauptskript
- Ein Streamlit-Schieberegler
- Eine zukünftige FastAPI-Route
ohne irgendwelche Pocket book-Zellen zu kopieren.
// Ein einfacher lokaler Einstiegspunkt
So passen alle Teile in einem einfachen Python-Skript zusammen, das Sie aufrufen können essential.py oder in einer Pocket book-Zelle ausführen:
from preprocessing import preprocess_wage_data
from statistics import run_q6_pearson_test, run_q7_ztest # transfer these from the pocket book
from evaluation import compare_management_vs_production # the perform above
if __name__ == "__main__":
# 1. Load and preprocess the information
df = preprocess_wage_data("state_M2024_dl.xlsx")
# 2. Run core analyses
t_stat, p_value = compare_management_vs_production(df)
print(f"T-test (Administration vs Manufacturing) -> t={t_stat:.2f}, p={p_value:.4f}")
corr_q6, p_q6 = run_q6_pearson_test(df)
print(f"Pearson correlation (TOT_EMP vs A_MEAN) -> r={corr_q6:.4f}, p={p_q6:.4f}")
z_q7 = run_q7_ztest(df)
print(f"Z-test (Tech vs Non-tech median wages) -> z={z_q7:.4f}")Dies sieht noch nicht wie eine Internet-API aus, aber konzeptionell ist es:
- Eingabe: der bereinigte DataFrame
- Operationen: benannte analytische Funktionen
- Ausgabe: genau definierte Zahlen, die Sie in einem Dashboard, einem Bericht oder später einem REST-Endpunkt anzeigen können.
# Alles protokollieren (auch die Particulars)
Die meisten Leute vernachlässigen die Protokollierung, aber sie ist die Artwork und Weise, wie Sie Ihr Projekt debuggbar und vertrauenswürdig machen.
Selbst in einem anfängerfreundlichen Analyseprojekt wie diesem ist es nützlich zu wissen:
- Welche Datei Sie geladen haben
- Wie viele Zeilen haben die Vorverarbeitung überstanden?
- Welche Assessments liefen
- Was waren die wichtigsten Teststatistiken?
Anstatt alles manuell auszudrucken und durch die Notizbuchausgabe zu scrollen, richten wir eine einfache Protokollierungskonfiguration ein, die Sie in Skripten und Notizbüchern wiederverwenden können.
// Grundlegende Protokollierungseinrichtung
Erstellen Sie eine logs/ Ordner in Ihrem Projekt und fügen Sie ihn dann irgendwo früh in Ihrem Code ein (z. B. oben in essential.py oder in einem dedizierten logging_config.py):
import logging
from pathlib import Path
# Be sure that logs/ exists
Path("logs").mkdir(exist_ok=True)
logging.basicConfig(
filename="logs/pipeline.log",
degree=logging.INFO,
format="%(asctime)s - %(levelname)s - %(message)s"
)Jedes Mal, wenn Sie Ihre Pipeline ausführen, a logs/pipeline.log Die Datei wird aktualisiert.
// Protokollierung der Vorverarbeitung und Analysen
Wir können das Hauptbeispiel aus Schritt 5 erweitern, um zu protokollieren, was passiert:
from preprocessing import preprocess_wage_data
from statistics import run_q6_pearson_test, run_q7_ztest
from evaluation import compare_management_vs_production
import logging
if __name__ == "__main__":
logging.information("Beginning wage evaluation pipeline.")
# 1. Preprocess information
df = preprocess_wage_data("state_M2024_dl.xlsx")
logging.information("Loaded cleaned dataset with %d rows and %d columns.", df.form(0), df.form(1))
# 2. T-test: Administration vs Manufacturing
t_stat, p_value = compare_management_vs_production(df)
logging.information("T-test (Mgmt vs Prod) -> t=%.3f, p=%.4f", t_stat, p_value)
# 3. Pearson correlation (Q6)
corr_q6, p_q6 = run_q6_pearson_test(df)
logging.information("Pearson (TOT_EMP vs A_MEAN) -> r=%.4f, p=%.4f", corr_q6, p_q6)
# 4. Z-test (Q7)
z_q7 = run_q7_ztest(df)
logging.information("Z-test (Tech vs Non-tech median wages) -> z=%.3f", z_q7)
logging.information("Pipeline completed efficiently.")Anstatt zu raten, was beim letzten Ausführen des Notebooks passiert ist, können Sie es jetzt öffnen logs/pipeline.log und sehen Sie sich eine Zeitleiste an:
- Als die Vorverarbeitung begann
- Wie viele Zeilen/Spalten Sie hatten
- Was waren die Teststatistiken?
Das ist ein kleiner Schritt, aber eine sehr „MLOps“-Sache: Sie führen Analysen nicht nur durch, Sie beobachten sie.
# Die Geschichte erzählen (auch bekannt als Schreiben für Menschen)
Dokumentation ist wichtig, insbesondere wenn es um Löhne, Berufe und regionale Vergleiche geht, Themen, die echten Entscheidungsträgern am Herzen liegen.
Ihre README-Datei oder Ihr endgültiges Notizbuch sollte Folgendes enthalten:
- Warum diese Analyse wichtig ist
- Eine Zusammenfassung der Lohn- und Beschäftigungsmuster
- Wichtige Visualisierungen (High-/Backside-Zustände, Lohnverteilungen, Gruppenvergleiche)
- Erläuterungen zu jedem statistischen Check und warum er ausgewählt wurde
- Klare Interpretationen der Regressions- und Korrelationsergebnisse
- Einschränkungen (z. B. fehlende Staatsdatensätze, Stichprobenvarianz)
- Nächste Schritte für eine tiefergehende Analyse oder Dashboard-Bereitstellung
Eine gute Dokumentation macht ein Datensatzprojekt zu etwas, das jeder nutzen und verstehen kann.
# Abschluss
Warum ist das alles wichtig?
Denn in der realen Welt lebt die Datenwissenschaft nicht im luftleeren Raum. Ihr schönes Modell ist nicht hilfreich, wenn niemand anderes es ausführen, verstehen oder ihm vertrauen kann. Hier kommt MLOps ins Spiel, nicht als Schlagwort, sondern als Brücke zwischen einem coolen Experiment und einem tatsächlichen, nutzbaren Produkt.
In diesem Artikel haben wir mit einer typischen Notizbuchaufgabe begonnen und gezeigt, wie man ihr Struktur und Durchhaltevermögen verleiht. Wir haben Folgendes eingeführt:
- Versionskontrolle, um unsere Arbeit organisiert zu halten
- Saubere, reproduzierbare Pipelines für die Vorverarbeitung und Erkennung
- Modellserialisierung, damit wir unsere Modelle wiederverwenden (nicht neu trainieren) können
- Eine schlanke API für die lokale Bereitstellung
- Protokollierung, um zu verfolgen, was hinter den Kulissen vor sich geht
- Und schließlich eine Dokumentation, die sowohl Technikbegeisterte als auch Geschäftsleute anspricht
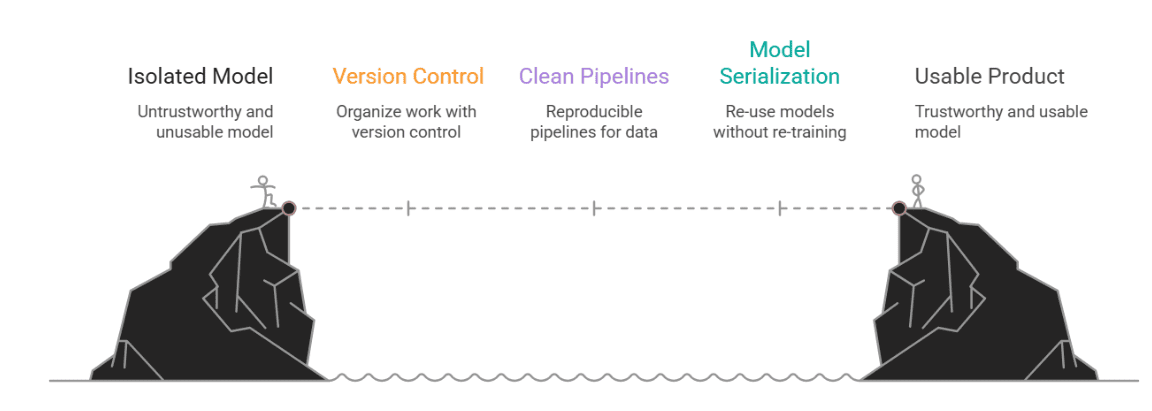
Bild vom Autor
Nate Rosidi ist Datenwissenschaftler und in der Produktstrategie tätig. Er ist außerdem außerordentlicher Professor für Analytik und Gründer von StrataScratch, einer Plattform, die Datenwissenschaftlern hilft, sich mit echten Interviewfragen von High-Unternehmen auf ihre Interviews vorzubereiten. Nate schreibt über die neuesten Traits auf dem Karrieremarkt, gibt Ratschläge zu Vorstellungsgesprächen, stellt Information-Science-Projekte vor und behandelt alles rund um SQL.