
Mistral AI wurde veröffentlicht Voxtral TTSein offenes Textual content-to-Speech-Modell, das den ersten großen Schritt des Unternehmens in die Audioerzeugung markiert. Nach der Veröffentlichung seiner Transkriptions- und Sprachmodelle stellt Mistral nun die letzte „Ausgabeschicht“ des Audio-Stacks bereit und positioniert sich damit als direkter Konkurrent proprietärer Sprach-APIs im Entwickler-Ökosystem.
Voxtral TTS ist mehr als nur ein synthetischer Sprachgenerator. Es handelt sich um eine leistungsstarke, modulare Komponente, die für die Integration in Echtzeit-Sprachworkflows konzipiert ist. Durch die Veröffentlichung des Modells unter a CC BY-NC-LizenzDas Mistral-Staff setzt seine Strategie fort, Entwicklern die Entwicklung und Bereitstellung bahnbrechender Funktionen zu ermöglichen, ohne den Einschränkungen durch Closed-Supply-API-Preise oder Datenschutzbeschränkungen unterliegen zu müssen.
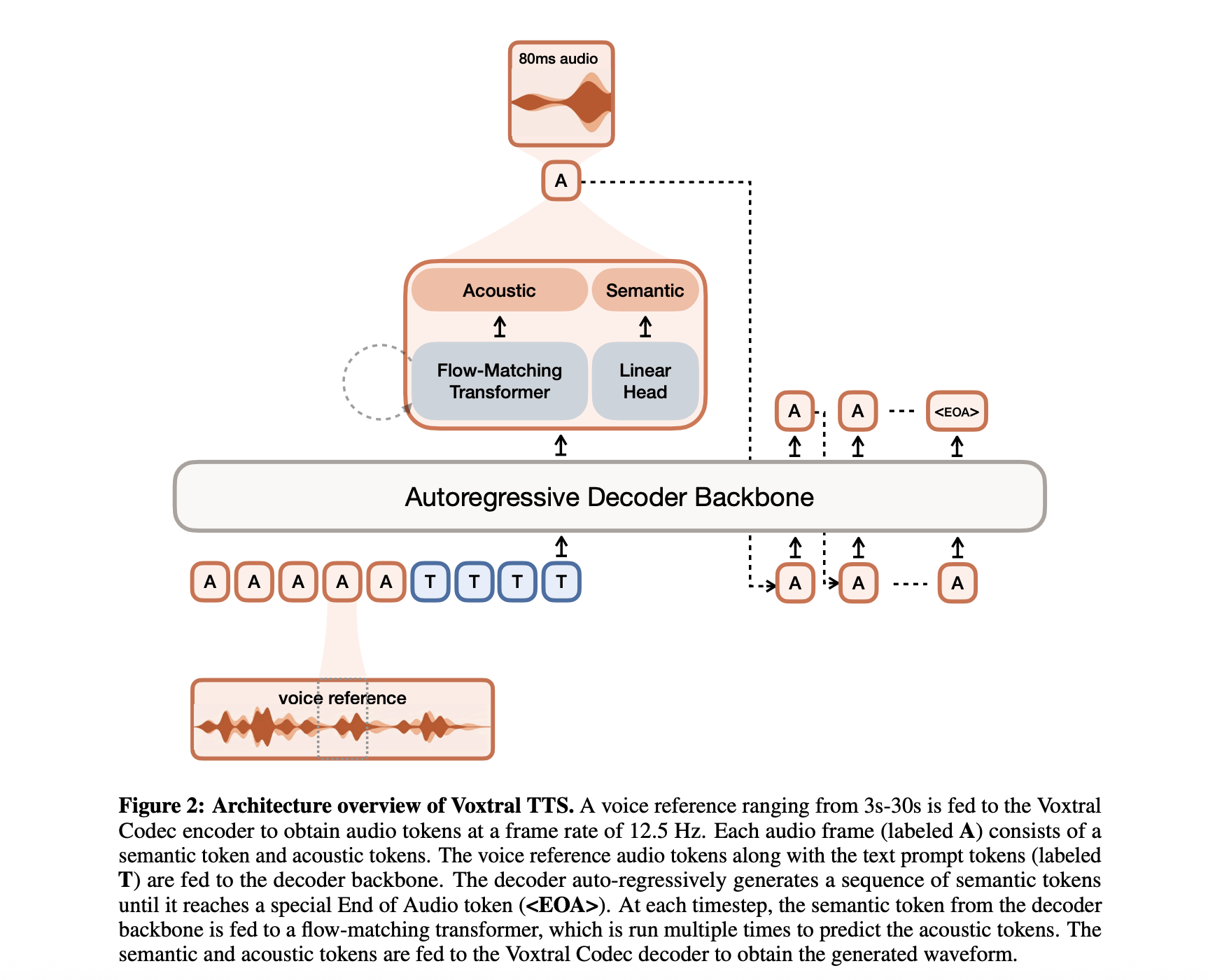
Architektur: Das 4B-Parameter-Hybridmodell
Während sich viele neuere Entwicklungen im Textual content-to-Speech-Bereich auf huge, ressourcenintensive Architekturen konzentrierten, wurde bei der Entwicklung von Voxtral TTS auf Effizienz geachtet. Die Modellfunktionen 4B-Parameternach modernen Grenzstandards als Leichtgewichtmodell eingestuft.
Diese Parameteranzahl wird über eine Hybridarchitektur verteilt, die darauf ausgelegt ist, die üblichen Kompromisse zwischen Erzeugungsgeschwindigkeit und Natürlichkeit des Klangs zu lösen. Das System besteht aus drei Hauptkomponenten:
- Transformator-Decoder-Spine: Ein 3.4B-Parametermodul basierend auf der Ministral-Architektur, das das Textverständnis übernimmt und semantische Darstellungen von Sprache vorhersagt.
- Akustischer Transformator mit Strömungsanpassung: Ein 390M-Parametermodul, das diese semantischen Darstellungen in detaillierte akustische Merkmale umwandelt.
- Neuronaler Audio-Codec: Ein 300M-Parameterdecoder, der die akustischen Merkmale wieder in eine Excessive-Constancy-Audiowellenform umwandelt.
Durch die Trennung der „Bedeutung“ der Sprache (Semantik) von der „Textur“ der Stimme (Akustik) sorgt Voxtral TTS für langfristige Konsistenz und liefert gleichzeitig die feinkörnigen Nuancen, die für eine lebensechte Interaktion erforderlich sind.
Leistung: 70 ms Latenz und hoher Durchsatz
Im Kontext produktionstauglicher KI ist die Latenz die entscheidende Einschränkung. Mistral hat Voxtral TTS für Streaming-Inferenz mit geringer Latenz optimiert, wodurch es für Konversationsagenten und Echtzeitübersetzung geeignet ist.
Das Modell erreicht a 70 ms Modelllatenz für ein typisches 10-Sekunden-Sprachbeispiel und eine Eingabe von 500 Zeichen. Diese Geschwindigkeit ist entscheidend für die Reduzierung der wahrgenommenen Verzögerung bei Voice-First-Anwendungen, bei denen selbst kleine Pausen den Fluss der Mensch-Maschine-Interaktion stören können.
Darüber hinaus verfügt das Modell über eine hohe Echtzeitfaktor (RTF) von ca. 9,7x. Das bedeutet, dass das System Audio quick zehnmal schneller synthetisieren kann, als es gesprochen wird. Für Entwickler bedeutet dieser Durchsatz niedrigere Rechenkosten und die Möglichkeit, Arbeitslasten mit hoher Parallelität auf Commonplace-Inferenzhardware zu bewältigen.
Globale Reichweite: 9 Sprachen und Dialektgenauigkeit
Voxtral TTS ist von Haus aus mehrsprachig und unterstützt 9 Sprachen von Anfang an: Englisch, Französisch, Deutsch, Spanisch, Niederländisch, Portugiesisch, Italienisch, Hindi und Arabisch.
Das Trainingsziel für das Modell geht über die einfache phonetische Übersetzung hinaus. Mistral hat die Aufnahmefähigkeit des Modells hervorgehoben numerous Dialektewobei die subtilen Veränderungen in Kadenz und Prosodie erkannt werden, die regionale Sprecher auszeichnen. Diese technische Präzision macht das Modell zu einem effektiven Werkzeug für globale Anwendungen – vom internationalen Kundensupport bis zur lokalisierten Inhaltserstellung –, bei denen ein allgemeiner, „abgeflachter“ Akzent oft den menschlichen Take a look at nicht besteht.
Adaptive Sprachanpassung
Eines der herausragenden Merkmale für KI-Entwickler ist die Benutzerfreundlichkeit des Modells Stimmanpassung. Voxtral TTS unterstützt das Klonen von Stimmen ohne oder mit wenigen Schüssen und ermöglicht so die Anpassung an eine neue Stimme mit nur wenigen Handgriffen 3 Sekunden Referenzaudio.
Diese Funktion ermöglicht die Erstellung konsistenter Markenstimmen oder personalisierter Benutzererlebnisse, ohne dass umfangreiche Feinabstimmungen erforderlich sind. Da das Modell eine faktorisierte Darstellung verwendet, kann es die Eigenschaften einer Referenzstimme (Klangfarbe, Ton und Tonhöhe) auf jeden generierten Textual content anwenden und dabei die korrekte sprachliche Prosodie der Zielsprache beibehalten.
Benchmarks: Eine Herausforderung für die proprietären Giganten
Die Bewertungen von Mistral konzentrieren sich insbesondere darauf, wie Voxtral TTS im Vergleich zu den aktuellen Branchenführern im Bereich der synthetischen Sprache abschneidet ElfLabs. In menschlichen Präferenztests, die von Muttersprachlern durchgeführt wurden, Voxtral TTS zeigte deutliche Zuwächse an Natürlichkeit und Ausdruckskraft.
- Vs. ElevenLabs Flash v2.5: Voxtral TTS erreichte a 68,4 % Gewinnquote in mehrsprachigen Voice-Cloning-Bewertungen.
- Vs. ElevenLabs v3: Das Modell erreichte Parität oder höhere Werte in SprecherähnlichkeitDies beweist, dass ein Modell mit offener Gewichtung die Wiedergabetreue der fortschrittlichsten proprietären Flaggschiff-Stimmen effektiv erreichen kann.
Diese Benchmarks deuten darauf hin, dass sich die Leistungslücke zwischen Open-Supply-Instruments und kostenintensiven APIs für viele Anwendungsfälle in Unternehmen praktisch geschlossen hat.

Bereitstellung und Integration
Voxtral TTS ist als Teil eines umfassenden Programs konzipiert Audio-Intelligenz Stapel. Es integriert sich nativ mit Voxtrale Transkriptionwodurch eine Finish-to-Finish-Speech-to-Speech-Pipeline (S2S) erstellt wird.
Für KI-Entwickler, die auf einer lokalen oder privaten Cloud-Infrastruktur aufbauen, ist der geringe Platzbedarf des Modells ein erheblicher Vorteil. Das Staff von Mistral hat bestätigt, dass das Modell effizient genug ist, um im Standardbetrieb zu laufen Smartphone und Laptop computer {Hardware} einmal quantisiert. Diese „Edge-Readiness“ ermöglicht eine neue Klasse privater Offline-Anwendungen, von sicheren Unternehmensassistenten bis hin zu Instruments für die Barrierefreiheit auf dem Gerät.
| Spezifikation | Metrisch |
| Modellgröße | 4B Parameter |
| Latenz (10 Sekunden Stimme / 500 Zeichen) | 70ms |
| Echtzeitfaktor (RTF) | ~9,7x |
| Unterstützte Sprachen | 9 |
| Referenz-Audio erforderlich | 3 – 30 Sekunden |
| Lizenz | CC BY-NC |
Wichtige Erkenntnisse
- Hocheffizientes 4B-Parametermodell: Voxtral TTS ist ein Frontier-Modell mit offenem Gewicht 4B-Parameter Footprint unter Verwendung einer Hybridarchitektur, die autoregressive semantische Generierung mit Circulate-Matching für akustische Particulars kombiniert.
- Extrem niedrige Latenz von 70 ms: Das für Echtzeitanwendungen optimierte Modell erreicht a 70 ms Modelllatenz für ein typisches 10-Sekunden-Sprachbeispiel (Eingabe von 500 Zeichen) und eine beeindruckende Echtzeitfaktor (RTF) von ca. 9,7x.
- Überlegene mehrsprachige Leistung: Das Modell unterstützt 9 Sprachen (Englisch, Französisch, Deutsch, Spanisch, Niederländisch, Portugiesisch, Italienisch, Hindi und Arabisch) und übertraf die Leistung ElevenLabs Flash v2.5 mit einem 68,4 % Gewinnquote in menschlichen Präferenztests für das Klonen mehrsprachiger Stimmen.
- Sofortige Sprachanpassung: Entwickler können mit nur wenig Aufwand ein Excessive-Constancy-Stimmenklonen erreichen 3 Sekunden Referenzaudiowas eine sprachübergreifende Zero-Shot-Anpassung ermöglicht, bei der die einzigartige Identität eines Sprechers über verschiedene Sprachen hinweg erhalten bleibt.
- Vollständige Audio-Stack-Integration: Es ist als „Ausgabeschicht“ einer einheitlichen Audio-Intelligence-Pipeline konzipiert und lässt sich nativ integrieren Voxtrale Transkription um durchgängige Speech-to-Speech-Workflows mit geringer Latenz zu erstellen.
Schauen Sie sich das an Papier, Modellgewicht Und Technische Particulars. Sie können uns auch gerne weiter folgen Twitter und vergessen Sie nicht, bei uns mitzumachen 120.000+ ML SubReddit und Abonnieren Unser Publication. Warten! Bist du im Telegram? Jetzt können Sie uns auch per Telegram kontaktieren.