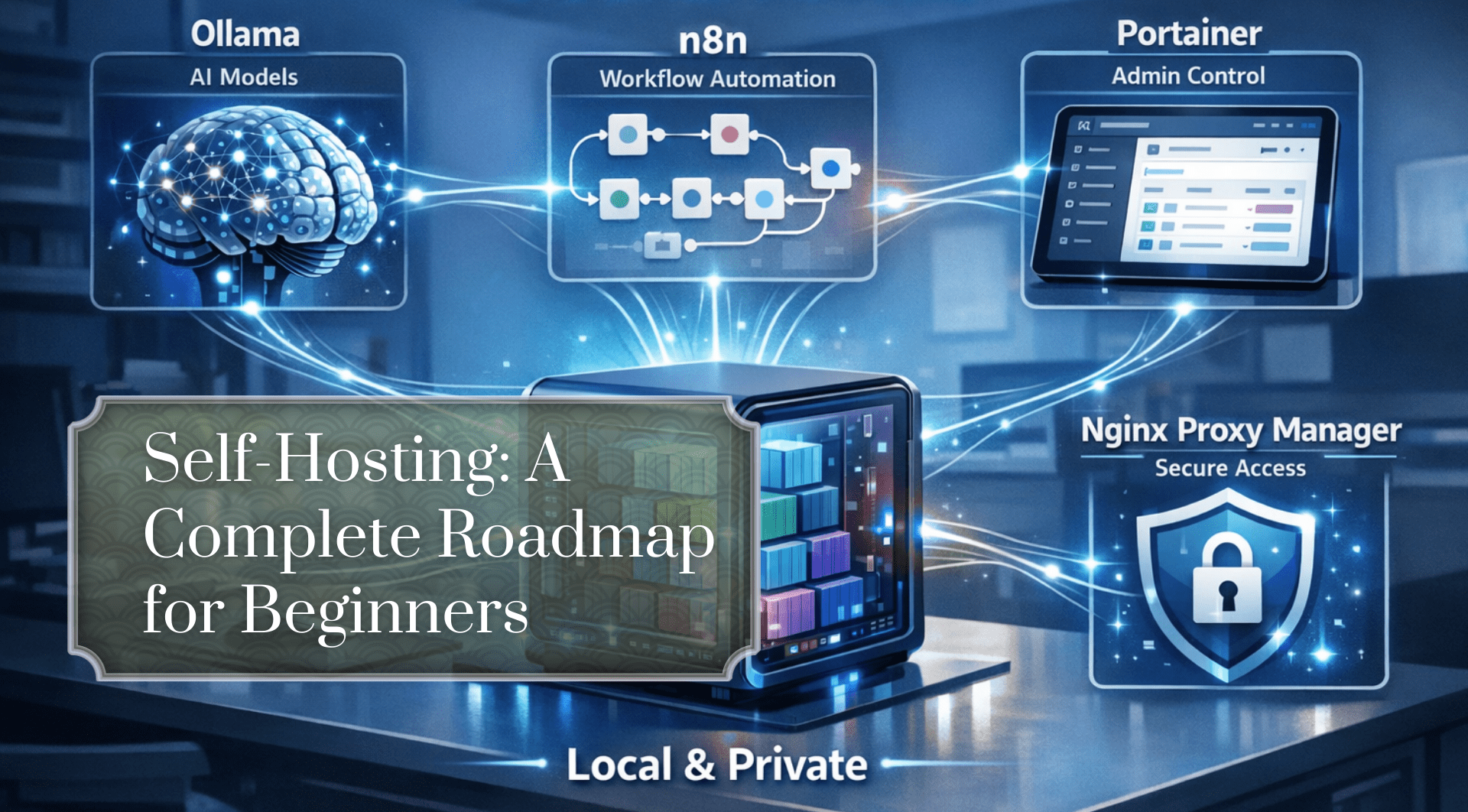
Bild vom Autor
# Einführung
Der Aufbau Ihres eigenen lokalen KI-Hubs gibt Ihnen die Freiheit, Aufgaben zu automatisieren, personal Daten zu verarbeiten und benutzerdefinierte Assistenten zu erstellen, ohne auf die Cloud angewiesen zu sein oder monatliche Gebühren zahlen zu müssen. In diesem Artikel werde ich Sie durch den Aufbau eines selbst gehosteten KI-Workflow-Hubs auf einem Heimserver führen, der Ihnen vollständige Kontrolle, mehr Privatsphäre und leistungsstarke Automatisierung bietet.
Wir werden Instruments wie kombinieren Docker zum Verpacken von Software program, Ollama um lokale Modelle für maschinelles Lernen auszuführen, n8n zum Erstellen visueller Automatisierungen und Portainer zur einfachen Verwaltung. Dieses Setup eignet sich perfekt für ein mäßig leistungsstarkes x86-64-System wie einen Mini-PC oder einen alten Desktop mit mindestens 8 GB RAM, das mehrere Dienste gleichzeitig bewältigen kann.
# Warum einen lokalen KI-Hub aufbauen?
Wenn Sie Ihre Instruments selbst hosten, werden Sie vom Nutzer von Diensten zum Eigentümer der Infrastruktur, und das ist wirkungsvoll. Ein lokaler Hub ist privat (Ihre Daten verlassen nie Ihr Netzwerk), kostengünstig (keine API-Gebühren (Software Programming Interface)) und vollständig anpassbar.
Der Kern dieses Hubs ist eine leistungsstarke Gruppe von Elementen, bei denen:
- Ollama dient als Ihr privates KI-Gehirn auf dem Gerät und führt Modelle zur Textgenerierung und -analyse aus
- n8n fungiert als Nervensystem und verbindet Ollama mit anderen Apps (wie Kalendern, E-Mails oder Dateien), um automatisierte Arbeitsabläufe zu erstellen
- Docker ist die Grundlage und verpackt jedes Device in separate, einfach zu verwaltende Container
// Kernkomponenten Ihres selbstgehosteten KI-Hubs
| Werkzeug | Primäre Rolle | Hauptvorteil für Ihren Hub |
|---|---|---|
| Docker/Portainer | Containerisierung und Administration | Isoliert Apps, vereinfacht die Bereitstellung und bietet ein visuelles Administration-Dashboard |
| Ollama | Lokaler LLM-Server (Massive Language Mannequin). | Führt KI-Modelle aus Datenschutzgründen lokal aus; stellt eine API zur Verwendung durch andere Instruments bereit |
| n8n | Plattform zur Workflow-Automatisierung | Verbindet Ollama visuell mit anderen Diensten (APIs, Datenbanken, Dateien), um leistungsstarke Automatisierungen zu erstellen |
| Nginx-Proxy-Supervisor | Sicherer Zugriff und Routing | Bietet ein sicheres Net-Gateway zu Ihren Diensten mit einfacher Einrichtung eines SSL-Zertifikats |
# Vorbereiten Ihrer Server Basis
Stellen Sie zunächst sicher, dass Ihr Server bereit ist. Wir empfehlen eine Neuinstallation von Ubuntu Server LTS oder einer ähnlichen Linux-Distribution. Stellen Sie nach der Set up eine Verbindung zu Ihrem Server über Safe Shell (SSH) her. Der erste und wichtigste Schritt ist die Set up von Docker, das alle unsere nachfolgenden Instruments ausführt.
// Docker und Docker Compose installieren
Führen Sie die folgenden Befehle in Ihrem Terminal aus, um Docker und Docker Compose zu installieren. Docker Compose ist ein Device, mit dem Sie Multi-Container-Anwendungen mit einer einfachen YAML-Datei definieren und verwalten können.
sudo apt replace && sudo apt improve -y
sudo apt set up apt-transport-https ca-certificates curl software-properties-common -y
curl -fsSL https://obtain.docker.com/linux/ubuntu/gpg | sudo apt-key add -
sudo add-apt-repository "deb (arch=amd64) https://obtain.docker.com/linux/ubuntu $(lsb_release -cs) steady"
sudo apt replace
sudo apt set up docker-ce docker-ce-cli containerd.io docker-compose-plugin -y// Überprüfen und Festlegen von Berechtigungen
Überprüfen Sie die Set up und fügen Sie Ihren Benutzer zur Docker-Gruppe hinzu, um Befehle ohne auszuführen sudo:
sudo docker model
sudo usermod -aG docker $USERAusgabe:

Damit dies wirksam wird, müssen Sie sich abmelden und dann erneut anmelden.
// Verwalten mit Portainer
Anstatt nur die Befehlszeile zu verwenden, werden wir Portainer bereitstellen, eine webbasierte grafische Benutzeroberfläche (GUI) zur Verwaltung von Docker. Erstellen Sie ein Verzeichnis dafür und a docker-compose.yml Datei mit dem folgenden Befehl.
mkdir -p ~/portainer && cd ~/portainer
nano docker-compose.ymlFügen Sie die folgende Konfiguration in die Datei ein. Dadurch wird Docker angewiesen, das Portainer-Picture herunterzuladen, es automatisch neu zu starten und seine Weboberfläche auf Port 9000 verfügbar zu machen.
companies:
portainer:
picture: portainer/portainer-ce:newest
container_name: portainer
restart: unless-stopped
ports:
- "9000:9000"
volumes:
- /var/run/docker.sock:/var/run/docker.sock
- portainer_data:/information
volumes:
portainer_data:Speichern Sie die Datei (Strg+X, dann Y, dann Enter). Stellen Sie nun Portainer bereit:
Ihre Ausgabe sollte so aussehen:

Navigieren Sie nun zu http://YOUR_SERVER_IP:9000 in Ihrem Browser. Für mich ist es das http://localhost:9000

Möglicherweise müssen Sie den Server neu starten. Das können Sie mit dem folgenden Befehl machen:
sudo docker begin portainerErstellen Sie ein Administratorkonto:
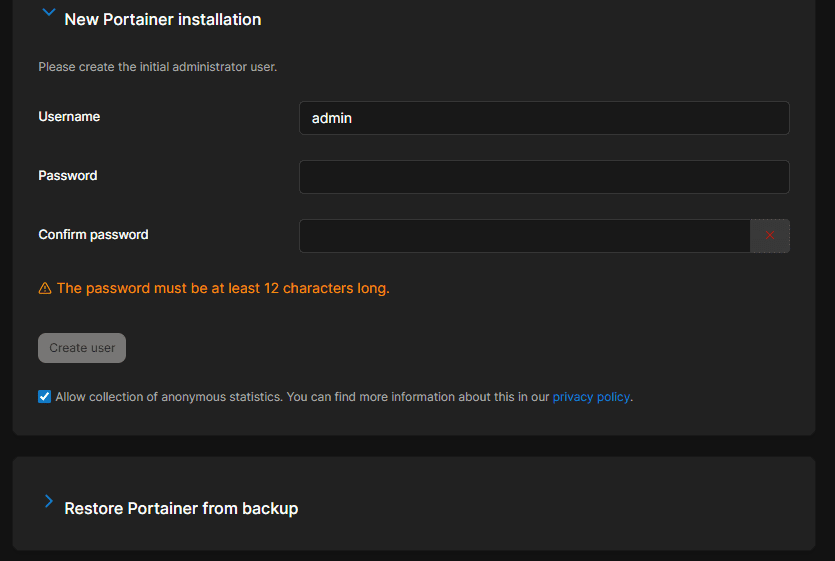
Und nachdem Sie ein Konto erstellt haben, sehen Sie das Portainer-Dashboard.

Dies ist Ihre Missionskontrolle für alle anderen Container. Von hier aus können Sie jeden anderen Dienst starten, stoppen, Protokolle anzeigen und verwalten.
# Ollama installieren: Ihre lokale KI-Engine
Ollama ist ein Device, mit dem Open-Supply-LLMs (Massive Language Fashions) wie Llama 3.2 oder Mistral problemlos lokal ausgeführt werden können. Es bietet eine einfache API, die n8n und andere Apps verwenden können.
// Bereitstellung von Ollama mit Docker
Während Ollama direkt installiert werden kann, sorgt die Verwendung von Docker für Konsistenz. Erstellen Sie ein neues Verzeichnis und a docker-compose.yml Datei dafür mit dem folgenden Befehl.
mkdir -p ~/ollama && cd ~/ollama
nano docker-compose.ymlVerwenden Sie diese Konfiguration. Der volumes Zeile ist wichtig, da sie Ihre heruntergeladenen Modelle für maschinelles Lernen dauerhaft speichert, sodass Sie sie nicht verlieren, wenn der Container neu gestartet wird.
companies:
ollama:
picture: ollama/ollama:newest
container_name: ollama
restart: unless-stopped
ports:
- "11434:11434"
volumes:
- ollama_data:/root/.ollama
volumes:
ollama_data:Stellen Sie es bereit: docker compose up -d
// Ziehen und Ausführen Ihres ersten Modells
Sobald der Container ausgeführt wird, können Sie ein Modell ziehen. Beginnen wir mit einem leistungsfähigen, aber effizienten Modell wie Llama 3.2.
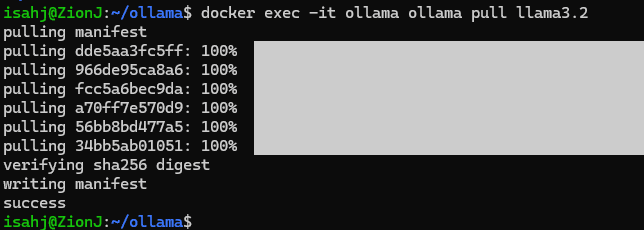
Dieser Befehl wird ausgeführt ollama pull llama3.2 im laufenden Container:
docker exec -it ollama ollama pull llama3.2Aufgabendemonstration: Ollama abfragen
Sie können jetzt direkt mit Ihrer lokalen KI interagieren. Der folgende Befehl sendet eine Eingabeaufforderung an das Modell, das im Container ausgeführt wird.
docker exec -it ollama ollama run llama3.2 "Write a brief haiku about know-how."In Ihrem Terminal sollte ein generiertes Gedicht angezeigt werden. Noch wichtiger ist, dass die API von Ollama jetzt unter verfügbar ist http://YOUR_SERVER_IP:11434 für n8n zu verwenden.

# Integration von n8n für intelligente Automatisierung
n8n ist ein visuelles Workflow-Automatisierungstool. Sie können Knoten per Drag-and-Drop verschieben, um Sequenzen zu erstellen. zum Beispiel: „Wenn ich ein Dokument speichere, fasse ich es mit Ollama zusammen und sende die Zusammenfassung dann an meine Notizen-App.“
// Bereitstellung von n8n mit Docker
Erstellen Sie ein Verzeichnis für n8n. Wir verwenden eine Compose-Datei, die eine Datenbank für n8n enthält, um Ihre Arbeitsabläufe und Ausführungsdaten zu speichern.
mkdir -p ~/n8n && cd ~/n8n
nano docker-compose.ymlFügen Sie nun Folgendes in die YAML-Datei ein:
companies:
n8n:
picture: n8nio/n8n:newest
container_name: n8n
restart: unless-stopped
ports:
- "5678:5678"
surroundings:
- N8N_PROTOCOL=http
- WEBHOOK_URL=http://YOUR_SERVER_IP:5678/
- N8N_ENCRYPTION_KEY=your_secure_encryption_key_here
- DB_TYPE=postgresdb
- DB_POSTGRESDB_HOST=db
- DB_POSTGRESDB_PORT=5432
- DB_POSTGRESDB_DATABASE=n8n
- DB_POSTGRESDB_USER=n8n
- DB_POSTGRESDB_PASSWORD=your_secure_db_password
volumes:
- n8n_data:/residence/node/.n8n
depends_on:
- db
db:
picture: postgres:17-alpine
container_name: n8n_db
restart: unless-stopped
surroundings:
- POSTGRES_USER=n8n
- POSTGRES_PASSWORD=your_secure_db_password
- POSTGRES_DB=n8n
volumes:
- postgres_data:/var/lib/postgresql/information
volumes:
n8n_data:
postgres_data:Ersetzen YOUR_SERVER_IP und die Platzhalter-Passwörter. Bereitstellen mit docker compose up -d. Greifen Sie auf n8n zu http://YOUR_SERVER_IP:5678.
Aufgabendemonstration: Erstellen Sie Ihren ersten KI-Workflow
Erstellen wir einen einfachen Workflow, bei dem n8n Ollama als kreativen Schreibassistenten verwendet.
- Fügen Sie im n8n-Editor einen „Schedule Set off“-Knoten hinzu und stellen Sie ihn so ein, dass er zu Testzwecken manuell ausgeführt wird
- Fügen Sie einen Knoten „HTTP-Anfrage“ hinzu. Konfigurieren Sie es so, dass es Ihre Ollama-API aufruft:
- Methode: POST
- URL: http://ollama:11434/api/generate
- Legen Sie den Textinhaltstyp auf JSON fest
- Geben Sie im JSON-Textual content Folgendes ein: {„mannequin“: „llama3.2“, „immediate“: „Generieren Sie drei Ideen für eine Science-Fiction-Kurzgeschichte.“}
- Fügen Sie einen „Set“-Knoten hinzu, um nur den Textual content aus Ollamas JSON-Antwort zu extrahieren. Stellen Sie den Wert auf ein
{{ $json("response") }} - Fügen Sie einen „Code“-Knoten hinzu und verwenden Sie eine einfache Zeile wie
objects = ({"json": {"story_ideas": $enter.merchandise.json}}); return objects;um die Daten zu formatieren - Verbinden Sie abschließend einen Knoten „E-Mail-Versand“ (konfiguriert mit Ihrem E-Mail-Dienst) oder einen Knoten „In Datei speichern“, um die Ergebnisse auszugeben
Klicken Sie auf „Workflow ausführen“. n8n sendet die Eingabeaufforderung an Ihren lokalen Ollama-Container, empfängt die Ideen und verarbeitet sie. Sie haben gerade einen privaten, automatisierten KI-Assistenten erstellt.
# Sichern Sie Ihren Hub mit Nginx Proxy Supervisor
Sie haben jetzt Dienste auf verschiedenen Ports (Portainer: 9000, n8n: 5678). Mit dem Nginx Proxy Supervisor (NPM) können Sie über übersichtliche Subdomains (wie portainer.residence.web) mit der kostenlosen SSL-Verschlüsselung (Safe Sockets Layer) von Let’s Encrypt darauf zugreifen.
// Bereitstellen des Nginx-Proxy-Managers
Erstellen Sie ein endgültiges Verzeichnis für NPM.
mkdir -p ~/npm && cd ~/npm
nano docker-compose.ymlFügen Sie den folgenden Code in Ihre YAML-Datei ein:
companies:
app:
picture: 'jc21/nginx-proxy-manager:newest'
container_name: nginx-proxy-manager
restart: unless-stopped
ports:
- '80:80'
- '443:443'
- '81:81'
volumes:
- ./information:/information
- ./letsencrypt:/and many others/letsencrypt
volumes:
information:
letsencrypt:Bereitstellen mit docker compose up -d.
Das Admin-Panel ist unter http://YOUR_SERVER_IP:81. Melden Sie sich mit den Standardanmeldeinformationen an (admin@instance.com/changeme) und ändern Sie diese sofort.

Aufgabendemonstration: Sichern des n8n-Zugriffs
- Leiten Sie in Ihrem Heimrouter die Ports 80 und 443 an die interne Web Protocol (IP)-Adresse Ihres Servers weiter. Dies ist die einzige erforderliche Portweiterleitung
- Gehen Sie im Admin-Bereich von NPM (Ihr-Server-IP:81) zu Hosts -> Proxy-Hosts -> Proxy-Host hinzufügen

- Geben Sie für n8n die Particulars ein:
- Area: n8n.yourdomain.com (oder eine Subdomain, die Sie besitzen und die auf Ihre Heimat-IP verweist)
- Schema: http
- Hostname/IP weiterleiten: n8n (Das interne Netzwerk von Docker löst den Containernamen auf!)
- Weiterleitungsport: 5678
- Klicken Sie auf SSL und fordern Sie ein Let’s Encrypt-Zertifikat an, wobei SSL erzwungen wird
Sie können jetzt sicher auf n8n unter https://n8n.yourdomain.com zugreifen. Wiederholen Sie diesen Vorgang für Portainer (portainer.yourdomain.com Weiterleitung an portainer:9000).
# Abschluss
Sie verfügen jetzt über einen voll funktionsfähigen, privaten KI-Automatisierungs-Hub. Ihre nächsten Schritte könnten sein:
- Ollama erweitern: Experimentieren Sie mit verschiedenen Modellen wie Mistral für Geschwindigkeit oder Codellama für Programmieraufgaben
- Erweiterte n8n-Workflows: Verbinden Sie Ihren Hub mit externen APIs (Google Kalender, Telegram, RSS-Feeds) oder internen Diensten (wie einem lokalen Dateiserver).
- Überwachung: Fügen Sie ein Device wie Uptime Kuma hinzu (auch über Docker einsetzbar), um den Standing aller Ihrer Dienste zu überwachen
Dieses Setup verwandelt Ihre bescheidene {Hardware} in ein leistungsstarkes, privates digitales Gehirn. Sie haben die Kontrolle über die Software program, sind Eigentümer der Daten und zahlen keine laufenden Gebühren. Die Fähigkeiten, die Sie bei der Verwaltung von Containern, der Orchestrierung von Diensten und der Automatisierung mit KI erworben haben, bilden die Grundlage einer modernen, unabhängigen technischen Infrastruktur.
// Weiterführende Literatur
Shittu Olumid ist ein Software program-Ingenieur und technischer Autor, der sich leidenschaftlich dafür einsetzt, modernste Technologien zu nutzen, um fesselnde Erzählungen zu erschaffen, mit einem scharfen Blick fürs Element und einem Gespür für die Vereinfachung komplexer Konzepte. Sie können Shittu auch auf finden Twitter.