Basis-Modelle sind large Deep-Studying-Modelle, die anhand einer enormen Menge allgemeiner, nicht gekennzeichneter Daten vortrainiert wurden. Sie können für eine Vielzahl von Aufgaben eingesetzt werden, beispielsweise zum Generieren von Bildern oder zum Beantworten von Kundenfragen.
Doch diese Modelle, die das Rückgrat leistungsstarker künstlicher Intelligenztools wie ChatGPT und DALL-E bilden, können falsche oder irreführende Informationen liefern. In einer sicherheitskritischen State of affairs, wie etwa wenn sich ein Fußgänger einem selbstfahrenden Auto nähert, könnten solche Fehler schwerwiegende Folgen haben.
Um solche Fehler zu vermeiden, haben Forscher vom MIT und dem MIT-IBM Watson AI Lab entwickelte eine Technik um die Zuverlässigkeit grundlegender Modelle abzuschätzen, bevor diese für eine bestimmte Aufgabe eingesetzt werden.
Dazu betrachten sie eine Reihe von Basismodellen, die sich leicht voneinander unterscheiden. Anschließend verwenden sie ihren Algorithmus, um die Konsistenz der Darstellungen zu bewerten, die jedes Modell über denselben Testdatenpunkt lernt. Wenn die Darstellungen konsistent sind, bedeutet dies, dass das Modell zuverlässig ist.
Als sie ihre Technik mit modernsten Basismethoden verglichen, konnte sie die Zuverlässigkeit von Basismodellen bei einer Vielzahl nachgelagerter Klassifizierungsaufgaben besser erfassen.
Mithilfe dieser Technik könnte man entscheiden, ob ein Modell in einer bestimmten Umgebung angewendet werden soll, ohne es an einem realen Datensatz testen zu müssen. Dies könnte insbesondere dann nützlich sein, wenn Datensätze aus Datenschutzgründen nicht zugänglich sind, wie etwa im Gesundheitswesen. Darüber hinaus könnte die Technik verwendet werden, um Modelle anhand von Zuverlässigkeitswerten zu bewerten, sodass ein Benutzer das beste Modell für seine Aufgabe auswählen kann.
„Alle Modelle können falsch sein, aber Modelle, die wissen, wann sie falsch sind, sind nützlicher. Das Downside der Quantifizierung von Unsicherheit oder Zuverlässigkeit ist bei diesen grundlegenden Modellen schwieriger, da ihre abstrakten Darstellungen schwer zu vergleichen sind. Unsere Methode ermöglicht es, zu quantifizieren, wie zuverlässig ein Darstellungsmodell für beliebige Eingabedaten ist“, sagt der leitende Autor Navid Azizan, Esther and Harold E. Edgerton Assistant Professor an der Fakultät für Maschinenbau des MIT und am Institute for Information, Programs, and Society (IDSS) sowie Mitglied des Laboratory for Data and Determination Programs (LIDS).
Er ist verbunden mit einem Papier über die Arbeit von Hauptautor Younger-Jin Park, einem LIDS-Studenten; Hao Wang, einem Forschungswissenschaftler am MIT-IBM Watson AI Lab; und Shervin Ardeshir, einem leitenden Forschungswissenschaftler bei Netflix. Das Papier wird auf der Konferenz über Unsicherheit in der künstlichen Intelligenz vorgestellt.
Konsens messen
Herkömmliche Modelle des maschinellen Lernens werden trainiert, um eine bestimmte Aufgabe auszuführen. Diese Modelle treffen in der Regel eine konkrete Vorhersage auf der Grundlage einer Eingabe. Das Modell könnte Ihnen beispielsweise sagen, ob ein bestimmtes Bild eine Katze oder einen Hund enthält. In diesem Fall könnte die Beurteilung der Zuverlässigkeit darin bestehen, sich die endgültige Vorhersage anzusehen, um festzustellen, ob das Modell richtig ist.
Bei Basismodellen ist das jedoch anders. Das Modell wird mit allgemeinen Daten vorab trainiert, und zwar in einer Umgebung, in der die Entwickler nicht alle nachfolgenden Aufgaben kennen, auf die es angewendet wird. Benutzer passen es nach dem Coaching an ihre spezifischen Aufgaben an.
Im Gegensatz zu herkömmlichen Modellen des maschinellen Lernens liefern Basismodelle keine konkreten Ergebnisse wie die Bezeichnungen „Katze“ oder „Hund“. Stattdessen generieren sie eine abstrakte Darstellung auf Grundlage eines Eingabedatenpunkts.
Um die Zuverlässigkeit eines Basismodells zu beurteilen, verwendeten die Forscher einen Ensemble-Ansatz, indem sie mehrere Modelle trainierten, die viele Eigenschaften gemeinsam haben, sich jedoch leicht voneinander unterscheiden.
„Unsere Idee ist, den Konsens zu messen. Wenn alle diese Basismodelle konsistente Darstellungen für alle Daten in unserem Datensatz liefern, können wir sagen, dass dieses Modell zuverlässig ist“, sagt Park.
Sie stießen jedoch auf ein Downside: Wie konnten sie abstrakte Darstellungen vergleichen?
„Diese Modelle geben lediglich einen Vektor aus, der aus einigen Zahlen besteht, daher können wir sie nicht einfach vergleichen“, fügt er hinzu.
Sie lösten dieses Downside mit einer Idee namens Nachbarschaftskonsistenz.
Für ihren Ansatz bereiten die Forscher eine Reihe zuverlässiger Referenzpunkte vor, die sie an der Gesamtheit der Modelle testen. Anschließend untersuchen sie für jedes Modell die Referenzpunkte, die sich in der Nähe der Darstellung des Testpunkts dieses Modells befinden.
Indem sie die Konsistenz benachbarter Punkte betrachten, können sie die Zuverlässigkeit der Modelle einschätzen.
Ausrichten der Darstellungen
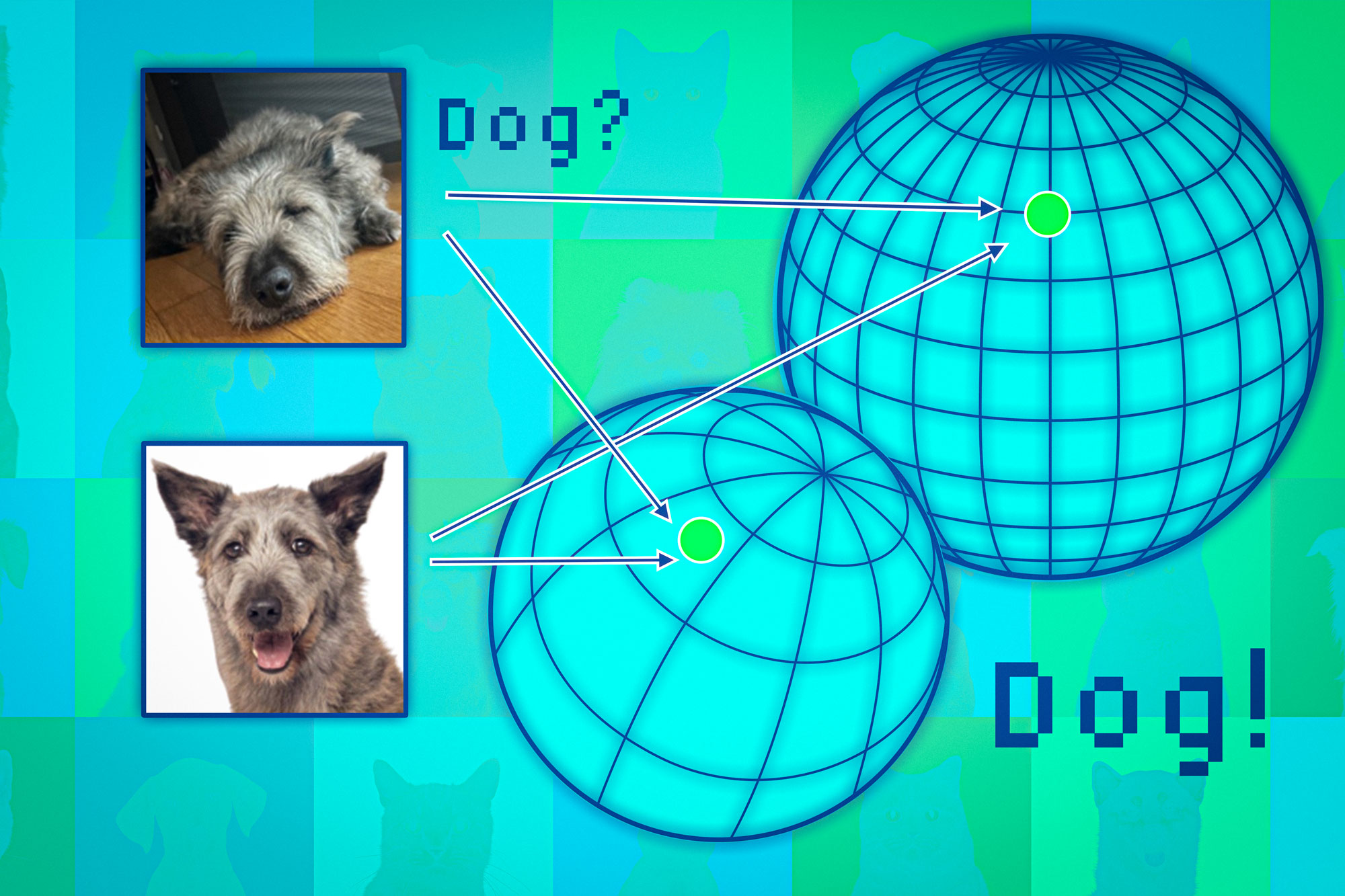
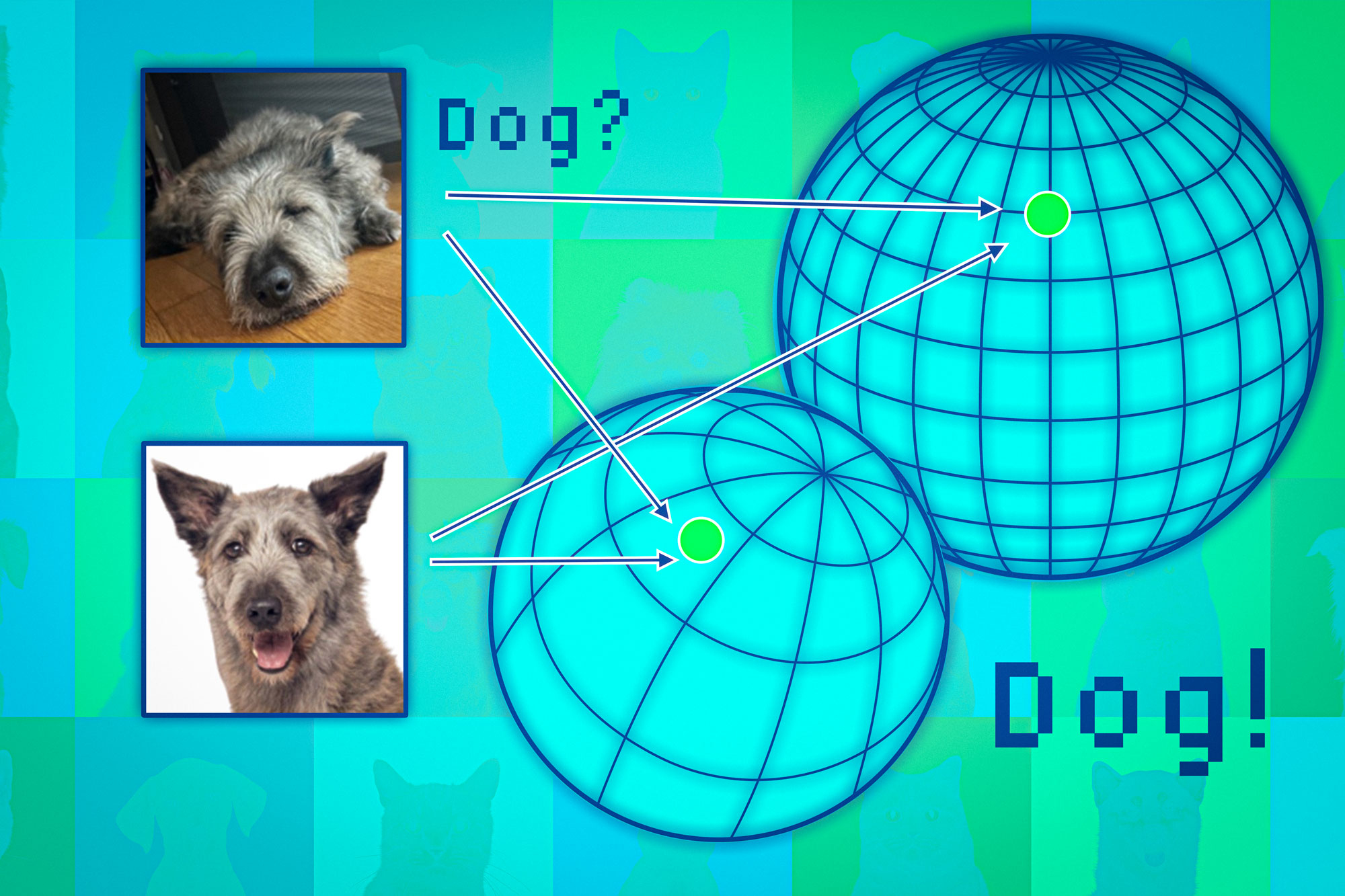
Grundlegende Modelle bilden Datenpunkte in einem sogenannten Darstellungsraum ab. Man kann sich diesen Raum als Kugel vorstellen. Jedes Modell bildet ähnliche Datenpunkte in demselben Teil seiner Kugel ab. Bilder von Katzen landen additionally an einer Stelle und Bilder von Hunden an einer anderen.
Allerdings würde jedes Modell die Tiere in seiner eigenen Sphäre anders abbilden. So könnten Katzen beispielsweise in der Nähe des Südpols einer Sphäre gruppiert sein, während ein anderes Modell sie irgendwo auf der Nordhalbkugel abbilden könnte.
Die Forscher verwenden die benachbarten Punkte wie Anker, um diese Kugeln auszurichten und so die Darstellungen vergleichbar zu machen. Wenn die Nachbarn eines Datenpunkts über mehrere Darstellungen hinweg konsistent sind, kann man von der Zuverlässigkeit der Modellausgabe für diesen Punkt überzeugt sein.
Als sie diesen Ansatz an einer Vielzahl von Klassifizierungsaufgaben testeten, stellten sie fest, dass er wesentlich konsistenter warfare als die Baselines. Außerdem wurde er nicht durch schwierige Testpunkte gestört, die bei anderen Methoden zum Scheitern führten.
Darüber hinaus kann ihr Ansatz verwendet werden, um die Zuverlässigkeit beliebiger Eingabedaten zu beurteilen. So könnte man beurteilen, wie intestine ein Modell für einen bestimmten Personentyp funktioniert, etwa für einen Patienten mit bestimmten Merkmalen.
„Selbst wenn die Leistung aller Modelle insgesamt durchschnittlich ist, bevorzugt man aus individueller Sicht das Modell, das für den Einzelnen am besten funktioniert“, sagt Wang.
Eine Einschränkung besteht jedoch darin, dass sie ein Ensemble von Basismodellen trainieren müssen, was rechenintensiv ist. In der Zukunft planen sie, effizientere Wege zu finden, um mehrere Modelle zu erstellen, vielleicht durch die Verwendung kleiner Störungen eines einzelnen Modells.
„Angesichts des aktuellen Developments, grundlegende Modelle für ihre Einbettungen zu verwenden, um verschiedene nachgelagerte Aufgaben zu unterstützen – von der Feinabstimmung bis zur durch Abruf erweiterten Generierung – wird das Thema der Quantifizierung von Unsicherheit auf Darstellungsebene zunehmend wichtiger, aber auch herausfordernder, da Einbettungen allein keine Grundlage haben. Entscheidend ist vielmehr, wie Einbettungen verschiedener Eingaben miteinander in Beziehung stehen, eine Idee, die diese Arbeit durch den vorgeschlagenen Nachbarschaftskonsistenz-Rating intestine erfasst“, sagt Marco Pavone, außerordentlicher Professor in der Abteilung für Luft- und Raumfahrt der Stanford College, der nicht an dieser Arbeit beteiligt warfare. „Dies ist ein vielversprechender Schritt in Richtung qualitativ hochwertiger Unsicherheitsquantifizierungen für Einbettungsmodelle, und ich bin gespannt auf zukünftige Erweiterungen, die ohne Modell-Ensemblierung funktionieren, um diesen Ansatz wirklich auf Modelle in der Größe von Grundlagen skalierbar zu machen.“
Diese Arbeit wird zum Teil vom MIT-IBM Watson AI Lab, MathWorks und Amazon finanziert.