
Haben Sie einem LLM jemals eine Frage gestellt, den Wortlaut ein paar Mal geändert und immer noch das Gefühl, dass die Antwort nicht ganz richtig battle? Wenn Sie mit Instruments wie gearbeitet haben ChatGPT oder Zwillingehaben Sie wahrscheinlich Eingabeaufforderungen umgeschrieben, mehr Kontext hinzugefügt oder Formulierungen wie „Seien Sie prägnant“ oder „Denken Sie Schritt für Schritt“ verwendet, um die Ergebnisse zu verbessern. Aber was wäre, wenn die Verbesserung der Genauigkeit so einfach wäre, indem Sie Ihre gesamte Eingabeaufforderung kopieren und erneut einfügen? Das ist die Idee hinter der prompten Wiederholung. Das hört sich vielleicht zu einfach an, aber Untersuchungen zeigen, dass die Genauigkeit vieler Aufgaben erheblich verbessert werden kann, wenn Sie dem Modell Ihre Frage zweimal stellen, was es zu einer der einfachsten Leistungssteigerungen macht, die Sie ausprobieren können.
Was ist schnelle Wiederholung und warum sollte man sie ausprobieren?
Um zu verstehen, warum Wiederholungen hilfreich sind, müssen wir uns ansehen, wie LLMs Textual content verarbeiten. Die meisten großen Sprachmodelle werden auf kausale Weise trainiert. Sie sagen Token einzeln voraus, und jeder Token kann sich nur um die Token kümmern, die vor ihm kamen. Das bedeutet, dass die Reihenfolge der Informationen in Ihrer Eingabeaufforderung das Verständnis des Modells beeinflussen kann.
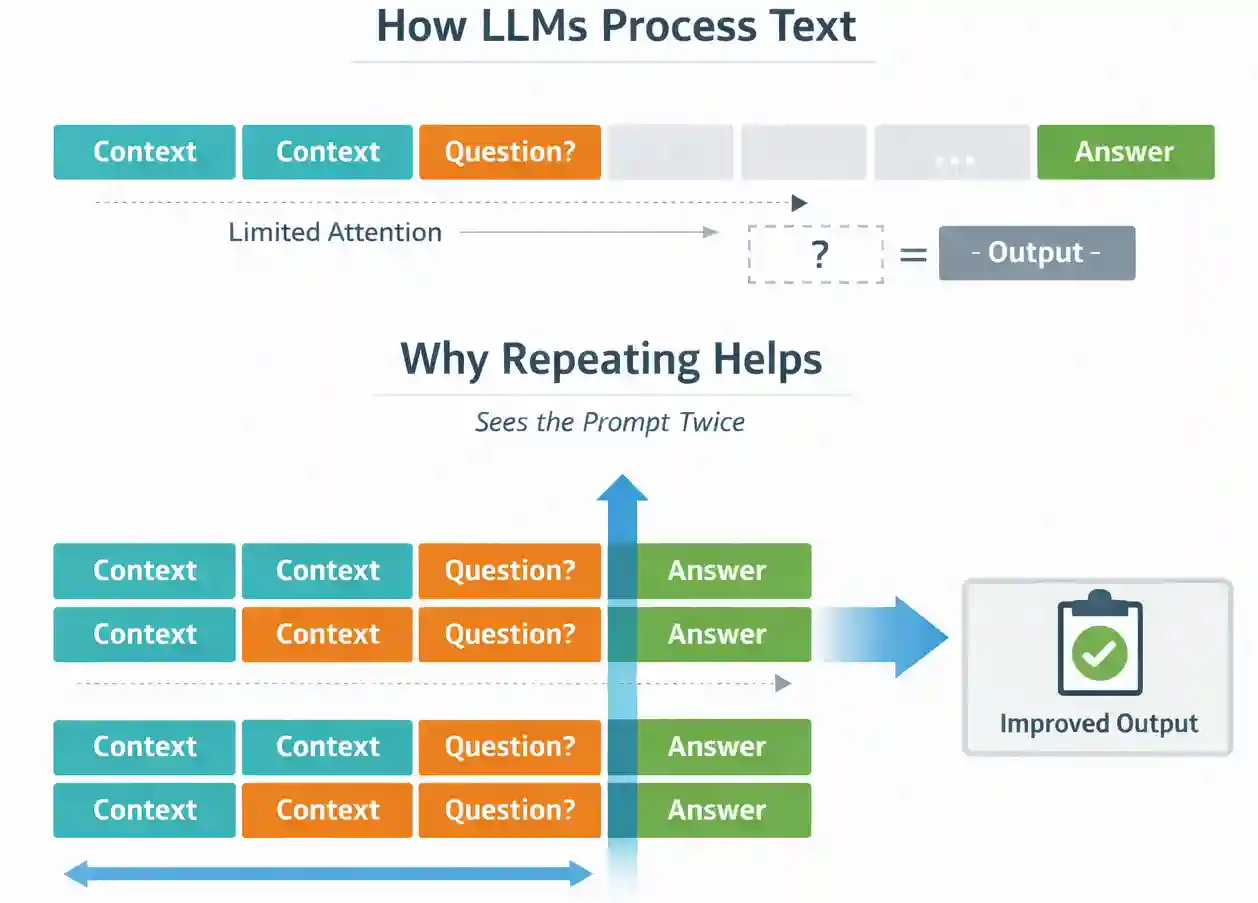
Eine zeitnahe Wiederholung trägt dazu bei, diesen Ordnungseffekt zu reduzieren. Wenn Sie die Eingabeaufforderung duplizieren, erhält jeder Token eine weitere Möglichkeit, sich um alle relevanten Informationen zu kümmern. Anstatt den Kontext nur einmal zu sehen, verarbeitet das Modell ihn effektiv zweimal während der Eingabephase (Vorausfüllung).
Wichtig ist, dass dies geschieht, bevor das Modell mit der Generierung einer Antwort beginnt. Das Ausgabeformat ändert sich nicht und das Modell generiert keine zusätzlichen Token. Sie verbessern lediglich die Artwork und Weise, wie das Modell die Eingabe verarbeitet.
Lesen Sie auch: Immediate Engineering Information 2026
Prompte Wiederholung in Aktion
In der Studie wurde die schnelle Wiederholung von sieben verschiedenen Aufgaben mithilfe von sieben LLMs bewertet. Dabei handelte es sich nicht um kleine Versuchsmodelle. Dazu gehörten weit verbreitete Modelle wie Gemini, GPT-4oClaude und DeepSeekZugriff über ihre offiziellen APIs. Die sieben Aufgaben bestanden aus:
Fünf Normal-Benchmarks:
- ARC (Fragen zum wissenschaftlichen Denken)
- OpenBookQA
- GSM8K (Mathe-Textaufgaben)
- MMLU-Professional (Multi-Area-Wissen)
- MATHE
Zwei maßgeschneiderte Aufgaben:
Die benutzerdefinierten Aufgaben wurden speziell entwickelt, um zu testen, wie intestine Modelle mit strukturierten und Positionsinformationen umgehen.
Für jede Aufgabe verglichen die Forscher zwei Setups:
- Die Baseline-Eingabeaufforderung
- Die exakt gleiche Aufforderung wiederholte sich zweimal
Sonst wurde nichts geändert. Das Ausgabeformat blieb gleich. Das Modell wurde nicht fein abgestimmt. Der einzige Unterschied bestand darin, dass die Eingabe dupliziert wurde.
Anschließend haben sie Folgendes gemessen:
- Genauigkeit
- Ausgabelänge
- Latenz
Leitfaden zu KI-Benchmarks, die alles abdecken, was MMLU, HumanEval und mehr erklärt
Ergebnis des Immediate-Repetition-Experiments
Bei insgesamt siebzig Vergleichen, die verschiedene Modelle und Benchmarks abdeckten, verbesserte die sofortige Wiederholung die Genauigkeit um das 47-fache. Es hat die Leistung nie wesentlich beeinträchtigt. Die Verbesserungen machten sich besonders bei A number of-Alternative-Formaten und strukturierten Aufgaben bemerkbar, bei denen das Modell Positionsinformationen sorgfältig verfolgen musste.
Beispiel aus dem Artikel: Die NameIndex-Aufgabe
Bei der NameIndex-Aufgabe erhält das Modell eine Liste mit 50 Namen und eine direkte Frage: „Was ist der 25. Title?“ Die Aufgabe erfordert keine Begründung oder Interpretation. Es ist lediglich eine genaue Positionsverfolgung innerhalb einer Liste erforderlich.
In der Grundeinstellung battle die Leistung gering. Gemini 2.0 Flash Lite erreichte beispielsweise eine Genauigkeit von 21,33 %. Durch schnelle Wiederholung stieg die Genauigkeit auf 97,33 %. Dies ist eine wesentliche Verbesserung der Zuverlässigkeit.
Für die Listenindizierung muss das Modell Reihenfolge und Place korrekt kodieren. Wenn die Eingabeaufforderung einmal angezeigt wird, verarbeitet das Modell die Liste und die Frage in einem einzigen Durchgang. Einige Positionsbeziehungen werden möglicherweise nicht stark verstärkt. Wenn die vollständige Liste und Frage wiederholt werden, verarbeitet das Modell die Struktur effektiv zweimal, bevor es antwortet. Dadurch wird die interne Repräsentation der Ordnung gestärkt.
Aber was ist mit Latenz und Token-Kosten?
Immer wenn wir die Genauigkeit verbessern, stellt sich die nächste Frage: Was kostet das? Überraschenderweise quick nichts.
Diese Zahlen vergleichen:
- Genauigkeit
- Durchschnittliche Antwortlänge
- Mittlere Antwortlänge
- Latenz
Die wichtigste Erkenntnis:
- Durch eine schnelle Wiederholung wird die Länge des Ausgabetokens nicht erhöht.
- Das Modell generiert keine längeren Antworten.
- Auch die Latenz bleibt ungefähr gleich, außer in sehr langen Eingabeaufforderungsszenarien (insbesondere bei Anthropic-Modellen), bei denen die Vorfüllphase etwas länger dauert.
Dies ist in Produktionssystemen wichtig.
Im Gegensatz zum Chain-of-Considering-Prompting, das die Token-Generierung und die Kosten erhöht, verschiebt die Immediate-Wiederholung die Berechnung in die Prefill-Part, die parallelisierbar ist.
In realen Anwendungen:
- Ihre Kosten professional Anfrage steigen nicht
- Ihr Antwortformat bleibt identisch
- Ihre nachgelagerte Parsing-Logik bleibt erhalten
Dadurch ist es äußerst einsatzfreundlich.
Wann funktioniert eine schnelle Wiederholung am besten?
Eine schnelle Wiederholung löst nicht jedes Drawback auf magische Weise. Die Forschung zeigt, dass es bei nicht-logischen Aufgaben am effektivsten ist, insbesondere wenn das Modell strukturierte oder geordnete Informationen sorgfältig verarbeiten muss.
Es funktioniert in der Regel am besten in folgenden Szenarien:
- Beantwortung von A number of-Alternative-Fragen
- Aufgaben mit langem Kontext, gefolgt von einer kurzen Frage
- Probleme bei der Indexierung oder beim Abrufen von Hear
- Strukturierte Datenextraktion
- Klassifizierungsaufgaben mit klar definierten Labels
Die Verbesserungen machen sich insbesondere dann bemerkbar, wenn das Modell Positionen oder Beziehungen innerhalb strukturierter Eingaben korrekt verfolgen muss. Durch die Wiederholung der Aufforderung werden diese Beziehungen gestärkt.
Wenn jedoch explizites Denken ermöglicht wird, beispielsweise indem das Modell dazu aufgefordert wird, „Schritt für Schritt zu denken“, werden die Vorteile geringer. In diesen Fällen wiederholt oder verarbeitet das Modell Teile der Frage während der Argumentation oft ohnehin noch einmal. Wiederholungen beeinträchtigen die Leistung immer noch nicht, aber die Verbesserung ist in der Regel eher impartial als dramatisch.
Der Schlüssel zum Erfolg ist einfach. Wenn Ihre Aufgabe keine lange Gedankenkette erfordert, ist eine schnelle Wiederholung wahrscheinlich einen Versuch wert.
So implementieren Sie zeitnahe Wiederholungen in die Praxis
Die Umsetzung ist unkompliziert. Sie benötigen keine Spezialwerkzeuge oder Modelländerungen. Sie duplizieren einfach die Eingabezeichenfolge, bevor Sie sie an das Modell senden.
Anstatt zu senden:
immediate = questionSie senden:
immediate = question + "n" + questionDas ist die ganze Veränderung.
Es gibt einige praktische Überlegungen. Stellen Sie zunächst sicher, dass die Länge Ihrer Eingabeaufforderung das Kontextfenster des Modells nicht überschreitet. Das Verdoppeln einer sehr langen Eingabeaufforderung kann dazu führen, dass Sie an Ihre Grenzen geraten. Zweitens testen Sie die Änderung an Ihrer spezifischen Aufgabe. Während die Forschung beständige Zuwächse zeigt, weist jedes Produktionssystem seine eigenen Merkmale auf.
Der Vorteil dieses Ansatzes besteht darin, dass sich sonst nichts in Ihrem System ändern muss. Ihr Ausgabeformat bleibt gleich. Ihre Parsing-Logik bleibt dieselbe. Ihre Evaluierungspipeline bleibt dieselbe. Dies erleichtert das Experimentieren ohne Risiko.
Prompte Wiederholung vs. Gedankenkettenanregung
Es ist wichtig zu verstehen, wie sich eine schnelle Wiederholung von einer Gedankenkettenaufforderung unterscheidet.
Die Aufforderung zur Gedankenkette ermutigt das Modell, seine Argumentation Schritt für Schritt zu erklären. Dies verbessert häufig die Leistung bei mathematischen und logikintensiven Aufgaben, erhöht jedoch die Ausgabelänge und die Token-Nutzung. Es verändert auch die Struktur der Antwort.
Schnelle Wiederholung bewirkt etwas anderes. Der Ausgabestil wird dadurch nicht geändert. Das Modell wird nicht aufgefordert, laut zu argumentieren. Stattdessen wird die Artwork und Weise gestärkt, wie die Eingabe codiert wird, bevor mit der Generierung begonnen wird.
In den Experimenten, bei denen Argumentationsaufforderungen verwendet wurden, führte die Wiederholung zu überwiegend neutralen Ergebnissen. Das macht Sinn. Wenn das Modell die Frage während seines Argumentationsprozesses bereits erneut aufgreift, werden durch das Duplizieren der Eingabeaufforderung nur wenige neue Informationen hinzugefügt.
Für Aufgaben, die detaillierte Überlegungen erfordern, kann die Gedankenkette dennoch nützlich sein. Für strukturierte oder klassifizierungsartige Aufgaben, bei denen Sie prägnante Antworten benötigen, bietet eine zeitnahe Wiederholung eine einfachere und kostengünstigere Verbesserung.
Praktische Erkenntnisse für Ingenieure
Wenn Sie LLM-gestützte Systeme bauen, schlägt diese Studie Folgendes vor:
- Testen Sie schnelle Wiederholungen bei Aufgaben, bei denen es sich nicht um logisches Denken handelt.
- Priorisieren Sie strukturierte oder positionsabhängige Arbeitsabläufe.
- Messen Sie die Genauigkeit vor und nach der Änderung.
- Überwachen Sie die Kontextlänge, um zu vermeiden, dass die Token-Grenzwerte erreicht werden.
Da sich bei dieser Methode weder die Ausgabeformatierung ändert noch die Latenz erheblich erhöht, ist das Testen in Staging-Umgebungen sicher. In vielen Fällen kann die Robustheit verbessert werden, ohne dass Architekturänderungen oder Feinabstimmungen erforderlich sind.
In Produktionssystemen, in denen kleine Genauigkeitsverbesserungen zu messbaren geschäftlichen Auswirkungen führen, können sogar wenige Prozentpunkte von Bedeutung sein. Bei einigen strukturierten Aufgaben sind die Gewinne viel größer.
Lesen Sie auch:
Abschluss
Schnelles Engineering fühlt sich oft wie Versuch und Irrtum an. Wir passen die Formulierungen an, fügen Einschränkungen hinzu und experimentieren mit verschiedenen Anweisungen. Die Idee, dass die Genauigkeit durch einfaches Wiederholen der gesamten Eingabeaufforderung verbessert werden kann, magazine trivial klingen, doch die experimentellen Erkenntnisse deuten auf etwas anderes hin.
Über mehrere Modelle und sieben verschiedene Aufgaben hinweg verbesserte die schnelle Wiederholung die Leistung kontinuierlich, ohne die Ausgabelänge zu erhöhen oder die Latenz wesentlich zu beeinträchtigen. Der Ansatz ist einfach zu implementieren, erfordert keine erneute Schulung und verändert die Antwortformatierung nicht.
Probieren Sie es selbst aus und teilen Sie mir Ihre Meinung im Kommentarbereich mit.
Alle Particulars finden Sie hier: Schnelle Wiederholung verbessert die Forschungsarbeit zu nicht-begründenden LLMs
Hallo, ich bin Nitika, eine technisch versierte Content material-Erstellerin und Vermarkterin. Kreativität und das Lernen neuer Dinge sind für mich selbstverständlich. Ich habe Erfahrung in der Erstellung ergebnisorientierter Content material-Strategien. Ich kenne mich intestine mit Search engine optimisation-Administration, Key phrase-Operationen, Internet-Content material-Schreiben, Kommunikation, Content material-Strategie, Redaktion und Schreiben aus.
Melden Sie sich an, um weiterzulesen und von Experten kuratierte Inhalte zu genießen.