
In den letzten Jahren folgte die KI-Welt einer einfachen Regel: Wenn Sie möchten, dass ein Giant Language Mannequin (LLM) ein schwierigeres Drawback löst, erstellen Sie es Gedankenkette (CoT) länger. Aber neue Forschungsergebnisse aus dem Universität von Virginia Und Google beweist, dass „langes Nachdenken“ nicht dasselbe ist wie „starkes Nachdenken“.
Das Forschungsteam zeigt, dass durch einfaches Hinzufügen weiterer Token zu einer Antwort tatsächlich eine KI entstehen kann weniger genau. Statt Wörter zu zählen, führen die Google-Forscher eine neue Messung ein: die Deep-Considering-Verhältnis (DTR).
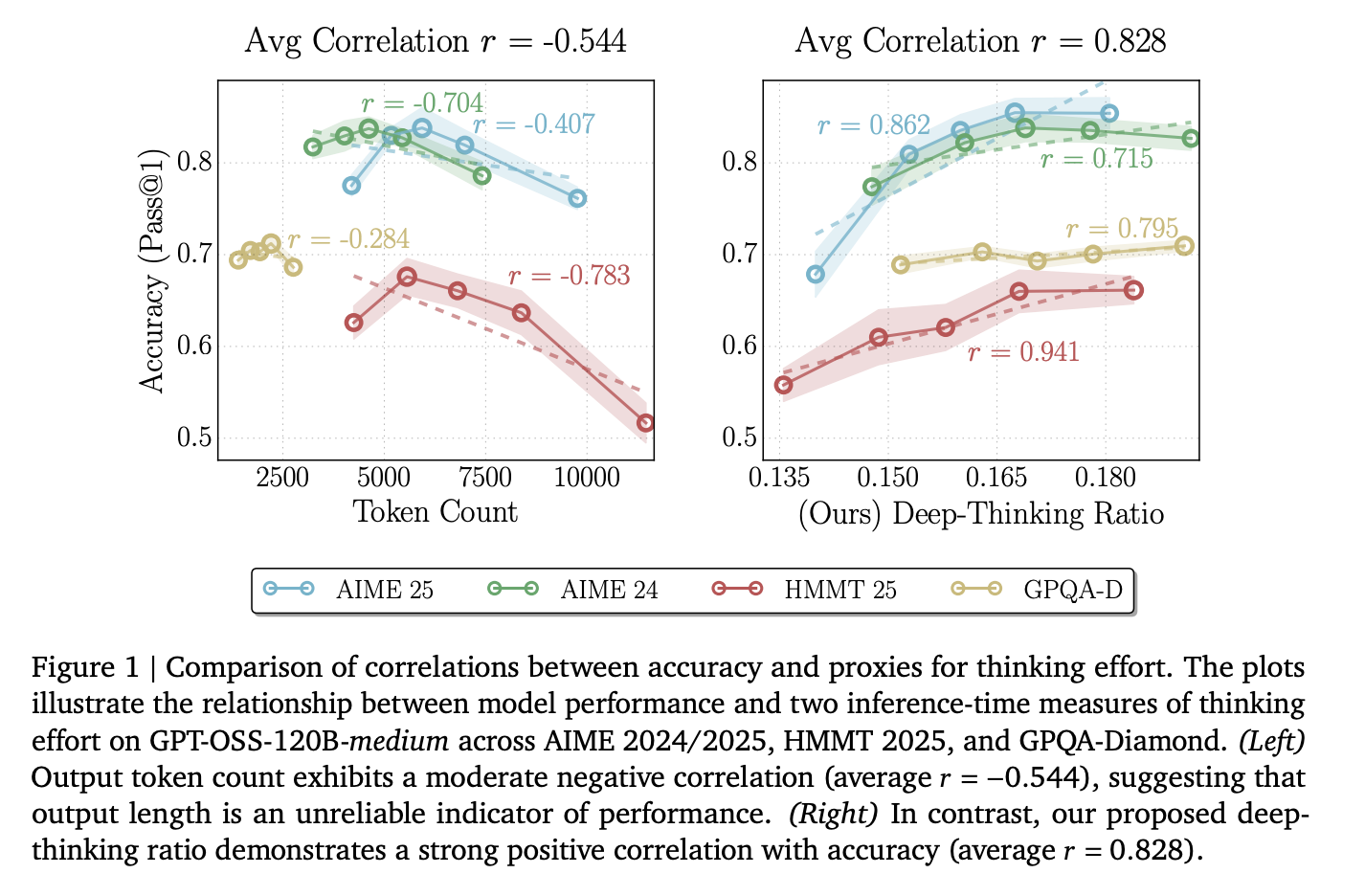
Das Scheitern von „Token Maxing“.‚
Ingenieure verwenden die Token-Zählung häufig als Indikator für den Aufwand, den eine KI für eine Aufgabe aufwendet. Die Forscher fanden jedoch heraus, dass die reine Tokenanzahl eine durchschnittliche Korrelation von aufweist r= -0,59 mit Genauigkeit.
Diese adverse Zahl bedeutet, dass die Wahrscheinlichkeit größer ist, dass das Modell falsch ist, je mehr Textual content es generiert. Dies geschieht aufgrund von „Überdenken“, bei dem das Modell in Schleifen stecken bleibt, überflüssige Schritte wiederholt oder seine eigenen Fehler verstärkt. Wenn man sich allein auf die Länge verlässt, wird teure Rechenleistung für nicht informative Token verschwendet.
Was sind Deep-Considering-Token?
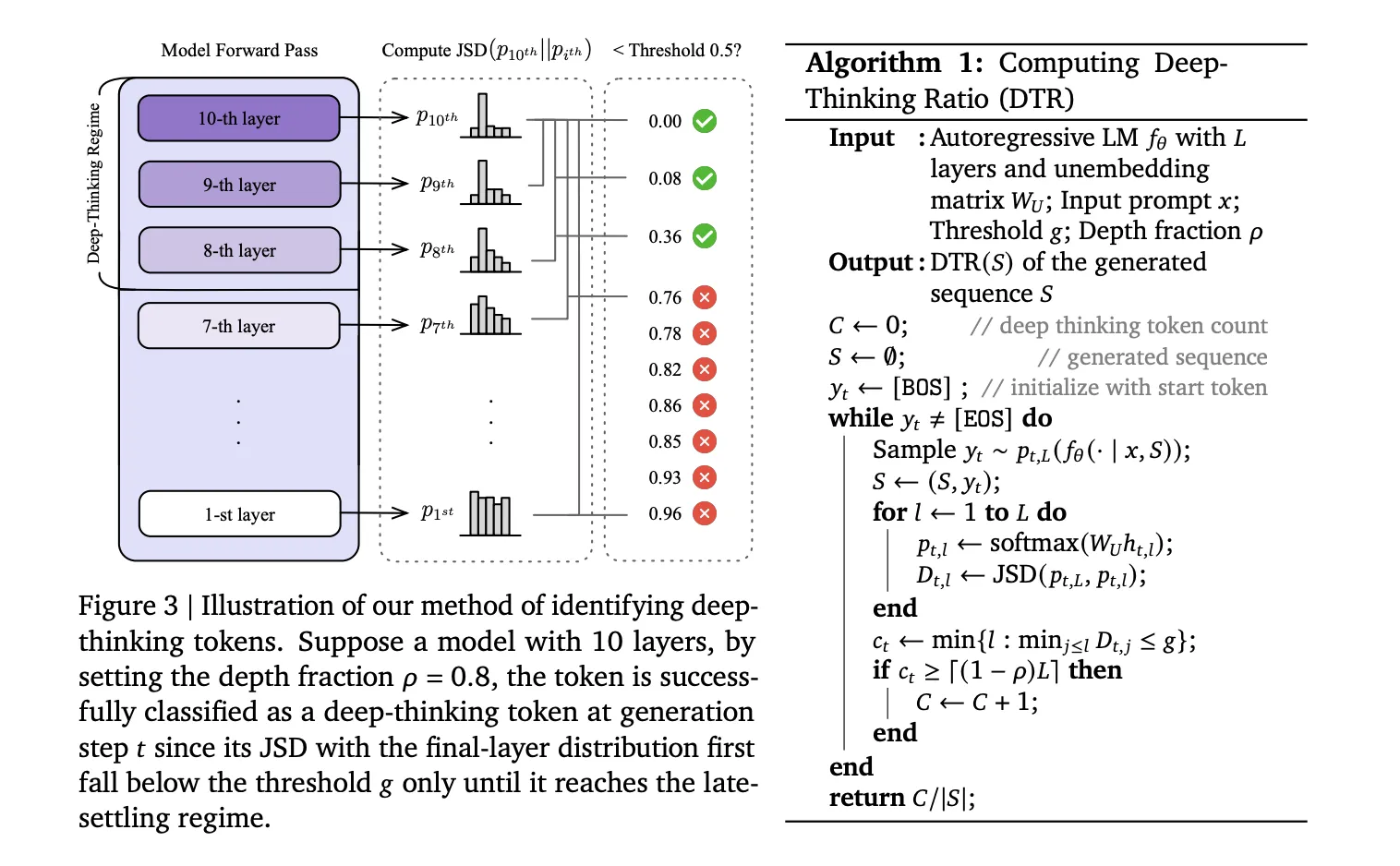
Das Forschungsteam argumentierte, dass echtes „Denken“ innerhalb der Schichten des Modells stattfindet und nicht nur in der Endausgabe. Wenn ein Modell ein Token vorhersagt, verarbeitet es Daten über eine Reihe von Transformatorschichten (L).
- Flache Token: Bei einfachen Worten stabilisiert sich die Vorhersage des Modells frühzeitig. Die „Vermutung“ ändert sich von Schicht 5 bis Schicht 36 nicht wesentlich.
- Tiefdenkende Token: Bei schwierigen logischen oder mathematischen Symbolen verschiebt sich die Vorhersage erheblich in die tieferen Schichten.
So messen Sie die Tiefe
Um diese Token zu identifizieren, verwendet das Forschungsteam eine Technik, um einen Blick auf die internen „Entwürfe“ des Modells auf jeder Ebene zu werfen. Sie projizieren die verborgenen Zwischenzustände (htl) mithilfe des Modells in den Vokabularraum einzufügen nicht einbettende Matrix (WU). Dadurch entsteht eine Wahrscheinlichkeitsverteilung (St,l) für jede Ebene.
Anschließend berechnen sie die Jensen-Shannon-Divergenz (JSD) zwischen der Zwischenschichtverteilung und der Endschichtverteilung (St,L):
Dt,l := JSD(St,L || Pt,l)
Ein Token ist ein tiefgründiges Zeichen wenn sich seine Vorhersage nur im „späten Regime“ einpendelt – definiert durch a Tiefenanteil (⍴). In ihren Assessments stellten sie fest ⍴= 0,85, was bedeutet, dass sich der Token nur in den letzten 15 % der Schichten stabilisiert hat.
Der Deep-Considering-Verhältnis (DTR) ist der Prozentsatz dieser „harten“ Token in einer vollständigen Sequenz. Modellübergreifend wie DeepSeek-R1-70B, Qwen3-30B-DenkenUnd GPT-OSS-120BDTR zeigte eine starke durchschnittliche optimistic Korrelation von r = 0,683 mit Genauigkeit.
Suppose@n: Höhere Genauigkeit bei 50 % der Kosten
Das Forschungsteam nutzte diesen innovativen Ansatz zur Erstellung Suppose@neine neue Möglichkeit, die KI-Leistung während der Inferenz zu skalieren.
Die meisten Entwickler verwenden Selbstkonsistenz (Cons@n)wo sie probieren 48 Geben Sie verschiedene Antworten ein und nutzen Sie die Mehrheitsentscheidung, um die beste Antwort auszuwählen. Das ist sehr aufwendig, da man für jede Antwort jedes einzelne Token generieren muss.
Suppose@n verändert das Spiel durch den Einsatz von „frühem Anhalten“:
- Das Modell beginnt mit der Generierung mehrerer Kandidatenantworten.
- Nach gerade 50 Präfix-Tokenberechnet das System die DTR für jeden Kandidaten.
- Es stoppt sofort die Generierung der „aussichtslosen“ Kandidaten mit niedrigem DTR.
- Es beendet die Kandidaten nur mit hohen Werten für tiefes Denken.
Die Ergebnisse zu AIME 2025
| Verfahren | Genauigkeit | Durchschn. Kosten (ok Token) |
| Nachteile@n (Mehrheitsabstimmung) | 92,7 % | 307,6 |
| Suppose@n (DTR-basierte Auswahl) | 94,7 % | 155,4 |
Auf der ZIEL 25 Mathe-Benchmark, Suppose@n erreicht höhere Genauigkeit als bei der Standardabstimmung, während die Inferenzkosten um reduziert werden 49 %.
Wichtige Erkenntnisse
- Die Anzahl der Token ist ein schlechter Indikator für die Genauigkeit: Die Länge der Rohausgabe weist eine durchschnittliche adverse Korrelation (r = -0,59) mit der Leistung auf, was bedeutet, dass längere Argumentationsspuren oft eher auf „Überdenken“ als auf höhere Qualität hinweisen.
- Tiefdenkende Token definieren wahre Anstrengung: Im Gegensatz zu einfachen Token, die sich in frühen Schichten stabilisieren, handelt es sich bei Deep-Considering-Token um solche, deren interne Vorhersagen in tieferen Modellschichten erheblich überarbeitet werden, bevor sie konvergieren.
- Die Deep-Considering Ratio (DTR) ist eine überlegene Messgröße: DTR misst den Anteil von Deep-Considering-Tokens in einer Sequenz und weist eine robuste optimistic Korrelation mit der Genauigkeit auf (durchschnittliches r = 0,683) und übertrifft durchweg längenbasierte oder konfidenzbasierte Basislinien.
- Suppose@n ermöglicht eine effiziente Testzeitskalierung: Indem nur die Stichproben mit hohen Deep-Considering-Verhältnissen priorisiert und abgeschlossen werden, erreicht oder übertrifft die Suppose@n-Strategie die Leistung der Standardmehrheitsabstimmung (Cons@n).
- Huge Kostenreduzierung durch frühzeitiges Anhalten: Da die DTR anhand eines kurzen Präfixes von nur 50 Token geschätzt werden kann, können aussichtslose Generationen frühzeitig abgelehnt werden, wodurch die gesamten Inferenzkosten um etwa 50 % gesenkt werden.
Schauen Sie sich das an Papier. Sie können uns auch gerne weiter folgen Twitter und vergessen Sie nicht, bei uns mitzumachen 100.000+ ML SubReddit und Abonnieren Unser Publication. Warten! Bist du im Telegram? Jetzt können Sie uns auch per Telegram kontaktieren.
