# Feinabstimmung von Sprachmodellen auf Apple Silicon mit MLX
Die Feinabstimmung eines Sprachmodells bedeutete früher, Cloud-GPUs zu mieten und zu beobachten, wie der Zähler läuft. Wenn Sie einen Mac mit einem Apple Silicon-Chip besitzen, können Sie jetzt ein offenes Modell lokal und ohne Cloud-Kosten an Ihre eigenen Daten anpassen, indem Sie ein Framework verwenden, das speziell für die {Hardware} in Ihrem Laptop computer entwickelt wurde.
Ich bin 2014 von Home windows- und Dell-Rechnern auf den Mac umgestiegen und habe es nie bereut. Was als Neugier auf ein saubereres Betriebssystem begann, entwickelte sich zu einer tiefen Wertschätzung dafür, wie eng Apple {Hardware} und Software program integriert. Über ein Jahrzehnt später zahlt sich diese Integration aus, die ich nie erwartet hätte, zuletzt durch die Möglichkeit, Sprachmodelle vollständig auf dem Gerät zu optimieren, ohne dass eine Cloud-Rechnung oder ein einziges Datenbyte meinen Laptop verlässt.
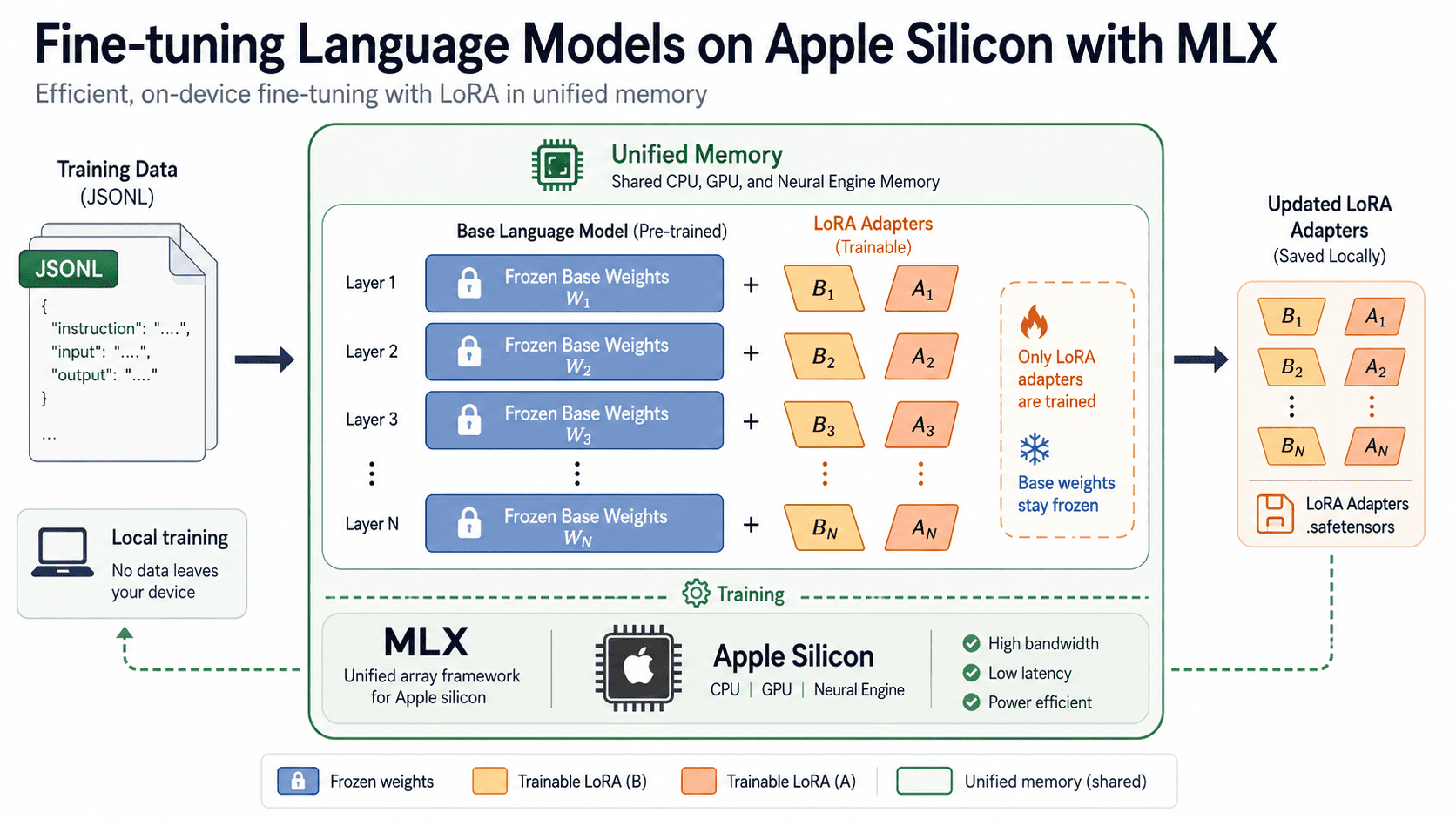
Diese Fähigkeit wird unterstützt von MLXeine Open-Supply-Array-Bibliothek des Apple-Forschungsteams für maschinelles Lernen, und das Begleitpaket MLX LMdas über einen kleinen Befehlssatz die Textgenerierung und Feinabstimmung für Tausende offener Modelle ermöglicht. Dieses Tutorial führt Sie durch den gesamten Prozess: Set up der Instruments, Vorbereiten eines Datensatzes, Coaching eines LoRA-Adapters, Reduzierung der Speichernutzung durch Quantisierung, anschließendes Testen und Bereitstellen des Ergebnisses. Am Ende verfügen Sie über ein fein abgestimmtes Modell, das auf Ihrem eigenen Laptop ausgeführt wird, und über einen wiederholbaren Arbeitsablauf, den Sie auf jeden Datensatz verweisen können.
# Verstehen, warum MLX zu Apple Silicon passt
Die meisten lokalen Inferenztools begannen auf NVIDIA-{Hardware} und wurden später auf den Mac portiert. MLX ging den umgekehrten Weg. Das Forschungsteam von Apple hat es von Grund auf auf der Grundlage der einheitlichen Speicherarchitektur von Apple Silicon entwickelt, bei der sich CPU und GPU einen einzigen Speicherpool teilen.
Durch dieses Design entfällt der Kopierschritt, der normalerweise Daten zwischen dem Systemspeicher und dem dedizierten GPU-Speicher hin- und herbewegt. Auf einem 16-GB-Mac sind die Modellgewichte, der Optimierungsstatus und der Trainingsbatch alle im selben Bereich vorhanden, was genau das macht, was die Feinabstimmung auf dem Gerät praktisch und nicht erstrebenswert macht. Die API spiegelt NumPy genau, fügt automatische Differenzierung für Coaching und Verwendung hinzu Metall um die GPU-Arbeit zu beschleunigen und gleichzeitig die gemeinsame Sicht auf den Speicher beizubehalten.
Bevor Sie beginnen, benötigen Sie einen Apple Silicon Mac (M1 oder neuer), macOS Ventura 13.5 oder höher und Python 3.10 oder höher. Intel-Macs werden nicht unterstützt. Beim Versuch, auf einem zu installieren, wird der Fehler „Keine passende Distribution“ zurückgegeben.
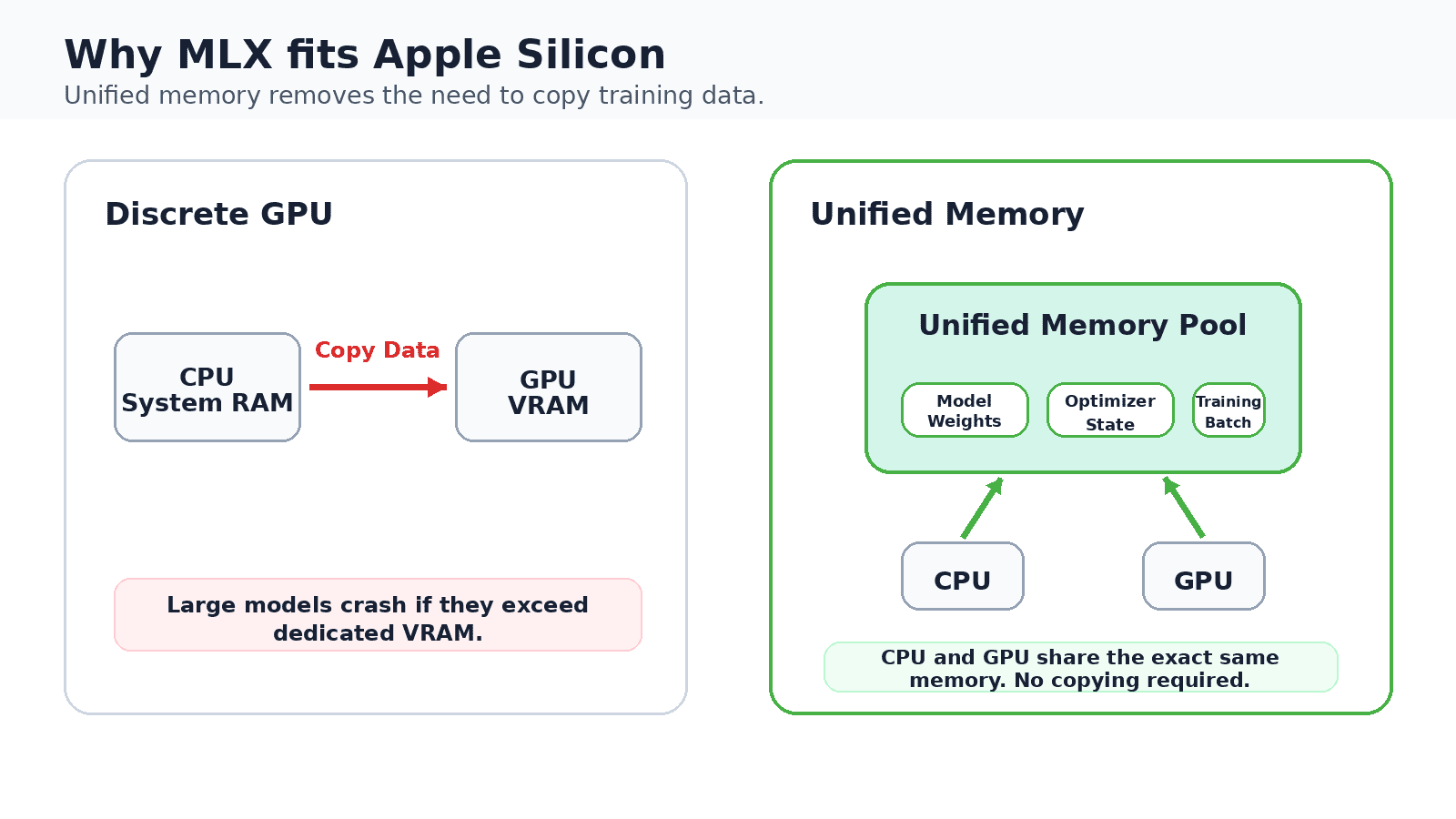
Auf einer separaten GPU werden Trainingsdaten zwischen dem Systemspeicher und dem dedizierten GPU-Speicher kopiert. Apple Silicon verfügt über einen gemeinsamen Pool, der es einem 16-GB-Mac ermöglicht, Modelle lokal zu optimieren.
# Einrichten Ihrer Umgebung
Lassen Sie uns unter Berücksichtigung dieser Architektur die Instruments installieren. Beginnen Sie mit dem Paket und seinen Trainingsextras, die alles enthalten, was die Feinabstimmungsbefehle benötigen.
pip set up "mlx-lm(practice)"Bestätigen Sie, dass die Set up mit einem schnellen Generierungstest anhand eines kleinen Modells funktioniert.
mlx_lm.generate
--model mlx-community/Mistral-7B-Instruct-v0.3-4bit
--prompt "Clarify LoRA in two sentences."
--max-tokens 120Beim ersten Durchlauf wird eine 4-Bit-Quantisierung heruntergeladen Mistral Modell aus der MLX-Neighborhood Organisation auf Umarmendes Gesichtspeichert es lokal zwischen und streamt dann eine Antwort. Die mlx-community-Organisation hostet Tausende vorkonvertierter Modelle, sodass Sie die Gewichtungen selten selbst konvertieren müssen.
Eine Einschränkung, die es zu beachten gilt: Für die MLX-Feinabstimmung sind Modelle im Hugging-Face-Safetensors-Format erforderlich. GGUF-Dateien, die in anderen lokalen Instruments üblich sind, dienen hier der Inferenz, aber nicht dem Coaching. Zu den unterstützten Architekturen gehören unter anderem Llama, Mistral, Qwen2, Phi, Gemma und Mixtral, sodass die beliebtesten offenen Modelle sofort verfügbar sind.
# Vorbereiten Ihres Datensatzes
Nachdem die Umgebung nun bereit ist, besteht der nächste Schritt darin, Ihre Daten in eine Type zu bringen, die der Coach verwenden kann. MLX LM liest Trainingsdaten aus einem Ordner mit drei Dateien: practice.jsonl, legitimate.jsonlund ein optionales take a look at.jsonl. Jede Zeile enthält ein JSON-Beispiel. Die Trainingsdatei ist erforderlich, die Validierungsdatei ermöglicht es dem Coach, während der Ausführung einen Validierungsverlust zu melden, und die Testdatei bewertet das Modell nach Abschluss des Trainings.
Drei Formate werden unterstützt: Chat, Vervollständigungen und Textual content. Das Chat-Format ist die robusteste Standardeinstellung. Es speichert mit Rollen versehene Nachrichten professional Zeile und ermöglicht MLX LM, die eigene Chat-Vorlage des Modells anzuwenden, sodass Ihre Daten mit der Artwork und Weise übereinstimmen, wie das Modell für den Umgang mit Gesprächen trainiert wurde.
{"messages": ({"function": "person", "content material": "What's LoRA?"}, {"function": "assistant", "content material": "An environment friendly option to fine-tune a mannequin."})}Für einfache Eingabe- und Ausgabepaare ist das Vervollständigungsformat einfacher und eignet sich intestine für Aufgaben im Befehlsstil.
{"immediate": "Summarize: The market rose sharply right now.", "completion": "Markets gained."}
{"immediate": "Translate to French: good morning", "completion": "bonjour"}Standardmäßig berechnet der Coach den Verlust über das gesamte Beispiel, was bedeutet, dass das Modell Mühe aufwendet, um sowohl die Eingabeaufforderung als auch die Antwort zu reproduzieren. Vorbeigehen --mask-prompt weist es an, den Verlust nur für den Abschluss zu berechnen, sodass sich das Coaching auf die Reaktion konzentriert, die Ihnen tatsächlich am Herzen liegt. Dies führt normalerweise zu einem Modell, das Anweisungen zuverlässiger befolgt und mit den Chat- und Vervollständigungsformaten funktioniert. Bei Chat-Daten wird die letzte Nachricht in der Liste als Abschluss behandelt.
Halten Sie jedes Beispiel in einer einzelnen Zeile ohne interne Zeilenumbrüche, da der Leser jede Zeile als separaten Datensatz behandelt. Teilen Sie Ihre Daten so auf, dass etwa 80 Prozent darin landen practice.jsonl und 10 bis 20 Prozent in legitimate.jsonl. Etwa 200 bis 500 Beispiele sind ein sinnvolles Minimal, um das Verhalten eines Modells zu ändern (wesentlich weniger neigen dazu, sich zu überanpassen und sich einzuprägen, statt zu verallgemeinern).
# Trainieren Sie Ihren ersten LoRA-Adapter
Wenn Ihre Daten vorhanden sind, wird es hier interessant. Anstatt jedes Gewicht im Modell zu aktualisieren, friert Low-Rank Adaptation (LoRA) die ursprünglichen Gewichte ein und trainiert neben ihnen kleine Adaptermatrizen. Dadurch sinkt der Speicher- und Speicherbedarf auf einen Bruchteil der vollständigen Feinabstimmung, während der Großteil der Qualität erhalten bleibt. Die Methode stammt aus der LoRA-Papier von Hu und Kollegen.

LoRA hält die großen vorab trainierten Gewichte eingefroren und trainiert nur die kleinen Matrizen A und B. Da nur diese beiden Adapter Updates erhalten, bleiben Speicher und Speicher gering.
Starten Sie einen Trainingslauf mit einem einzigen Befehl und richten Sie ihn auf ein Modell und Ihren Datenordner.
mlx_lm.lora
--model mlx-community/Mistral-7B-Instruct-v0.3-4bit
--train
--data ./knowledge
--iters 600
--batch-size 1Während der Ausführung gibt MLX LM Trainingsverluste, Validierungsverluste, verarbeitete Token und Iterationen professional Sekunde aus. Adaptergewichte sparen an adapters Ordner standardmäßig. Wichtige wissenswerte Flags: --fine-tune-type akzeptiert lora (die Standardeinstellung), doraoder full; --num-layers legt fest, wie viele Transformatorschichten Adapter empfangen (Customary: 16); Und --iters Steuert die Trainingsdauer.
Das Beispiel setzt --batch-size 1 mit Absicht, um den Speicherverbrauch so gering wie möglich zu halten. Dies verhindert Abstürze auf 16-GB-Maschinen. Wenn Sie über 64 GB oder mehr verfügen, verkürzt die Erhöhung auf 2 oder 4 die gesamte Trainingszeit. Wenn der Speicher knapp ist, Sie aber den Glättungseffekt einer größeren Cost wünschen, --grad-accumulation-steps Erhöht die effektive Stapelgröße, ohne die Speichernutzung zu erhöhen.
Wenn Sie Dwell-Diagramme gegenüber der Terminalausgabe bevorzugen, fügen Sie hinzu --report-to wandb um Metriken zu protokollieren Gewichte und Voreingenommenheiten. Wenn Sie auf Gedächtnisdruck stoßen, verringern Sie ihn --num-layers auf 8 oder 4, oder hinzufügen --grad-checkpoint um die Berechnung gegen weniger Speicher einzutauschen. Diese beiden Flaggen reichen normalerweise aus, um einen Job unterzubringen, bei dem andernfalls kein Platz mehr vorhanden wäre.
# Auswählen eines Basismodells und Adaptereinstellungen
Aufbauend auf den oben genannten Trainingsmechanismen prägen zwei frühe Entscheidungen den Relaxation Ihres Laufs: mit welchem Modell Sie beginnen und wie viel davon Sie anpassen möchten. Für ein erstes Projekt ist ein 8B-Parametermodell in 4-Bit-Type der Candy Spot. Sobald sich der Arbeitsablauf angenehm anfühlt, können Sie auf 13B- oder 14B-Modelle umsteigen, die 14 bis 18 GB Arbeitsspeicher benötigen und bequem auf einem 32-GB-Rechner Platz finden.
Die Anzahl der trainierten Schichten und der Adapterrang steuern zusammen die Kapazität. Mehr Schichten und ein höherer Rang geben dem Adapter mehr Spielraum zum Lernen, allerdings auf Kosten von Speicher und Zeit. Ein üblicher Ausgangspunkt verwendet 16 Ebenen mit einem moderaten Rang und passt dann basierend darauf an, ob der Validierungsverlust immer noch sinkt. Wenn der Trainingsverlust sinkt, während der Validierungsverlust steigt, merkt sich der Adapter Ihre Beispiele.
Auch die Lerngeschwindigkeit ist wichtig. Werte im Bereich von 1e-5 bis 5e-5 funktionieren für die meisten LoRA-Läufe. Zu hoch und das Coaching wird instabil; zu niedrig und das Modell bewegt sich kaum. Ändern Sie jeweils eine Einstellung, damit Sie jede Verbesserung einer bestimmten Auswahl zuordnen können.
# Reduzieren der Speichernutzung durch Quantisierung
Beachten Sie, dass das obige Basismodell bereits mit endet 4bit. Das Coaching eines LoRA-Adapters auf der Grundlage eines quantisierten Modells wird als QLoRA bezeichnet und im beschrieben QLoRA-Papier. Da die Quantisierung in MLX integriert ist, gilt das Gleiche mlx_lm.lora Der Befehl trainiert Adapter direkt auf quantisierten Gewichten, ohne dass zusätzliche Einstellungen erforderlich sind.
Die Auszahlung ist konkret. Ein 4-Bit-7B-Modell reduziert den Gewichtsspeicher um etwa das 3,5-fache im Vergleich zu voller Präzision und bringt eine 7B-Feinabstimmung bequem in 8 GB Arbeitsspeicher. Auf einem 16-GB-MacBook bleibt dadurch ausreichend Spielraum für das Betriebssystem und Ihr Trainingspaket.
Wenn Sie ein Modell mit voller Präzision vor dem Coaching lieber selbst quantisieren möchten, übernimmt der Befehl „convert“ dies.
mlx_lm.convert
--hf-path mistralai/Mistral-7B-Instruct-v0.3
--mlx-path ./mistral-4bit
-qDadurch wird eine 4-Bit-Model in einen lokalen Ordner geschrieben, den Sie dann übergeben --model.
# Testen und Generieren mit Ihrem Adapter
Nach Abschluss der Schulung ist es an der Zeit zu sehen, wie intestine der Adapter gelernt hat. Bewerten Sie es mit Ihrem durchgehaltenen Testsatz, um eine Zahl zu erhalten, die Sie über Experimente hinweg verfolgen können.
mlx_lm.lora
--model mlx-community/Mistral-7B-Instruct-v0.3-4bit
--adapter-path ./adapters
--data ./knowledge
--testUm zu sehen, wie das Modell reagiert, übergeben Sie denselben Adapterpfad an den Befehl „generate“. MLX LM lädt das Basismodell und wendet Ihren Adapter darauf an.
mlx_lm.generate
--model mlx-community/Mistral-7B-Instruct-v0.3-4bit
--adapter-path ./adapters
--prompt "Summarize: Our quarterly income grew twelve %."Führen Sie dieselbe Eingabeaufforderung ohne den zu vergleichenden Adapter aus. Wenn Ihr Datensatz intestine mit der Zielaufgabe übereinstimmt, sollten die angepassten Antworten Ihre Trainingsbeispiele genauer verfolgen als das Basismodell.
# Das Modell verschmelzen und ihm dienen
Adapter sind beim Experimentieren praktisch, für die Bereitstellung benötigen Sie jedoch häufig ein einzelnes, eigenständiges Modell. Der Befehl „fuse“ fügt den Adapter wieder in die Basisgewichte ein.
mlx_lm.fuse
--model mlx-community/Mistral-7B-Instruct-v0.3-4bit
--adapter-path ./adapters
--save-path ./fused-modelDer verschmolzene Ordner verhält sich wie jedes andere MLX-Modell. Sie können es über einen OpenAI-kompatiblen Endpunkt bereitstellen, der vorhandenen Shopper-Code nach nur einer Änderung der Foundation-URL mit Ihrem lokalen Modell kommunizieren lässt.
mlx_lm.server --model ./fused-model --port 8080Für eine grafische Different: LM Studio führt MLX-Modelle mit einem lokalen Ein-Klick-Server und einer Chat-Schnittstelle aus, was besonders nützlich ist, wenn Sie Ihr fein abgestimmtes Modell nebeneinander mit anderen vergleichen möchten.
# Zusammenfassung
Sie verfügen nun über einen vollständigen lokalen Feinabstimmungsworkflow: Installieren Sie MLX LM, formatieren Sie einen Datensatz als JSONL, trainieren Sie einen LoRA- oder QLoRA-Adapter mit einem einzigen Befehl, testen Sie ihn, führen Sie dann eine Fusion durch und stellen Sie das Ergebnis bereit. Alles läuft auf dem Mac, den Sie bereits besitzen, ohne Cloud-Rechnung und ohne Daten, die Ihren Laptop verlassen.
Für mich fühlt sich das wie eine natürliche Fortsetzung der Reise an, die begann, als ich 2014 zum Mac wechselte. Die enge {Hardware}-Software program-Integration, die mich zunächst anzog, hat sich im Stillen zu etwas weitaus Leistungsstärkerem entwickelt, einer Maschine, die ernsthafte maschinelle Lernaufgaben am Küchentisch bewältigen kann.
Als nächstes lohnt es sich, einige Richtungen zu erkunden. Probieren Sie es aus dora Feinabstimmung des Typs und Vergleich der Ergebnisse mit normalem LoRA. Passen Sie die Anzahl der trainierten Schichten und die Anzahl der Iterationen an, um Qualität und Geschwindigkeit auszugleichen. Tauschen Sie eine andere Basisarchitektur aus. Lama, Qwen, Phi und Gemma arbeiten alle mit denselben Befehlen. Jedes Experiment ist kostengünstig, wenn die {Hardware} auf Ihrem Schreibtisch steht. Dies ist die praktische Änderung, die MLX bei der Anpassung von Sprachmodellen mit sich bringt.
Vinod Chugani ist ein KI- und Datenwissenschaftspädagoge, der die Lücke zwischen neuen KI-Technologien und der praktischen Anwendung für Berufstätige schließt. Zu seinen Schwerpunkten zählen Agentische KI, Anwendungen für maschinelles Lernen und Automatisierungsworkflows. Durch seine Arbeit als technischer Mentor und Ausbilder hat Vinod Datenprofis bei der Kompetenzentwicklung und bei Karriereübergängen unterstützt. Er bringt analytisches Fachwissen aus dem quantitativen Finanzwesen in seinen praxisorientierten Lehransatz ein. Sein Inhalt betont umsetzbare Strategien und Rahmenbedingungen, die Fachleute sofort anwenden können.