Was wäre, wenn Sie die langweiligen Datenanalyse überspringen und direkt zu den guten Dingen springen könnten – wie die Aufdeckung von Erkenntnissen? Der neue Knowledge Science Agent von Google Colab, der von Gemini AI betrieben wird, tut genau das, indem sie Aufgaben wie das Importieren von Bibliotheken, die Reinigung von Daten, das Ausführen von Explorationsdatenanalysen (EDA) und sogar das Generieren von Code für Sie erledigen. Dieser praktische KI -Assistent glättet den maschinellen Lernprozess und lässt sich auf das konzentrieren, was am wichtigsten ist, ohne sich in der sich wiederholenden Codierung festzuhalten. In diesem Artikel werden Sie in Google Colab das Beste daraus machen, mit einem einfachen Leitfaden, um Ihre Datenerforschung, Ihr Modellbau und Ihre Visualisierungen zu steigern – perfekt für Anfänger und erfahrene Datenprofis, und gleichzeitig die Teamarbeit in Cloud -Notebooks einfacher und effizienter machen.
Was ist ein Knowledge Science Agent?
Ein Knowledge Science Agent ist ein KI-betriebener Assistent, der die Datenanalyse vereinfacht, indem Aufgaben wie Datenvorverarbeitung automatisiert werden. Explorationsdatenanalyse (EDA)Characteristic Engineering und Modellentwicklung. In Google Colab fungiert der Knowledge Science Agent, der von Gemini AI betrieben wird, als intelligenter Assistent, der Bibliotheksinporte, Datensatzlade-, Visualisierung, Codegenerierung und Codeausführung automatisiert.
Anstatt die Umgebung manuell zu konfigurieren, können Benutzer ihre Analyseziele zusammen mit der Datendatei in einer einfachen Sprache definieren, und der Agent generiert ein Colab -Notizbuch und führt sie für sich selbst aus und verarbeitet auch Fehler effektiv.
Abgesehen von der Automatisierung verbessert der Gemini-betriebene Agent den Datenanalyseprozess, indem sie kontextbezogene Vorschläge, das Fehlerdebuggen und die Codeoptimierung unterstützt. Durch die Integration von KI in Colab-Notebooks reduziert der Knowledge Science Agent die Zeit, die für sich wiederholende Codierungsaufgaben aufgewendet werden, erheblich, sodass Benutzer sich darauf konzentrieren können, Erkenntnisse zu extrahieren, Modelle zu bauen und Entscheidungsprozesse zu verbessern.
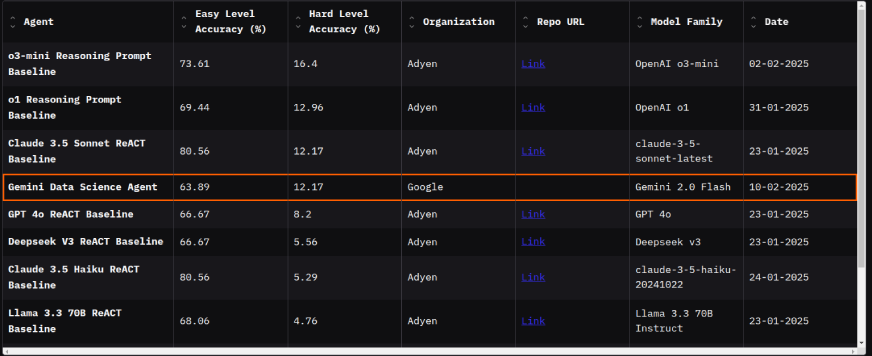
Benchmarks
Google Knowledge Science Agent hat auch auf dem 4. Platz auf dem Land gelandet DABStep: Knowledge Agent-Benchmark für mehrstufige Argumentation auf das Umarmungsfacevor React-Wirkstoffen basierend auf GPT 4O, Deepseek-V3, Claude 3.5 Haiku, Lama 3.3 70b.

Wie benutze ich Knowledge Science Agent in Google Colab?
Der Knowledge Science Agent in Google Colab, der von Gemini AI betrieben wird, vereinfacht den Datenanalyse -Workflow durch die Behandlung von Wiederholungsaufgaben und das automatische Generieren von Code. So können Sie es effektiv verwenden:
- Öffnen Sie ein neues Notizbuch: Starten Sie mit einem Leerzeichen für diesen Klick auf Google Colab Pocket bookund dann klicken Sie auf „neues Notizbuch“. Dadurch wird ein sauberer Arbeitsbereich für Ihre Analyse bereitgestellt.
- Laden Sie Ihre Daten hoch: Sobald das neue Notizbuch geöffnet wurde, drücken Sie in „Dateien mit Gemini analysieren“ und schweben Sie in der unteren rechten Ecke, um Ihren Datensatz in das Pocket book zu importieren, unabhängig davon, ob es sich um einen CSV (.csv) oder eine Excel -Datei (.xls) handelt.

- Definieren Sie Ihre Ziele: Geben Sie im Gemini -Seitenfeld die Artwork der Analyse oder des Modells an, die Sie benötigen. Sie können natürliche Sprachanforderungen wie verwenden „Developments visualisieren“, „Erstellen und Optimieren Sie ein Vorhersagemodell“, „Handlungswerte“ oder „Wählen Sie die beste statistische Technik“. Der Agent versteht Ihre Anfrage und passt den Workflow entsprechend an.
- Lassen Sie den Agenten die Arbeit erledigen: Sobald Sie Ihre Ziele angegeben haben, generiert der Knowledge Science Agent den erforderlichen Code, importiert relevante Bibliotheken und führt die erforderliche Analyse aus. Innerhalb Momente haben Sie ein voll funktionsfähiges Colab -Notizbuch zur weiteren Erkundung und Verfeinerung.
Dieser KI-betriebene Assistent spart nicht nur Zeit, sondern gewährleistet auch einen strukturierteren und effizienteren Datenflow für Datenwissenschaften, was ihn sowohl für Anfänger als auch für erfahrene Praktiker zu einem wertvollen Instrument macht.
Gemini Knowledge Science Agent in Aktion
Jetzt werden wir drei wichtige Aufgaben untersuchen, bei denen der Knowledge Science Agent die Effizienz erheblich verbessern kann:
- Datenanalyse und Visualisierung
- Modellgebäude
- Erstellen eines Mehrfachsystems mit Crewai oder Autogen.
Durch die Nutzung seiner Automatisierungsfunktionen können wir diese Prozesse optimieren, die manuellen Anstrengungen reduzieren und sich mehr darauf konzentrieren, wertvolle Erkenntnisse abzuleiten. Lassen Sie uns Schritt für Schritt in jede Aufgabe eintauchen.
Aufgabe 1: Automatisierte Datenanalyse – Manipulation und Visualisierung
Diese Aufgabe optimiert Datenmanipulation und Visualisierung, sodass Benutzer Datensätze mühelos ohne umfangreiche Codierung analysieren können. Der Knowledge Science Agent automatisiert Prozesse wie Datenreinigung, Transformation und Zusammenfassung und generiert gleichzeitig Diagramme und Diagramme, um bessere Einblicke zu erhalten. Durch die Reduzierung des manuellen Aufwands können Benutzer sich darauf konzentrieren, wertvolle Muster und Developments aus ihren Daten zu extrahieren.
Immediate: „Helfen Sie mir bei der Datenanalyse für diesen Datensatz. Dies umfasst Datenmanipulation und Datenvisualisierung.“
Antwort von Knowledge Science Agent:
Erste Antwort:

Antwort, nachdem Sie auf „Plan ausführen“ geklickt haben:
Analyse:
Der Knowledge Science Agent automatisierte Datenanalyse, Lade-, Reinigungs-, Erkundungs- und Visualisierungsprüfungsanalyse mit minimalem manuellem Aufwand. Es verarbeitete den Datensatz „Diabetes_reced.csv“ und identifizierte und behandelte Probleme wie Zero -Werte in ‚Skinthickness‘, ‚Insulin‘ und ‚BMI‘, um die Datenintegrität zu gewährleisten. Durch Skalierung numerischer Merkmale und Analyse von Beziehungen zur Zielvariablen („Ergebnis“) lieferte es wertvolle Erkenntnisse. Die automatisierten Visualisierungen, einschließlich Diagramme und Heatmaps, verbesserte die Interpretierbarkeit, während die Zusammenfassung und die Q & A -Funktion es den Benutzern ermöglichten, ihre Analyse zu verfeinern. Insgesamt optimierte der Agent den Workflow und verbessert die Effizienz, die Genauigkeit und die datengesteuerte Entscheidungsfindung.
Aufgabe 2: automatisierte Modellbewertung und Optimierung
Diese Aufgabe vereinfacht die Modellbewertung und -optimierung und ermöglicht es den Benutzern, die Modellleistung effizient zu bewerten und zu verbessern. Der Knowledge Science Agent automatisiert wichtige Prozesse wie Hyperparameter-Tuning, Kreuzvalidierung und Leistungsbenchmarking, um eine optimale Modellauswahl zu gewährleisten. Durch die Reduzierung des manuellen Aufwands können Benutzer sich auf die Interpretation der Ergebnisse und auf fundierte, datengesteuerte Entscheidungen konzentrieren.
Immediate: „Verwenden Sie nun 2 ML -Algorithmen und überprüfen Sie deren Bewertung auf verschiedenen Metriken“
Notiz: Diese Eingabeaufforderung ist ein Comply with -up aus der obigen Aufgabe.
Antwort von Knowledge Science Agent:
Erste Antwort:

Antwort, nachdem Sie auf „Plan ausführen“ geklickt haben
Analyse:
Der Knowledge Science Agent wurde die Modellbewertung und -optimierung erleichtert, indem wichtige Schritte wie das Aufteilen von Daten, Trainingsmodellen, Testleistung und Feinabstimmungseinstellungen automatisiert wurden. Es unterteilte zunächst den vorverarbeiteten Diabetes-Datensatz in Trainings- und Testsätze für einen strukturierten Ansatz. Dann trainierte es sowohl logistische Regression als auch Zufällige WaldmodelleVergleich ihrer Leistung mit relevanten Metriken. Der Agent optimierte die Modelle auch, indem er seine Einstellungen anpasste, um die Genauigkeit zu verbessern. Schließlich half die Zusammenfassung und die Q & A -Funktionen den Benutzern, die Ergebnisse zu verstehen und ihren Ansatz zu verfeinern. Diese Automatisierung sparte Zeit, reduzierte manuelle Anstrengungen und sorgte für eine bessere Modellauswahl und Entscheidungsfindung.
Aufgabe 3: Erstellen von Multiagent -Systemen
Diese Aufgabe konzentriert sich auf den Aufbau eines Multi-Agent-Programs, das Echtzeit-Updates zu wichtigen Sportveranstaltungen bietet. Unter Verwendung von Frameworks wie Autogen oder Crewai kann das System Daten aus verschiedenen Quellen aggregieren, relevante Informationen filtern und kurze Zusammenfassungen liefern.
Immediate: „Ich möchte ein Multi-Agent-System aufbauen, das auf die aktuellen Hauptveranstaltungen in der Sportwelt hinweist, die Sie dafür entweder Autogen oder Crewai verwenden können, und bitte auch die Aufgabe ausführen.“
Antwort durch Knowledge Science Agent

Analyse:
Der Knowledge Science Agent hatte Probleme mit dieser Aufgabe, da sie mit Datensätzen und nicht in Echtzeitdaten gearbeitet hat. Das Erstellen eines Multi-Agent-Programs benötigt Dwell-Daten, nicht nur statische Dateien, sodass der Agent dies nicht selbst tun konnte. Stattdessen gab es einen vorgefertigten Code-Snippet, den Benutzer ausführen und sich selbst testen müssen. Dies zeigt eine klare Begrenzung – es ist intestine in der Datenanalyse, Modelltraining und zur Behandlung strukturierter Daten, aber es ist nicht großartig bei Dwell -Daten, APIs oder Gebäudesystemen, die selbst laufen. Der Code, den es gibt, ist ein hilfreicher Begin, aber Benutzer müssen ihn weiterhin ausführen und alle Probleme manuell beheben.
Schlüsselanwendungen des Knowledge Science Brokers
- Automatisierte Datenverarbeitung: Reinigt, transformiert und visualisiert strukturierte Datensätze (CSV/XLS), sodass Benutzer Einblicke mit minimaler Codierungsaufwand erhalten können.
- Stimmungsanalyse zu Textdaten: Verarbeitet textbasierte Datensätze, die in CSV gespeichert sind, wendet NLP-Techniken an und klassifiziert Gefühle mit ML-Modellen.
- Deep -Studying -Modellentwicklung: Nahe Integration in Tensorflow und Pytorch, was es einfacher macht, Modelle wie Anns und LSTMs zu bauen, zu trainieren und zu feinstimmen.
- Automatisierte Fehlerbehandlung: Identifiziert und löst Fehler während der Ausführung, vereinfachte die Verfeinerung und Debuggen des Modells.
- Strukturierter Workflow für ML -Projekte: Bietet einen Schritt-für-Schritt-Ansatz für die Datenvorverarbeitung, das Modelltraining, die Bewertung und die Optimierung, um die Effizienz in ML-Pipelines zu gewährleisten.
Zukünftige Implikationen des Knowledge Science Brokers
Während sich der Knowledge Science Agent in der Behandlung strukturierter Datensätze auszeichnet, schränkt die Unfähigkeit, unstrukturierte Formate wie TXT, PDF, Bilder und JSON zu verarbeiten, den Anwendungsbereich ein. Um es für generative KI -Aufgaben besser geeignet zu machen, könnten zukünftige Verbesserungen umfassen:
- Verbesserte Textverarbeitung: Direkte Unterstützung für TXT und JSON zur Erweiterung von NLP- und AI-gesteuerten Textanalyse.
- Verständnis des Dokuments: Fähigkeit, PDFs für Datenextraktion, Zusammenfassung und KI-basierte Erkenntnisse zu verarbeiten.
- Bilddatenhandhabung: Integration von Bildformaten, um Laptop -Imaginative and prescient -Aufgaben wie Objekterkennung und Bildklassifizierung zu ermöglichen.
- API- und Echtzeitdatenverarbeitung: Fähigkeit, Echtzeitdaten von APIs abzurufen und zu verarbeiten, was es für dynamische und lebende KI-Anwendungen nützlich macht.
Durch die Einbeziehung dieser Merkmale könnte sich der Knowledge Science Agent zu einem umfassenden KI-betriebenen Assistenten entwickeln und die Lücke zwischen strukturierter und unstrukturierter Datenverarbeitung überbrücken und gleichzeitig seine Rolle bei generativen kI-gesteuerten Workflows erweitern.
Abschluss
Der Knowledge Science Agent in Google Colab ist ein KI-angetanter Helfer, der die Datenanalyse, das Modellaufbau und die Optimierung erleichtert. Es eignet sich hervorragend mit strukturierten Daten wie CSV- oder XLS-Dateien und bietet Ihnen einen klaren Schritt-für-Schritt-Prozess. Es kann sogar Fehler für Sie beheben. Es funktioniert intestine mit Tensorflow und PytorchEs ist einfacher, Dinge wie neuronale Netzwerke oder LSTMs zu bauen. Aber es kämpft mit unstrukturierten Daten wie Textdateien, PDFs, JSON oder Bildern, die das, was sie können, einschränken. Wenn es diese in Zukunft umgehen könnte und Dokumente verstehen und mit Echtzeitdaten arbeiten könnte, wäre es eine noch größere Hilfe für Datenwissenschaftler und KI-Forscher.
Häufig gestellte Fragen
A. Der Knowledge Science Agent ist ein KI-betriebener Assistent in Google Colab, der die Datenvorverarbeitung, Visualisierung, Modellbildung und Optimierung automatisiert und es den Benutzern ermöglicht, sich auf Erkenntnisse zu konzentrieren, anstatt umfangreiche Code zu schreiben.
A. Es funktioniert derzeit intestine mit strukturierten Datenformaten wie CSV und XLS, kämpft jedoch mit TXT-, PDF-, JSON- und Bildformaten.
A. Ja, es unterstützt TensorFlow und Pytorch, sodass Benutzer Modelle wie Anns und LSTMs erstellen, trainieren und optimieren können.
A. Ja, es identifiziert und behebt bestimmte Fehler während der Ausführung, wodurch das Debuggen für Benutzer erleichtert wird.
A. Zukünftige Updates können die Unterstützung für unstrukturierte Datenformate, die Verarbeitung von Dokumenten, die Bildanalyse und die Echtzeitdatenintegration umfassen, wodurch die Rolle bei generativen KI-Anwendungen verbessert wird.
Hallo! Ich bin Vipin, ein leidenschaftlicher Knowledge Science und maschinelles Lernen, der eine starke Grundlage für die Datenanalyse, Algorithmen und Programmierung maschinelles Lernens und Programmierung hat. Ich habe praktische Erfahrungen beim Aufbau von Modellen, beim Verwalten unordentlicher Daten und die Lösung realer Probleme. Mein Ziel ist es, datengesteuerte Erkenntnisse anzuwenden, um praktische Lösungen zu erstellen, die Ergebnisse erzielen. Ich bin bestrebt, meine Fähigkeiten in einer kollaborativen Umgebung beizutragen und gleichzeitig in den Bereichen Datenwissenschaft, maschinelles Lernen und NLP zu lernen und zu wachsen.