
In der hochriskanten Welt der KI-Infrastruktur geht die Branche von einer einzigen Annahme aus: Flexibilität ist Trumpf. Wir bauen Allzweck-GPUs, weil sich KI-Modelle jede Woche ändern und wir programmierbares Silizium benötigen, das sich an den nächsten Forschungsdurchbruch anpassen kann.
Aber TaalasDas in Toronto ansässige Startup glaubt, dass Flexibilität genau das ist, was KI zurückhält. Laut dem Taalas-Group müssen wir aufhören, Intelligenz auf Allzweckcomputern zu „simulieren“, und stattdessen damit beginnen, sie direkt in Silizium zu „gießen“, wenn wir wollen, dass KI so verbreitet und billig wie Plastik ist.
Das Drawback: Die „Reminiscence Wall“ und die GPU-Steuer
Die aktuellen Kosten für den Betrieb eines Massive Language Mannequin (LLM) werden durch einen physischen Engpass bestimmt: den Erinnerungswand.
Herkömmliche Prozessoren (GPUs) basieren auf der „Instruction Set Structure“ (ISA). Sie trennen Rechenleistung und Speicher. Wenn Sie einen Inferenzdurchlauf auf einem Modell wie Llama-3 ausführen, verbringt der Chip den größten Teil seiner Zeit und Energie damit, Gewichte vom Excessive Bandwidth Reminiscence (HBM) zu den Verarbeitungskernen zu transportieren. Diese „Datenbewegungssteuer“ macht quick 90 % des Stromverbrauchs in modernen KI-Rechenzentren aus.
Die Lösung von Taalas ist radikal: Eliminieren Sie den Speicherabrufzyklus. Mithilfe eines proprietären automatisierten Designablaufs übersetzt Taalas den Rechengraphen eines bestimmten Modells direkt in das physische Format eines Chips. In ihrem HC1 (Hardcore 1)-Chip sind die Gewichte und die Architektur des Modells buchstäblich in die Verkabelung des Siliziums eingraviert.

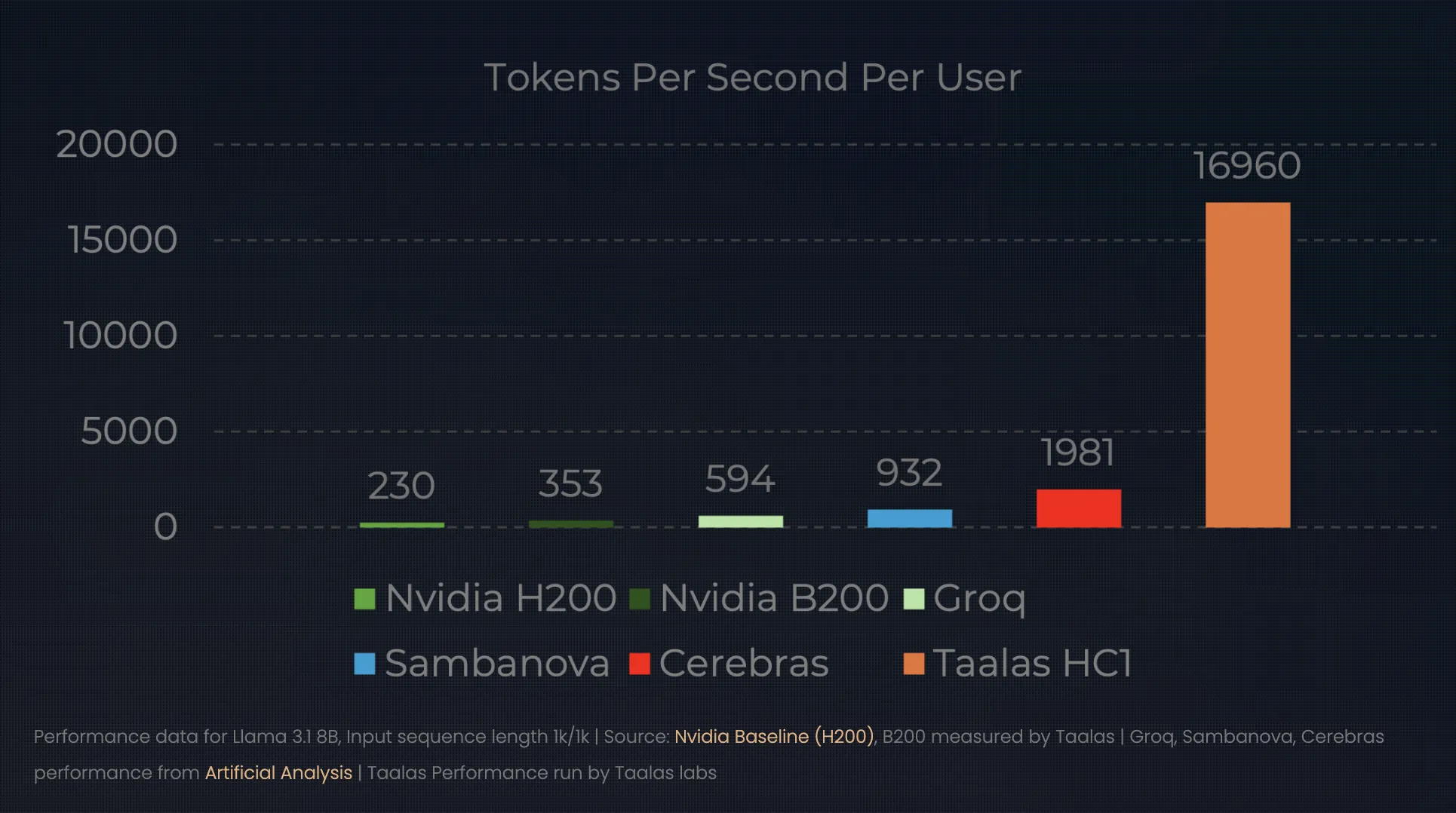
Hardcore-Modelle: 17.000 Token professional Sekunde
Die Ergebnisse dieses „Direct-to-Silicon“-Ansatzes definieren die Leistungsobergrenze für Inferenz neu. Bei ihrer letzten Enthüllung demonstrierte Taalas das HC1 Betrieb eines Llama 3.1 8B-Modells. Während ein NVIDIA H100 der Spitzenklasse einen einzelnen Benutzer mit etwa 150 Token professional Sekunde bedienen kann, leistet der HC1 eine atemberaubende Leistung 16.000 bis 17.000 Token professional Sekunde.
Dies verändert die „Einheitsökonomie“ der KI:
- Leistung: Ein einzelner HC1-Chip kann ein kleines GPU-Rechenzentrum hinsichtlich des Rohdurchsatzes für ein bestimmtes Modell übertreffen.
- Effizienz: Taalas behauptet a 1000-fache Verbesserung in der Effizienz (Leistung professional Watt und Leistung professional Greenback) im Vergleich zu herkömmlichen Chips.
- Infrastruktur: Da die Gewichte fest verdrahtet sind, sind kein externes HBM oder komplexe Flüssigkeitskühlsysteme erforderlich. Ein standardmäßiges luftgekühltes Rack kann zehn dieser 250-W-Karten aufnehmen und liefert so die Leistung eines gesamten GPU-Clusters in einer einzigen Serverbox.
Die 60-Tage-Grenze durchbrechen: Die automatisierte Gießerei
Der offensichtliche Haken für einen KI-Entwickler ist Flexibilität. Wenn Sie heute ein Modell fest in einen Chip integrieren, was passiert, wenn morgen ein besseres Modell herauskommt? In der Vergangenheit dauerte der Entwurf eines ASIC (Software-Particular Built-in Circuit) zwei Jahre und kostete mehrere zehn Millionen Greenback.
Taalas hat dieses Drawback gelöst Automatisierung. Sie haben ein Compiler-ähnliches Gießereisystem aufgebaut, das Modellgewichte nimmt und in etwa einer Woche ein Chipdesign generiert. Durch die Konzentration auf einen optimierten Fertigungsablauf, bei dem nur die oberen Metallmasken des Siliziums ausgetauscht werden, konnten sie die Durchlaufzeit von „Gewichte zu Silizium“ auf nur noch wenige Sekunden verkürzen zwei Monate.
Dies ermöglicht einen „saisonalen“ Hardwarezyklus. Ein Unternehmen könnte im Frühjahr die Feinabstimmung eines Grenzmodells vornehmen und bis zum Sommer Tausende spezialisierter, hocheffizienter Inferenzchips im Einsatz haben.
Der Marktwandel: Von Schaufeln zu Briefmarken
Dieser Übergang markiert einen entscheidenden Second im KI-Hype-Zyklus. Wir bewegen uns von der Part „Forschung und Schulung“, in der GPUs für ihre Flexibilität von entscheidender Bedeutung sind, zur Part „Bereitstellung und Inferenz“, in der die Kosten professional Token die einzige Messgröße sind, die zählt.
Wenn Taalas erfolgreich ist, wird sich der KI-Markt in zwei verschiedene Ebenen aufteilen:
- Allgemeine Schulung: Unter der Leitung von NVIDIA und AMD werden die riesigen, flexiblen Cluster bereitgestellt, die zum Entdecken und Trainieren neuer Architekturen erforderlich sind.
- Spezialisierte Schlussfolgerung: Angeführt von „Gießereien“ wie Taalas, die diese bewährten Architekturen nutzen und sie in billiges, allgegenwärtiges Silizium für alles von Smartphones bis hin zu Industriesensoren „drucken“.
Wichtige Erkenntnisse
- Der „festverdrahtete“ Paradigmenwechsel: Taalas zieht um softwaredefinierte KI (Ausführen von Modellen auf Allzweck-GPUs) bis Hardwaredefinierte KI. Indem sie die Gewichte und Architektur eines bestimmten Modells direkt in das Silizium „einbacken“, machen sie den herkömmlichen Befehlssatz-Overhead überflüssig und machen das Modell effektiv zum Prozessor selbst.
- Tod der Erinnerungsmauer: Herkömmliche KI-{Hardware} verschwendet etwa 90 % ihrer Energie beim Verschieben von Daten zwischen Speicher und Rechenleistung. Taalas HC1 (Hardcore 1) Der Chip eliminiert die „Reminiscence Wall“, indem er die Modellparameter physisch in den Metallschichten des Chips verdrahtet, wodurch der Bedarf an teurem Excessive Bandwidth Reminiscence (HBM) entfällt.
- 1000x Effizienzsprung: Durch die Abschaffung der „Programmierbarkeitssteuer“ behauptet Taalas a 1.000-fache Verbesserung in Leistung professional Watt und Leistung professional Greenback. In der Praxis bedeutet dies, dass ein HC1 treffen kann 17.000 Token professional Sekunde auf einem Llama 3.1 8B-Modell – übertrifft ein Customary-GPU-Rack deutlich und verbraucht dabei weitaus weniger Strom.
- Automatisierte „Direct-to-Silicon“-Gießerei: Um das Drawback der Modellveralterung zu lösen, verwendet Taalas ein proprietäres Automatisierter Designablauf. Dadurch verkürzt sich die Zeit für die Erstellung eines benutzerdefinierten KI-Chips von Jahren auf nur noch wenige Jahre WochenDies ermöglicht es Unternehmen, ihre fein abgestimmten Modelle saisonal in Silizium zu „drucken“.
- Die Zukunft der Rohstoff-KI: Diese Technologie signalisiert einen Wandel von „Cloud-First“ hin zu „Gerätenative“ KI. Da Inferenz zu einem billigen, fest verdrahteten Intestine wird, wird KI von zentralisierten Servern auf lokale {Hardware} mit geringem Stromverbrauch verlagert – von Smartphones bis hin zu Industriesensoren – ohne Latenz und ohne Abonnementkosten.
Schauen Sie sich das an Technische Particulars. Sie können uns auch gerne weiter folgen Twitter und vergessen Sie nicht, bei uns mitzumachen 100.000+ ML SubReddit und Abonnieren Unser E-newsletter. Warten! Bist du im Telegram? Jetzt können Sie uns auch per Telegram kontaktieren.
