 Bild vom Herausgeber
Bild vom Herausgeber# Einführung
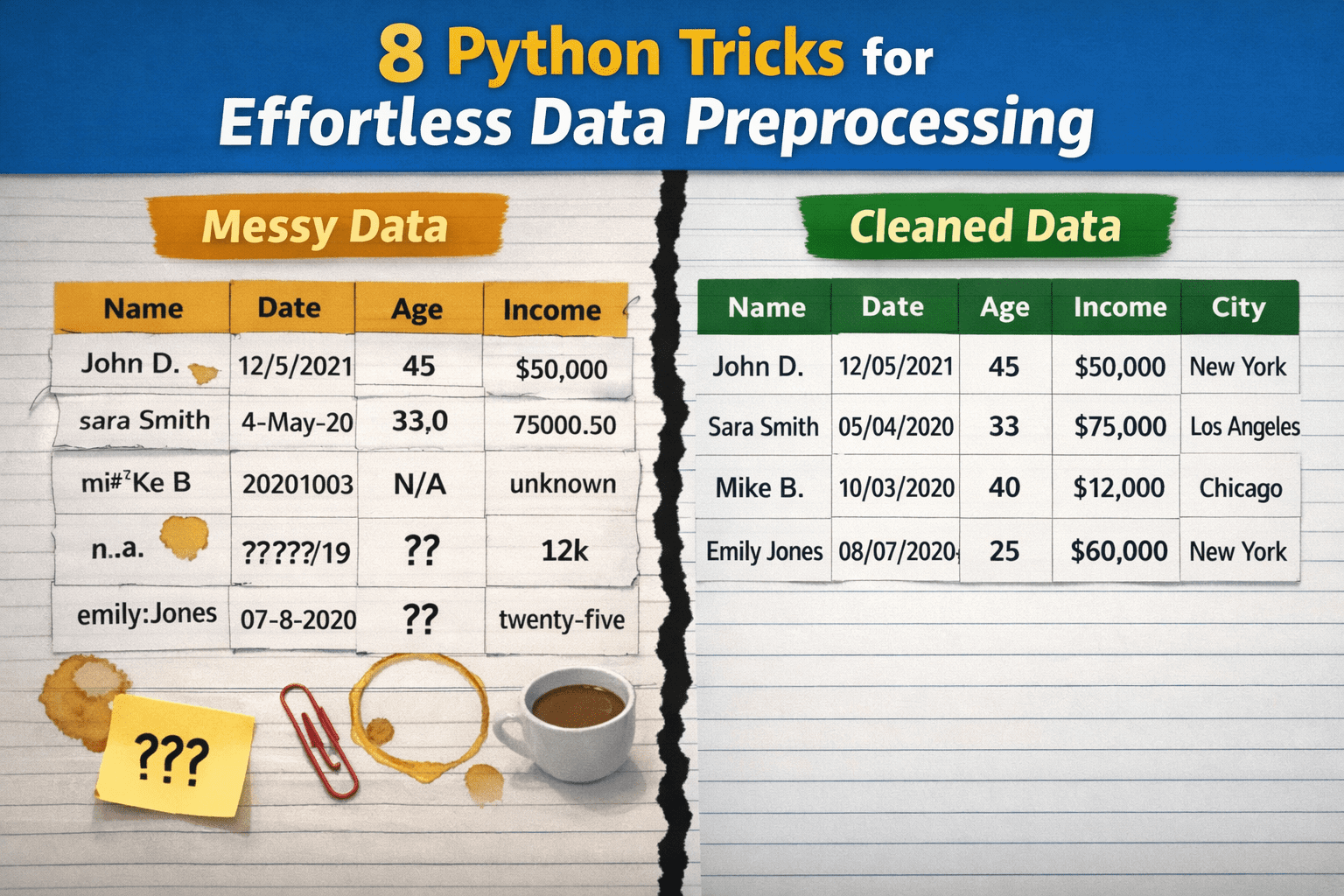
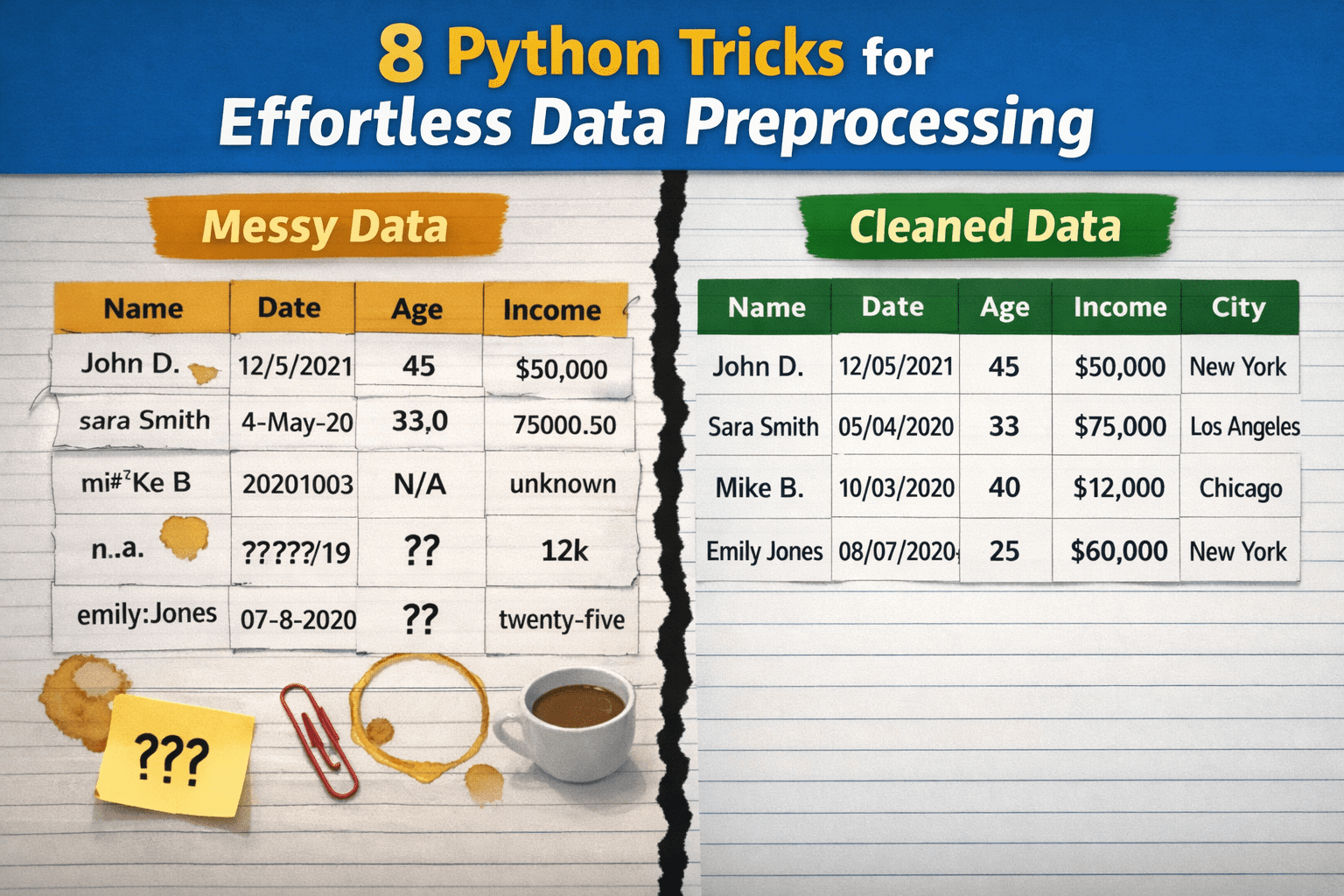
Während Datenvorverarbeitung Obwohl sie in den Arbeitsabläufen der Datenwissenschaft und des maschinellen Lernens von großer Bedeutung sind, werden diese Prozesse oft nicht korrekt durchgeführt, vor allem weil sie als übermäßig komplex, zeitaufwändig oder als erfordernd umfangreichen benutzerdefinierten Code angesehen werden. Infolgedessen verzögern Praktiker möglicherweise wichtige Aufgaben wie die Datenbereinigung, verlassen sich auf brüchige Advert-hoc-Lösungen, die auf lange Sicht nicht nachhaltig sind, oder überarbeiten Lösungen für Probleme, die im Kern einfach sein könnten.
In diesem Artikel werden 8 Python-Methods vorgestellt, um rohe, unordentliche Daten mit minimalem Aufwand in saubere, sauber vorverarbeitete Daten umzuwandeln.
Bevor wir uns die spezifischen Methods und begleitenden Codebeispiele ansehen, richtet der folgende Präambelcode die erforderlichen Bibliotheken ein und definiert einen Spielzeugdatensatz, um jeden Trick zu veranschaulichen:
import pandas as pd
import numpy as np
# A tiny, deliberately messy dataset
df = pd.DataFrame({
" Consumer Identify ": (" Alice ", "bob", "Bob", "alice", None),
"Age": ("25", "30", "?", "120", "28"),
"Earnings$": ("50000", "60000", None, "1000000", "55000"),
"Be part of Date": ("2023-01-01", "01/15/2023", "not a date", None, "2023-02-01"),
"Metropolis": ("New York", "the big apple ", "NYC", "New York", "nyc"),
})# 1. Spaltennamen sofort normalisieren
Dies ist ein sehr nützlicher Trick im Einzeiler-Stil: In einer einzigen Codezeile werden die Namen aller Spalten in einem Datensatz normalisiert. Die Einzelheiten hängen davon ab, wie genau Sie die Namen Ihrer Attribute normalisieren möchten. Das folgende Beispiel zeigt jedoch, wie Sie Leerzeichen durch Unterstrichsymbole und alles in Kleinbuchstaben ersetzen und so eine konsistente, standardisierte Namenskonvention sicherstellen. Dies ist wichtig, um lästige Fehler in nachgelagerten Aufgaben zu verhindern oder mögliche Tippfehler zu beheben. Es ist nicht nötig, Spalte für Spalte zu iterieren!
df.columns = df.columns.str.strip().str.decrease().str.exchange(" ", "_")# 2. Leerzeichen maßstabsgetreu aus Strings entfernen
Manchmal möchten Sie möglicherweise nur sicherstellen, dass bestimmte, für das menschliche Auge unsichtbare Daten, wie Leerzeichen am Anfang oder Ende von Zeichenfolgenwerten (kategorialen Werten), systematisch im gesamten Datensatz entfernt werden. Diese Strategie führt dies problemlos für alle Spalten aus, die Zeichenfolgen enthalten, während andere Spalten, wie z. B. numerische, unverändert bleiben.
df = df.apply(lambda s: s.str.strip() if s.dtype == "object" else s)# 3. Numerische Spalten sicher konvertieren
Wenn wir nicht 100 % sicher sind, dass alle Werte in einer numerischen Spalte einem identischen Format entsprechen, ist es im Allgemeinen eine gute Idee, diese Werte explizit in ein numerisches Format zu konvertieren und so aus manchmal unordentlichen Zeichenfolgen, die wie Zahlen aussehen, tatsächliche Zahlen zu machen. In einer einzigen Zeile können wir das tun, was sonst erforderlich wäre – außer Blöcken auszuprobieren und einen manuelleren Reinigungsvorgang durchzuführen.
df("age") = pd.to_numeric(df("age"), errors="coerce")
df("revenue$") = pd.to_numeric(df("revenue$"), errors="coerce")Beachten Sie hier, dass andere klassische Ansätze wie df('columna').astype(float) konnte manchmal abstürzen, wenn ungültige Rohwerte gefunden wurden, die nicht trivial in Zahlen umgewandelt werden können.
# 4. Daten analysieren mit errors="coerce"
Ähnliches validierungsorientiertes Verfahren, unterschiedlicher Datentyp. Dieser Trick konvertiert gültige Datums-/Uhrzeitwerte und macht ungültige Werte ungültig. Benutzen errors="coerce" ist der Schlüssel zum Erzählen Pandas dass, wenn ungültige, nicht konvertierbare Werte gefunden werden, diese umgewandelt werden müssen NaT (Keine Zeit), anstatt einen Fehler zu generieren und das Programm während der Ausführung zum Absturz zu bringen.
df("join_date") = pd.to_datetime(df("join_date"), errors="coerce")# 5. Beheben fehlender Werte mit intelligenten Standardeinstellungen
Für diejenigen, die nicht mit Strategien zum Umgang mit fehlenden Werten vertraut sind, außer mit dem Löschen ganzer Zeilen, die diese Werte enthalten: Diese Strategie imputiert diese Werte – füllt die Lücken – und verwendet dabei statistisch bedingte Standardwerte wie median oder mode. Eine effiziente, einzeilige Strategie, die mit verschiedenen Standardaggregaten angepasst werden kann. Der (0) Der dem Modus beigefügte Index wird verwendet, um bei Gleichständen zwischen zwei oder mehreren „häufigsten Werten“ nur einen Wert zu erhalten.
df("age") = df("age").fillna(df("age").median())
df("metropolis") = df("metropolis").fillna(df("metropolis").mode()(0))# 6. Kategorien mit Karte standardisieren
In kategorialen Spalten mit unterschiedlichen Werten, wie z. B. Städten, ist es auch notwendig, Namen zu standardisieren und mögliche Inkonsistenzen zu reduzieren, um sauberere Gruppennamen zu erhalten und nachgelagerte Gruppenaggregationen zu erstellen groupby() zuverlässig und effektiv. Mithilfe eines Wörterbuchs wendet dieses Beispiel eine Eins-zu-eins-Zuordnung auf Zeichenfolgenwerte an, die sich auf New York Metropolis beziehen, um sicherzustellen, dass alle einheitlich mit „NYC“ bezeichnet werden.
city_map = {"the big apple": "NYC", "nyc": "NYC"}
df("metropolis") = df("metropolis").str.decrease().map(city_map).fillna(df("metropolis"))# 7. Duplikate klug und flexibel entfernen
Der Schlüssel für diese hochgradig anpassbare Strategie zum Entfernen von Duplikaten ist die Verwendung von subset=("user_name"). In diesem Beispiel wird es verwendet, um Pandas anzuweisen, eine Zeile nur durch Betrachten als dupliziert zu betrachten "user_name" Spalte und überprüfen, ob der Wert in der Spalte mit dem in einer anderen Zeile identisch ist. Eine großartige Möglichkeit, sicherzustellen, dass jeder einzelne Benutzer nur einmal in einem Datensatz vertreten ist, wodurch Doppelzählungen vermieden werden und alles in einer einzigen Anweisung erledigt wird.
df = df.drop_duplicates(subset=("user_name"))# 8. Clipping-Quantile zur Entfernung von Ausreißern
Der letzte Trick besteht darin, Extremwerte oder Ausreißer automatisch zu begrenzen, anstatt sie vollständig zu entfernen. Besonders nützlich, wenn davon ausgegangen wird, dass Ausreißer beispielsweise auf manuell eingeführte Fehler in den Daten zurückzuführen sind. Durch das Abschneiden werden die Extremwerte festgelegt, die unter (und über) zwei Perzentilen (im Beispiel 1 und 99) liegen, wobei solche Perzentilwerte die ursprünglichen Werte, die zwischen den beiden angegebenen Perzentilen liegen, unverändert lassen. Vereinfacht ausgedrückt ist es so, als würde man zu große oder zu kleine Werte innerhalb der Grenzen halten.
q_low, q_high = df("revenue$").quantile((0.01, 0.99))
df("revenue$") = df("revenue$").clip(q_low, q_high)# Zusammenfassung
In diesem Artikel wurden acht nützliche Methods, Tipps und Strategien vorgestellt, die Ihre Datenvorverarbeitungs-Pipelines in Python verbessern und sie gleichzeitig effizienter, effektiver und robuster machen.
Iván Palomares Carrascosa ist ein führender Autor, Redner und Berater in den Bereichen KI, maschinelles Lernen, Deep Studying und LLMs. Er schult und leitet andere darin, KI in der realen Welt zu nutzen.