Neue Wörter. Alte Konzepte. Letztendlich geht es um Datenfusion.
Die Entitätsauflösung ist ein Prozess. Ein Wissensgraph ist ein technisches Artefakt. Und die Kombination der beiden ergibt eines der leistungsstärksten Datenfusionstools, die wir im Bereich der Wissensdarstellung und des Schlussfolgerns haben. In letzter Zeit haben ERKGs ihren Weg in die Datenarchitektur gefunden, insbesondere für analytische Organisationen, die alle Daten in einem bestimmten Bereich zur Untersuchung an einem Ort verknüpft haben möchten. In diesem Artikel werden der Entity Resolved Data Graph, der ER, der KG und einige Particulars zu ihrer Implementierung erläutert.
ER. Entitätsauflösung (auch Identitätsauflösung, Datenabgleich oder Datensatzverknüpfung genannt) ist der Computerprozess, bei dem Entitäten in einem Datensatz dedupliziert und/oder verknüpft werden. Dies kann so einfach sein wie das Auflösen von zwei Datensätzen in einer Datenbank, von denen einer als Tom Riddle und der andere als TM Riddle aufgeführt ist. Oder es kann so komplex sein wie eine Individual, die Decknamen (Lord Voldemort), verschiedene Telefonnummern und mehrere IP-Adressen verwendet, um Bankbetrug zu begehen.
KG. Ein Wissensgraph ist eine Type der Wissensdarstellung, die Daten visuell als Entitäten und die Beziehungen zwischen ihnen präsentiert. Entitäten können Personen, Unternehmen, Konzepte, physische Vermögenswerte, geografische Standorte usw. sein. Beziehungen können Informationsaustausch, Kommunikation, Reisen, Bankgeschäfte, Computertransaktionen usw. sein. Entitäten und Beziehungen werden in einer Graphdatenbank gespeichert, vorab verknüpft und visuell als Knoten und Kanten dargestellt. Das sieht ungefähr so aus …

Daher…
ERKG. Ein Wissensgraph, der mehrere Datensätze enthält, innerhalb derer Entitäten verbunden und dedupliziert sind. Mit anderen Worten, es gibt keine doppelten Entitäten (die Knoten für Tom Riddle und TM Riddle wurden in einen einzigen Knoten aufgelöst). Außerdem wurden latente Verbindungen zwischen potenziell verwandten Knoten innerhalb einer akzeptablen Wahrscheinlichkeitsschwelle entdeckt (z. B. Tom Riddle, Lord Voldemort und Marvolo Riddle). An diesem Punkt fragen Sie sich wahrscheinlich: „Warum sollte man jemals einen Wissensgraphen aus mehreren Datenquellen erstellen, der ist nicht Entitätsaufgelöst?“ Die einfache Antwort lautet: „Das würden Sie nicht.“ Allerdings machen die Methoden zur Auflösung von Entitäten und die verfügbaren Technologien zur Graphdarstellung die Erstellung eines ERKG zu einer gewaltigen Aufgabe.
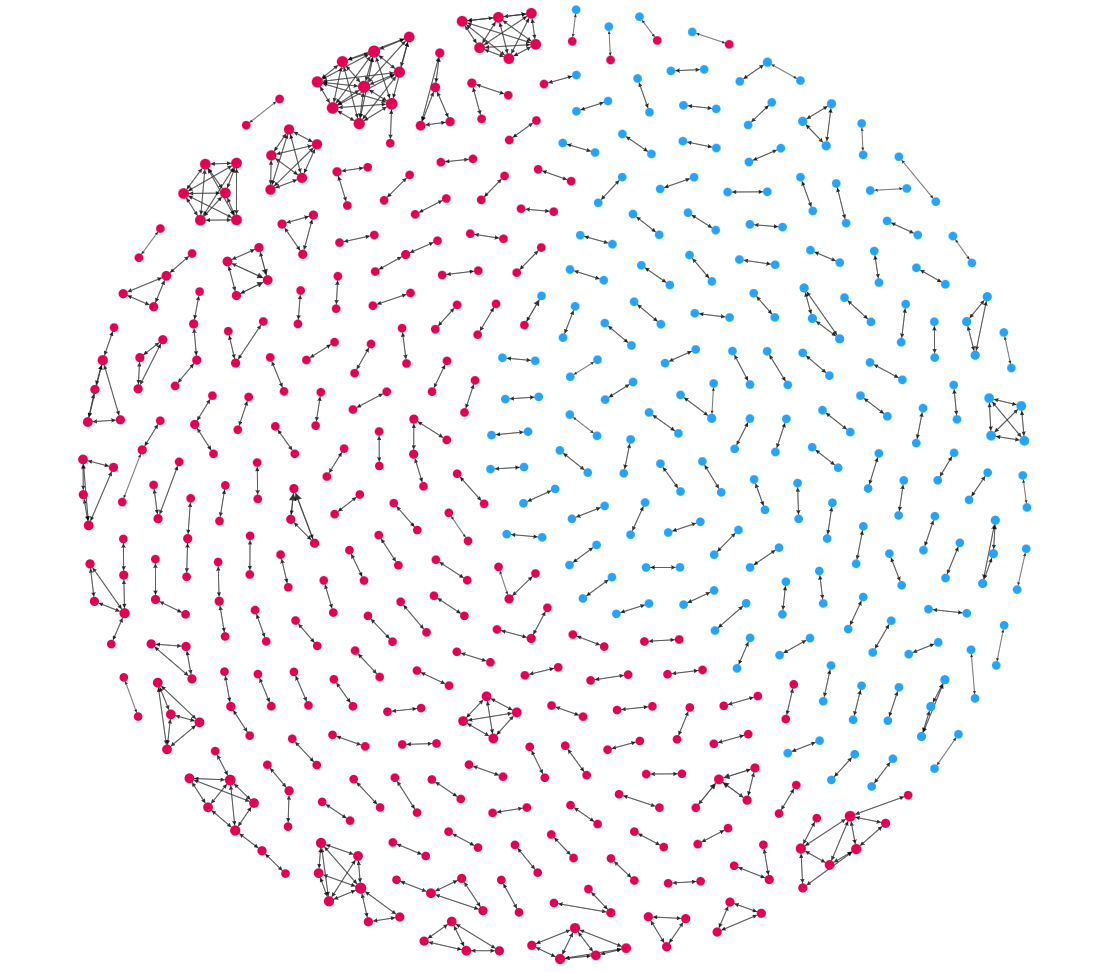
Dies ist das erste ERKG, das wir je hergestellt haben.

Im Jahr 2016 haben wir zwei Datensätze in eine Graphdatenbank eingebracht: 1) Personen auf der internationalen Sanktionsliste des Workplace of International Belongings Management (OFAC) (blau) und 2) Kunden einer Firma, deren Identify nicht genannt werden soll (rosa). Offensichtlich struggle es die Absicht der Firma, herauszufinden, ob einer ihrer Kunden worldwide sanktionierte Personen waren, ohne eine manuelle Suche in der OFAC-Datenbank durchzuführen. Obwohl der ER-Prozess, den diese Grafik darstellt, für diese Aufgabe wahrscheinlich übertrieben ist, ist er Ist illustrativ.
Die Mehrheit der aufgelösten Entitäten im Diagramm besteht aus zwei bis drei Einzelpersonen innerhalb der gleiche Datensatz (blau zu blau oder rosa zu rosa). Dabei handelt es sich wahrscheinlich um doppelte Datensätze (das Tom Riddle vs. TM Riddle-Downside, über das wir zuvor gesprochen haben). In einigen Fällen ist die Deduplizierung extrem, wie in den rosa Clustern oben im Bild. Hier sehen wir, dass eine einzelne Individual durch 5–10 separate Datensätze im Kundendatensatz dargestellt wird. Wir sehen additionally zumindest, dass das Unternehmen einen Deduplizierungsprozess innerhalb seiner eigenen Kundendatenbestände benötigt.
Interessant wird es bei den blau-rosa Beziehungen, die wir oben im Bild identifiziert sehen. Das ist, wonach das Unternehmen gesucht hat: Unternehmensauflösungen über Datensätze. Mehrere seiner Kunden sind wahrscheinlich Personen, gegen die worldwide Sanktionen verhängt wurden.

Dieses Beispiel ist ziemlich einfach, was zu der falschen Schlussfolgerung führen könnte, dass der Aufbau eines ERKG ein einfaches Unterfangen ist. Es ist alles andere als einfach. Insbesondere, wenn es mehrere Terabyte an Daten und mehrere Analystenbenutzer umfassen muss.
Leichtgewichtige Algorithmen zur Verarbeitung natürlicher Sprache (NLP) (wie Fuzzy-Matching-Techniken) sind recht einfach zu implementieren. Diese können das Tom Riddle vs. TM Riddle-Downside problemlos lösen. Wenn man jedoch mehr als zwei Datensätze kombinieren möchte, möglicherweise mit mehreren Sprachen und internationalen Zeichen, wird der einfache NLP-Prozess ziemlich pikant.
Für komplexere analytische Problemstellungen wie die Bekämpfung von Geldwäsche oder Bankbetrug sind auch fortgeschrittenere ER-Lösungen erforderlich. Fuzzy-Matching reicht nicht aus, um einen Täter zu identifizieren, der seine Identität absichtlich unter Verwendung mehrerer Aliasnamen verbirgt und versucht, Sanktionen oder andere Vorschriften zu umgehen. Zu diesem Zweck sollte der ER-Prozess auf maschinellem Lernen basierende Ansätze und ausgefeiltere Methoden umfassen, die neben einem Namen auch zusätzliche Metadaten berücksichtigen. Es geht nicht nur um NLP.
Es gibt auch eine große Debatte über graphenbasierte ER vs. ER auf Datensatzebene. Für die graphenbasierte Analyse mit höchster Genauigkeit sind beide erforderlich. Entitäten auflösen innerhalb Und über Datensätze, wenn diese Datensätze in eine Graphdatenbank importiert werden, 1) werden umfangreiche, rechenintensive Operationen am Graphen minimiert und 2) wird sichergestellt, dass der Graph zu Beginn nur aufgelöste Einheiten (keine Duplikate) enthält, was auch enorme Kosteneinsparungen für die gesamte Grapharchitektur mit sich bringt.
Sobald ein entitätsaufgelöster Wissensgraph vorhanden ist, können Knowledge Science-Groups mithilfe graphenbasierter ER-Techniken weitere ERs untersuchen. Diese Techniken haben den zusätzlichen Vorteil, dass sie die Graphtopologie (d. h. die inhärente Struktur des Graphen selbst) als Merkmal nutzen, um latente Verbindungen zwischen den kombinierten Datensätzen vorherzusagen.
Das ERKG kann ein leistungsstarkes und visuell intuitives Analysetool sein. Es bietet:
- Zusammenführung mehrerer Datensätze zu einer Grasp-Graphdatenbank
- Ein domänenspezifischer Wissensgraph, der visuell dargestellt wird, damit Analysten ihn erkunden können
- Die Möglichkeit, ein lebendiges Graphschema anzugeben, das darstellt, wie Daten verbunden und für Analysten dargestellt werden
- Die visuelle Darstellung der Datendeduplizierung und expliziter Verbindungen innerhalb und zwischen Datensätzen
- Latente Verbindungen (vorhergesagte Hyperlinks) innerhalb und zwischen Datensätzen mit der Möglichkeit, die Wahrscheinlichkeitsschwelle der Vorhersage zu steuern
Das ERKG wird dann zur analytischen Leinwand, auf der eine lebendig vernetzte Erkundung eines bestimmten Bereichs, der durch mehrere Datensätze repräsentiert wird, gemalt werden kann. Es handelt sich um eine Datenfusionslösung, und zwar eine, die für den Menschen höchst intuitiv ist.