

Bild vom Autor
# Einführung
Jeder konzentriert sich auf die Lösung des Issues, aber quick niemand testet die Lösung. Manchmal kann ein perfekt funktionierendes Skript mit nur einer neuen Datenzeile oder einer geringfügigen Änderung der Logik abbrechen.
In diesem Artikel werden wir eine Tesla-Interviewfrage lösen Python und zeigen Sie, wie Versionierung und Komponententests ein fragiles Skript in eine zuverlässige Lösung verwandeln, indem Sie drei Schritte befolgen. Wir beginnen mit der Interviewfrage und enden mit dem automatisierten Testen GitHub-Aktionen.
Bild vom Autor
Wir werden diese drei Schritte durchlaufen, um eine Datenlösung produktionsreif zu machen.
Zuerst werden wir eine echte Interviewfrage von Tesla lösen. Als Nächstes werden wir Unit-Assessments hinzufügen, um sicherzustellen, dass die Lösung langfristig zuverlässig bleibt. Schließlich werden wir GitHub Actions verwenden, um Assessments und Versionskontrolle zu automatisieren.
# Eine echte Interviewfrage von Tesla lösen
Neue Produkte
Berechnen Sie die Nettoveränderung der Anzahl der von Unternehmen im Jahr 2020 eingeführten Produkte im Vergleich zu 2019. Ihre Ausgabe sollte die Firmennamen und die Nettodifferenz enthalten.
(Nettodifferenz = Anzahl der im Jahr 2020 eingeführten Produkte – Anzahl der im Jahr 2019 eingeführten Produkte.)
In diesem Interview Frage von Teslawerden Sie gebeten, das Produktwachstum über zwei Jahre hinweg zu messen.
Die Aufgabe besteht darin, den Namen jedes Unternehmens zusammen mit der Differenz in der Produktanzahl zwischen 2020 und 2019 zurückzugeben.
// Den Datensatz verstehen
Schauen wir uns zunächst den Datensatz an, mit dem wir arbeiten. Hier sind die Spaltennamen.
| Spaltenname | Datentyp |
|---|---|
| Jahr | int64 |
| Identify der Firma | Objekt |
| Produktname | Objekt |
Lassen Sie uns eine Vorschau des Datensatzes anzeigen.
| Jahr | Identify der Firma | Produktname |
|---|---|---|
| 2019 | Toyota | Avalon |
| 2019 | Toyota | Camry |
| 2020 | Toyota | Blumenkrone |
| 2019 | Honda | Übereinstimmung |
| 2019 | Honda | Reisepass |
Dieser Datensatz enthält drei Spalten: 12 months, company_nameUnd product_name. Jede Zeile stellt ein Automodell dar, das von einem Unternehmen in einem bestimmten Jahr herausgebracht wurde.
// Schreiben der Python-Lösung
Wir werden Primary verwenden Pandas Vorgänge zum Gruppieren, Vergleichen und Berechnen der Nettoproduktveränderung professional Unternehmen. Die Funktion, die wir schreiben werden, teilt die Daten in Teilmengen für 2019 und 2020 auf.
Anschließend werden sie nach Firmennamen zusammengeführt und die Anzahl der jedes Jahr auf den Markt gebrachten einzigartigen Produkte gezählt.
import pandas as pd
import numpy as np
from datetime import datetime
df_2020 = car_launches(car_launches('12 months').astype(str) == '2020')
df_2019 = car_launches(car_launches('12 months').astype(str) == '2019')
df = pd.merge(df_2020, df_2019, how='outer', on=(
'company_name'), suffixes=('_2020', '_2019')).fillna(0)Bei der endgültigen Ausgabe werden die Zählungen für 2019 von 2020 abgezogen, um die Nettodifferenz zu erhalten. Hier ist der gesamte Code.
import pandas as pd
import numpy as np
from datetime import datetime
df_2020 = car_launches(car_launches('12 months').astype(str) == '2020')
df_2019 = car_launches(car_launches('12 months').astype(str) == '2019')
df = pd.merge(df_2020, df_2019, how='outer', on=(
'company_name'), suffixes=('_2020', '_2019')).fillna(0)
df = df(df('product_name_2020') != df('product_name_2019'))
df = df.groupby(('company_name')).agg(
{'product_name_2020': 'nunique', 'product_name_2019': 'nunique'}).reset_index()
df('net_new_products') = df('product_name_2020') - df('product_name_2019')
end result = df(('company_name', 'net_new_products'))// Anzeigen der erwarteten Ausgabe
Hier ist die erwartete Ausgabe.
| Identify der Firma | Net_new_products |
|---|---|
| Chevrolet | 2 |
| Ford | -1 |
| Honda | -3 |
| Jeep | 1 |
| Toyota | -1 |
# Mit Unit-Assessments die Lösung zuverlässig machen
Die einmalige Lösung eines Datenproblems bedeutet nicht, dass es weiterhin funktioniert. Eine neue Zeile oder eine logische Änderung kann Ihr Skript stillschweigend zerstören. Stellen Sie sich zum Beispiel vor, Sie benennen versehentlich eine Spalte in Ihrem Code um und ändern dabei diese Zeile:
df('net_new_products') = df('product_name_2020') - df('product_name_2019')dazu:
df('new_products') = df('product_name_2020') - df('product_name_2019')Die Logik läuft weiterhin, aber Ihre Ausgabe (und Assessments) schlagen plötzlich fehl, weil der erwartete Spaltenname nicht mehr übereinstimmt. Unit-Assessments beheben das. Sie prüfen jedes Mal, ob dieselbe Eingabe immer noch dieselbe Ausgabe liefert. Wenn etwas kaputt geht, schlägt der Check fehl und zeigt genau an, wo. Wir werden dies in drei Schritten tun, von der Umwandlung der Lösung der Interviewfrage in eine Funktion bis zum Schreiben eines Assessments, der die Ausgabe mit unseren Erwartungen vergleicht.

Bild vom Autor
// Das Skript in eine wiederverwendbare Funktion umwandeln
Bevor wir Assessments schreiben, müssen wir unsere Lösung wiederverwendbar und einfach zu testen machen. Durch die Konvertierung in eine Funktion können wir sie mit verschiedenen Datensätzen ausführen und die Ausgabe automatisch überprüfen, ohne jedes Mal den gleichen Code neu schreiben zu müssen. Wir haben den ursprünglichen Code in eine Funktion geändert, die a akzeptiert DataFrame und gibt ein Ergebnis zurück. Hier ist der Code.
def calculate_net_new_products(car_launches):
df_2020 = car_launches(car_launches('12 months').astype(str) == '2020')
df_2019 = car_launches(car_launches('12 months').astype(str) == '2019')
df = pd.merge(df_2020, df_2019, how='outer', on=(
'company_name'), suffixes=('_2020', '_2019')).fillna(0)
df = df(df('product_name_2020') != df('product_name_2019'))
df = df.groupby(('company_name')).agg({
'product_name_2020': 'nunique',
'product_name_2019': 'nunique'
}).reset_index()
df('net_new_products') = df('product_name_2020') - df('product_name_2019')
return df(('company_name', 'net_new_products'))// Testdaten und erwartete Ausgabe definieren
Bevor wir Assessments durchführen, müssen wir wissen, wie „richtig“ aussieht. Durch die Definition der erwarteten Ausgabe erhalten wir einen klaren Maßstab, mit dem wir die Ergebnisse unserer Funktion vergleichen können. Wir werden additionally eine kleine Testeingabe erstellen und klar definieren, wie die richtige Ausgabe aussehen soll.
import pandas as pd
# Pattern check information
test_data = pd.DataFrame({
'12 months': (2019, 2019, 2020, 2020),
'company_name': ('Toyota', 'Toyota', 'Toyota', 'Toyota'),
'product_name': ('Camry', 'Avalon', 'Corolla', 'Yaris')
})
# Anticipated output
expected_output = pd.DataFrame({
'company_name': ('Toyota'),
'net_new_products': (0) # 2 in 2020 - 2 in 2019
})// Schreiben und Ausführen von Unit-Assessments
Der folgende Testcode prüft, ob Ihre Funktion genau das zurückgibt, was Sie erwarten.

Wenn nicht, schlägt der Check fehl und zeigt Ihnen bis zur letzten Zeile oder Spalte den Grund dafür an.
Der folgende Check verwendet die Funktion aus dem vorherigen Schritt (calculate_net_new_products()) und die erwartete Ausgabe, die wir definiert haben.
import unittest
class TestProductDifference(unittest.TestCase):
def test_net_new_products(self):
end result = calculate_net_new_products(test_data)
end result = end result.sort_values('company_name').reset_index(drop=True)
anticipated = expected_output.sort_values('company_name').reset_index(drop=True)
pd.testing.assert_frame_equal(end result, anticipated)
if __name__ == '__main__':
unittest.major()# Automatisierung von Assessments mit kontinuierlicher Integration
Assessments zu schreiben ist ein guter Anfang, aber nur, wenn sie tatsächlich durchgeführt werden. Sie könnten die Assessments nach jeder Änderung manuell ausführen, aber das lässt sich nicht skalieren, es kann leicht vergessen werden und Teammitglieder verwenden möglicherweise unterschiedliche Setups. Steady Integration (CI) löst dieses Drawback, indem Assessments automatisch ausgeführt werden, wenn Codeänderungen in das Repository übertragen werden.
GitHub-Aktionen ist ein kostenloses CI-Software, das dies bei jedem Push tut und so dafür sorgt, dass Ihre Lösung auch dann zuverlässig bleibt, wenn sich Code, Daten oder Logik ändern. Es führt Ihre Assessments automatisch bei jedem Push durch, sodass Ihre Lösung auch dann zuverlässig bleibt, wenn sich Code, Daten oder Logik ändern. Hier erfahren Sie, wie Sie CI mit GitHub Actions anwenden.
Bild vom Autor
// Organisieren Ihrer Projektdateien
Um CI auf eine Interviewabfrage anzuwenden, müssen Sie Ihre Lösung zunächst in ein GitHub-Repository übertragen. (Um zu erfahren, wie man ein GitHub-Repo erstellt, lesen Sie bitte Das).
Richten Sie dann die folgenden Dateien ein:
answer.py: Lösung für Interviewfragen aus Schritt 2.1expected_output.py: Definiert die Testeingabe und die erwartete Ausgabe aus Schritt 2.2test_solution.py: Unit-Check mitunittestab Schritt 2.3necessities.txt: Abhängigkeiten (z. B. Pandas).github/workflows/check.yml: GitHub Actions-Workflow-Dateiinformation/car_launches.csv: Von der Lösung verwendeter Eingabedatensatz
// Das Repository-Structure verstehen
Das Repository ist auf diese Weise organisiert, sodass GitHub Actions ohne zusätzliche Einrichtung alles finden kann, was es in Ihrem GitHub-Repository benötigt. Es sorgt dafür, dass die Dinge sowohl für Sie als auch für andere einfach, konsistent und leicht zu handhaben sind.
my-query-solution/
├── information/
│ └── car_launches.csv
├── answer.py
├── expected_output.py
├── test_solution.py
├── necessities.txt
└── .github/
└── workflows/
└── check.yml// Erstellen eines GitHub-Aktionsworkflows
Da Sie nun alle Dateien haben, ist die letzte, die Sie benötigen check.yml. Diese Datei teilt GitHub Actions mit, wie Ihre Assessments automatisch ausgeführt werden sollen, wenn sich Code ändert.
Zuerst benennen wir den Workflow und teilen GitHub mit, wann er ausgeführt werden soll.
identify: Run Unit Assessments
on:
push:
branches: ( major )
pull_request:
branches: ( major )Das bedeutet, dass die Assessments jedes Mal ausgeführt werden, wenn jemand Code pusht oder eine Pull-Anfrage im Hauptzweig öffnet. Als Nächstes erstellen wir einen Job, der definiert, was im Workflow passieren soll.
jobs:
check:
runs-on: ubuntu-latestDer Job läuft in der Ubuntu-Umgebung von GitHub, wodurch Sie jedes Mal ein sauberes Setup erhalten. Jetzt fügen wir Schritte innerhalb dieses Jobs hinzu. Der erste checkt Ihr Repository aus, damit GitHub Actions auf Ihren Code zugreifen kann.
- identify: Checkout repository
makes use of: actions/checkout@v4Dann richten wir Python ein und wählen die Model aus, die wir verwenden möchten.
- identify: Arrange Python
makes use of: actions/setup-python@v5
with:
python-version: "3.10"Danach installieren wir alle in aufgeführten Abhängigkeiten necessities.txt.
- identify: Set up dependencies
run: |
python -m pip set up --upgrade pip
pip set up -r necessities.txtAbschließend führen wir alle Unit-Assessments im Projekt durch.
- identify: Run unit checks
run: python -m unittest uncoverDieser letzte Schritt führt Ihre Assessments automatisch durch und zeigt alle Fehler an, wenn etwas kaputt geht. Hier ist die vollständige Datei als Referenz:
identify: Run Unit Assessments
on:
push:
branches: ( major )
pull_request:
branches: ( major )
jobs:
check:
runs-on: ubuntu-latest
steps:
- identify: Checkout repository
makes use of: actions/checkout@v4
- identify: Arrange Python
makes use of: actions/setup-python@v5
with:
python-version: "3.10"
- identify: Set up dependencies
run: |
python -m pip set up --upgrade pip
pip set up -r necessities.txt
- identify: Run unit checks
run: python -m unittest uncover// Überprüfen von Testergebnissen in GitHub-Aktionen
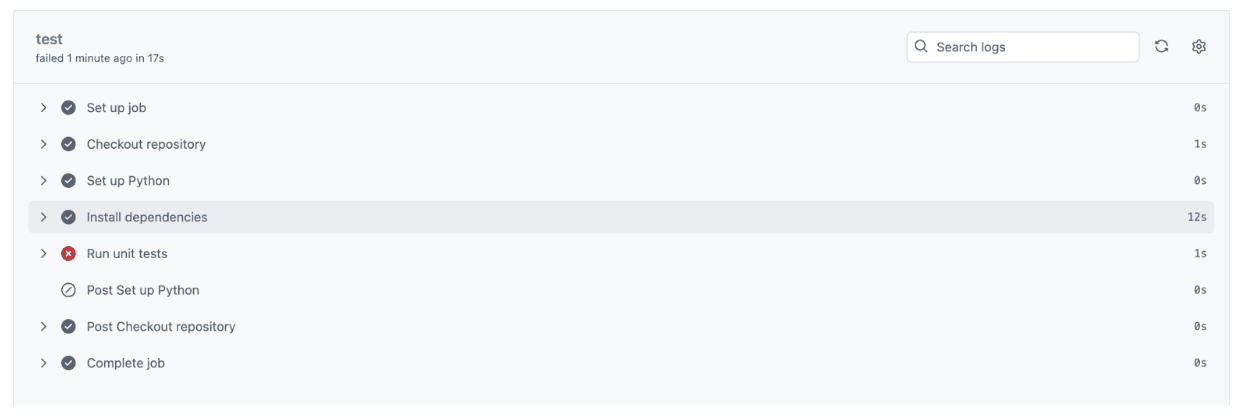
Nachdem Sie alle Dateien in Ihr GitHub-Repository hochgeladen haben, wechseln Sie zur Registerkarte „Aktionen“, indem Sie auf „Aktionen“ klicken, wie Sie im Screenshot unten sehen können.

Sobald Sie auf „Aktionen“ klicken, wird ein grünes Häkchen angezeigt, wenn alles erfolgreich ausgeführt wurde, wie im Screenshot unten.

Klicken Sie auf „Check.yml aktualisieren“, um zu sehen, was tatsächlich passiert ist. Sie erhalten eine vollständige Aufschlüsselung, von der Einrichtung von Python bis zur Durchführung des Assessments. Wenn alle Assessments erfolgreich sind:
- Jeder Schritt wird mit einem Häkchen versehen.
- Das bestätigt, dass alles wie erwartet funktioniert hat.
- Das bedeutet, dass sich Ihr Code basierend auf den von Ihnen definierten Assessments in jeder Part wie beabsichtigt verhält.
- Die Ausgabe entspricht den Zielen, die Sie beim Erstellen dieser Assessments festgelegt haben.
Lasst uns sehen:

Wie Sie sehen, conflict unser Unit-Check in nur 1 Sekunde abgeschlossen und der gesamte CI-Prozess conflict in 17 Sekunden abgeschlossen, wobei alles vom Setup bis zur Testausführung überprüft wurde.
// Wenn eine kleine Änderung den Check bricht
Nicht jede Änderung wird den Check bestehen. Nehmen wir an, Sie benennen versehentlich eine Spalte in um answer.pyUnd Senden Sie die Änderungen an GitHubZum Beispiel:
# Authentic (works advantageous)
df('net_new_products') = df('product_name_2020') - df('product_name_2019')
# Unintentional change
df('new_products') = df('product_name_2020') - df('product_name_2019')Sehen wir uns nun die Testergebnisse auf der Registerkarte „Aktion“ an.

Wir haben einen Fehler. Klicken wir darauf, um die Particulars anzuzeigen.

Die Unit-Assessments wurden nicht bestanden. Klicken Sie daher auf „Unit-Assessments ausführen“, um die vollständige Fehlermeldung anzuzeigen.
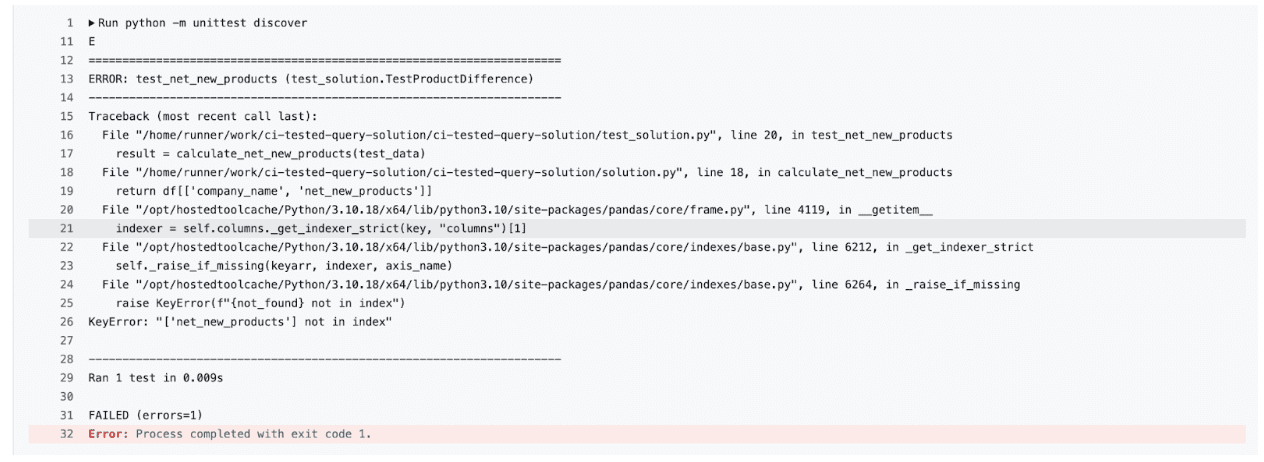
Wie Sie sehen können, haben unsere Assessments das Drawback mit einem gefunden KeyError: 'net_new_products'da der Spaltenname in der Funktion nicht mehr mit den Erwartungen des Assessments übereinstimmt.
So halten Sie Ihren Code ständig unter Kontrolle. Wenn Sie oder jemand in Ihrem Group einen Fehler macht, dienen die Assessments als Ihr Sicherheitsnetz.
# Verwenden der Versionskontrolle zum Verfolgen und Testen von Änderungen
Mit der Versionierung können Sie jede von Ihnen vorgenommene Änderung verfolgen, sei es in Ihrer Logik, Ihren Assessments oder Ihrem Datensatz. Angenommen, Sie möchten eine neue Methode zum Gruppieren der Daten ausprobieren. Anstatt das Hauptskript direkt zu bearbeiten, erstellen Sie einen neuen Zweig:
git checkout -b refactor-groupingHier ist, was als nächstes kommt:
- Nehmen Sie Ihre Änderungen vor, übernehmen Sie sie und führen Sie die Assessments durch.
- Wenn alle Assessments erfolgreich sind, d. h. der Code wie erwartet funktioniert, führen Sie ihn zusammen.
- Wenn nicht, setzen Sie den Zweig zurück, ohne den Hauptcode zu beeinträchtigen.
Das ist die Stärke der Versionskontrolle: Jede Änderung ist nachverfolgbar, testbar und rückgängig zu machen.
# Letzte Gedanken
Die meisten Menschen hören auf, nachdem sie die richtige Antwort erhalten haben. Aber reale Datenlösungen verlangen mehr als das. Sie belohnen diejenigen, die Abfragen erstellen können, die über einen längeren Zeitraum und nicht nur einmal bestehen.
Mit Versionierung, Unit-Assessments und einem einfachen CI-Setup wird selbst eine einmalige Interviewfrage zu einem zuverlässigen, wiederverwendbaren Teil Ihres Portfolios.
Nate Rosidi ist Datenwissenschaftler und in der Produktstrategie tätig. Er ist außerdem außerordentlicher Professor für Analytik und Gründer von StrataScratch, einer Plattform, die Datenwissenschaftlern hilft, sich mit echten Interviewfragen von Prime-Unternehmen auf ihre Interviews vorzubereiten. Nate schreibt über die neuesten Developments auf dem Karrieremarkt, gibt Ratschläge zu Vorstellungsgesprächen, stellt Knowledge-Science-Projekte vor und behandelt alles rund um SQL.