DeepSeek-Forscher versuchen, ein konkretes Drawback beim Coaching großer Sprachmodelle zu lösen. Restverbindungen machten sehr tiefe Netzwerke trainierbar, Hyperverbindungen erweiterten diesen Reststrom und das Coaching wurde dann im großen Maßstab instabil. Die neue Methode mHC, Manifold Constrained Hyper Connections, behält die reichhaltigere Topologie von Hyperverbindungen bei, sperrt aber das Mischverhalten auf eine wohldefinierte Mannigfaltigkeit, sodass Signale in sehr tiefen Stapeln numerisch stabil bleiben.
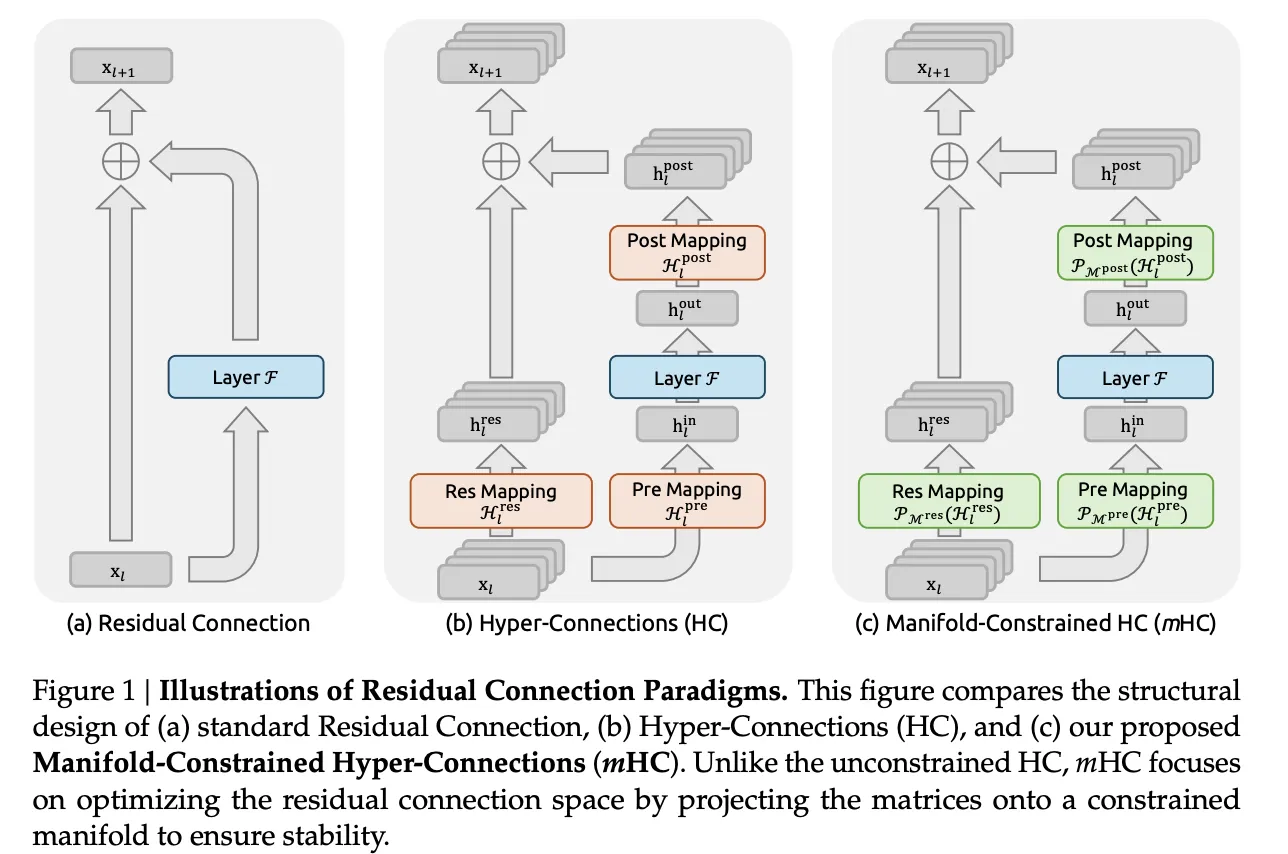
Von Residualverbindungen zu Hyperverbindungen
Customary-Restverbindungen, wie in ResNets und Transformers, verbreiten Aktivierungen mit xl+1=xl+F(xl,Wl)
Der Identitätspfad behält die Größe bei und sorgt dafür, dass Farbverläufe auch dann nutzbar bleiben, wenn Sie viele Ebenen stapeln.
Hyperverbindungen verallgemeinern diese Struktur. Anstelle eines einzelnen Restvektors der Größe C behält das Modell einen n-Stream-Puffer 𝑥𝑙∈𝑅𝑛×𝐶. Drei erlernte Zuordnungen steuern, wie jede Schicht diesen Puffer liest und schreibt:
- Hlvor wählt eine Mischung aus Streams als Layer-Eingabe aus
- F ist die übliche Aufmerksamkeits- oder Feed-Ahead-Unterschicht
- HlPut up schreibt Ergebnisse zurück in den n-Stream-Puffer
- Hlres∈Rn×n mischt Streams zwischen Ebenen
Das Replace hat das Formular
Xl+1=HlresXl+HlPut up⊤F(HlvorXl,Wl)
Wenn n auf 4 gesetzt ist, erhöht dieses Design die Ausdruckskraft, ohne dass die Gleitkommakosten stark steigen, weshalb Hyperverbindungen die Downstream-Leistung in Sprachmodellen verbessern.
Warum Hyperverbindungen instabil werden
Das Drawback tritt auf, wenn man das Produkt der Restmischer über viele Schichten hinweg betrachtet. In einem 27B-Combine-of-Experten-Modell untersucht DeepSeek die zusammengesetzte Kartierung
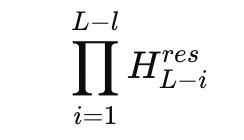
und definiert eine Amax-Verstärkungsgröße basierend auf den maximalen Zeilen- und Spaltensummen. Diese Metrik misst die Verstärkung im ungünstigsten Fall im Vorwärts- und Rückwärtssignalpfad. Im Hyperverbindungsmodell erreicht dieser Gewinn Spitzen um 3000, weit entfernt vom Idealwert 1, den man von einem stabilen Restpfad erwartet.
Dies bedeutet, dass kleine Abweichungen professional Schicht zu sehr großen Verstärkungsfaktoren über die Tiefe führen. Trainingsprotokolle zeigen Verlustspitzen und instabile Gradientennormen im Vergleich zu einem Foundation-Residuenmodell. Gleichzeitig erhöht die Beibehaltung eines Multi-Stream-Puffers den Speicherverkehr für jedes Token, was die naive Skalierung von Hyperverbindungen für die Produktion großer Sprachmodelle unattraktiv macht.
Vielfältig eingeschränkte Hyperverbindungen
mHC behält die Multi-Stream-Restidee bei, schränkt aber den gefährlichen Teil ein. Die Restmischungsmatrix Hlres lebt nicht mehr im vollen n-mal-n-Raum. Stattdessen wird es auf die Mannigfaltigkeit doppelt stochastischer Matrizen projiziert, auch Birkhoff-Polytop genannt. In dieser Menge sind alle Einträge nicht negativ und jede Zeile und jede Spalte ergibt in der Summe 1.
Das DeepSeek-Crew erzwingt diese Einschränkung mit dem klassischen Sinkhorn-Knopp-Algorithmus von 1967, der Zeilen- und Spaltennormalisierungen abwechselt, um eine doppelt stochastische Matrix anzunähern. Das Forschungsteam verwendet während des Trainings 20 Iterationen professional Schicht, was ausreicht, um die Zuordnung nahe an der Zielmannigfaltigkeit zu halten und gleichzeitig die Kosten überschaubar zu halten.
Unter diesen Einschränkungen hat Hlresxl verhält sich wie eine konvexe Kombination von Restströmen. Die gesamte Merkmalsmasse bleibt erhalten und die Norm ist streng reguliert, wodurch das explosionsartige Wachstum, das bei einfachen Hyperverbindungen auftritt, eliminiert wird. Das Forschungsteam parametrisiert außerdem Eingabe- und Ausgabezuordnungen so, dass die Koeffizienten nicht negativ sind, was eine Auslöschung zwischen Streams vermeidet und die Interpretation als Mittelung klar hält.
Mit mHC bleibt die zusammengesetzte Amax Acquire Magnitude begrenzt und erreicht beim 27B-Modell einen Spitzenwert von etwa 1,6, verglichen mit Spitzenwerten nahe 3000 bei der uneingeschränkten Variante. Das entspricht einer Reduzierung um etwa drei Größenordnungen bei der Verstärkung im ungünstigsten Fall und ist eher auf eine direkte mathematische Einschränkung als auf abgestimmte Tips zurückzuführen.
Systemarbeit und Schulungsaufwand
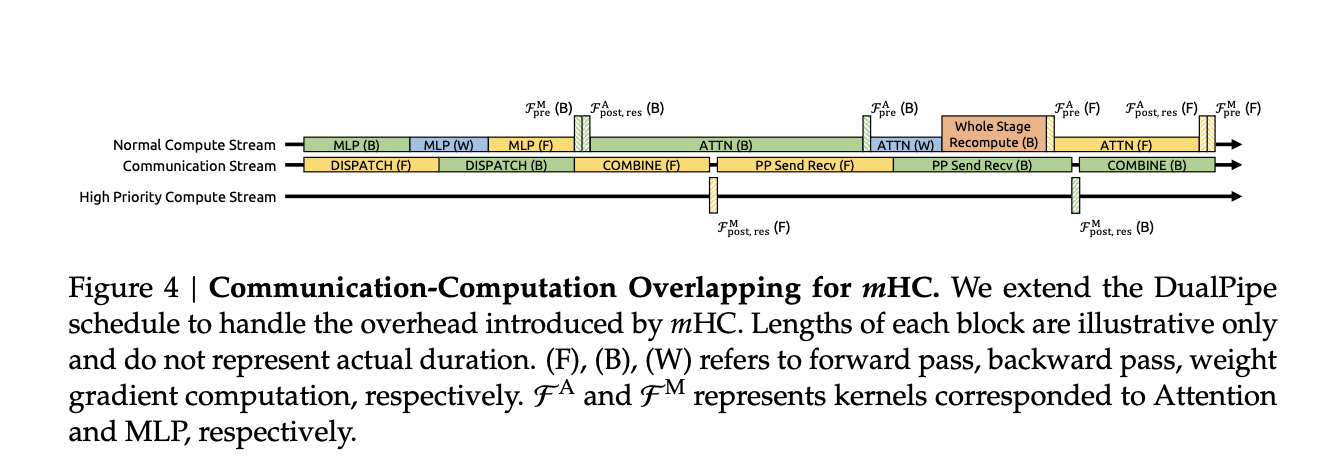
Die Beschränkung jedes Restmischers durch Iterationen im Sinkhorn-Stil erhöht die Kosten auf dem Papier. Das Forschungsteam begegnet diesem Drawback mit mehreren Systemoptionen:
- Fusionierte Kernel kombinieren RMSNorm, Projektionen und Gating für die mHC-Zuordnungen, sodass der Speicherverkehr gering bleibt
- Neuberechnungsbasiertes Aktivierungs-Checkpointing tauscht Rechenleistung für den Arbeitsspeicher aus, indem mHC-Aktivierungen während des Backprops für Layer-Blöcke neu berechnet werden
- Durch die Integration mit einem DualPipe-ähnlichen Pipeline-Zeitplan überlappen sich Kommunikation und Neuberechnung, sodass zusätzliche Arbeit die Trainingspipeline nicht blockiert
Bei umfangreichen internen Trainingsläufen erhöht mHC mit einer Expansionsrate n von 4 den Trainingszeitaufwand im Vergleich zur Basisarchitektur um etwa 6,7 Prozent. In dieser Zahl sind sowohl die zusätzliche Rechenleistung von Sinkhorn Knopp als auch die Infrastrukturoptimierungen bereits enthalten.
Empirische Ergebnisse
Das Forschungsteam trainiert 3B-, 9B- und 27B-Mischungen von Expertenmodellen und bewertet sie anhand einer Customary-Sprachmodell-Benchmark-Suite, einschließlich Aufgaben wie BBH, DROP, GSM8K, HellaSwag, MMLU, PIQA und TriviaQA.
Für das 27B-Modell zeigen die gemeldeten Zahlen zu einer Teilmenge von Aufgaben das Muster deutlich:
- Basislinie: BBH 43,8, DROP F1 47,0
- Mit Hyperverbindungen: BBH 48,9, DROP 51,6
- Mit mHC: BBH 51,0, DROP 53,9
Hyperverbindungen bieten additionally bereits einen Vorteil gegenüber dem grundlegenden Restdesign, und vielfältig eingeschränkte Hyperverbindungen steigern die Leistung weiter und stellen gleichzeitig die Stabilität wieder her. Ähnliche Developments treten bei anderen Benchmarks und über Modellgrößen hinweg auf, und Skalierungskurven deuten darauf hin, dass der Vorteil über alle Rechenbudgets und den gesamten Trainingsverlauf hinweg bestehen bleibt und nicht nur bei der Konvergenz.
Wichtige Erkenntnisse
- mHC stabilisiert verbreiterte Restströme: mHC, Manifold Constrained Hyper Connections, erweitert den Restweg in 4 interagierende Ströme wie HC, beschränkt aber die Restmischungsmatrizen auf eine Mannigfaltigkeit doppelt stochastischer Matrizen, sodass die Ausbreitung über große Entfernungen normkontrolliert bleibt und nicht explodiert.
- Der Explosionsgewinn wird von ≈3000 auf ≈1,6 reduziert: Bei einem 27B-MoE-Modell erreicht die Amax-Verstärkungsgröße der zusammengesetzten Restkartierung bei uneingeschränktem HC einen Spitzenwert von etwa 3000, während mHC diese Metrik auf etwa 1,6 beschränkt, wodurch das explodierende Reststromverhalten, das zuvor das Coaching unterbrochen hat, beseitigt wird.
- Sinkhorn Knopp erzwingt eine doppelt stochastische Restmischung: Jede verbleibende Mischmatrix wird mit etwa 20 Sinkhorn-Knopp-Iterationen projiziert, sodass sich sowohl Zeilen als auch Spalten zu 1 summieren. Dadurch wird die Zuordnung zu einer konvexen Kombination von Permutationen, die ein identitätsähnliches Verhalten wiederherstellt und gleichzeitig eine umfassende Cross-Stream-Kommunikation ermöglicht.
- Geringer Trainingsaufwand, messbare Downstream-Gewinne: Bei den 3B-, 9B- und 27B-DeepSeek-MoE-Modellen verbessert mHC die Benchmark-Genauigkeit, zum Beispiel etwa plus 2,1 Prozent gegenüber BBH für das 27B-Modell, während der Trainingszeitaufwand durch Fusionskerne, Neuberechnung und Pipeline-bewusste Planung nur etwa 6,7 Prozent erhöht.
- Führt eine neue Skalierungsachse für das LLM-Design ein: Anstatt nur Parameter oder Kontextlänge zu skalieren, zeigt mHC, dass das explizite Entwerfen der Topologie und vielfältigen Einschränkungen des Reststroms, zum Beispiel Restbreite und -struktur, eine praktische Möglichkeit ist, eine bessere Leistung und Stabilität in zukünftigen großen Sprachmodellen zu erzielen.
Schauen Sie sich das an VOLLSTÄNDIGES PAPIER hier. Sie können uns auch gerne weiter folgen Twitter und vergessen Sie nicht, bei uns mitzumachen 100.000+ ML SubReddit und Abonnieren Unser Publication. Warten! Bist du im Telegram? Jetzt können Sie uns auch per Telegram kontaktieren.
Asif Razzaq ist CEO von Marktechpost Media Inc.. Als visionärer Unternehmer und Ingenieur setzt sich Asif dafür ein, das Potenzial der künstlichen Intelligenz für das soziale Wohl zu nutzen. Sein jüngstes Unterfangen ist die Einführung einer Medienplattform für künstliche Intelligenz, Marktechpost, die sich durch eine ausführliche Berichterstattung über maschinelles Lernen und Deep-Studying-Nachrichten auszeichnet, die sowohl technisch fundiert als auch für ein breites Publikum leicht verständlich ist. Die Plattform verfügt über mehr als 2 Millionen monatliche Aufrufe, was ihre Beliebtheit beim Publikum verdeutlicht.