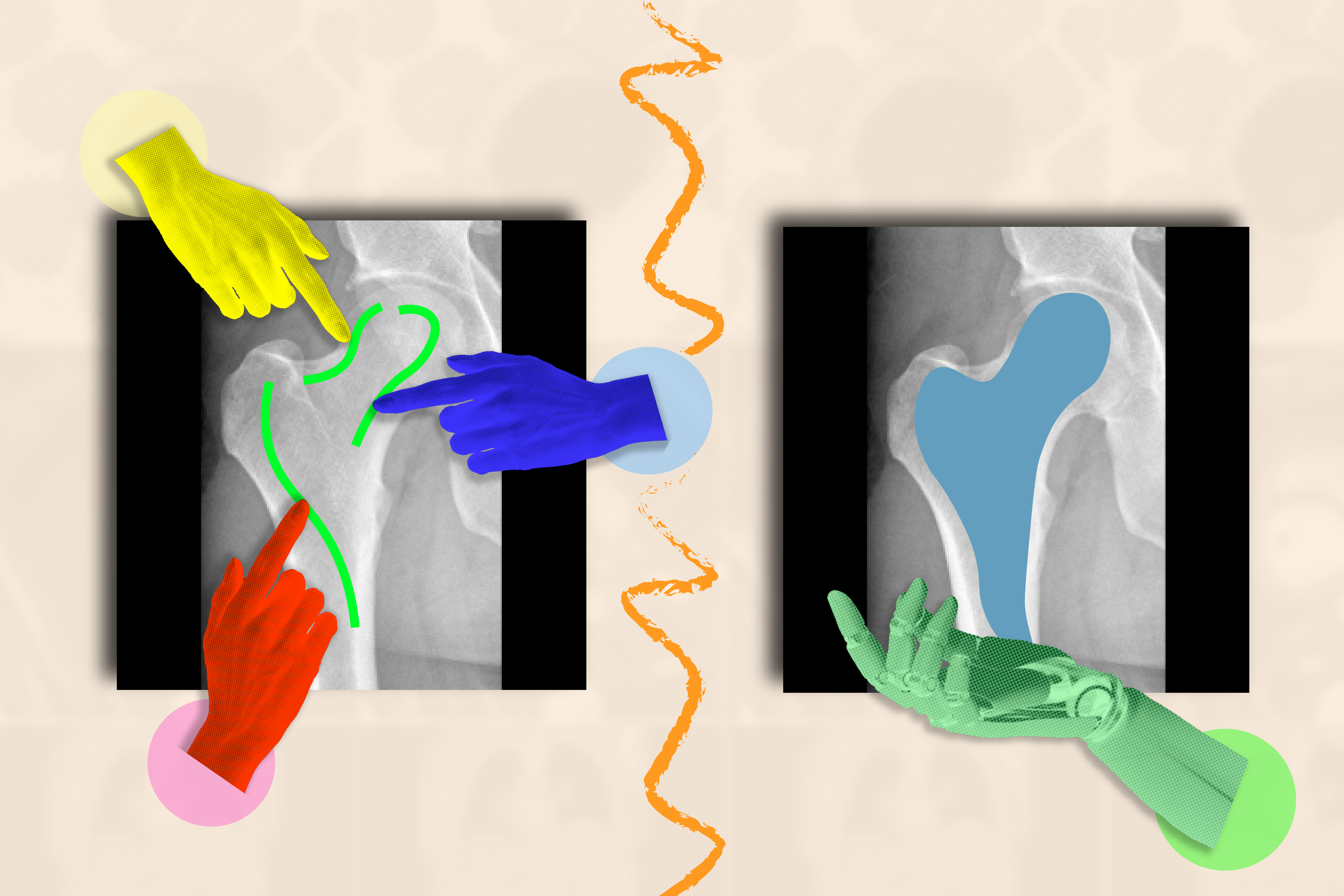
Für das ungeübte Auge erscheint ein medizinisches Bild wie ein MRT oder ein Röntgenbild wie eine trübe Ansammlung schwarz-weißer Flecken. Es kann schwierig sein zu erkennen, wo eine Struktur (wie ein Tumor) endet und eine andere beginnt.
Wenn KI-Systeme darauf trainiert sind, die Grenzen biologischer Strukturen zu erkennen, können sie Bereiche von Interesse segmentieren (oder abgrenzen), die Ärzte und biomedizinisches Private auf Krankheiten und andere Anomalien überwachen möchten. Anstatt kostbare Zeit damit zu verlieren, die Anatomie über viele Bilder hinweg manuell nachzuzeichnen, könnte ein künstlicher Assistent dies für sie tun.
Der Haken? Forscher und Kliniker müssen unzählige Bilder beschriften, um ihr KI-System zu trainieren, bevor es genau segmentieren kann. Sie müssten beispielsweise die Großhirnrinde in zahlreichen MRT-Scans kommentieren, um ein überwachtes Modell zu trainieren, das versteht, wie die Type der Hirnrinde in verschiedenen Gehirnen variieren kann.
Um diese mühsame Datenerfassung zu umgehen, haben Forscher des Pc Science and Synthetic Intelligence Laboratory (CSAIL) des MIT, des Massachusetts Common Hospital (MGH) und der Harvard Medical Faculty das interaktive „ScribblePrompt“-Framework: ein flexibles Instrument, mit dem sich jedes medizinische Bild schnell segmentieren lässt, sogar solche, die noch nicht bekannt sind.
Anstatt jedes Bild manuell von Menschen markieren zu lassen, simulierte das Crew, wie Benutzer über 50.000 Scans, darunter MRTs, Ultraschallbilder und Fotos, von Strukturen in Augen, Zellen, Gehirnen, Knochen, Haut und mehr kommentieren würden. Um all diese Scans zu beschriften, verwendete das Crew Algorithmen, um zu simulieren, wie Menschen auf verschiedene Bereiche in medizinischen Bildern kritzeln und klicken würden. Zusätzlich zu allgemein beschrifteten Bereichen verwendete das Crew auch Superpixel-Algorithmen, die Teile des Bildes mit ähnlichen Werten finden, um potenzielle neue Bereiche zu identifizieren, die für medizinische Forscher von Interesse sind, und ScribblePrompt zu trainieren, diese zu segmentieren. Diese synthetischen Daten bereiteten ScribblePrompt darauf vor, reale Segmentierungsanfragen von Benutzern zu verarbeiten.
„KI hat ein erhebliches Potenzial bei der Analyse von Bildern und anderen hochdimensionalen Daten, um Menschen zu helfen, Dinge produktiver zu erledigen“, sagt MIT-Doktorandin Hallee Wong SM ’22, die Hauptautorin eines neues Paper über ScribblePrompt und ein CSAIL-Associate. „Wir möchten die Bemühungen des medizinischen Personals durch ein interaktives System ergänzen, nicht ersetzen. ScribblePrompt ist ein einfaches Modell mit der Effizienz, Ärzten dabei zu helfen, sich auf die interessanteren Teile ihrer Analyse zu konzentrieren. Es ist schneller und genauer als vergleichbare interaktive Segmentierungsmethoden und reduziert die Annotationszeit beispielsweise im Vergleich zum Phase Something Mannequin (SAM)-Framework von Meta um 28 Prozent.“
Die Benutzeroberfläche von ScribblePrompt ist einfach: Benutzer können über den groben Bereich kritzeln, den sie segmentieren möchten, oder darauf klicken, und das Instrument hebt die gesamte Struktur oder den Hintergrund je nach Wunsch hervor. Sie können beispielsweise auf einzelne Venen in einem Netzhaut-(Augen-)Scan klicken. ScribblePrompt kann auch eine Struktur markieren, die einen Begrenzungsrahmen enthält.
Anschließend kann das Instrument auf Grundlage des Feedbacks des Benutzers Korrekturen vornehmen. Wenn Sie beispielsweise eine Niere in einem Ultraschallbild hervorheben möchten, können Sie einen Begrenzungsrahmen verwenden und dann zusätzliche Teile der Struktur einfügen, wenn ScribblePrompt Kanten übersehen hat. Wenn Sie Ihr Phase bearbeiten möchten, können Sie eine „damaging Skizze“ verwenden, um bestimmte Bereiche auszuschließen.
Diese selbstkorrigierenden, interaktiven Funktionen machten ScribblePrompt in einer Benutzerstudie zum bevorzugten Werkzeug der Neurobildgebungsforscher am MGH. 93,8 Prozent dieser Benutzer bevorzugten den MIT-Ansatz gegenüber der SAM-Baseline, da er seine Segmente als Reaktion auf Kritzelkorrekturen verbesserte. Bei klickbasierten Bearbeitungen bevorzugten 87,5 Prozent der medizinischen Forscher ScribblePrompt.
ScribblePrompt wurde anhand simulierter Kritzeleien und Klicks auf 54.000 Bildern aus 65 Datensätzen trainiert, darunter Scans von Augen, Brustkorb, Wirbelsäule, Zellen, Haut, Bauchmuskeln, Hals, Gehirn, Knochen, Zähnen und Läsionen. Das Modell machte sich mit 16 Arten medizinischer Bilder vertraut, darunter Mikroskope, CT-Scans, Röntgenaufnahmen, MRTs, Ultraschallbilder und Fotografien.
„Viele bestehende Methoden reagieren nicht intestine, wenn Benutzer über Bilder kritzeln, weil es schwierig ist, solche Interaktionen im Coaching zu simulieren. Für ScribblePrompt konnten wir unser Modell mithilfe unserer synthetischen Segmentierungsaufgaben dazu zwingen, auf unterschiedliche Eingaben zu achten“, sagt Wong. „Wir wollten ein im Wesentlichen grundlegendes Modell anhand vieler unterschiedlicher Daten trainieren, damit es sich auf neue Arten von Bildern und Aufgaben verallgemeinern lässt.“
Nachdem das Crew so viele Daten erfasst hatte, bewertete es ScribblePrompt anhand von 12 neuen Datensätzen. Obwohl diese Bilder noch nicht bekannt waren, übertraf es vier vorhandene Methoden, indem es effizienter segmentierte und genauere Vorhersagen über die genauen Bereiche lieferte, die die Benutzer hervorheben wollten.
„Die Segmentierung ist die häufigste Aufgabe der biomedizinischen Bildanalyse, die sowohl in der klinischen Routinepraxis als auch in der Forschung häufig durchgeführt wird. Dies macht sie zu einem sehr vielfältigen und entscheidenden Schritt mit großer Wirkung“, sagt der leitende Autor Adrian Dalca SM ’12, PhD ’16, CSAIL-Forscher und Assistenzprofessor am MGH und der Harvard Medical Faculty. „ScribblePrompt wurde sorgfältig entwickelt, um für Kliniker und Forscher praktisch nützlich zu sein und diesen Schritt daher wesentlich viel, viel schneller zu machen.“
„Die meisten Segmentierungsalgorithmen, die in der Bildanalyse und im maschinellen Lernen entwickelt wurden, basieren zumindest teilweise auf unserer Fähigkeit, Bilder manuell zu kommentieren“, sagt Bruce Fischl, Professor für Radiologie an der Harvard Medical Faculty und Neurowissenschaftler am MGH, der nicht an der Arbeit beteiligt battle. „Das Drawback ist bei der medizinischen Bildgebung, bei der unsere ‚Bilder‘ typischerweise 3D-Volumina sind, dramatisch schlimmer, da es für den Menschen weder evolutionär noch phänomenologisch einen Grund gibt, 3D-Bilder zu kommentieren. ScribblePrompt ermöglicht eine viel, viel schnellere und genauere manuelle Kommentierung, indem ein Netzwerk genau auf die Arten von Interaktionen trainiert wird, die ein Mensch beim manuellen Kommentieren normalerweise mit einem Bild hat. Das Ergebnis ist eine intuitive Benutzeroberfläche, die Kommentatoren eine natürliche Interaktion mit Bilddaten mit weitaus größerer Produktivität ermöglicht, als dies bisher möglich battle.“
Wong und Dalca haben das Papier zusammen mit zwei weiteren CSAIL-Mitgliedern verfasst: John Guttag, dem Dugald C. Jackson Professor für EECS am MIT und leitenden CSAIL-Forscher, und der MIT-Doktorandin Marianne Rakic SM ’22. Ihre Arbeit wurde teilweise von Quanta Pc Inc., dem Eric and Wendy Schmidt Middle am Broad Institute, der Wistron Corp. und dem Nationwide Institute of Biomedical Imaging and Bioengineering der Nationwide Institutes of Well being unterstützt, mit {Hardware}-Unterstützung vom Massachusetts Life Sciences Middle.
Die Arbeit von Wong und ihren Kollegen wird auf der European Convention on Pc Imaginative and prescient 2024 vorgestellt und wurde Anfang des Jahres auch als mündlicher Vortrag auf dem DCAMI-Workshop auf der Pc Imaginative and prescient and Sample Recognition Convention präsentiert. Sie wurden auf dem Workshop für die potenziellen klinischen Auswirkungen von ScribblePrompt mit dem Bench-to-Bedside Paper Award ausgezeichnet.