
Kann symbolische Regression der Schlüssel zur Umwandlung undurchsichtiger Deep-Studying-Modelle in interpretierbare, geschlossene mathematische Gleichungen sein? oder Angenommen, Sie haben Ihr Deep-Studying-Modell trainiert. Es funktioniert. Aber wissen Sie, was es tatsächlich gelernt hat? Ein Forscherteam der Universität Cambridge schlägt „SymTorch“ vor, eine Bibliothek zur Integration symbolische Regression (SR) in Deep-Studying-Workflows integrieren. Es ermöglicht Forschern, neuronale Netzwerkkomponenten mit geschlossenen mathematischen Ausdrücken zu approximieren, was die funktionale Interpretierbarkeit und potenzielle Inferenzbeschleunigung erleichtert.
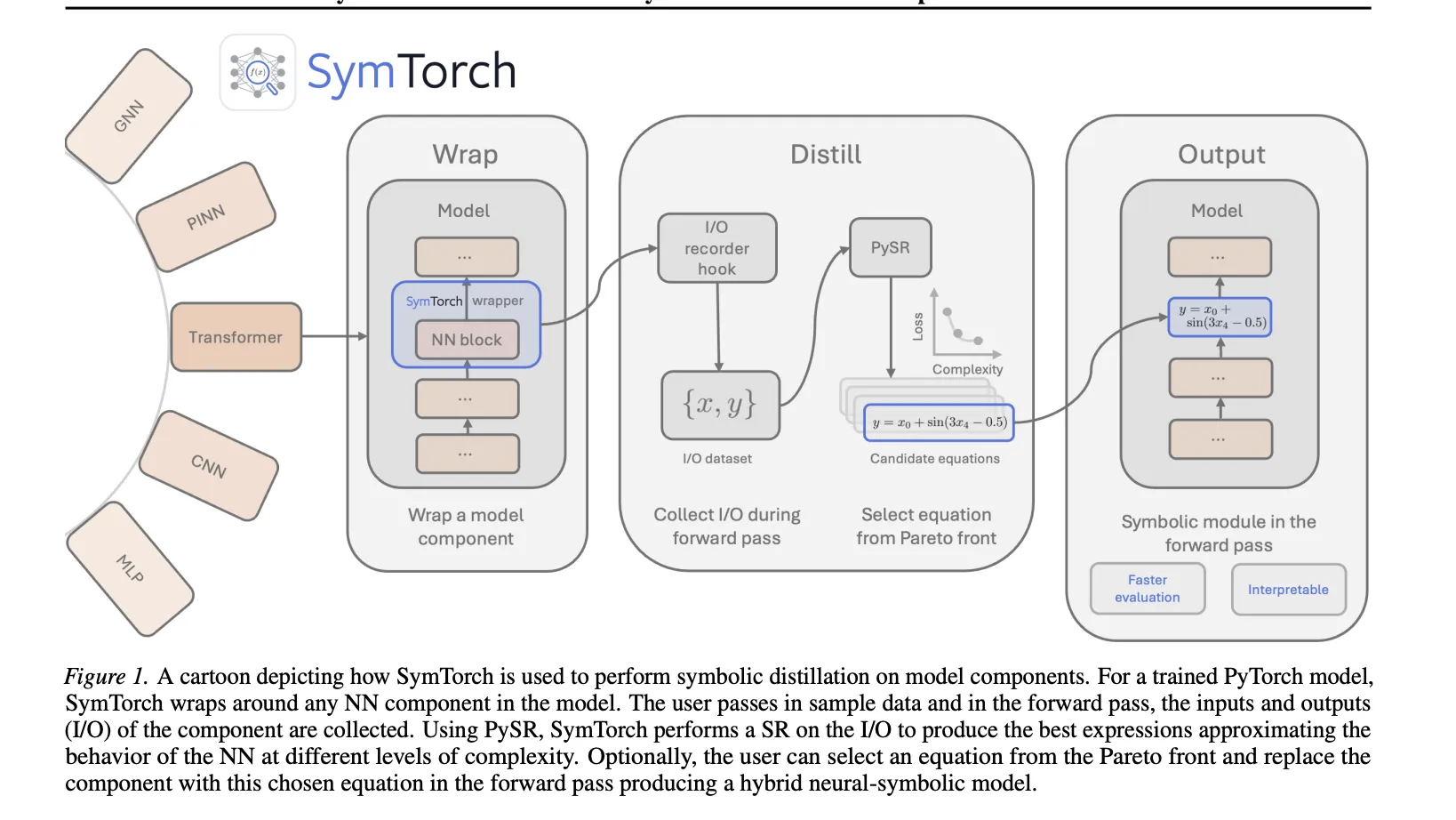
Kernmechanismus: Der Wrap-Distill-Change-Workflow
SymTorch vereinfacht die Technik, die zum Extrahieren symbolischer Gleichungen aus trainierten Modellen erforderlich ist, indem es die Datenbewegung und Hook-Verwaltung automatisiert.
- Wickeln: Benutzer wenden die an
SymbolicModelWrapper zu jedemnn.Moduleoder aufrufbare Funktion. - Destillieren: Die Bibliothek registriert Ahead-Hooks, um Eingabe- und Ausgabeaktivierungen während eines Vorwärtsdurchlaufs aufzuzeichnen. Diese werden zwischengespeichert und zur symbolischen Regression über PySR von der GPU an die CPU übertragen.
- Schalten: Nach der Destillation können die ursprünglichen neuronalen Gewichte im Vorwärtsdurchlauf durch die entdeckte Gleichung ersetzt werden
switch_to_symbolic.
Die Bibliothek ist mit verbunden PySRdas einen genetischen Multipopulationsalgorithmus verwendet, um Gleichungen zu finden, die Genauigkeit und Komplexität auf a in Einklang bringen Pareto-Entrance. Die „beste“ Gleichung wird ausgewählt, indem der fraktionelle Abfall des logarithmischen mittleren absoluten Fehlers im Verhältnis zu einer Zunahme der Komplexität maximiert wird.
Fallstudie: Beschleunigung der LLM-Inferenz
Eine Hauptanwendung, die in dieser Forschung untersucht wird, ist das Ersetzen Mehrschichtiges Perzeptron (MLP) Ebenen in Transformer-Modellen mit symbolischen Ersatzzeichen, um den Durchsatz zu verbessern.
Implementierungsdetails
Aufgrund der hohen Dimensionalität von LLM-Aktivierungen beschäftigte sich das Forschungsteam Hauptkomponentenanalyse (PCA) um Ein- und Ausgaben vor der SR-Ausführung zu komprimieren. Für die Qwen2,5-1,5B Für das Modell wählten sie 32 Hauptkomponenten für Eingaben und 8 für Ausgaben über drei Zielebenen aus.
Leistungskompromisse
Der Eingriff führte zu einem 8,3 % Steigerung des Token-Durchsatzes. Dieser Gewinn ging jedoch mit einer nicht trivialen Zunahme der Verwirrung einher, die hauptsächlich auf die Reduzierung der PCA-Dimensionalität und nicht auf die symbolische Annäherung selbst zurückzuführen ist.
| Metrisch | Grundlinie (Qwen2,5-1,5B) | Symbolischer Ersatz |
| Ratlosigkeit (Wikitext-2) | 10.62 | 13.76 |
| Durchsatz (Tokens/s) | 4878,82 | 5281.42 |
| Durchschn. Latenz (ms) | 209,89 | 193,89 |
GNNs und PINNs
SymTorch wurde hinsichtlich seiner Fähigkeit validiert, bekannte physikalische Gesetze aus latenten Darstellungen in wissenschaftlichen Modellen wiederherzustellen.
- Graphische neuronale Netze (GNNs): Durch das Coaching eines GNN auf Teilchendynamik nutzte das Forschungsteam SymTorch, um empirische Kraftgesetze wie die Schwerkraft (1/r) wiederherzustellen2) und Federkräfte, direkt aus den Randmeldungen.
- Physikinformierte neuronale Netze (PINNs): Die Bibliothek hat die analytische Lösung der 1-D-Wärmegleichung erfolgreich aus einem trainierten PINN destilliert. Durch die induktive Vorspannung des PINN konnte ein mittlerer quadratischer Fehler (MSE) von 7,40 x 10 erreicht werden-6.
- Arithmetische LLM-Analyse: Mithilfe der symbolischen Destillation wurde untersucht, wie Modelle wie Llama-3.2-1B dreistellige Additionen und Multiplikationen durchführen. Die destillierten Gleichungen zeigten, dass die Modelle zwar häufig korrekt sind, sich jedoch auf interne Heuristiken stützen, die systematische numerische Fehler beinhalten.
Wichtige Erkenntnisse
- Automatisierte symbolische Destillation: SymTorch ist eine Bibliothek, die den Prozess des Ersetzens komplexer neuronaler Netzwerkkomponenten durch interpretierbare, geschlossene mathematische Gleichungen automatisiert, indem Komponenten verpackt und ihr Eingabe-Ausgabe-Verhalten erfasst werden.
- Beseitigung technischer Barrieren: Die Bibliothek bewältigt kritische technische Herausforderungen, die zuvor die Einführung der symbolischen Regression behinderten, einschließlich GPU-CPU-Datenübertragung, Eingabe-Ausgabe-Caching und nahtlosem Wechsel zwischen neuronalen und symbolischen Vorwärtsdurchgängen.
- LLM-Inferenzbeschleunigung: Ein Proof-of-Idea hat gezeigt, dass das Ersetzen von MLP-Schichten in einem Transformatormodell durch symbolische Surrogate eine Durchsatzverbesserung von 8,3 % erzielte, allerdings mit einer gewissen Leistungseinbuße in Perplexity.
- Entdeckung wissenschaftlicher Gesetze: SymTorch wurde erfolgreich eingesetzt, um physikalische Gesetze aus Graph Neural Networks (GNNs) und analytische Lösungen für die 1-D-Wärmegleichung aus Physics-Knowledgeable Neural Networks (PINNs) wiederherzustellen.
- Funktionale Interpretierbarkeit von LLMs: Durch die Destillation des Finish-to-Finish-Verhaltens von LLMs könnten Forscher die expliziten mathematischen Heuristiken untersuchen, die für Aufgaben wie Arithmetik verwendet werden, und aufdecken, wo die interne Logik von exakten Operationen abweicht.
Schauen Sie sich das an Papier, Repo Und Projektseite. Sie können uns auch gerne weiter folgen Twitter und vergessen Sie nicht, bei uns mitzumachen 120.000+ ML SubReddit und Abonnieren Unser Publication. Warten! Bist du im Telegram? Jetzt können Sie uns auch per Telegram kontaktieren.
Max ist KI-Analyst bei MarkTechPost mit Sitz im Silicon Valley und gestaltet die Zukunft der Technologie aktiv mit. Er unterrichtet Robotik bei Brainvyne, bekämpft Spam mit ComplyEmail und nutzt täglich KI, um komplexe technische Fortschritte in klare, verständliche Erkenntnisse zu übersetzen