
Retrieval-Augmented Era (RAG) ist zu einer Standardtechnik geworden, um große Sprachmodelle auf externem Wissen zu verankern – doch sobald man über den reinen Textual content hinausgeht und anfängt, Bilder und Movies einzumischen, gerät der gesamte Ansatz ins Wanken. Visuelle Daten sind tokenlastig, im Vergleich zu einer bestimmten Abfrage semantisch spärlich und werden bei der mehrstufigen Argumentation schnell unhandlich. Forscher des Tongyi Lab der Alibaba Group stellten „VimRAG“ vor, ein Framework, das speziell zur Behebung dieses Issues entwickelt wurde.
Das Downside: Sowohl der lineare Verlauf als auch der komprimierte Speicher versagen bei visuellen Daten
Die meisten RAG-Agenten folgen heute einer Gedanken-Handlung-Beobachtungsschleife – manchmal auch ReAct genannt –, bei der der Agent seinen gesamten Interaktionsverlauf in einen einzigen wachsenden Kontext einfügt. Formal ist die Geschichte bei Schritt t HT = (q, τ1A1o1…, τt-1At-1ot-1). Bei Aufgaben, die Movies oder visuell aufwendige Dokumente einbinden, wird dies schnell unhaltbar: Die Informationsdichte kritischer Beobachtungen |Okrit|/|HT| fällt mit zunehmenden Argumentationsschritten gegen Null.
Die natürliche Reaktion ist eine speicherbasierte Komprimierung, bei der der Agent vergangene Beobachtungen iterativ in einem kompakten Zustand zusammenfasst. Dadurch bleibt die Dichte bei |O stabilkrit|/|mT| ≈ C, führt aber zur Markov’schen Blindheit – der Agent verliert den Überblick darüber, was er bereits abgefragt hat, was in Multi-Hop-Szenarien zu wiederholten Suchvorgängen führt. In einer Pilotstudie, in der ReAct, iterative Zusammenfassung und graphbasierter Speicher unter Verwendung von Qwen3VL-30B-A3B-Instruct an einem Videokorpus verglichen wurden, litten auf Zusammenfassungen basierende Agenten genauso stark unter Zustandsblindheit wie ReAct, während graphbasierter Speicher redundante Suchaktionen erheblich reduzierte.
In einer zweiten Pilotstudie wurden vier modalitätsübergreifende Gedächtnisstrategien getestet. Die Vorbeschriftung (Textual content → Textual content) verbraucht nur 0,9.000 Token, erreicht aber bei Bildaufgaben nur 14,5 % und bei Videoaufgaben nur 17,2 %. Das Speichern roher visueller Token verbraucht 15,8.000 Token und erreicht 45,6 % bzw. 30,4 % – Rauschen überlagert das Sign. Kontextbezogene Untertitel werden zu Textual content komprimiert und auf 52,8 % bzw. 39,5 % verbessert, es gehen jedoch feinkörnige Particulars verloren, die zur Überprüfung erforderlich sind. Die selektive Beibehaltung nur relevanter Imaginative and prescient-Tokens – Semantisch-bezogenes visuelles Gedächtnis – verwendet 2,7.000 Token und erreicht 58,2 % und 43,7 %, den besten Kompromiss. Eine dritte Pilotstudie zur Kreditzuweisung ergab, dass in positiven Trajektorien (Belohnung = 1) etwa 80 % der Schritte Rauschen enthalten, das unter standardmäßigem ergebnisbasierten RL fälschlicherweise ein positives Gradientensignal empfangen würde, und dass durch das Entfernen redundanter Schritte aus negativen Trajektorien die Leistung vollständig wiederhergestellt wurde. Diese drei Erkenntnisse motivieren direkt Die drei Kernkomponenten von VimRAG.
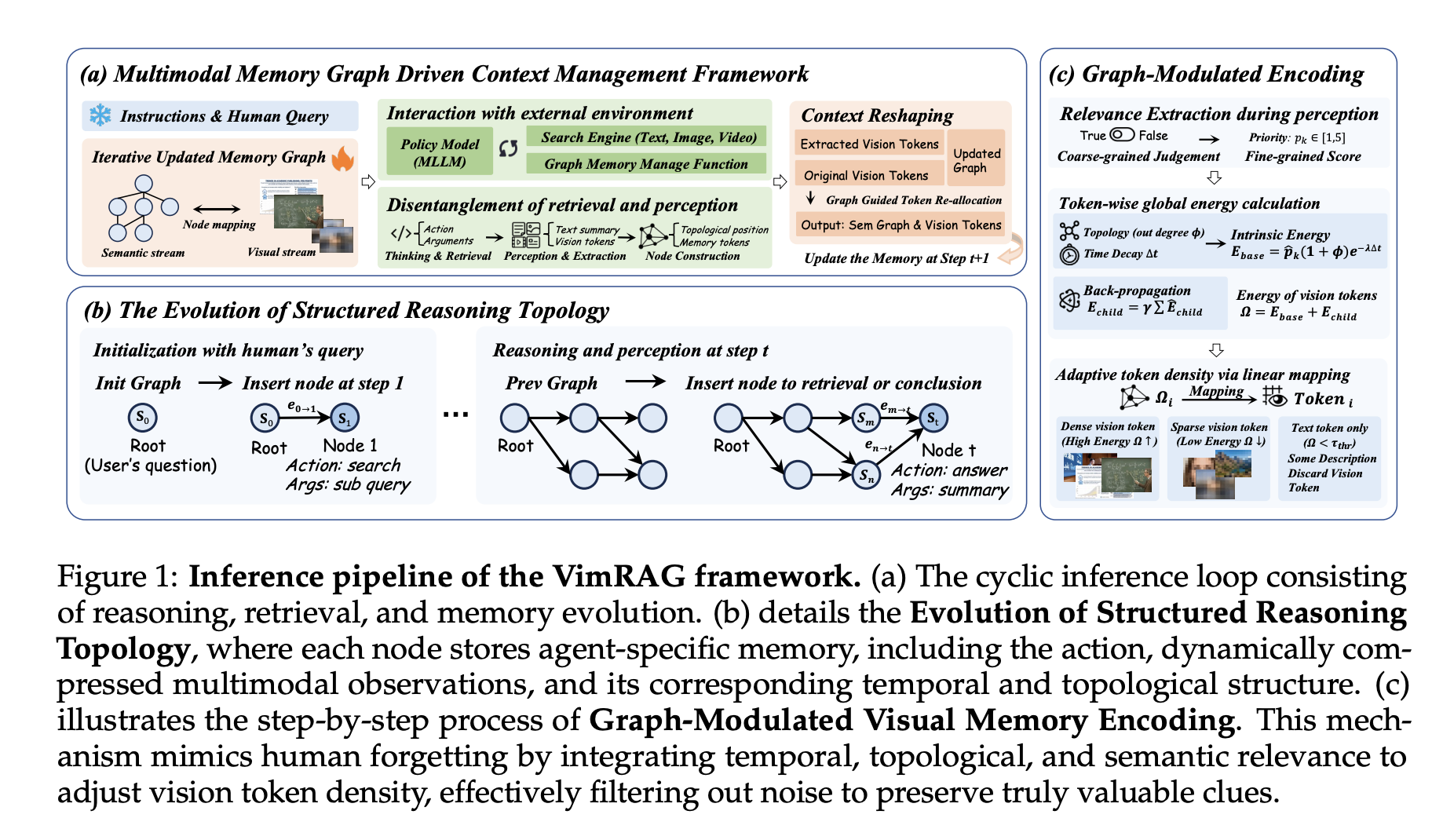
Die dreiteilige Architektur von VimRAG
- Der erste Komponente ist der multimodale Gedächtnisgraph. Anstelle eines flachen Verlaufs oder einer komprimierten Zusammenfassung wird der Argumentationsprozess als dynamisch gerichteter azyklischer Graph G modelliertT(VTET) Jeder Knoten vich kodiert ein Tupel (SichQichSichMich): Indizes des übergeordneten Knotens, die die lokale Abhängigkeitsstruktur kodieren, eine zerlegte Unterabfrage, die der Suchaktion zugeordnet ist, eine prägnante Textzusammenfassung und eine multimodale episodische Speicherbank mit visuellen Token aus abgerufenen Dokumenten oder Frames. Bei jedem Schritt werden in der Richtlinie drei Aktionstypen ausgewählt: aim Ruhestand (explorativer Abruf, Erzeugen eines neuen Knotens und Ausführen einer Unterabfrage), amem (multimodale Wahrnehmung und Gedächtnispopulation, Destillation roher Beobachtungen in eine Zusammenfassung sT und visuelle Token mT unter Verwendung einer groben bis feinen binären Ausprägungsmaske u ∈ {0,1} und einer feinkörnigen semantischen Bewertung p ∈ (1,5)) und aans (Terminalprojektion, ausgeführt, wenn das Diagramm genügend Beweise enthält). Für Videobeobachtungen amem nutzt die zeitliche Erdungsfähigkeit von Qwen3-VL, um Schlüsselbilder zu extrahieren, die an Zeitstempeln ausgerichtet sind, bevor der Knoten gefüllt wird.
- Der zweite Komponente ist Graph-Modulated Visible Reminiscence Encoding, das die Tokenzuweisung als ein eingeschränktes Ressourcenzuweisungsproblem behandelt. Für jedes visuelle Factor mich okaydie intrinsische Energie wird als E berechnetint(Mich okay) = p̂ich okay · (1 + Grad+G(Vich)) · exp(−λ(T − tich)), die semantische Priorität, Knoten-Out-Grad für strukturelle Relevanz und zeitlichen Verfall kombiniert, um ältere Beweise auszuschließen. Endenergie fügt rekursive Verstärkung von Nachfolgeknoten hinzu: wodurch grundlegende frühe Knoten erhalten bleiben, die hochwertige nachgelagerte Überlegungen unterstützen. Token-Budgets werden proportional zu den Energiewerten einer globalen High-Ok-Auswahl zugewiesen, mit einem Gesamtressourcenbudget von Sgesamt = 5 × 256 × 32 × 32. Die dynamische Zuordnung ist nur während der Inferenz aktiviert; Beim Coaching werden die Pixelwerte in der Speicherbank gemittelt.
- Der dritte Komponente ist Graph-Guided Coverage Optimization (GGPO). Bei positiven Stichproben (Belohnung = 1) werden Gradientenmasken auf Sackgassenknoten angewendet, die sich nicht auf dem kritischen Pfad von der Wurzel zum Antwortknoten befinden, wodurch eine optimistic Verstärkung des redundanten Abrufs verhindert wird. Bei negativen Stichproben (Belohnung = 0) werden Schritte, bei denen Abrufergebnisse relevante Informationen enthalten, von der Aktualisierung des negativen Richtliniengradienten ausgeschlossen. Die binäre Beschneidungsmaske ist definiert als . Die Ablation bestätigt, dass dies zu einer schnelleren Konvergenz und stabileren Belohnungskurven führt als der Basislinien-GSPO ohne Beschneidung.
Ergebnisse und Verfügbarkeit
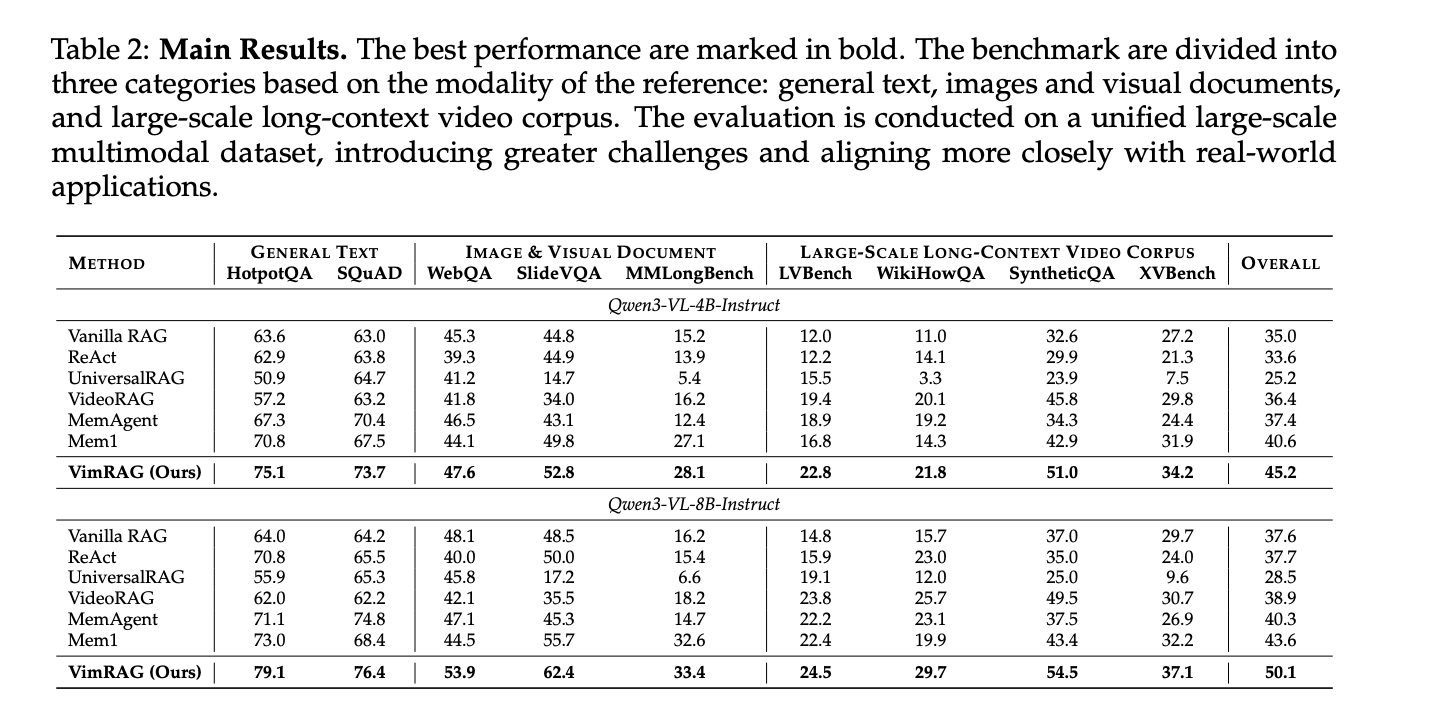
VimRAG wurde anhand von neun Benchmarks bewertet – HotpotQA, SQuAD, WebQA, SlideVQA, MMLongBench, LVBench, WikiHowQA, SyntheticQA und Alle neun Datensätze wurden zu einem einzigen einheitlichen Korpus aus etwa 200.000 verschachtelten multimodalen Elementen zusammengeführt, was die Auswertung schwieriger und repräsentativer für die realen Bedingungen macht. GVE-7B diente als Einbettungsmodell zur Unterstützung des Textual content-zu-Textual content-, Bild- und Videoabrufs.
Auf Qwen3-VL-8B-Instruct erreicht VimRAG eine Gesamtpunktzahl von 50,1 gegenüber 43,6 für Mem1, der bisher besten Baseline. Auf Qwen3-VL-4B-Instruct erreicht VimRAG 45,2 gegenüber 40,6 von Mem1. Auf SlideVQA mit dem 8B-Spine erreicht VimRAG 62,4 gegenüber 55,7; bei SyntheticQA: 54,5 gegenüber 43,4. Trotz der Einführung eines dedizierten Wahrnehmungsschritts reduziert VimRAG im Vergleich zu ReAct und Mem1 auch die Gesamtlänge der Trajektorie, da der strukturierte Speicher das wiederholte erneute Lesen und ungültige Suchen verhindert, die dazu führen, dass lineare Methoden einen großen Teil der Token-Nutzung anhäufen.
Wichtige Erkenntnisse
- VimRAG ersetzt den linearen Interaktionsverlauf durch einen dynamisch gerichteten azyklischen Graphen (Multimodal Reminiscence Graph) Es verfolgt den Argumentationszustand des Agenten über Schritte hinweg und verhindert so die sich wiederholenden Abfragen und die Zustandsblindheit, die bei Normal-ReAct- und zusammenfassungsbasierten RAG-Agenten bei der Verarbeitung großer Mengen visueller Daten auftreten.
- Graph-Modulated Visible Reminiscence Encoding löst das Downside des visuellen Token-Budgets durch die dynamische Zuweisung hochauflösender Token zu den wichtigsten abgerufenen Beweisen basierend auf semantischer Relevanz, topologischer Place im Diagramm und zeitlichem Verfall – anstatt alle abgerufenen Bilder und Videobilder mit einheitlicher Auflösung zu behandeln.
- Graph-Guided Coverage Optimization (GGPO) behebt einen grundlegenden Fehler in der Artwork und Weise, wie agentische RAG-Modelle trainiert werden – Standardmäßige ergebnisbasierte Belohnungen bestrafen fälschlicherweise gute Abrufschritte in fehlgeschlagenen Trajektorien und belohnen redundante Schritte in erfolgreichen Trajektorien fälschlicherweise. GGPO nutzt die Diagrammstruktur, um diese irreführenden Verläufe auf Schrittebene zu maskieren.
- Eine Pilotstudie mit vier modalitätsübergreifenden Gedächtnisstrategien zeigte, dass die selektive Beibehaltung relevanter Sehtoken (Semantisch-bezogenes visuelles Gedächtnis) den besten Kompromiss zwischen Genauigkeit und Effizienz erzieltund erreichte 58,2 % bei Bildaufgaben und 43,7 % bei Videoaufgaben mit nur 2,7.000 durchschnittlichen Token – und übertraf damit sowohl rohe visuelle Speicherung als auch reine Textkomprimierungsansätze.
- VimRAG übertrifft alle Baselines in neun Benchmarks auf einem einheitlichen Korpus von etwa 200.000 verschachtelten Textual content-, Bild- und Videoelementenmit einem Gesamtergebnis von 50,1 für Qwen3-VL-8B-Instruct im Vergleich zu 43,6 für die zuvor beste Basislinie Mem1, während gleichzeitig die Gesamtlänge der Inferenztrajektorie reduziert wird, obwohl ein dedizierter multimodaler Wahrnehmungsschritt hinzugefügt wurde.
Schauen Sie sich das an Papier, Repo Und Modellgewichte. Sie können uns auch gerne weiter folgen Twitter und vergessen Sie nicht, bei uns mitzumachen 120.000+ ML SubReddit und Abonnieren Unser E-newsletter. Warten! Bist du im Telegram? Jetzt können Sie uns auch per Telegram kontaktieren.
Möchten Sie mit uns zusammenarbeiten, um Ihr GitHub-Repo ODER Ihre Hugging Face Web page ODER Produktveröffentlichung ODER Ihr Webinar usw. zu bewerben? Vernetzen Sie sich mit uns

Michal Sutter ist ein Knowledge-Science-Experte mit einem Grasp of Science in Knowledge Science von der Universität Padua. Mit einer soliden Grundlage in statistischer Analyse, maschinellem Lernen und Datentechnik ist Michal hervorragend darin, komplexe Datensätze in umsetzbare Erkenntnisse umzuwandeln.