Der Erfolg von Pipelines für maschinelles Lernen hängt vom Function-Engineering als wesentlicher Grundlage ab. Die beiden stärksten Methoden zum Umgang mit Zeitreihendaten sind Lag-Options und Rolling-Options, je nach Ihren fortgeschrittenen Techniken. Die Fähigkeit, diese Techniken zu verwenden, wird die Leistung Ihres Modells für Umsatzprognosen, Aktienkursvorhersagen und Bedarfsplanungsaufgaben verbessern.
In diesem Leitfaden werden Lag- und Rolling-Funktionen erläutert, indem deren Bedeutung aufgezeigt und Python-Implementierungsmethoden und potenzielle Implementierungsherausforderungen anhand funktionierender Codebeispiele vorgestellt werden.
Was ist Function Engineering in Zeitreihen?
Zeitreihen Function-Engineering erstellt neue Eingabevariablen durch den Prozess der Umwandlung zeitlicher Rohdaten in Funktionen, die es Modellen des maschinellen Lernens ermöglichen, zeitliche Muster effektiver zu erkennen. Zeitreihen Daten unterscheiden sich von statischen Datensätzen dadurch, dass sie eine sequentielle Struktur beibehalten, die von Beobachtern verlangt, zu verstehen, dass vergangene Beobachtungen Auswirkungen auf das haben, was als nächstes kommt.
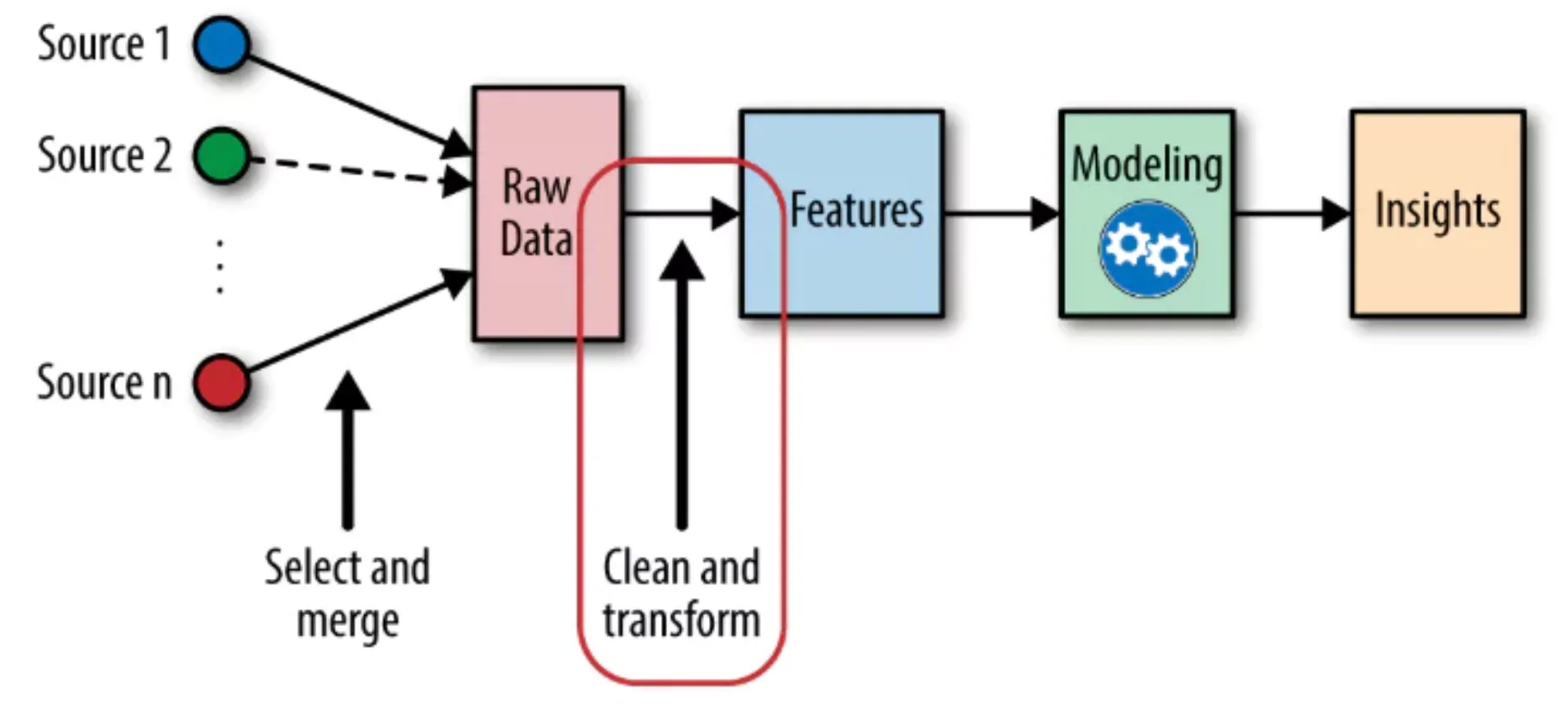
Den herkömmlichen Modellen für maschinelles Lernen XGBoost, LightGBM und Random Forests fehlen integrierte Funktionen zur Zeitverarbeitung. Das System erfordert spezifische Indikatoren, die vergangene Ereignisse anzeigen müssen, die zuvor stattgefunden haben. Diesem Zweck dient die Implementierung von Lag-Options zusammen mit Rolling-Options.
Was sind Verzögerungsfunktionen?
Ein Verzögerungsmerkmal ist einfach ein vergangener Wert einer Variablen, der zeitlich nach vorne verschoben wurde, bis er mit dem aktuellen Datenpunkt übereinstimmt. Die Verkaufsprognose für heute hängt von drei verschiedenen Verkaufsinformationsquellen ab, zu denen die Verkaufsdaten von gestern sowie die Verkaufsdaten für sieben und dreißig Tage gehören.

Warum Verzögerungsfunktionen wichtig sind
- Sie stellen den Zusammenhang zwischen verschiedenen Zeiträumen dar, in denen eine Variable ihre vergangenen Werte anzeigt.
- Mit der Methode können saisonale und zyklische Muster kodiert werden, ohne dass komplizierte Transformationen erforderlich sind.
- Die Methode bietet einfache Berechnungen und klare Ergebnisse.
- Das System funktioniert mit allen Machine-Studying-Modellen, die Baumstrukturen und lineare Methoden verwenden.
LAG-Funktionen in Python implementieren
import pandas as pd
import numpy as np
# Create a pattern time sequence dataset
np.random.seed(42)
dates = pd.date_range(begin="2024-01-01", durations=15, freq='D')
gross sales = (200, 215, 198, 230, 245, 210, 225, 260, 275, 240, 255, 290, 305, 270, 285)
df = pd.DataFrame({'date': dates, 'gross sales': gross sales})
df.set_index('date', inplace=True)
# Create lag options
df('lag_1') = df('gross sales').shift(1)
df('lag_3') = df('gross sales').shift(3)
df('lag_7') = df('gross sales').shift(7)
print(df.head(12))Ausgabe:
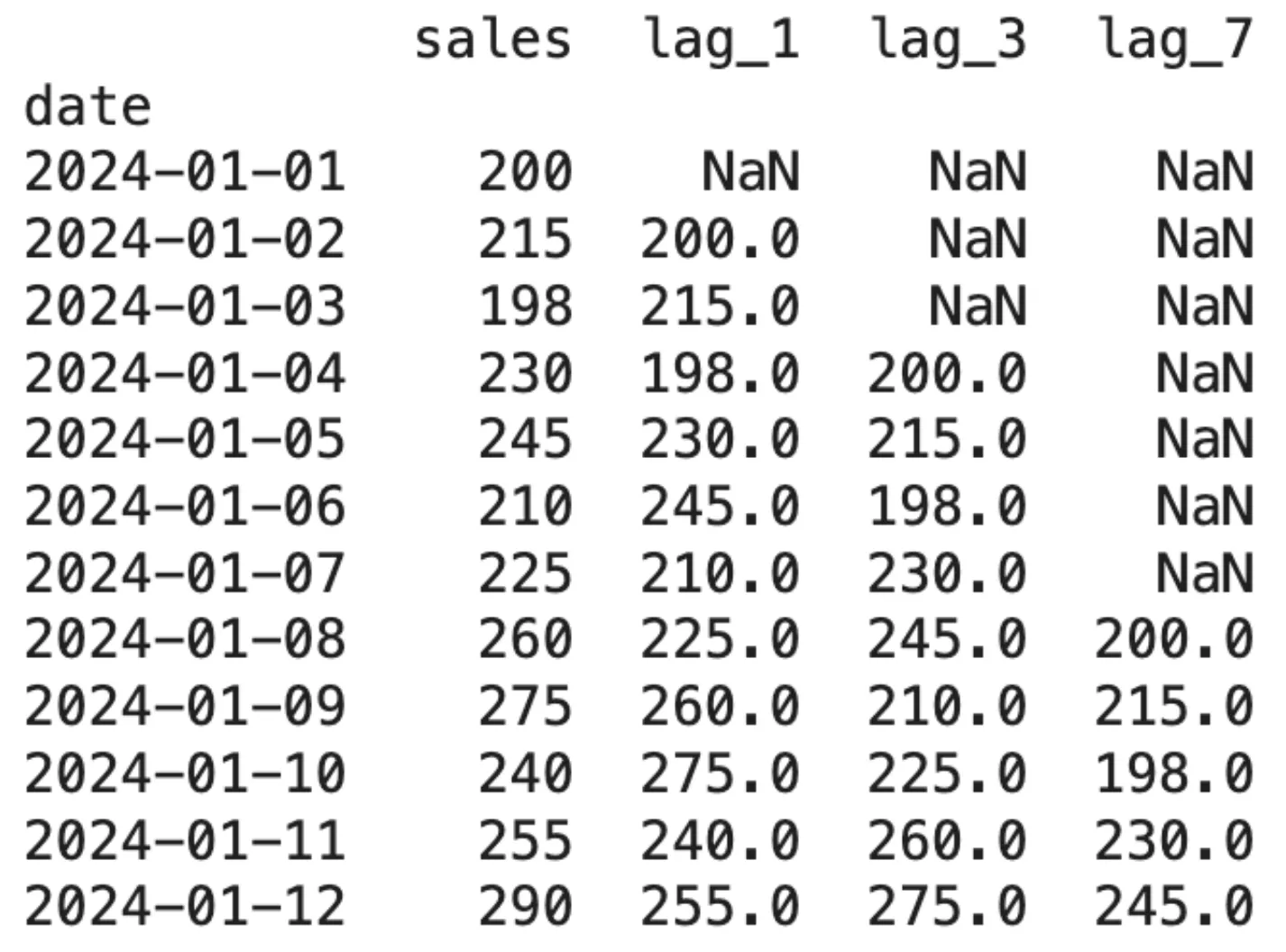
Das anfängliche Erscheinen von NaN-Werten zeigt eine Type von Datenverlust, der aufgrund von Verzögerungen auftritt. Dieser Faktor ist entscheidend für die Bestimmung der Anzahl der zu erstellenden Verzögerungen.
Auswahl der richtigen Verzögerungswerte
Der Auswahlprozess für optimale Verzögerungen erfordert wissenschaftliche Methoden, die eine zufällige Auswahl als Choice ausschließen. Folgende Methoden haben in der Praxis erfolgreiche Ergebnisse gezeigt:
- Die Kenntnis der Domäne hilft sehr, z. B. wöchentliche Verkaufsdaten? Fügen Sie Verzögerungen nach 7, 14, 28 Tagen hinzu. Stündliche Energiedaten? Versuchen Sie es 24 bis 48 Stunden lang.
- Mit der Autokorrelationsfunktion ACF können Benutzer mithilfe der statistischen Erkennungsmethode bestimmen, welche Verzögerungen signifikante Verbindungen zu ihrer Zielvariablen aufweisen.
- Nach Abschluss des Trainingsvorgangs ermittelt das Modell, welche Verzögerungen die höchste Bedeutung haben.
Was sind Roll-(Fenster-)Funktionen?
Die Rollfunktionen fungieren als Fensterfunktionen, die sich durch die Zeit bewegen, um variable Mengen zu berechnen. Das System stellt Ihnen aggregierte Statistiken zur Verfügung, die Mittelwert, Median, Standardabweichung, Minimal- und Maximalwerte für die letzten N Perioden umfassen, anstatt Ihnen einen einzelnen Vergangenheitswert anzuzeigen.

Warum sind rollierende Funktionen wichtig?
Die folgenden Funktionen bieten hervorragende Möglichkeiten zur Ausführung der ihnen zugewiesenen Aufgaben:
- Der Prozess eliminiert Rauschelemente und deckt gleichzeitig die grundlegenden Wachstumsmuster auf.
- Das System ermöglicht es Benutzern, kurzfristige Preisschwankungen zu beobachten, die innerhalb bestimmter Zeiträume auftreten.
- Das System ermöglicht es Benutzern, kurzfristige Preisschwankungen zu beobachten, die innerhalb bestimmter Zeiträume auftreten.
- Das System erkennt ungewöhnliches Verhalten, wenn sich die aktuellen Werte vom festgelegten gleitenden Durchschnitt entfernen.
Die folgenden Aggregationen belegen ihre Präsenz als Standardpraxis bei rollierenden Fenstern:
- Die gebräuchlichste Methode zur Trendglättung verwendet als primäre Methode einen gleitenden Mittelwert.
- Die rollierende Standardabweichungsfunktion berechnet den Grad der Variabilität, der innerhalb eines bestimmten Zeitfensters besteht.
- Die rollierenden Minimal- und Maximalfunktionen identifizieren die höchsten und niedrigsten Werte, die während eines definierten Zeitintervalls/Zeitraums auftreten.
- Die rollierende Medianfunktion liefert genaue Ergebnisse für Daten, die Ausreißer enthalten und ein hohes Maß an Rauschen aufweisen.
- Mit der Rollsummenfunktion können Sie das Gesamtvolumen oder die Gesamtanzahl über einen bestimmten Zeitraum hinweg verfolgen.
Implementieren von Rolling-Options in Python
import pandas as pd
import numpy as np
np.random.seed(42)
dates = pd.date_range(begin="2024-01-01", durations=15, freq='D')
gross sales = (200, 215, 198, 230, 245, 210, 225, 260, 275, 240, 255, 290, 305, 270, 285)
df = pd.DataFrame({'date': dates, 'gross sales': gross sales})
df.set_index('date', inplace=True)
# Rolling options with window dimension of three and seven
df('roll_mean_3') = df('gross sales').shift(1).rolling(window=3).imply()
df('roll_std_3') = df('gross sales').shift(1).rolling(window=3).std()
df('roll_max_3') = df('gross sales').shift(1).rolling(window=3).max()
df('roll_mean_7') = df('gross sales').shift(1).rolling(window=7).imply()
print(df.spherical(2))Ausgabe:
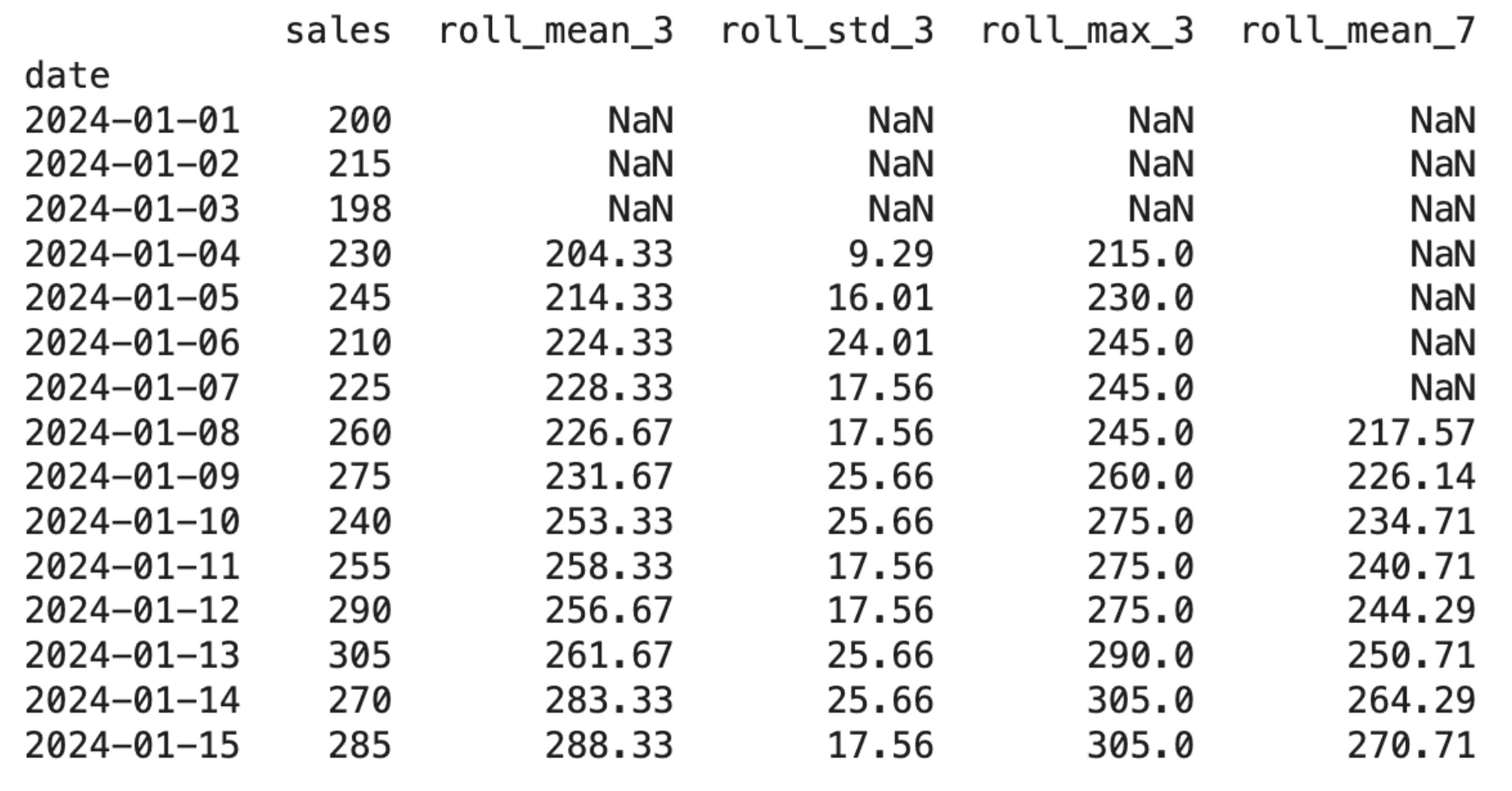
Die Funktion .shift(1) muss vor der Funktion .rolling() ausgeführt werden, da sie eine wichtige Verbindung zwischen beiden Funktionen herstellt. Das System benötigt diesen Mechanismus, da es fortlaufende Berechnungen erstellt, die ausschließlich auf historischen Daten basieren, ohne aktuelle Daten zu verwenden.
Kombination von Verzögerungs- und Rollfunktionen: Ein produktionsreifes Beispiel
Tatsächlich maschinelles Lernen Zeitreihen-Workflows erstellen Forscher ihren eigenen Hybrid-Function-Satz, der sowohl Lag-Options als auch Rolling-Options umfasst. Wir stellen Ihnen eine komplette Function-Engineering-Funktion zur Verfügung, die Sie für jedes Projekt nutzen können.
import pandas as pd
import numpy as np
def create_time_features(df, target_col, lags=(1, 3, 7), home windows=(3, 7)):
"""
Create lag and rolling options for time sequence ML.
Parameters:
df : DataFrame with datetime index
target_col : Identify of the goal column
lags : Record of lag durations
home windows : Record of rolling window sizes
Returns:
DataFrame with new options
"""
df = df.copy()
# Lag options
for lag in lags:
df(f'lag_{lag}') = df(target_col).shift(lag)
# Rolling options (shift by 1 to keep away from leakage)
for window in home windows:
shifted = df(target_col).shift(1)
df(f'roll_mean_{window}') = shifted.rolling(window).imply()
df(f'roll_std_{window}') = shifted.rolling(window).std()
df(f'roll_max_{window}') = shifted.rolling(window).max()
df(f'roll_min_{window}') = shifted.rolling(window).min()
return df.dropna() # Drop rows with NaN from lag/rolling
# Pattern utilization
np.random.seed(0)
dates = pd.date_range('2024-01-01', durations=60, freq='D')
gross sales = 200 + np.cumsum(np.random.randn(60) * 5)
df = pd.DataFrame({'gross sales': gross sales}, index=dates)
df_features = create_time_features(df, 'gross sales', lags=(1, 3, 7), home windows=(3, 7))
print(f"Authentic form: {df.form}")
print(f"Engineered form: {df_features.form}")
print(f"nFeature columns:n{checklist(df_features.columns)}")
print(f"nFirst few rows:n{df_features.head(3).spherical(2)}")Ausgabe:

Häufige Fehler und wie man sie vermeidet
Der schwerwiegendste Fehler beim Time Collection Function Engineering tritt auf, wenn Datenverlustdas bevorstehende Daten zum Testen von Funktionen offenlegt, führt zu einer irreführenden Modellleistung.
Wichtige Fehler, auf die Sie achten sollten:
- Der Prozess erfordert einen .shift(1)-Befehl, bevor die .rolling()-Funktion gestartet wird. Die aktuelle Beobachtung wird Teil des rollierenden Fensters, da beim Rollen die erste Beobachtung verschoben werden muss.
- Durch das Hinzufügen von Verzögerungen kommt es zu Datenverlust, da jede Verzögerung NaN-Zeilen erstellt. Der 100-Zeilen-Datensatz verliert 30 % seiner Daten, da für 30 Verzögerungen die Erstellung von 30 NaN-Zeilen erforderlich ist.
- Der Prozess erfordert separate Fenstergrößenexperimente, da unterschiedliche Eigenschaften unterschiedliche Fenstergrößen erfordern. Der Prozess erfordert das Testen kurzer Fenster im Bereich von 3 bis 5 und langer Fenster im Bereich von 14 bis 30.
- In der Produktionsumgebung müssen Sie Roll- und Verzögerungsfunktionen aus tatsächlichen historischen Daten berechnen, die Sie während der Inferenzzeit anstelle Ihrer Trainingsdaten verwenden.
Wann sollten Lag- oder Rolling-Funktionen verwendet werden?
| Anwendungsfall | Empfohlene Funktionen |
|---|---|
| Starke Autokorrelation in den Daten | Verzögerungsfunktionen (Lag-1, Lag-7) |
| Verrauschtes Sign, Glättung erforderlich | Rollender Mittelwert |
| Saisonale Muster (wöchentlich) | Lag-7, Lag-14, Lag-28 |
| Trenderkennung | Rollmittel über lange Fenster |
| Anomalieerkennung | Abweichung vom gleitenden Mittelwert |
| Variabilität/Risiko erfassen | Rollierende Standardabweichung, Rollbereich |
Abschluss
Die Zeitreihen-Infrastruktur für maschinelles Lernen verwendet Verzögerungsfunktionen und rollierende Funktionen als wesentliche Komponenten. Die beiden Methoden schaffen einen Weg von unverarbeiteten sequentiellen Daten zum organisierten Datenformat, das maschinelle Lernmodelle für ihren Trainingsprozess benötigen. Die Methoden werden zum größten Einflussfaktor für die Prognosegenauigkeit, wenn Benutzer sie mit präzisen Datenverarbeitungs- und Fensterauswahlmethoden sowie ihrem kontextuellen Verständnis des spezifischen Bereichs ausführen.
Das Beste daran? Sie liefern klare Erklärungen, die nur minimale Rechenressourcen erfordern und mit jedem maschinellen Lernmodell funktionieren. Diese Funktionen kommen Ihnen unabhängig davon zugute, ob Sie sie nutzen XGBoost für Bedarfsprognosen, LSTM zur Anomalieerkennung, oder lineare Regression für Basismodelle.
Gen AI-Praktikant bei Analytics Vidhya
Abteilung für Informatik, Vellore Institute of Expertise, Vellore, Indien
Derzeit arbeite ich als Gen AI-Praktikant bei Analytics Vidhya, wo ich zu innovativen KI-gesteuerten Lösungen beitrage, die Unternehmen in die Lage versetzen, Daten effektiv zu nutzen. Als Informatikstudent im Abschlussjahr am Vellore Institute of Expertise bringe ich solide Grundlagen in Softwareentwicklung, Datenanalyse und maschinellem Lernen in meine Rolle ein.
Kontaktieren Sie mich gerne unter (e mail protected)
Melden Sie sich an, um weiterzulesen und von Experten kuratierte Inhalte zu genießen.