
Das Considering Machines Lab ist umgezogen Tinker-Trainings-API in die allgemeine Verfügbarkeit gebracht und drei Hauptfunktionen hinzugefügt: Unterstützung für das Kimi K2 Considering-Argumentationsmodell, OpenAI-kompatibles Sampling und Bildeingabe über Qwen3-VL-Imaginative and prescient-Sprachmodelle. Für KI-Ingenieure wird Tinker dadurch zu einer praktischen Möglichkeit, Grenzmodelle zu verfeinern, ohne eine verteilte Trainingsinfrastruktur aufzubauen.
Was macht Tinker eigentlich?
Tinker ist eine Trainings-API, die sich auf die Feinabstimmung großer Sprachmodelle konzentriert und den Aufwand des verteilten Trainings verbirgt. Sie schreiben eine einfache Python-Schleife, die auf einer reinen CPU-Maschine ausgeführt wird. Sie definieren die Daten- oder RL-Umgebung, den Verlust und die Trainingslogik. Der Tinker-Dienst ordnet diese Schleife einem Cluster von GPUs zu und führt genau die von Ihnen angegebene Berechnung aus.
Die API stellt einen kleinen Satz von Grundelementen bereit, z forward_backward um Steigungen zu berechnen, optim_step um Gewichte zu aktualisieren, pattern zum Generieren von Ausgaben und Funktionen zum Speichern und Laden des Standing. Dadurch bleibt die Trainingslogik explizit für Personen, die überwachtes Lernen, verstärkendes Lernen oder Präferenzoptimierung implementieren möchten, aber keine GPU-Ausfälle und Zeitplanung verwalten möchten.
Tinker verwendet für alle unterstützten Modelle eine Low-Rank-Adaption (LoRA) anstelle einer vollständigen Feinabstimmung. LoRA trainiert kleine Adaptermatrizen auf eingefrorenen Basisgewichten, was den Speicher reduziert und es praktisch macht, wiederholte Experimente mit einer großen Mischung von Expertenmodellen im selben Cluster durchzuführen.
Allgemeine Verfügbarkeit und Kimi K2 Considering
Die wichtigste Änderung im Replace vom Dezember 2025 besteht darin, dass Tinker keine Warteliste mehr hat. Jeder kann sich anmelden, die aktuelle Modellpalette und Preise einsehen und Kochbuchbeispiele direkt ausprobieren.
Auf der Modellseite können Benutzer nun Feinabstimmungen vornehmen moonshotai/Kimi-K2-Considering auf Tinker. Kimi K2 Considering ist ein Argumentationsmodell mit etwa 1 Billion Gesamtparametern in einer Mischung aus Expertenarchitektur. Es ist für lange Gedankengänge und starken Werkzeugeinsatz konzipiert und derzeit das größte Modell im Tinker-Katalog.
In der Tinker-Modellreihe erscheint Kimi K2 Considering als Reasoning MoE-Modell, neben Qwen3 Dense und Combine-of-Professional-Varianten, Modellen der Llama-3-Technology und DeepSeek-V3.1. Reasoning-Modelle produzieren immer interne Gedankenketten vor der sichtbaren Antwort, während Instruktionsmodelle sich auf Latenz und direkte Antworten konzentrieren.
OpenAI-kompatibles Sampling während des Trainings
Tinker verfügte bereits über eine native Sampling-Schnittstelle SamplingClient. Das typische Inferenzmuster bildet a ModelInput von Token-IDs, Pässen SamplingParamsund Anrufe pattern um eine Zukunft zu bekommen, die sich in Ausgaben auflöst
Die neue Model fügt einen zweiten Pfad hinzu, der die OpenAI-Abschlussschnittstelle widerspiegelt. Auf einen Modellprüfpunkt auf Tinker kann über einen URI wie folgt verwiesen werden:
response = openai_client.completions.create(
mannequin="tinker://0034d8c9-0a88-52a9-b2b7-bce7cb1e6fef:practice:0/sampler_weights/000080",
immediate="The capital of France is",
max_tokens=20,
temperature=0.0,
cease=("n"),
)Imaginative and prescient-Eingabe mit Qwen3-VL auf Tinker
Die zweite Hauptfunktion ist die Bildeingabe. Tinker stellt jetzt zwei Qwen3-VL-Imaginative and prescient-Sprachmodelle vor: Qwen/Qwen3-VL-30B-A3B-Instruct Und Qwen/Qwen3-VL-235B-A22B-Instruct. Sie sind in der Tinker-Modellreihe als Imaginative and prescient MoE-Modelle aufgeführt und stehen für Schulung und Probenahme über dieselbe API-Oberfläche zur Verfügung.
Um ein Bild in ein Modell zu senden, erstellen Sie ein ModelInput das verschachtelt ein ImageChunk mit Textblöcken. Der Forschungsblog verwendet das folgende Minimalbeispiel:
model_input = tinker.ModelInput(chunks=(
tinker.varieties.ImageChunk(information=image_data, format="png"),
tinker.varieties.EncodedTextChunk(tokens=tokenizer.encode("What is that this?")),
))Hier image_data ist Rohbytes und format identifiziert beispielsweise die Kodierung png oder jpeg. Sie können dieselbe Darstellung für überwachtes Lernen und für die RL-Feinabstimmung verwenden, wodurch multimodale Pipelines auf API-Ebene konsistent bleiben. Imaginative and prescient-Eingaben werden im LoRA-Trainingssetup von Tinker vollständig unterstützt.
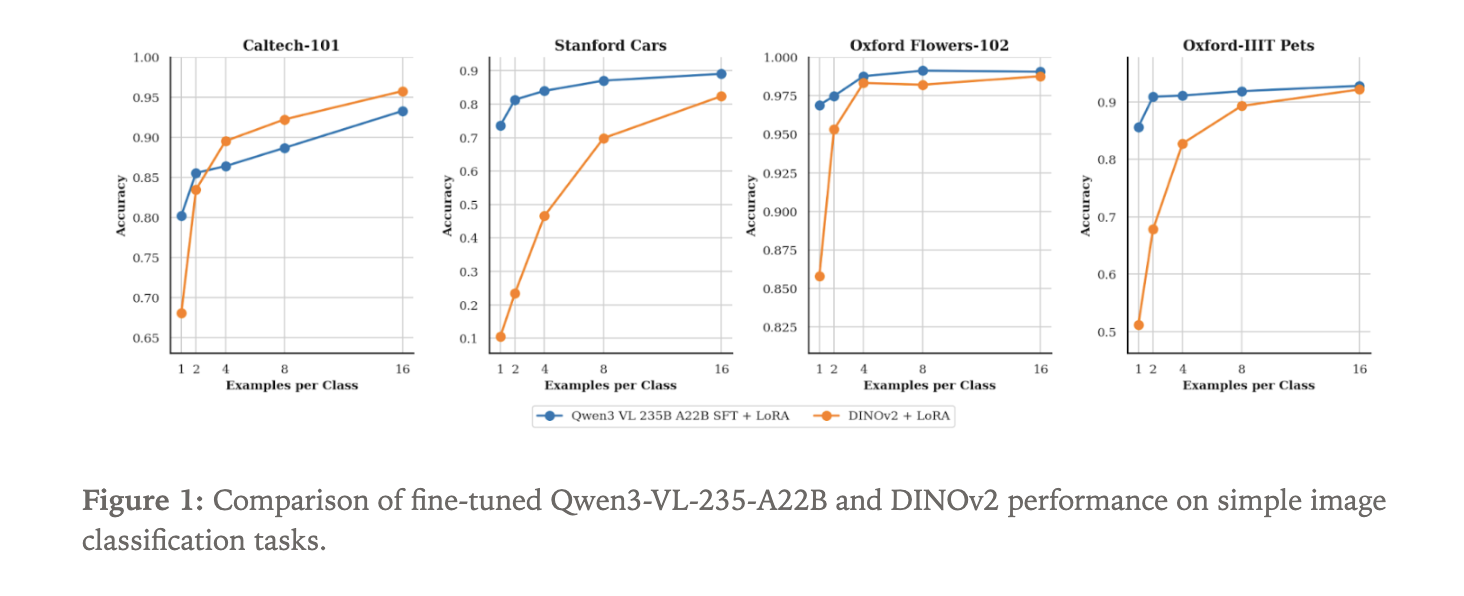
Qwen3-VL versus DINOv2 zur Bildklassifizierung
Um zu zeigen, was der neue Imaginative and prescient-Pfad bewirken kann, hat das Tinker-Staff eine Feinabstimmung vorgenommen Qwen3-VL-235B-A22B-Instruct als Bildklassifikator. Sie verwendeten 4 Standarddatensätze:
- Caltech 101
- Stanford-Autos
- Oxford-Blumen
- Oxford Haustiere
Da es sich bei Qwen3-VL um ein Sprachmodell mit visueller Eingabe handelt, wird die Klassifizierung als Textgenerierung bezeichnet. Das Modell empfängt ein Bild und generiert den Klassennamen als Textsequenz.
Als Foundation haben sie ein DINOv2-Basismodell verfeinert. DINOv2 ist ein selbstüberwachter Imaginative and prescient-Transformer, der Bilder in Einbettungen kodiert und häufig als Rückgrat für Imaginative and prescient-Aufgaben verwendet wird. Für dieses Experiment wird ein Klassifizierungskopf über DINOv2 angebracht, um eine Verteilung über die N Labels in jedem Datensatz vorherzusagen.
Sowohl Qwen3-VL-235B-A22B-Instruct als auch DINOv2 Base werden mit LoRA-Adaptern in Tinker trainiert. Der Fokus liegt auf der Dateneffizienz. Das Experiment durchsucht die Anzahl der markierten Beispiele professional Klasse, beginnend mit nur 1 Probe professional Klasse und zunehmend. Für jede Einstellung misst das Staff die Klassifizierungsgenauigkeit.
Wichtige Erkenntnisse
- Tinker ist jetzt allgemein verfügbar, sodass sich jeder anmelden und Open-Weight-LLMs über eine Python-Trainingsschleife optimieren kann, während Tinker das verteilte Trainings-Backend verwaltet.
- Die Plattform unterstützt Kimi K2 Considering, ein 1 Billion Parameter umfassendes Experten-Argumentationsmodell von Moonshot AI, und stellt es als fein abstimmbares Argumentationsmodell in der Tinker-Reihe zur Verfügung.
- Tinker fügt eine OpenAI-kompatible Inferenzschnittstelle hinzu, mit der Sie mithilfe von a Stichproben aus Trainingskontrollpunkten erstellen können
tinker://…Modell-URI über standardmäßige OpenAI-Purchasers und -Instruments. - Die visuelle Eingabe wird durch die Qwen3-VL-Modelle Qwen3-VL 30B und Qwen3-VL 235B ermöglicht, sodass Entwickler multimodale Trainingspipelines erstellen können, die kombiniert werden
ImageChunkEingaben mit Textual content über dieselbe LoRA-basierte API. - Considering Machines zeigt, dass Qwen3-VL 235B, fein abgestimmt auf Tinker, bei Datensätzen wie Caltech 101, Stanford Vehicles, Oxford Flowers und Oxford Pets eine stärkere Bildklassifizierungsleistung bei wenigen Aufnahmen erzielt als eine DINOv2-Basislinie, was die Dateneffizienz großer Imaginative and prescient-Sprachmodelle hervorhebt.
Asif Razzaq ist CEO von Marktechpost Media Inc.. Als visionärer Unternehmer und Ingenieur setzt sich Asif dafür ein, das Potenzial der künstlichen Intelligenz für das soziale Wohl zu nutzen. Sein jüngstes Unterfangen ist die Einführung einer Medienplattform für künstliche Intelligenz, Marktechpost, die sich durch eine ausführliche Berichterstattung über maschinelles Lernen und Deep-Studying-Nachrichten auszeichnet, die sowohl technisch fundiert als auch für ein breites Publikum leicht verständlich ist. Die Plattform verfügt über mehr als 2 Millionen monatliche Aufrufe, was ihre Beliebtheit beim Publikum verdeutlicht.
