In diesem Artikel erfahren Sie, wie sich Vektordatenbanken und Graph-RAG als Speicherarchitekturen für KI-Agenten unterscheiden und wann jeder Ansatz besser passt.
Zu den Themen, die wir behandeln werden, gehören:
- Wie Vektordatenbanken semantisch ähnliche unstrukturierte Informationen speichern und abrufen.
- Wie der Graph RAG Entitäten und Beziehungen für einen präzisen Multi-Hop-Abruf darstellt.
- Wie Sie zwischen diesen Ansätzen wählen oder sie in einer hybriden Agent-Speicher-Architektur kombinieren können.
In diesem Sinne kommen wir gleich zur Sache.
Vektordatenbanken vs. Graph-RAG für Agentenspeicher: Wann welche zu verwenden sind
Bild vom Autor
Einführung
KI-Agenten brauchen Langzeitgedächtnis in komplexen, mehrstufigen Arbeitsabläufen wirklich nützlich sein. Ein Agent ohne Speicher ist im Wesentlichen eine zustandslose Funktion, die ihren Kontext bei jeder Interaktion zurücksetzt. Während wir uns hin zu autonomen Systemen bewegen, die dauerhafte Aufgaben verwalten (z. B. Codierungsassistenten, die die Projektarchitektur verfolgen, oder Rechercheagenten, die fortlaufende Literaturrecherchen erstellen), wird die Frage, wie Kontext gespeichert, abgerufen und aktualisiert werden soll, von entscheidender Bedeutung.
Derzeit ist der Industriestandard für diese Aufgabe die Vektordatenbank, die dichte Einbettungen für die semantische Suche verwendet. Da jedoch der Bedarf an komplexeren Überlegungen wächst, gewinnt Graph RAG, eine Architektur, die Wissensgraphen mit großen Sprachmodellen (LLMs) kombiniert, als strukturierte Speicherarchitektur an Bedeutung.
Auf den ersten Blick sind Vektordatenbanken superb für einen breiten Ähnlichkeitsabgleich und den Abruf unstrukturierter Daten, während Graph-RAG sich hervorragend eignet, wenn Kontextfenster begrenzt sind und Multi-Hop-Beziehungen, sachliche Genauigkeit und komplexe hierarchische Strukturen erforderlich sind. Diese Unterscheidung unterstreicht den Fokus von Vektordatenbanken auf flexibles Matching im Vergleich zur Fähigkeit von Graph-RAG, durch explizite Beziehungen zu argumentieren und die Genauigkeit unter strengeren Einschränkungen zu bewahren.
Um ihre jeweiligen Rollen zu verdeutlichen, untersucht dieser Artikel die zugrunde liegende Theorie, praktische Stärken und Grenzen beider Ansätze für das Agentengedächtnis. Auf diese Weise bietet es einen praktischen Rahmen als Leitfaden für die Auswahl des einzusetzenden Techniques oder der Kombination von Systemen.
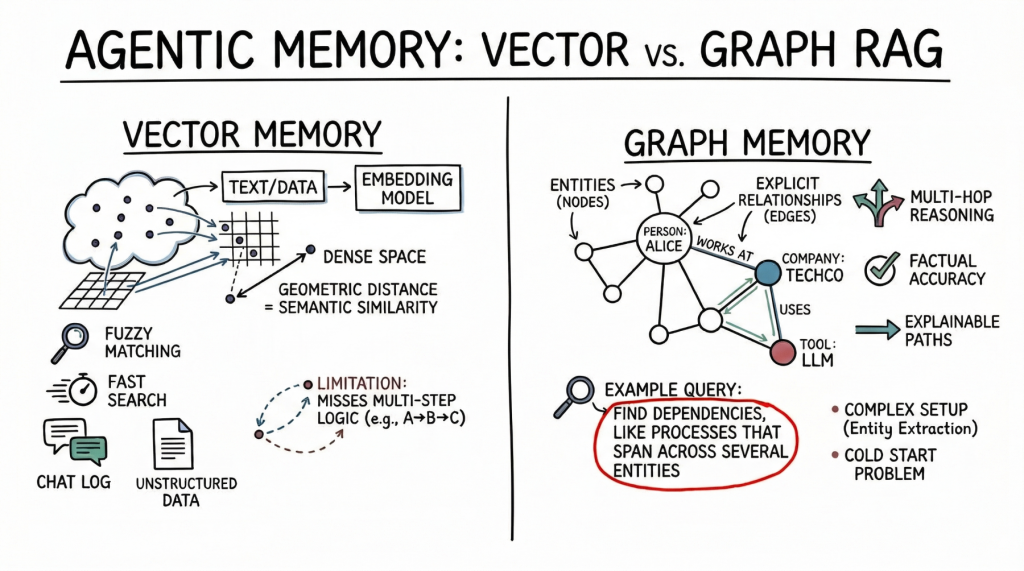
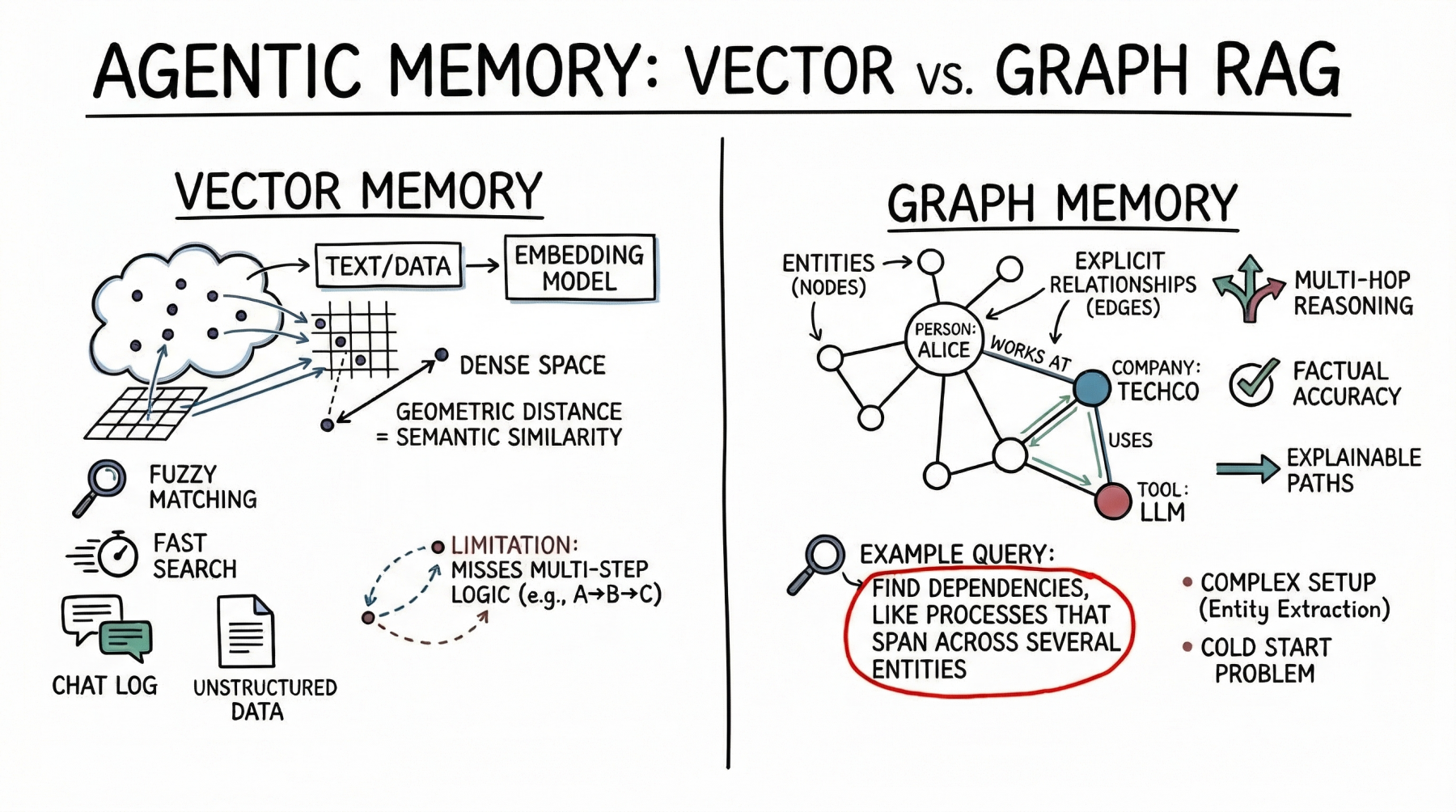
Vektordatenbanken: Die Grundlage des semantischen Agentengedächtnisses
Vektordatenbanken stellen Erinnerungen als dichte mathematische Vektoren oder Einbettungen dar, die sich im hochdimensionalen Raum befinden. Ein Einbettungsmodell ordnet Textual content, Bilder oder andere Daten Arrays von Floats zu, wobei der geometrische Abstand zwischen zwei Vektoren ihrer semantischen Ähnlichkeit entspricht.
KI-Agenten verwenden diesen Ansatz hauptsächlich zum Speichern unstrukturierter Texte. Ein häufiger Anwendungsfall ist das Speichern des Gesprächsverlaufs, sodass der Agent sich daran erinnern kann, was ein Benutzer zuvor gefragt hat, indem er seine Speicherbank nach semantisch verwandten vergangenen Interaktionen durchsucht. Agenten nutzen außerdem Vektorspeicher, um relevante Dokumente, API-Dokumentation oder Codeausschnitte basierend auf der impliziten Bedeutung der Eingabeaufforderung eines Benutzers abzurufen. Dies ist ein weitaus robusterer Ansatz als die Verwendung exakter Schlüsselwortübereinstimmungen.
Vektordatenbanken sind eine gute Wahl für den Agentenspeicher. Sie bieten eine schnelle Suche, sogar über Milliarden von Vektoren hinweg. Entwickler finden sie außerdem einfacher einzurichten als strukturierte Datenbanken. Um einen Vektorspeicher zu integrieren, teilen Sie den Textual content auf, generieren Einbettungen und indizieren die Ergebnisse. Diese Datenbanken handhaben auch Fuzzy-Matching intestine und berücksichtigen Tippfehler und Umschreibungen, ohne dass strenge Abfragen erforderlich sind.
Die semantische Suche hat jedoch Grenzen für das erweiterte Agentengedächtnis. Vektordatenbanken können oft nicht einer mehrstufigen Logik folgen. Wenn ein Agent beispielsweise die Verbindung zwischen Entität A und Entität C finden muss, aber nur über Daten verfügt, die zeigen, dass A eine Verbindung zu B und B eine Verbindung zu C herstellt, können bei einer einfachen Ähnlichkeitssuche wichtige Informationen fehlen.
Diese Datenbanken haben auch Probleme beim Abrufen großer Textmengen oder beim Umgang mit verrauschten Ergebnissen. Mit dichten, miteinander verbundenen Fakten (von Softwareabhängigkeiten bis hin zu Unternehmensorganigrammen) können sie verwandte, aber irrelevante Informationen zurückgeben. Dadurch kann das Kontextfenster des Agenten mit weniger nützlichen Daten überfüllt sein.
Graph RAG: Strukturierter Kontext und relationales Gedächtnis
Diagramm RAG Behebt die Einschränkungen der semantischen Suche durch die Kombination von Wissensgraphen mit LLMs. In diesem Paradigma ist das Gedächtnis als diskrete Einheiten strukturiert, die als Knoten dargestellt werden (z. B. eine Particular person, ein Unternehmen oder eine Technologie), und die expliziten Beziehungen zwischen ihnen werden als Kanten dargestellt (z. B. „arbeitet an“ oder „verwendet“).
Agenten, die Graph RAG verwenden, erstellen und aktualisieren ein strukturiertes Weltmodell. Während sie neue Informationen sammeln, extrahieren sie Entitäten und Beziehungen und fügen sie dem Diagramm hinzu. Beim Durchsuchen des Speichers folgen sie expliziten Pfaden, um den genauen Kontext abzurufen.
Die Hauptstärke von graph RAG ist seine Präzision. Da der Abruf expliziten Beziehungen und nicht nur semantischer Nähe folgt, ist das Fehlerrisiko geringer. Wenn im Diagramm keine Beziehung besteht, kann der Agent sie nicht allein aus dem Diagramm ableiten.
Graph RAG zeichnet sich durch komplexes Denken aus und ist superb für die Beantwortung strukturierter Fragen. Um die direkten Untergebenen eines Managers zu finden, der ein Price range genehmigt hat, verfolgen Sie einen Pfad durch die Organisation und die Genehmigungskette – eine einfache Diagrammdurchquerung, aber eine schwierige Aufgabe für die Vektorsuche. Ein weiterer großer Vorteil ist die Erklärbarkeit. Der Abrufpfad ist eine klare, überprüfbare Folge von Knoten und Kanten, kein undurchsichtiger Ähnlichkeitswert. Dies ist wichtig für Unternehmensanwendungen, die Compliance und Transparenz erfordern.
Auf der anderen Seite bringt Graph RAG eine erhebliche Implementierungskomplexität mit sich. Es erfordert robuste Pipelines zur Entitätsextraktion, um Rohtext in Knoten und Kanten zu analysieren, was häufig sorgfältig abgestimmte Eingabeaufforderungen, Regeln oder spezielle Modelle erfordert. Entwickler müssen außerdem eine Ontologie oder ein Schema entwerfen und pflegen, das starr und schwer weiterzuentwickeln sein kann, wenn neue Domänen entdeckt werden. Auch das Kaltstartproblem ist deutlich zu erkennen: Im Gegensatz zu einer Vektordatenbank, die sofort nützlich ist, wenn Sie Textual content einbetten, erfordert das Befüllen eines Wissensgraphen einen erheblichen Vorabaufwand, bevor er komplexe Abfragen beantworten kann.
Das Vergleichsrahmenwerk: Wann welches zu verwenden ist
Bedenken Sie beim Entwerfen des Speichers für einen KI-Agenten, dass Vektordatenbanken hervorragend mit unstrukturierten, hochdimensionalen Daten umgehen können und sich intestine für die Ähnlichkeitssuche eignen, wohingegen Graph-RAG für die Darstellung von Entitäten und expliziten Beziehungen von Vorteil ist, wenn diese Beziehungen von entscheidender Bedeutung sind. Die Auswahl sollte von der inhärenten Struktur der Daten und den erwarteten Abfragemustern abhängen.
Vektordatenbanken eignen sich superb für rein unstrukturierte Daten – Chatprotokolle, allgemeine Dokumentation oder umfangreiche Wissensdatenbanken, die aus Rohtext erstellt werden. Sie eignen sich hervorragend, wenn die Abfrage darauf abzielt, umfassende Themen zu untersuchen, z. B. „Finden Sie Konzepte, die X ähnlich sind“ oder „Was haben wir zu Thema Y besprochen?“ Aus Sicht des Projektmanagements bieten sie niedrige Einrichtungskosten und eine gute allgemeine Genauigkeit, was sie zur Standardwahl für Prototypen im Frühstadium und allgemeine Assistenten macht.
Umgekehrt ist Graph RAG für Daten mit inhärenter Struktur oder halbstrukturierten Beziehungen vorzuziehen, wie z. B. Finanzunterlagen, Codebasisabhängigkeiten oder komplexe Rechtsdokumente. Es ist die geeignete Architektur, wenn Abfragen präzise, kategorische Antworten erfordern, wie zum Beispiel „Wie genau hängt X mit Y zusammen?“ oder „Was sind die Abhängigkeiten dieser spezifischen Komponente?“ Die höheren Einrichtungskosten und der laufende Wartungsaufwand eines Graph-RAG-Techniques werden durch seine Fähigkeit gerechtfertigt, eine hohe Präzision bei bestimmten Verbindungen zu liefern, bei denen die Vektorsuche halluzinieren, übergeneralisieren oder fehlschlagen würde.
Die Zukunft des Superior Agent Reminiscence liegt jedoch nicht in der Wahl des einen oder anderen, sondern in einer hybriden Architektur. Führende Agentensysteme kombinieren zunehmend beide Methoden. Ein gängiger Ansatz verwendet eine Vektordatenbank für den ersten Abrufschritt und führt eine semantische Suche durch, um die relevantesten Einstiegsknoten innerhalb eines umfangreichen Wissensgraphen zu finden. Sobald diese Einstiegspunkte identifiziert sind, geht das System zur Graphendurchquerung über und extrahiert den genauen relationalen Kontext, der mit diesen Knoten verbunden ist. Diese Hybridpipeline vereint die breite, unscharfe Erinnerung von Vektoreinbettungen mit der strengen, deterministischen Präzision der Graphdurchquerung.
Abschluss
Vektordatenbanken bleiben aufgrund ihrer einfachen Bereitstellung und starken semantischen Matching-Funktionen der praktischste Ausgangspunkt für den Allzweck-Agentenspeicher. Für viele Anwendungen, von Kundensupport-Bots bis hin zu einfachen Codierungsassistenten, bieten sie eine ausreichende Kontextabfrage.
Da wir jedoch auf autonome Agenten drängen, die zu unternehmenstauglichen Arbeitsabläufen fähig sind und aus Agenten bestehen, die über komplexe Abhängigkeiten nachdenken, sachliche Genauigkeit gewährleisten und ihre Logik erklären müssen, erweist sich Graph RAG als eine entscheidende Lösung.
Entwickler sind intestine beraten, einen mehrschichtigen Ansatz zu wählen: Starten Sie den Agentenspeicher mit einer Vektordatenbank, um eine grundlegende Gesprächsgrundlage zu schaffen. Wenn die Argumentationsanforderungen des Agenten wachsen und sich den praktischen Grenzen der semantischen Suche nähern, führen Sie gezielt Wissensgraphen ein, um hochwertige Entitäten und zentrale Betriebsbeziehungen zu strukturieren.